c语言自定义类型:结构体的前世今生
一、什么是结构体
在c语言中,结构体(struct)是一种用户自定义的数据类型,允许将不同类型的组合在一起,以便作为一个单独的数据单元来使用。结构体可以包含多个不同数据类型的成员变量,这是他们能表示更为复杂的数据结构。
通俗的说,我们可以把结构体想象成一种生物,比如一种结构体就是人类,人类的性别,名字,国籍,年龄等标签,这些标签就是人类这个结构体不同类型的成员变量。人是一种结构体,那么植物,动物都可以算作是不同的结构体类型。
有了结构体这种自定义的数据类型,我们才能更恰当且方便的让代码变得实用。
例如,我们不能简单的只通过int ,char等数据类型来记录生活中的集合,因为你无法将那些数据类型关联起来,不能让它们成为一种“集合”,而结构体,就是解决这个问题的方法。
二、结构体的创建与初始化
那么,我们又该如何在c语言中声明,自定义一种结构体呢?
struct tag{ member-list;}variable-list;我们通过关键字struct 来告诉计算机这是一个我们自定义的结构体,tag代表这种结构体的名字,例如:人类,花。
然后通过{ }大括号将我们即将申明的成员变量给包裹起来,member-list就代表我们选择加入结构体的各个成员变量,也就相当于人中的姓名,年龄,花中的颜色,花香等。
而variable-list,则是这个tag结构体中的小类,我们可以想象成人类中的个体,人类是个种群,包含不同的人类个体,我们可以通过定义的一种结构体类型,定义多个类型相同的结构体,比如我可以定义a这个人,也可以定义b这个人,他们有着不同的个体值特征差异,但都是属于人这个结构体类型。
例:
struct People{char name[20];int age;char gender[15];};我们在此串代码里自定义了一个结构体People,然后给他赋上了三个成员变量name,age,gender,之后,我们就可以通过我们自己定义的People结构体类型,创建许多People结构体类型变量:
int main(){struct People ZhangSan = { "zhangsan",18,"man" };struct People LiSi = { "lisi",16,"woman" };return 0;}比如我们就定义两个“人”,一个是张三,一个是李四,两个结构体都是属于people这个结构体类型。我们可以给张三与李四赋上不同的成员变量的值(注意:初始化时括号里的数据要按照结构体成员类型的顺序依次赋值,zhangsan与18的顺序不能颠倒)(比较没有人的年龄是zhangsan,也没有人叫18)
除了这种初始化方式外,我们可以通过指定的顺序初始化:
int main(){struct People ZhangSan = { .age = 18,.gender = "man",.name = "zhangsan" };struct People LiSi = { .gender = "woman",.age = 18,.name = "lisi" };return 0;}这样子初始化是与上面的初始化效果一样,由于我们在初始化时指定了目标,所以可以打乱顺序(没指定目标就不要更改顺序喽,会迷路的!!)
三、结构体的自引用
既然结构体拥有着许多不同类型的成员变量,我们知道,结构体本身也是一种数据类型,那么能不能在结构体的成员变量里套用结构体呢?
答案是可以的,除了不同的结构体可以互相套用之外,相同类型的结构体也是可以的:
struct People{char name[20];int age;char gender[15];struct People person;};那我们这样写可以吗?
答案却是不行的,因为一旦这样套用,我们就不能知道这个结构体的大小,将会出现一种无限套娃的情况,所以我们应该用指针:
struct People{char name[20];int age;char gender[15];struct People* person;};我们创建一个结构体指针,由于指针的大小是确定的,且可以通过操纵指针来控制该结构体,既符合了大小的控制,也满足了我们对于这个成员功能的需求。
我们为什么要使用这样的结构体指针呢?这就像我们人一样,人与人之间是有不同的关系的,比如兄弟,姐妹,父母,这样不同的人际关系就会把许多人联系起来,结构体指针就相当于是在记录一个People与另一个People之间的关联。
当然,在结构体的自引用当中,我们通常会使用typedef重新命名我们的结构体类型,使其变得更加简略,但也会引出一些错误:
typedef struct People{char name[20];int age;char gender[15];People* person;}People;像这样子,在我们没有完成结构体的重命名之前,使用了重命名之后的名字,就会出现错误,正确的方式应该是不嫌麻烦,用一开始的名字:
typedef struct People{char name[20];int age;char gender[15];struct People* person;}People;四、结构体的大小与内存对齐
我们在上面结构体的自引用中有提到结构体的大小会变得无限大,那么我们如何计算一个结构体的大小呢?
这里就要引出一个概念了:结构体内存对齐。
在计算机中,为了提高数据的读写效率,数据存储在内存中时,有时候不是按照声明顺序依次排列,而是根据数据类型的大小以及系统要求进行对齐操作,也就是说,结构体内存对齐的目的就是为了方便我们对数据的存储与读取。
内存对齐有以下规则:
1. 结构体的第⼀个成员对⻬到和结构体变量起始位置偏移量为0的地址处2. 其他成员变量要对⻬到对⻬数的整数倍的地址处。3. 结构体总⼤⼩为最⼤对⻬数(结构体中每个成员变量都有⼀个对⻬数,所有对⻬数中最⼤的)的整数倍。4. 如果嵌套了结构体的情况,嵌套的结构体成员对⻬到⾃⼰的成员中最⼤对⻬数的整数倍处,结构体的整体⼤⼩就是所有最⼤对⻬数(含嵌套结构体中成员的对⻬数)的整数倍。我们在上面引出了一个概念叫做对齐数,对齐数是编译器默认的一个数与此成员变量的大小中的较小值,以Visual Studio 2022为例,它默认的那个数是8,那么age变量的对齐数就是int大小4与8中的较小值,也就是4。
我们举几个例子来加深一下理解:
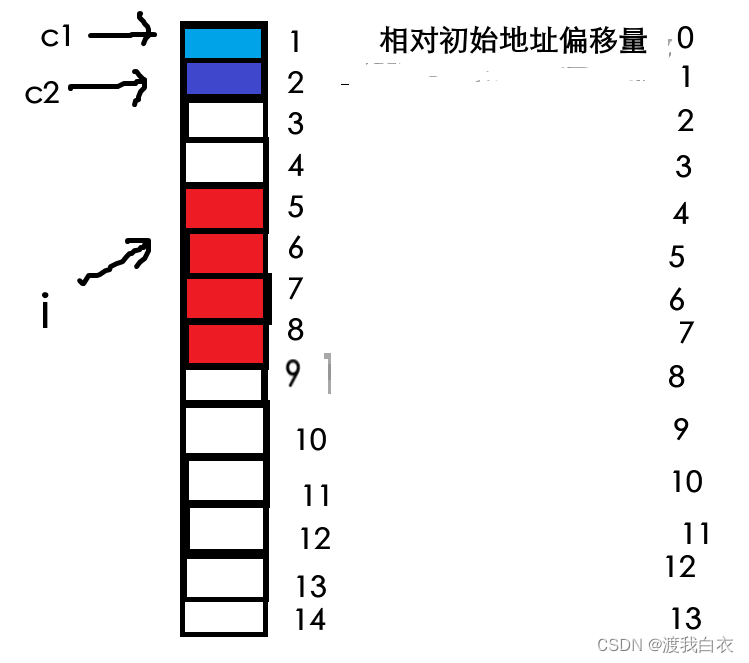
struct s1{char c1;char c2;int i;}s1;struct s2{char c1;int i;char c2;}s2;printf("%zd\n", sizeof(struct s1));//8printf("%zd\n", sizeof(struct s2));//12在这串代码中,我们分别定义了s1与s2两个结构体,并且每个种类我们都创建了一个结构体变量,通过sizeof()计算出两个结构体类型的大小并打印出来,我们可以看到,s1的大小是8,s2的大小是12,明明含有的成员变量的个数与类型都是一样的,为什么还会出现这种差异呢?
这就是内存对齐造成的影响了:在s1中,根据我们提到的对齐规则,c1将会对齐到偏移量为0内存空间处,c2的大小是1,在VS中默认数是8,也就是c2的对齐数是1,就会对齐到相对初始地址偏移量为1的内存空间,之后进行i的对齐,int大小为4,默认数是8,对齐数就是4,需要对齐到最近的4的整数倍的内存空间,也就是会对齐到偏移量为4的内存空间,c1占1号字节,c2占据2号字节,3、4号字节则空出浪费,i则占据了5、6、7、8号字节。然后根据对齐规则,结构体的大小为最大对齐数的整数倍,最大对齐数是i的4,总大小就满足4的整数倍,并且需要将成员变量占据的内存空间包括进去,就正好就是8。
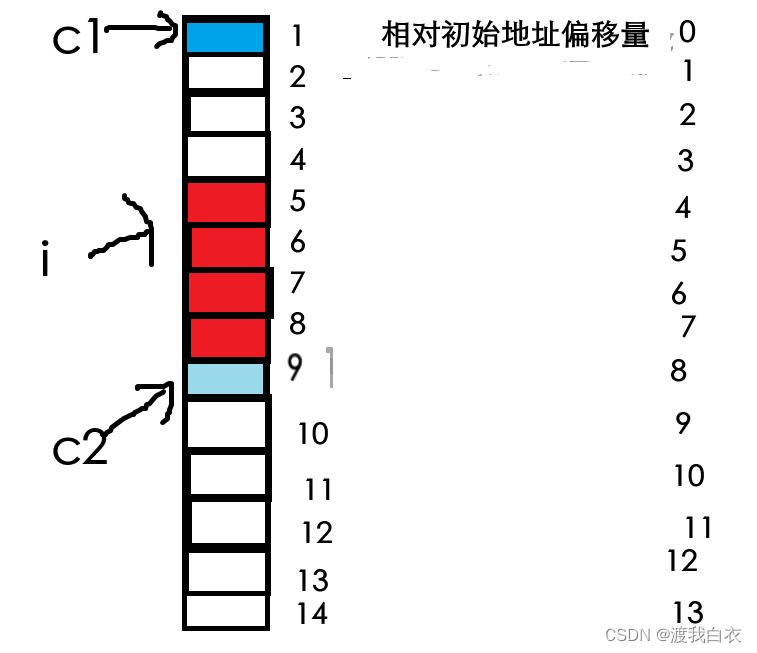
同理,s2就是先对齐c1到起始地址,在对齐i,由于对齐数是4,直接对齐到偏移量为4的位置,占据了5、6、7、8,随后c2对齐到偏移量为8的位置,占据了9,结构体的大小为最大对齐数的整数倍,由于8不能包括所有的数据,就只能是12。
由此可知,在设计结构体时为了尽可能节省空间,满足对齐,我们尽量让占用空间较小的数据类型集中在一起 。
五、结构体成员的访问与使用
要想使用我们定义的结构体变量的某个成员,比如age,gender,name,又该怎么办呢?
这里就要介绍两个运算符:
1:.(点运算符)
当结构体变量本身是一个实体,我们要直接访问结构体变量的成员时,就可以使用.(点运算符)。适用于结构体变量本身,而不是指向结构体的指针。
struct Person { char name[50]; int age;};struct Person person1;person1.age = 25;由于person1是一个结构体类型,我们直接通过.运算符给它的成员变量age赋值25。
而->(箭头运算符)用于通过指向结构体的指针来访问结构体的成员。适用于指向结构体的指针,而不是结构体变量本身。
struct Person { char name[50]; int age;};struct Person *ptrPerson;ptrPerson = malloc(sizeof(struct Person));ptrPerson->age = 30;也就是说
. 用于直接访问结构体变量的成员。-> 用于通过指向结构体的指针访问结构体的成员。 如何使用.与->还是取决于 目前操作的是结构体变量自身还是指向结构体的指针。
登录后可发表评论
点击登录