ChatGPT是由OpenAI开发的一种基于大规模预训练的语言生成模型。它建立在GPT(Generative Pre-trained Transformer)模型的基础上,通过大量的无监督学习和生成式任务训练来学习语言的概念和模式。
ChatGPT的原理是基于Transformer模型。Transformer是一种基于自注意力机制的深度神经网络架构,它能够有效地捕捉长距离依赖关系。ChatGPT的核心结构包括编码器和解码器,其中编码器用于将输入序列转换成上下文向量,解码器则利用上下文向量生成输出序列。
ChatGPT的训练过程分为两个阶段:预训练和微调。在预训练阶段,模型使用大量的文本数据进行自监督学习,通过预测下一个词来学习语言的概念和语义。预训练过程中使用的数据可以是从互联网上爬取的大规模文本数据集。预训练完成后,ChatGPT具备了一定的语言理解和生成能力。
在微调阶段,ChatGPT会使用有标签的对话数据进行有监督学习,以提高其生成对话的质量和准确性。这些对话数据通常是人类专家生成的,或者是从互联网上收集并经过人工筛选处理的。微调过程中,模型会根据对话上下文和目标对话的相关信息来生成响应。通过反复微调,可以逐渐提升ChatGPT在生成对话方面的表现。
ChatGPT的应用方式可以分为两种:单轮对话和多轮对话。在单轮对话中,用户输入一个问题或指令,ChatGPT生成一个回答或执行相应的任务。在多轮对话中,用户和ChatGPT之间进行连续的对话,ChatGPT需要维护上下文信息,并根据之前的对话内容生成合适的回应。
所以,咱们可以知道,ChatGPT提示词是指向ChatGPT提供的一段文本,用来指导它如何生成期望的回答或内容。提示词的质量和效果直接影响了ChatGPT的表现和能力。因此,编写好的提示词是使用ChatGPT的关键技能之一。
DALL.E模型是一种基于DALL·E 3的变分自编码器(VAE)和Transformer的文本到图像生成模型,可以根据用户提供的文本提示,即自然语言描述,生成高质量、高分辨率、多样化的图像。DALL.E模型的提示词法则是指如何编写有效的文本提示,以引导DALL·E模型生成期望的图像。
接下来,咱们先把这两个模型的原则列一列,再用实例对比分析一下。
一、挖掘ChatGPT提示词的总原则
1. 写清晰的指令
要清楚地表达你想要什么,不要让ChatGPT猜你想要什么。如果生成的内容很长,就要求ChatGPT做简短地回答;如果生成的结果太简单,就要求ChatGPT用专业级的要求写作;如果不喜欢格式,就给ChatGPT展示你期望的格式......
2. 使用分隔符
使用三重引号、XML标签、章节标题等分隔符可以帮助划分文本的不同部分,便于ChatGPT更好地理解,以便进行不同的处理。分隔符可以用来区分指令、参考文本、控制符、输出等。
3. 提供参考文本
如果你想让ChatGPT生成类似于某个文本的内容,你可以提供一些参考文本作为示例,让ChatGPT模仿其风格、语言、结构等。参考文本可以是你自己写的,也可以是从其他来源复制的。
4. 使用控制符
控制符是一些特殊的符号或单词,用来调整ChatGPT的行为和输出。例如,你可以使用`<|end|>`来告诉ChatGPT停止生成,使用`<|start|>`来告诉ChatGPT开始生成,使用`<|pad|>`来告诉ChatGPT填充空白,使用`<|keyword|>`来告诉ChatGPT使用特定的关键词,等等。控制符可以帮助你更精确地控制生成的内容和格式。
5. 适应不同的场景
不同的场景可能需要不同的提示词,因为ChatGPT的目标和任务也不同。例如,如果你想让ChatGPT生成一首诗,你可能需要提供一些诗歌的特征,如韵律、押韵、主题等;如果你想让ChatGPT生成一段代码,你可能需要提供一些编程语言的规则,如语法、变量、函数等;如果你想让ChatGPT生成一篇文章,你可能需要提供一些文章的结构,如标题、段落、引用等。根据不同的场景,你可以调整提示词的长度、内容、风格等,以达到最佳的效果。
6. 测试和改进
编写提示词是一个不断试错和改进的过程,你可能需要多次测试和修改你的提示词,才能得到满意的结果。你可以通过观察ChatGPT的输出,来判断提示词的效果,看看是否符合你的期望,是否有错误或不合理的地方,是否有可以改进的地方。你也可以参考其他人的提示词,学习他们的技巧和经验,或者向他们寻求反馈和建议。
二、挖掘DALL.E提示词的总原则
1. 进行多方面的具体描述
提示词应该尽可能具体、描述性和详细,包括图像的所有重要元素和细节,以实现对生成图像的细粒度控制。
2. 对描述进行适当分隔
提示词可以使用符号和格式来分隔文本提示的不同部分,增加清晰度和多样性,例如使用括号、冒号、逗号等。
例如,`(purple hairs:1.2)`表示头发的颜色是紫色,且权重是1.2。
3. 穿插使用一些特定格式描述
提示词可以使用特定的格式来指定图像的风格,例如`<lora:dingdang-liuqiyue:0.55>`,其中`lora`是风格的名称,`dingdang-liuqiyue`是风格的作者,`0.55`是风格的权重。
4. 遵守DALL·E模型的政策
提示词应该遵守DALL·E模型的政策,不要创建任何可能冒犯、违法或有害的图像,不要参考任何政治家或公众人物,不要使用在过去100年内创作的艺术家的风格,不要改变模因或虚构角色的起源等。
5. 明确场景及目标
提示词应该适应不同的场景和目标,根据需求和偏好,选择合适的图像类型、分辨率、数量等参数,例如使用`photo`或`1024x1792`等关键词。如果用户想要生成一张全身肖像,就要求DALL.E模型使用`1024x1792`这样的尺寸。
6. 反复测试与改进
提示词应该经过多次测试和改进,以获得最佳的生成效果,观察和评估生成图像的质量和多样性,修改和优化文本提示中的内容和格式。比如,用户可以通过观察DALL.E模型的输出,来评估提示词的质量,看看是否符合用户的期望,是否有错误或不合理的地方,是否有可以改进的地方。同时,还需要经常参考和学习其他人的文本提示,寻求和接受反馈和建议。
三、以绘画示例穿插使用ChatGPT与DALL·E的演绎
目标:使用一些鲜明的手法创作一套敦煌飞天仙女图。
这是一件很有意思的工作,同时使用ChatGPT与DALL·E的模型来完成,在这个过程中,咱们会尝试很多中技巧,来达到我们的目标。
从很一般提问开始:
请问敦煌的飞天仙女图有什么背景知识吗
这种提问得到的回答只能如下:

咱们尝试更换一种问法:
我是一名敦煌知识的爱好值,我打算要仿照古老的敦煌壁画创作一副"'敦煌飞天仙女图"',但我并不是太清楚关于敦煌飞天仙女的背景知识,以致于我无法为整幅画作进行框架设计。所以,我想要通过你的强大的知识库,为我填充创作这幅画作的知识空白,给我一些全面的知识描述,并在最后帮我生成一些描述这幅画作要素的必要关键词,这些关键词比如"'南北朝绘画艺术"'、"'东西方艺术走廊"'等。当然,我希望这些描述里面包含有'<|西域|>'这个关键词,以方便我创作图画的时候能够受到该地域艺术风格的影响。为我生成描述的时候,最好能够让前面给出的背景知识描述与后面给出的画作要素关键词相呼应。
ChatGPT就帮我生成了相当有水平的答案:



接下来,咱们基于ChatGPT的答案提炼出图画的创作描述:
创作一幅具备敦煌南北朝艺术风格的飞天仙女图。
该图描绘佛教中的天人或神仙在空中飞舞的场景。
该图融合了印度、西域和中原的艺术元素。
图中飞天仙女的造型服饰要求如下:
飞天仙女的头部有圆光,头发束成圆髻或双髻,有的戴印度式的宝冠,有的戴道冠或花冠,有的头发散开,飞天仙女的下身穿着长裙,裙子的颜色和花纹各异,有的裙子开叉,露出白皙的腿部,有的裙子紧贴身体,显示出曲线。飞天仙女的手中多持有各种乐器、花篮、香炉等物品,表现出她们的音乐和芬芳的功能。
图中飞天仙女的姿态和动作要求如下:
飞天仙女的姿态轻盈优美,动作灵动自然,表现出她们的飘逸和欢乐。飞天仙女有的横空飞翔,有的俯冲而下,有的盘旋而上,有的倒踢而飞,有的单飞,有的群飞,有的散花,有的弹奏,有的歌唱,有的舞动,有的祈祷,有的微笑,有的沉思,有的神情严肃,有的神情妩媚 。
飞天仙女的背景和环境要求如下:
飞天仙女的背景有天空、云彩、山水、花草、建筑、佛龛等,表现出她们的天国和人间的关系。飞天仙女的环境有明亮、暗淡、清新、艳丽等,表现出她们的气氛和情绪。飞天仙女的色彩有红、黄、绿、蓝、紫、白、黑等,表现出她们的个性和特征 。
过程如下:

稍等片刻,图片出来:
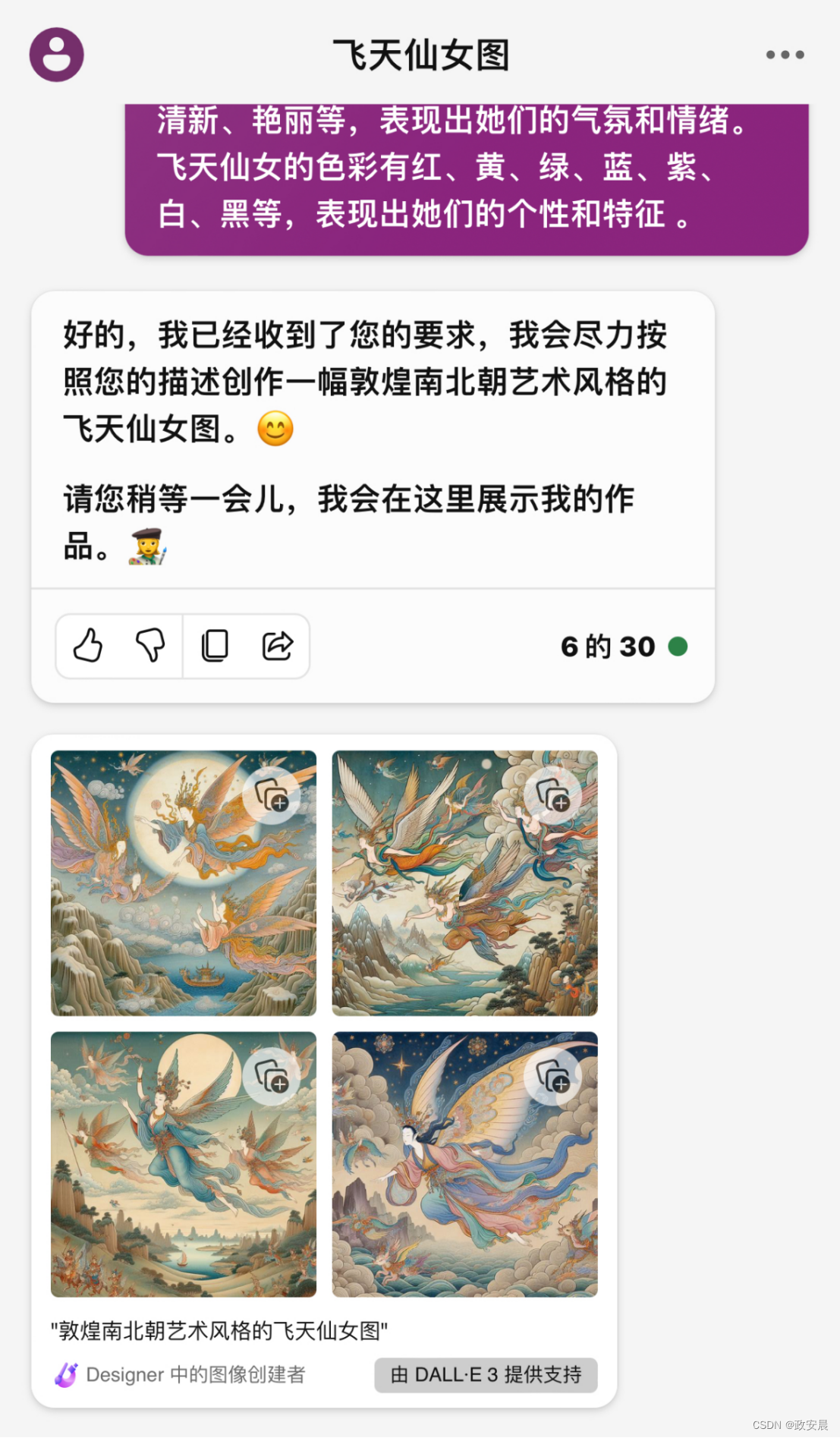
还不错,咱们放大一下图片:


在生成图片时,可以反复尝试,找到最合理的描述方法,同时使用一些格式化方式会有更好的效果。
最后,希望小伙伴们都能够得到自己满意的答案,创作出自己心仪的好图!