人工智能、机器学习与深度学习之间的关系
文章目录
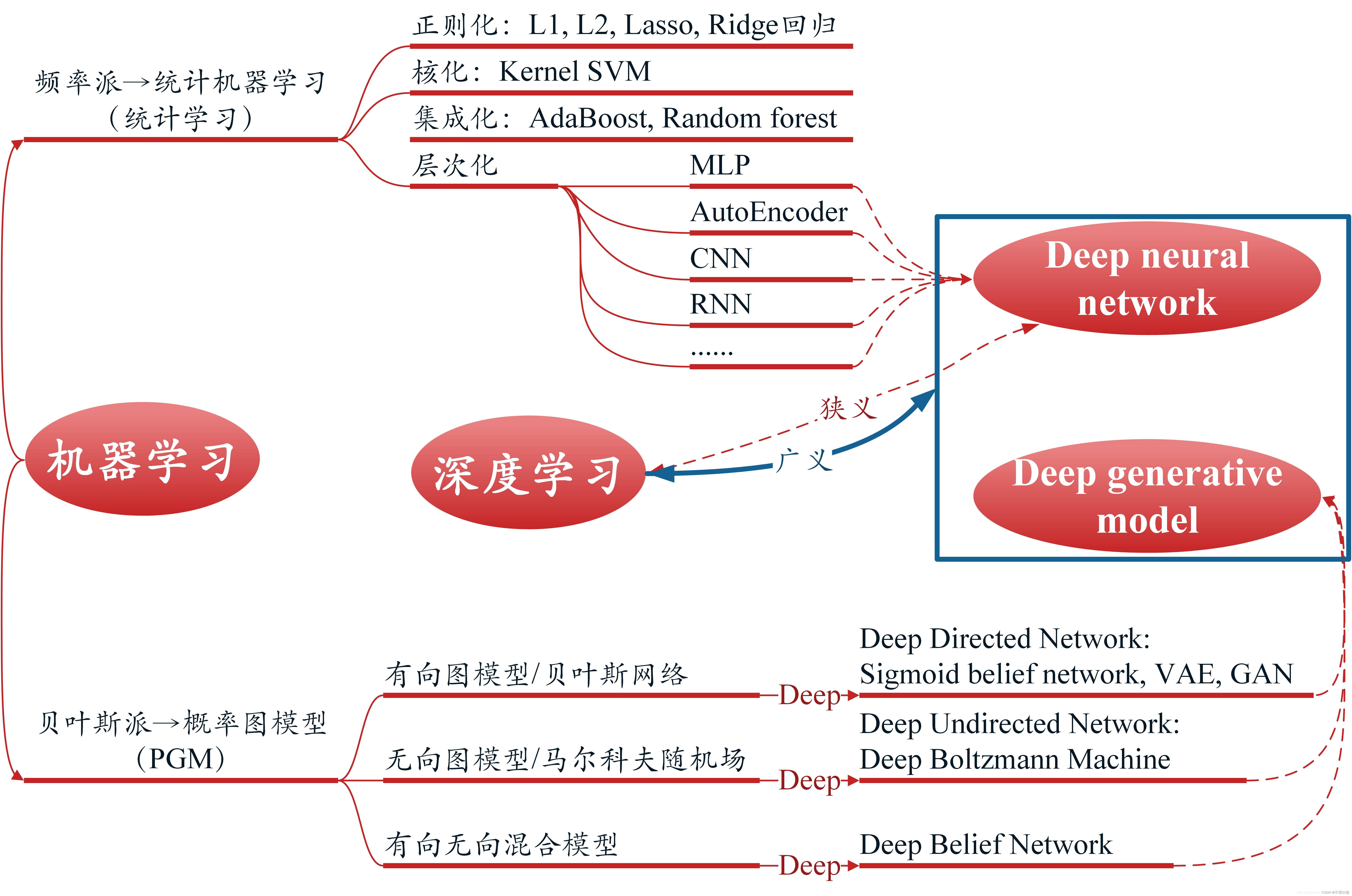
人工智能、机器学习与深度学习之间的关系一、 什么是人工智能?二、 什么是机器学习?机器学习的类型1. 监督学习2. 无监督学习3. 强化学习(弱监督学习)4. 监督学习与强化学习的区别 三、 什么是深度学习?四、机器学习和深度学习的区别1. 传统机器学习与深度学习数据处理过程:2. 传统机器学习和深度学习的效果性能3. 传统机器学习与深度学习对硬件要求
一、 什么是人工智能?
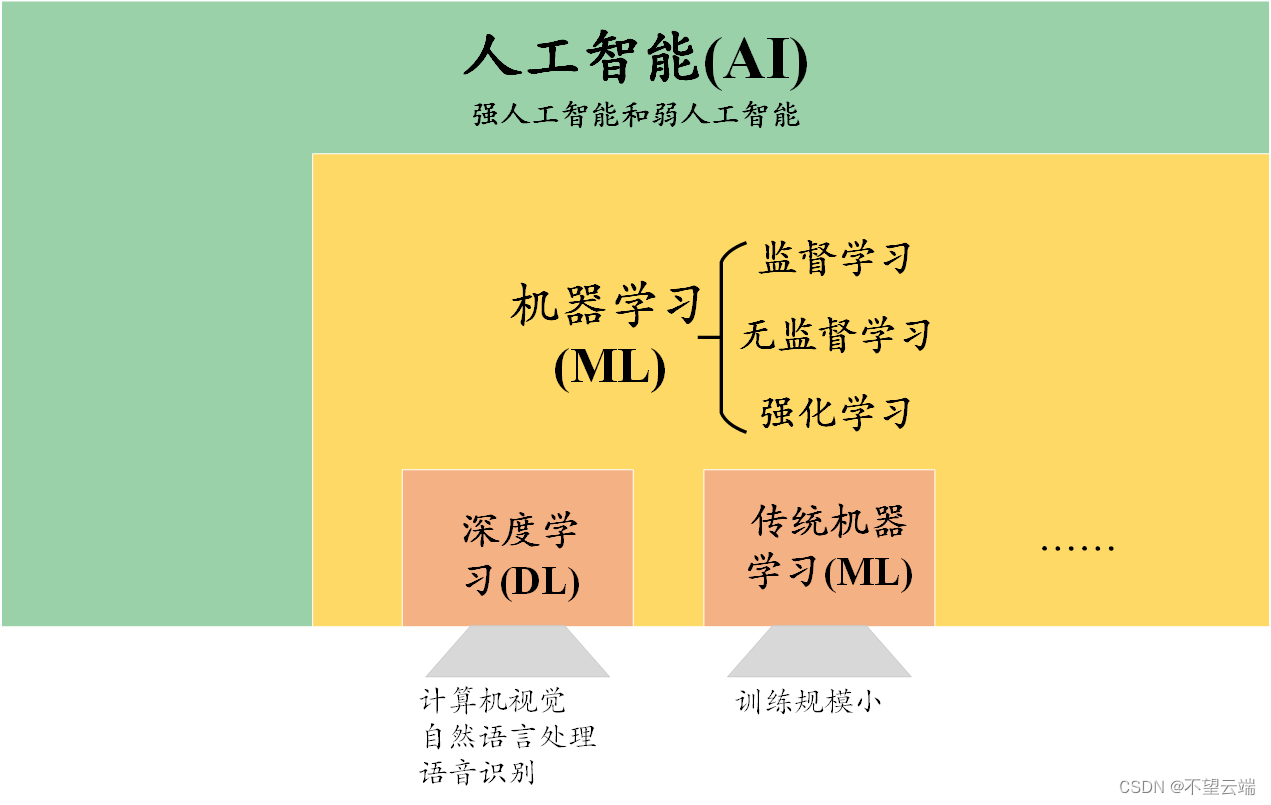
在我们深入研究机器学习和深度学习之前,让我们快速浏览一下它们所属的分支:人工智能(AI)。简而言之,人工智能是一个将计算机科学与大量数据相结合以帮助解决问题的领域。人工智能有许多不同的用例。图像识别,图像分类,自然语言处理,语音识别,面部识别等。
人工智能主要有两种类型:弱人工智能和强人工智能。弱人工智能旨在执行特定任务,它使自动驾驶汽车和 Amazon Alexa 等应用程序能够运行。强人工智能目前还没有实际应用,但它是一个正在研究和探索的领域。它以具有人类智能和意识的机器为中心,具有学习、制定计划和解决问题的能力。
二、 什么是机器学习?
机器学习是人工智能的一个子领域。机器学习通过算法解析数据,从中学习,并运用知识做出明智的决策。机器学习模型的目标是使计算机能够自主执行任务,而无需人工干预或特定编程。
开始时,向计算机输入训练数据。它使用这些数据来学习将来如何根据这些数据采取行动。一旦这些模型被实现,计算机就可以在无需我们帮助情况下,接受新数据并对其采取行动。随着学习的推进,计算机便可以开始识别未标记的数据。
机器学习的类型
该领域分为机器学习的三个子集:监督学习、无监督学习和强化学习。
1. 监督学习
监督学习使用标记数据集来训练算法。目标是训练这些算法独立地对数据进行分类并准确地预测结果。通俗的说就是,人类希望通过教会机器,按照给定的规则去完成一件对于机器来说比较复杂的事。监督学习的一个非常实际的应用是邮件收件箱中的垃圾邮件检测。
监督学习侧重于解决两类问题:回归和分类。回归的输出变量是真实值,例如某人的年龄或体重。解决这些问题的主要模型是线性回归。分类具有属于类别的输出类别,例如“哺乳动物”或“两栖动物”。用于解决这些问题的主要模型是决策树、逻辑回归和随机森林。
2. 无监督学习
无监督学习使用未标记的数据集集群。这些机器学习算法有助于发现隐藏的模式或数据组。无监督学习的一个常见应用是图像识别。无监督学习模型包括聚类、异常检测等。
3. 强化学习(弱监督学习)
强化学习,可以训练模型做出一系列决策。可以将其视为一个试错游戏。为了让机器做我们希望它做的事情,我们根据它的行为给予奖励或惩罚。我们希望它学习如何最大化奖励。现实世界中的一个例子是 Facebook 的 Horizon,它使用强化学习来执行个性化建议以及向用户提供更有意义的通知等操作。
4. 监督学习与强化学习的区别
| 学习方式 | 监督学习 | 非监督学习 | 强化学习 |
|---|---|---|---|
| 条件 | 在有标签数据的情况下进行学习 | 在没有标签数据的情况下进行学习 | 在与环境交互的过程中进行学习 |
| 目标 | 学习一个从输入到输出的映射关系 | 学习数据中的内在结构和模式 | 学习如何做出最优的决策 |
| 目标函数 | 最大化或最小化某个目标函数 | 最大化累积奖励 | |
| 训练数据 | 静态 | 由智能体与环境交互产生 | |
| 途径 | 通过优化目标函数来学习模型参数 | 通过试错来学习最优策略 |
通俗的说,监督学习就是,人类这个老师通过自己大量的事例经验,强制让机器这个懵懂的孩子,去学会判别什么是黑,什么是白,哪个是猪,哪个是狗;而在非监督学习情境下,这里没有是非对错,机器运用人类给定的方法,在不断学习的过程,去发现它能看得到的这小小世界的规律;而强化学习就是人类这个老师,在机器这个小孩横冲直撞时,于特定的时间给予它一些奖励或者惩罚,从而引导它在面对分岔路口时,学会自己做出判断,朝着能够获得最多奖励的方向前进。而这个方向是人类希望它走的方向。
三、 什么是深度学习?
深度学习是机器学习的一个子集。您可以将其视为机器学习甚至更深入的机器学习的演变。
深度学习模型旨在模拟人类做出决策和得出结论的逻辑结构,以此分析数据。这些模型是根据人脑建模的,它们使数据能够在模仿神经元的节点之间传递。深度学习模型将算法分层以创建可以自行学习和做出决策的人工神经网络(ANN)。这种设计使深度学习模型比传统机器学习模型更强大。
深度学习系统需要建立在学习大型数据集基础之上。如果系统成功建立,一旦输入数据,它们就可以立即产生结果。一旦设置完毕,人工干预的需要就非常低。深度学习领域的一个重要进步称为迁移学习(transfer learning),它涉及预训练模型的使用。这些预训练模型有助于满足对大型训练数据集的需求。
与神经网络相关的深度学习,之所以用“深度”描述,主要是看神经网络的层数,1-2层叫做浅层神经网络,超过5层叫做深层神经网络,又叫做“深度学习”。<.mark>
四、机器学习和深度学习的区别
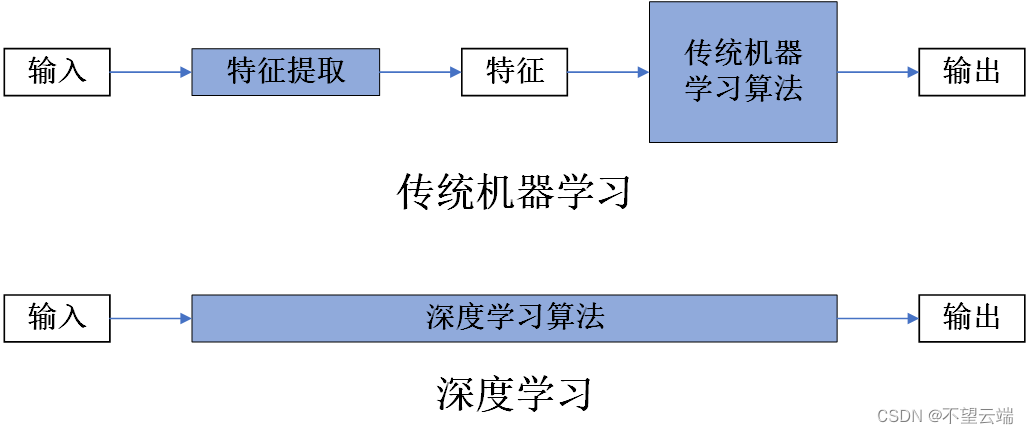
1. 传统机器学习与深度学习数据处理过程:
传统机器学习特征是清晰的,深度学习内部特征是黑盒
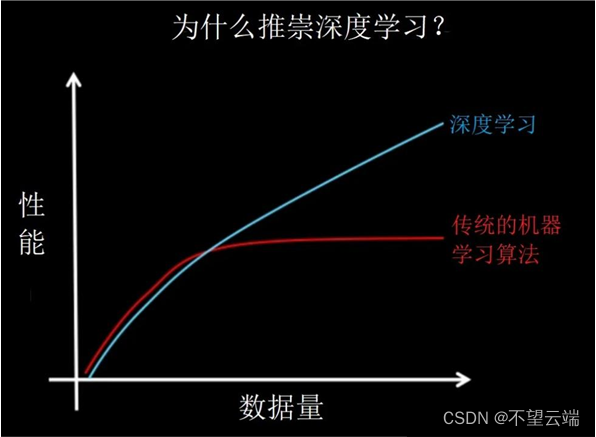
2. 传统机器学习和深度学习的效果性能
在训练数据规模比较小的情况下,传统机器学习型算法表现还可以,但是数据增加了,传统机器学习效果没有增加,会有一个临界点;但是对于深度学习来说,数据越多,效果越好。
3. 传统机器学习与深度学习对硬件要求
传统机器学习在训练的时候,基本可以使用传统CPU运算就可以了。但是在深度学习方面,因为神经网络层数多,计算量大,一般都需要使用 GPU或AI计算芯片(AI卡)进行运算才行,这个也就是我们常说的“算力”。
深度学习在大规模数据计算方面算力消耗成本惊人,以ChatGPT为例,传闻大概运算花费了英伟达(NVIDIA)的A100型号GPU一万张,目前京东A100的卡销售价格大约为人民币10万元,ChatGPT大概训练算力成本粗略预估为10亿人民币,对于ChatGPT公布的数据来看,一次大模型的训练大约需要1200万美元,所以除了比拼算法,算力更是很重要的决定性因素。