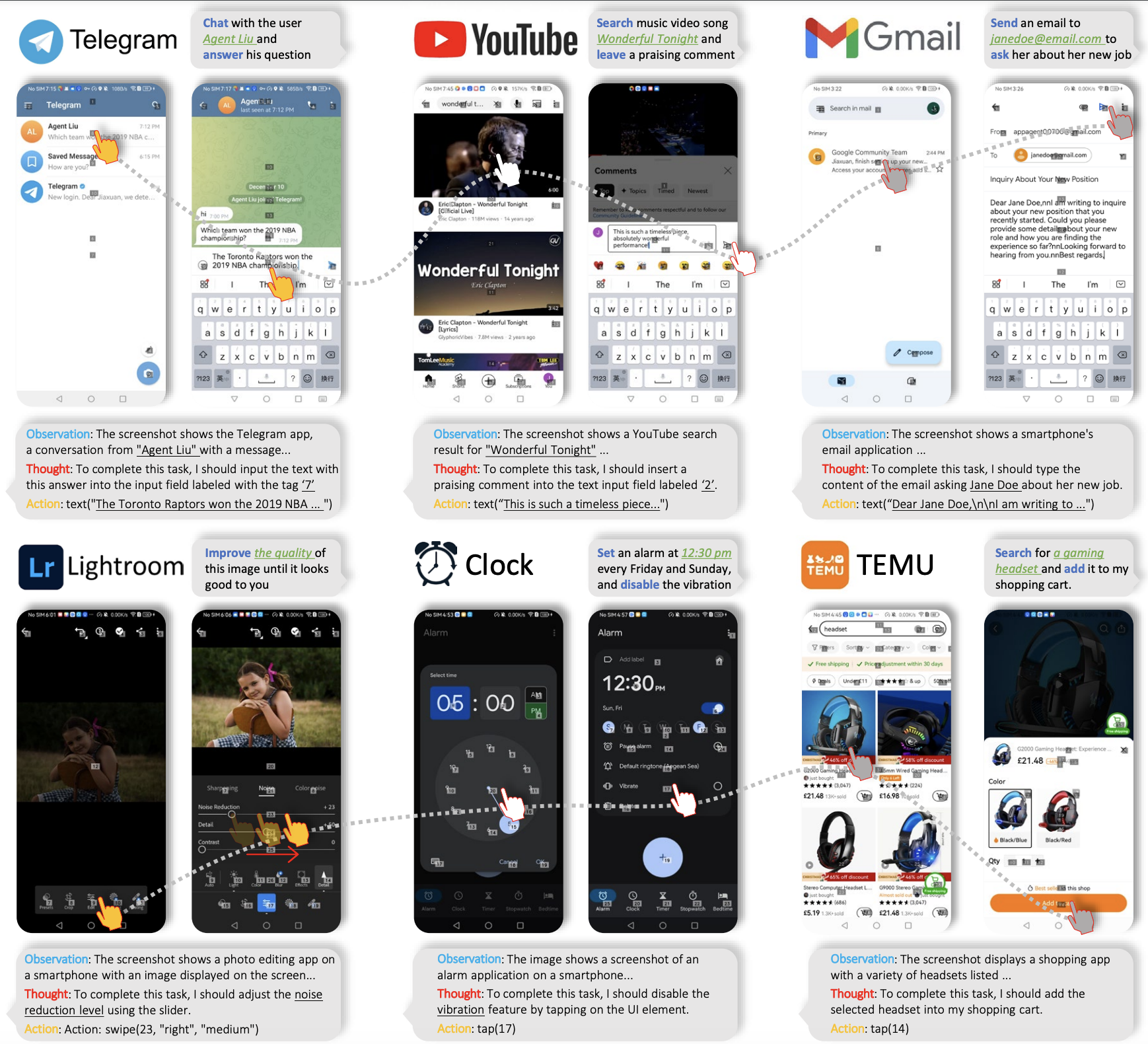
腾讯推出的 AppAgent,是一个多模态智能体,通过识别当前手机的界面和用户指令直接操作手机界面,能像真实用户一样操作手机!
机器学习周刊:关注Python、机器学习、深度学习、大模型等硬核技术
1、如何学习深度学习?
最近X上有推友重提这篇文章,是网友看过 Jeremy 教授的 fast.ai 深度学习课程后,把每节课提到的学习建议和忠告都总结了下来:https://forums.fast.ai/t/things-jeremy-says-to-do/36682/1
我让ChatGPT、Claude、Gemini翻译并总结了这篇文章,Gemini完成的更加出色,给出了26条关于学习方法和一些细节的建议(强烈建议,如果时间允许,可以看原文):
**倾听:**仔细注意老师在整堂课中的建议和提示。**不要被理论淹没:**专注于运行代码并对其进行实验,而不是一开始就陷入理论细节中。**选择一个项目并把它做得精彩:**选择一个你感兴趣的项目,并投入额外的精力,确保对其进行优化和改进。**探索不同的数据集:**不要局限于课程中提供的数据集;自己寻找数据集并对其进行实验。**不要使你的代码过于复杂:**保持你的代码简单和有条理,避免不必要的复杂性。**学习 Jupyter 快捷键:**熟悉 Jupyter 快捷键以提高你的效率。**运行代码并对其进行实验:**不要只阅读代码;运行它并尝试不同的输入和参数来观察会发生什么。**不要花几个小时试图立即理解所有理论:**可以先不理解所有内容;专注于实践方面,并随着时间的推移逐渐加深你的理解。**阅读比赛获胜者的论文:**通过阅读比赛获胜者的论文来学习他人的成功经验,注意他们的方法和见解。**使用你拥有的所有文本:**在处理 NLP 时,确保使用所有可用的文本,包括未标记的验证集,以增强模型的性能。**学会发音希腊字母:**熟悉深度学习论文中常用的希腊字母的发音。**非常习惯 PyTorch 张量:**培养对 PyTorch 张量和运算的扎实理解。**应用广播规则:**在处理更高秩张量时学习并应用广播规则。**不要假设库是正确的:**对库持怀疑态度;验证其正确性并了解其工作原理。**不要担心你是否跟上了所有内容:**感到不知所措是正常的;专注于你能理解的内容,并逐渐建立你的知识。**学会调试深度学习代码:**调试 DL 代码具有挑战性;确保你的代码简单,并检查中间结果以尽量减少错误。**用玩具问题进行实验:**创建并解决玩具问题以深入了解深度学习的概念和技术。**学习 Swift for TensorFlow:**抓住机会学习 Swift for TensorFlow,它为 DL 开发提供了优势。**为 Swift for TensorFlow 生态系统做出贡献:**通过为代码、文档或讨论做出贡献来参与 Swift for TensorFlow 社区。**使用compose 进行函数组合:**使用 compose 函数熟悉函数组合的概念。**谨慎的数据增强:**在增强数据时,仔细考虑转换及其对数据完整性和标签准确性的影响。**尝试不同的架构:**尝试不同的神经网络架构以深入了解它们的性能特征。**不要冻结批归一化层:**避免在微调期间冻结批归一化层,以确保适当的权重更新。**尽可能以原始方式预处理数据:**作为一般规则,尽量减少对神经网络数据的预处理,以保留其原始信息和结构。**学习 Swift for TensorFlow:**抓住机会学习 Swift for TensorFlow,它为 DL 开发提供了优势。**自定义 Swift for TensorFlow:**Swift for TensorFlow 是完全可自定义的,允许你修改和扩展它以满足你的特定需求。 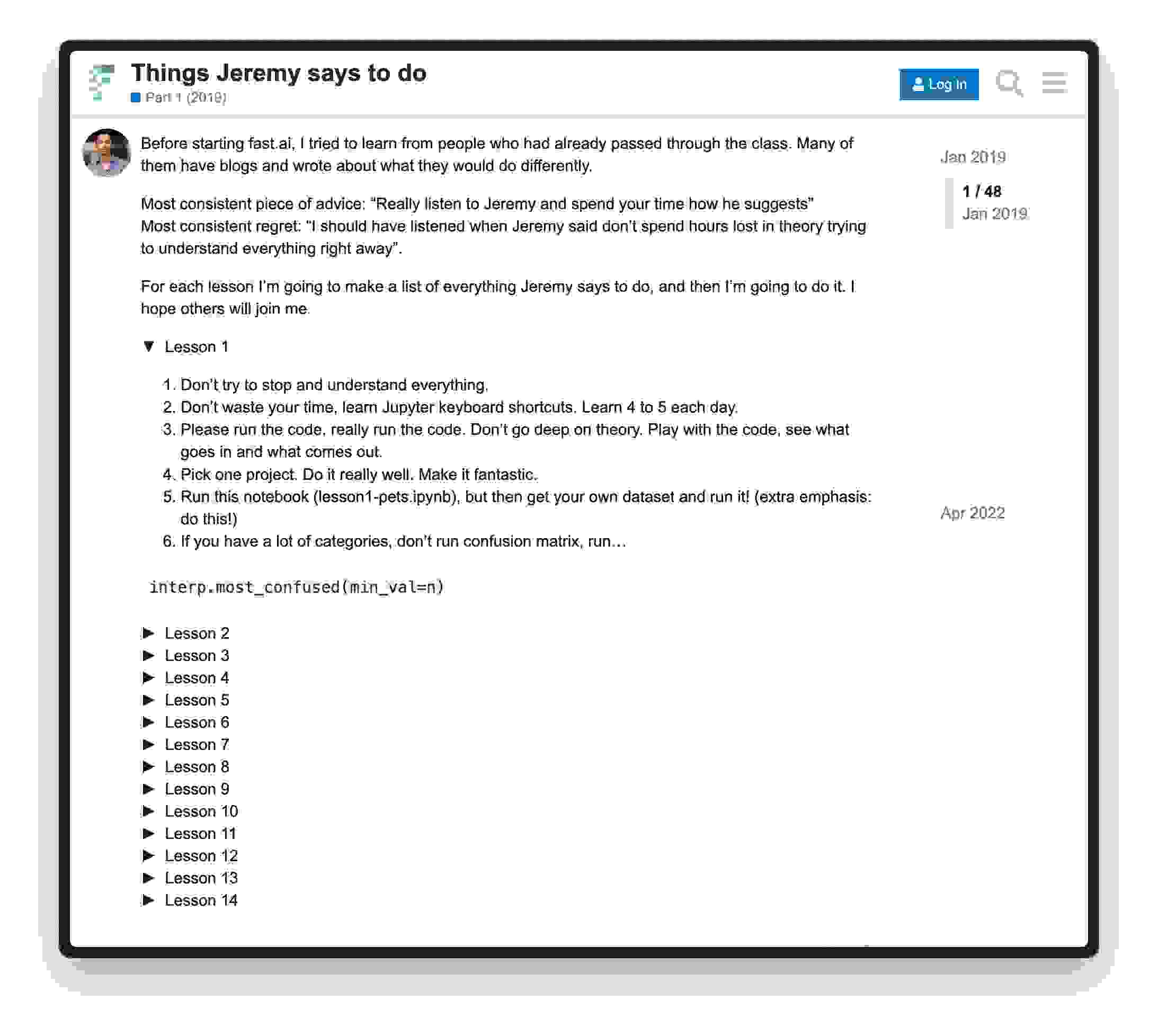
2、2024 年学习生成式 AI 路线图
项目地址:https://github.com/krishnaik06/Roadmap-To-Learn-Generative-AI-In-2024

这个项目总结了生成式AI学习路线,从Python、机器学习、NLP、深度学习、GPT-4、Langchain、向量数据库、LLM项目部署,非常顺畅。
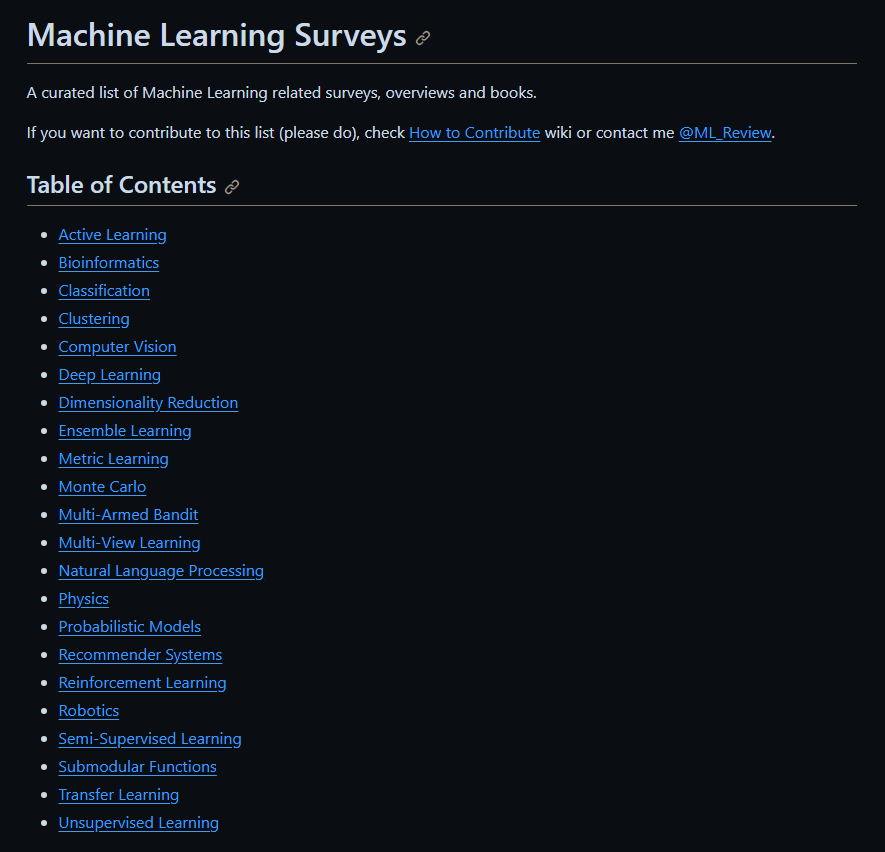
3、机器学习调查
地址:https://github.com/metrofun/machine-learning-surveys
有关主动学习、生物信息学、分类、度量学习、蒙特卡罗、多视图学习等方面的调查、教程和书籍的精选列表。
4、应用机器学习
地址:https://github.com/eugeneyan/applied-ml
这个项目分享了各公司在生产中数据科学和机器学习方面的论文和技术博客,已经更新了3年。
主要内容包括:
如何构架问题 ?(例如,将个性化视为推荐系统 vs. 搜索 vs. 序列)哪些机器学习技术有效 ✅(有时候,哪些不行 ❌)为什么它有效,背后的科学原理包括研究、文献和引用 ?实现了什么现实世界的结果(可以更好地评估投资回报率 ⏰??)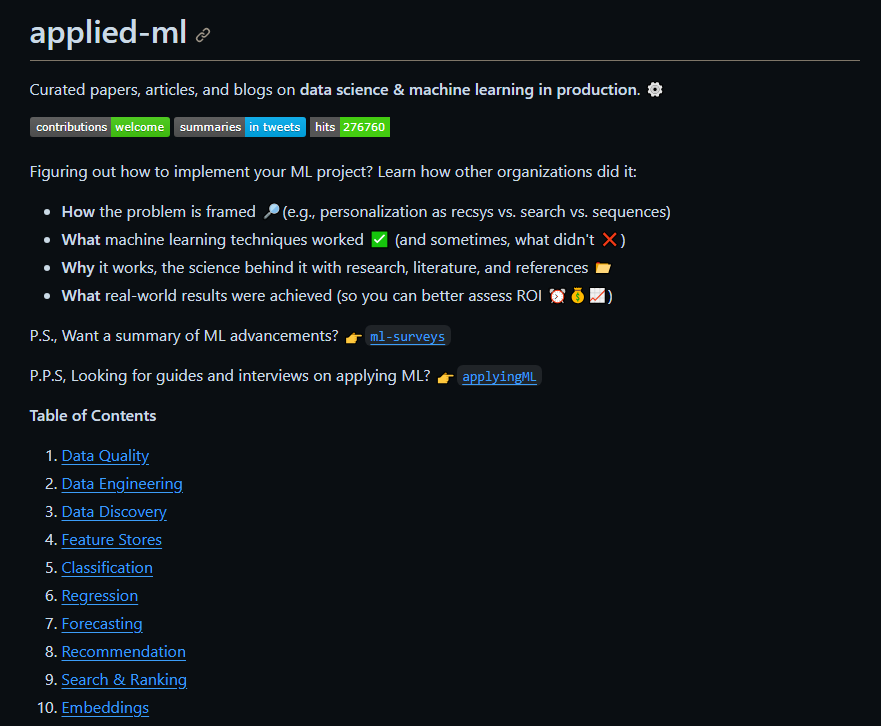
5、如何构建高效的RAG系统

程序员Jiayuan (Forrest)在X上分享了开发者搜索工具 devv.ai 是如何构建RAG系统的过程,内容十分硬核。
这里是Treads汇总:https://typefully.com/Tisoga/PBB58Vu
6、MLC Chat
MLC Chat:在iPhone上离线运行7B最强LLM Mistral
中文不太行,速度很快,手机会发热
APP下载:https://apps.apple.com/gb/app/mlc-chat/id6448482937
Github:https://github.com/mlc-ai/mlc-llm
支持各种系统,能在各种设备上开发、优化和部署AI模型。包括iOS和安卓
7、Ollama
地址:https://ollama.ai/download
Ollama为那些在macOS、Linux(暂不支持Windows)上使用LLM的开发者提供了一种简便的解决方案,可以更轻松地将这些模型集成到自己的应用程序中。
Ollama目前支持了10余种大模型,安装后均可一个命令本地启动并运行
| Model | Parameters | Size | Download |
|---|---|---|---|
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Llama 2 | 7B | 3.8GB | ollama run llama2 |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| Llama 2 13B | 13B | 7.3GB | ollama run llama2:13b |
| Llama 2 70B | 70B | 39GB | ollama run llama2:70b |
| Orca Mini | 3B | 1.9GB | ollama run orca-mini |
| Vicuna | 7B | 3.8GB | ollama run vicuna |
| LLaVA | 7B | 4.5GB | ollama run llava |
8、DreaMoving
DreaMoving是一个基于扩散模型的人类舞蹈视频生成框架。能够根据指导序列和简单的内容描述(仅文本提示、仅图像提示或文本和图像提示)生成高质量、高保真度的视频。
体验地址:https://modelscope.cn/studios/vigen/video_generation/summary
9、苹果最新论文
论文: https://huggingface.co/papers/2312.11514
苹果发的这个论文《使用有限的内存实现更快的 LLM 推理》。通过将将模型参数保存在闪存里,根据需要移动到DRAM。 使得能够运行的模型大小是可用DRAM的两倍,与传统的CPU和GPU加载方法相比,推理速度分别提高了4-5倍和20-25倍。
10、腾讯最新论文:《AppAgent: 多模态智能体,像真实用户一样操作手机》
项目首页:https://appagent-official.github.io
论文链接:https://arxiv.org/abs/2312.13771
项目地址:https://github.com/mnotgod96/AppAgent
论文通过引入一种基于大型语言模型(LLMs)的多模态智能代理(Agent)框架,赋予了智能体操作智能手机应用的能力。与传统的智能助手如 Siri 不同,AppAgent 不依赖于系统后端访问,而是通过模拟人类的点击和滑动等操作,直接与手机应用的图形用户界面(GUI)互动。这种独特的方法不仅提高了安全性和隐私性,还确保了智能体能够适应应用界面的变化和更新。

