目录
1. 概述2. 知识图谱设计方法3. 知识图谱结果与评价3.1 NEO4J 的基本操作3.1.1 NEO4J 的安装与启动3.1.2 NEO4J 的插入、删除实体与关系的操作3.1.3 NEO4J 的插入图形、图像或视频的操作3.1.4 NEO4J 的批量导入外部数据的操作3.1.5 NEO4J 的数据库查询 3.2 知识图谱结果3.3 知识图谱的评价3.3.1 有效性3.3.2. 完整性3.3.3. 准确性3.3.4. 一致性3.3.5. 可用性 4. 知识图谱的应用5. 总结6. 相关代码文件资源
1. 概述
知识图谱的经典定义是结构化的语义知识库,是用形象化的图形式来表达出物理世界中的概念以及内部关系。其基本组成单位是“实体-关系-实体”三元组,实体间通过关系相互连接形成知识结构网络。而它也是基于图的数据结构,基本组成是“节点-边-节点”,从而将知识信息连接成为一个关系网。所以知识图谱主要有实体、关系、属性等部分。其中实体表示的某种事物是独立于其他事物的,也是构建图谱最基本的元素;关系表示的是实体与实体之间的关系,用边连接着实体;而属性则用来阐述某一类实体的一些具体的值。这些三元组形式是知识图谱数据层最底层的形式。
图数据库是一种新型的非关系型数据库,无论是节点还是边缘,它的图表都基于图论。图论中的基本元素节点和边对应图数据库当中的节点与关系。图数据库的模型是包括节点、关系以及属性。它主要存储两类数据:节点和边。节点是实体:如人、成绩、书籍或其他具体事物。边关系:连接节点的概念、事件或事物。
在本次实验中,采用 NEO4J 图数据库。 NEO4J 具有高性能、成熟等特点,在进行海量数据处理时,速度更快。处理大量繁琐、关系混乱的结构化数据时更高效。而且无论图的数据量有多大,都不会影响其速度。
2. 知识图谱设计方法
画出构建知识图谱的一般流程图,并文字描述整个构建过程。知识图谱的一般流程图如下:
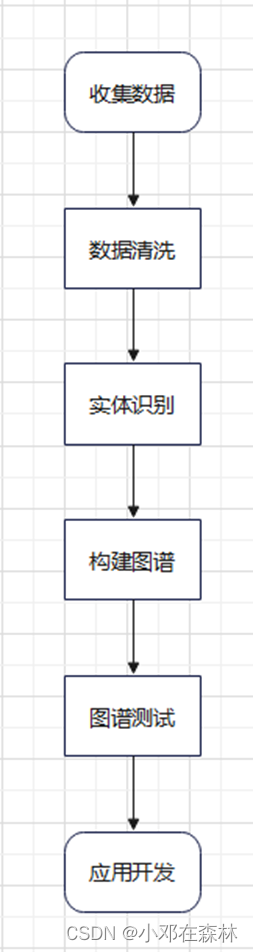
下面是整个构建过程的文字描述:
收集数据:从不同的数据源中收集数据,包括数据库、文本文档、网络、社交媒体等。例如文本、图像、语音等。可以使用Web 爬虫、文本挖掘等技术来收集数据。数据可以是结构化或非结构化的。结构化数据通常存储在数据库中,例如关系数据库和 NoSQL 数据库,可以通过 SQL 查询或 API 调用进行访问。非结构化数据包括文本、图像、音频和视频等,通常需要使用自然语言处理、图像处理或视频处理等技术进行处理。数据清洗:对收集到的数据进行清洗和预处理,以确保数据的一致性和准确性。例如去除重复数据、去除噪声、标准化数据格式等。实体识别:使用自然语言处理技术,对文本数据进行实体识别,识别出文本中的关键实体,例如人名、地名等。关系抽取:使用自然语言处理技术,对文本数据进行关系抽取,识别出文本中实体之间的关系,例如人与人之间的关系等。构建图谱:将实体和关系构建成图谱,使用图数据库或其他知识图谱平台,将数据加载到知识图谱中。这包括创建节点和关系,并将它们放置在适当的位置。构建过程需要考虑节点和关系的类型、属性和标识符,以及它们之间的关系。例如使用 NEO4J 构建图谱。图谱测试:验证和测试知识图谱,以确保它满足预期的要求。这包括检查数据的准确性、节点和关系的正确性、查询的效率等。验证和测试可以使用查询和可视化工具进行。应用开发:将图谱与应用程序集成,并进行维护和更新。这包括添加新数据、更新现有节点和关系、优化查询等。维护和更新需要考虑数据的一致性和可靠性。例如智能问答系统、推荐系统、搜索引擎等,以实现更高层次的知识服务和应用。 3. 知识图谱结果与评价
3.1 NEO4J 的基本操作
3.1.1 NEO4J 的安装与启动
安装可在 CSDN 上搜索其他博主写的,这方面资源很多,这里不再重复,下面只介绍启动。
cmd;切换路径,代码如下(具体的路径视乎你的安装位置):D:cd D:\Neo4J\neo4j-chs-community-5.5.0-windows\binneo4j console2023-09-10 11:31:11.295+0000 INFO Started.http://localhost:7474/用户:
neo4j,默认密码:neo4j,点击 Connect 即可。 3.1.2 NEO4J 的插入、删除实体与关系的操作
插入实体操作:
基础语法:
CREATE ( <node-name>:<label-name> { <Property1-name>:<Property1-Value> ........ <Propertyn-name>:<Propertyn-Value> })| 语法元素 | 描述 |
|---|---|
| <node-name> | 它是我们将要创建的节点名称。 |
| <label-name> | 它是一个节点标签名称 |
| <Property1-name>…<Propertyn-name> | 属性是键值对。定义将分配给创建节点的属性的名称 |
| <Property1-value>…<Propertyn-value> | 属性是键值对。定义将分配给创建节点的属性的值 |
实例:
CREATE (ee:Person {name: 'Emil', from: 'Sweden', kloutScore: 99})• CREATE 创建节点。
• () 表示节点。
• ee:Person – ee 是节点变量,Person 是节点标签。
• {} 包含描述节点的属性。
删除实体操作:
基础语法:
DELETE <node-name-list>| 语法元素 | 描述 |
|---|---|
| DELETE | 它是一个Neo4j CQL关键字 |
| <node-name-list> | 它是一个要从数据库中删除的节点名称列表 |
实例一(删除单个节点):
MATCH (e: Person) DELETE e实例二(删除全部节点及其关系):
MATCH (n) DETACH DELETE n注意:如果节点有关系,则无法删除,需要分离节点后才能删除它们。
插入关系操作:
基础语法:
CREATE (<node1-name>:<label1-name>)-[<relationship-name>:<relationship-label-name>]->(<node2-name>:<label2-name>)| 语法元素 | 描述 |
|---|---|
| CREATE创建 | 它是一个Neo4J CQL关键字 |
| <node1-name><节点1名> | 它是From节点的名称 |
| <node2-name><节点2名> | 它是To节点的名称 |
| <label1-name><LABEL1名称> | 它是From节点的标签名称 |
| <label2-name><LABEL2名称> | 它是To节点的标签名称 |
| <relationship-name><关系名称> | 它是一个关系的名称 |
| <relationship-label-name><相关标签名称> | 它是一个关系的标签名称 |
实例:
CREATE (p1:Profile1)-[r1:LIKES]->(p2:Profile2)• 这里p1和profile1是节点名称和节点标签名称“From Node”
• p2和Profile2是“To Node”的节点名称和节点标签名称
• r1是关系名称
• LIKES是一个关系标签名称
删除关系操作:
基础语法:
DELETE <node1-name>,<node2-name>,<relationship-name>实例一(删除指定节点及其关系):
MATCH (cc:Profile1)-[rel]-(c:Profile2) DELETE rel实例二(删除全部节点及其关系):
MATCH (n) DETACH DELETE n| 语法元素 | 描述 |
|---|---|
| DELETE | 它是一个Neo4j CQL关键字 |
| <node1-name> | 它是用于创建关系的一个结束节点名称 |
| <node2-name> | 它是用于创建关系的另一个节点名称 |
| <relationship-name> | 它是一个关系名称,它在和之间创建 |
3.1.3 NEO4J 的插入图形、图像或视频的操作
基础语法:
WITH 'xxx.url' AS urlCREATE(<node-name>:<label-name>{<Property1-name>:<Property1-Value>........<Propertyn-name>:<Propertyn-Value>, image:url})| 语法元素 | 描述 |
|---|---|
| xxx.url | 图像、视频链接(需要公开可直接访问的网址) |
| <node-name> | 它是我们将要创建的节点名称。 |
| <label-name> | 它是一个节点标签名称 |
| <Property1-name>… | 属性是键值对。定义将分配给创建节点的属性的名称 |
| <Property1-value>… | 属性是键值对。定义将分配给创建节点的属性的值 |
实例:
WITH 'https://thumbnail0.baidupcs.com/thumbnail/29f6e0082kefb5d59b7b6bd2a9004666?fid=3316406216-250528-217104295189955&time=1680102000&rt=sh&sign=FDTAER-DCb740ccc5511e5e8fedcff06b081203-hjiOJRLQbpX3R07Z6Ww0Lkuvvg0%3D&expires=8h&chkv=0&chkbd=0&chkpc=&dp-logid=8957641175237157343&dp-callid=0&file_type=0&size=c1536_u864&quality=90&vuk=-&ft=video&autopolicy=1' AS urlCREATE (与或图:图片 {名称:"与或图", image:url, 链接:"https://pan.baidu.com/s/1CjYk5Vktcj33wAQFhFLLlg?pwd=rgzn"})return *;3.1.4 NEO4J 的批量导入外部数据的操作
导入 csv 数据插入节点:
LOAD CSV WITH HEADERS FROM "file:///person_Format.csv" AS lineMERGE (p:person{id:line.id,name:line.name,age:line.age})导入 csv 数据创建节点之间的关系:
LOAD CSV WITH HEADERS FROM "file:///PersonRel_Format.csv" AS linematch (from:person{id:line.from_id}),(to:person{id:line.to_id})merge (from)-[r:rel{property1:line.property1,property2:line.property2}]->(to)注意:要将 csv 文件放入 NEO4J 的 import 文件夹下!
3.1.5 NEO4J 的数据库查询
基础语法:
MATCH ( <node-name>:<label-name>)RETURN <node-name>.<property1-name>, ... <node-name>.<propertyn-name>实例一(查找指定节点和关系):
MATCH (ee:Person) WHERE ee.name = 'Emil' RETURN ee;• MATCH 指定节点和关系的模式。
• (ee:Person) 是带有标签 Person 的单节点模式。它将匹配项赋给变量 ee。
• WHERE 筛选查询。
• ee.name = ‘Emil’ 比较 name 属性与值 Emil.
• RETURN 返回特定结果。
实例二(查找所有节点和关系):
MATCH (n) return n3.2 知识图谱结果
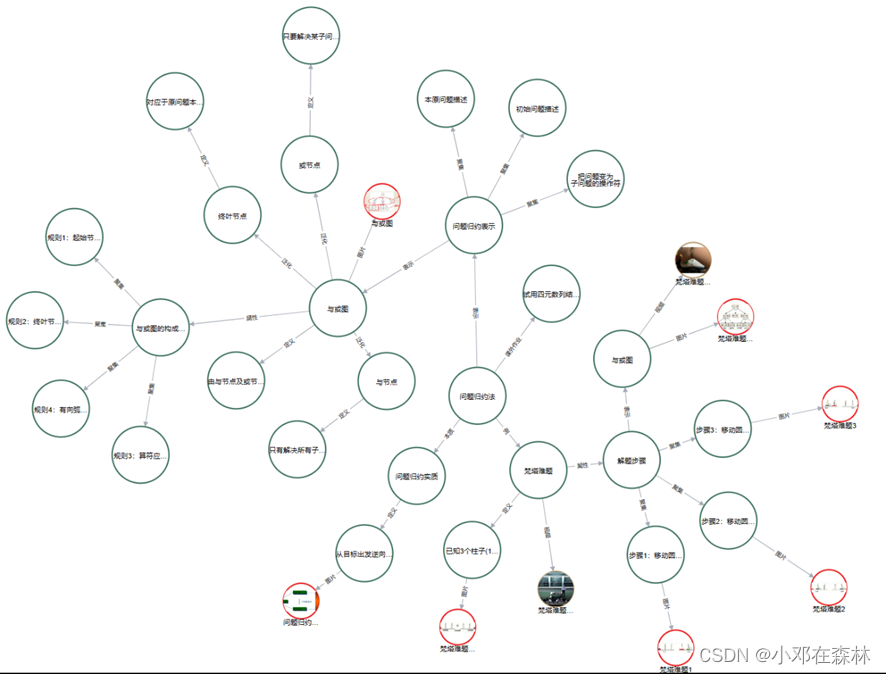
所建问题归约法知识图谱共有 37 个节点,36 个关系,通过上课内容将不同文本通过 csv 文件构建节点,同时通过 csv 文件构建文本之间的关系。本知识图谱共有 10 类关系,分别是:属性、定义、例子、表示、聚集、泛化、课外作业、本质、图片以及视频。从节点“问题归约法”出发,通过箭头“→”不断拓展进而总结出本次问题归约法课程所学知识。
3.3 知识图谱的评价
3.3.1 有效性
对知识图谱中的实体和关系进行抽样,对其进行人工验证,以确保其准确性。使用基准数据集或标准测试集进行验证,以评估知识图谱的性能和有效性。测试知识图谱在实际应用中的效果,例如,将其应用于自然语言处理或智能搜索等领域,以评估其效果和质量。3.3.2. 完整性
对领域中的实体和关系进行全面调研,以确保知识图谱的完整性。对知识图谱进行抽样,比对其与领域中的已知实体和关系,以评估其完整性。分析知识图谱中的节点度分布,以确定是否存在孤立节点或异常节点,以评估其完整性。3.3.3. 准确性
对知识图谱中的实体和关系进行抽样,对其进行人工验证,以确保其准确性。比对知识图谱中的实体和关系与领域中已知的数据源,以评估其准确性。分析知识图谱中的错误节点和边缘,对其进行纠错和优化,以提高其准确性。3.3.4. 一致性
比对知识图谱中的实体和关系与其他数据源,以评估其一致性。分析知识图谱中的重复节点和边缘,对其进行去重和合并,以提高其一致性。3.3.5. 可用性
对知识图谱进行可视化和交互设计,以提高其用户体验和可用性。提供API或查询接口,以便其他应用程序能够访问和使用知识图谱中的数据。提供文档和教程,以帮助用户了解和使用知识图谱。除了上述提到的指标和方法外,还有一些其他的评价知识图谱的方法和工具,例如:
知识图谱质量评估工具:可以自动化地评估知识图谱的质量和完整性,例如,使用基准数据集进行自动化测试和验证,以评估知识图谱的准确性和完整性。知识图谱可视化工具:可以帮助用户更好地理解和探索知识图谱中的数据,例如,使用图形化界面展示知识图谱中的节点和边缘,以便用户更好地理解知识图谱中的数据。知识图谱查询工具:可以帮助用户在知识图谱中进行复杂的查询和分析,例如,使用SPARQL 或 Cypher 等查询语言,以便用户能够更好地了解知识图谱中的数据和关系。知识图谱应用评估工具:可以评估知识图谱在实际应用中的效果和质量,例如,使用自然语言处理或智能搜索等技术,以评估知识图谱在这些应用中的效果和性能。 经过检验,发现可用性不好,对于图像API接口,由于百度网盘每隔一段时间会更改链接网址,导致之后再次运行会不显示图像,解决方法是查询时会返回总的链接,供用户查看;或者寻找其他更稳定的接口来实现!
4. 知识图谱的应用
自然语言处理:可以使用知识图谱中的实体和关系来解决自然语言处理中的命名实体识别、实体关系抽取等问题,例如,使用知识图谱中的实体和关系来解析文本中的实体和关系,以便更好地理解和分析文本内容。智能搜索:可以使用知识图谱中的实体和关系来优化搜索结果,例如,使用知识图谱中的实体和关系来扩展搜索范围,以便更全面地搜索相关内容。语义推理:可以使用知识图谱中的实体和关系来进行语义推理,例如,使用知识图谱中的实体和关系来推断未知的实体和关系,以便更好地理解和分析数据。数据挖掘和分析:可以使用知识图谱中的实体和关系来进行数据挖掘和分析,例如,使用知识图谱中的实体和关系来发现潜在的关联和模式,以便更好地理解和分析数据。智能问答:可以使用知识图谱中的实体和关系来回答用户的问题,例如,使用知识图谱中的实体和关系来推断答案,以便更准确地回答用户的问题。当然这些应用最终融合进一个可视化系统是最好的,但由于缺乏相关前端开发知识,因此现时无法真正将上述应用前端化,只能提出一些想法。
5. 总结
构建知识图谱需要多个领域的专业知识,包括数据管理、数据建模、图数据库、自然语言处理、机器学习和人工智能等。成功构建一个知识图谱需要仔细的规划和设计,并需要不断进行优化和更新,以反映领域知识的变化。
通过这次实验,我学会了如何用 NEO4J 构建知识图谱,加深了知识图谱一些概念的记忆,了解了 Cypher 的语法使用。
6. 相关代码文件资源
资源地址:用NEO4J平台构建一个《人工智能引论》课程的多模态知识图谱相关代码与文件