在AI的浪潮之巅,一款名为SQLCoder-7b的模型在huggingface上震撼发布,它不仅在文本转SQL生成上与GPT-4平分秋色,更在数据处理的速度和准确性上实现了惊人突破,甚至有超越GPT-4的势头。
更多内容迁移到知乎,感谢的关注:https://www.zhihu.com/people/dlimeng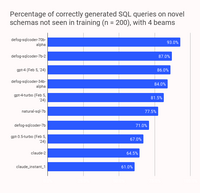
然而,让人好奇的是,这款模型究竟是如何实现这一飞跃的?它的秘密武器究竟是什么?
模型特点
你是否曾为理解SQL数据库中的数据而感到困惑?现在有了SQLCoder-7B-2和SQLCoder-70B-Alpha模型,这些问题将迎刃而解。这两个强大的工具专为非技术用户设计,让他们能够轻松分析数据库内容,无需深厚的专业知识。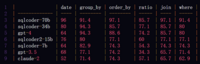
令人振奋的是,SQLCoder-70B-Alpha在文本到SQL的转换能力上超越了包括GPT-4在内的所有通用模型。这意味着它能更准确地理解你的需求,并生成相应的SQL查询。同时,SQLCoder-7B-2也是一个不容忽视的佼佼者,它在自然语言到SQL的生成上表现出色。
但请注意,这些模型仅适用于只读访问权限的用户。为了确保数据的安全性,它们并未被训练来应对恶意写请求。
开源精神是推动技术发展的重要动力。SQLCoder2和SQLCoder-7B模型已经向公众开放,让更多人能够受益于它们的能力。其中,SQLCoder2在原始SQLCoder的基础上进行了重大改进,而SQLCoder-7B则以7B参数的模型身份亮相,性能与前者不相上下。
这一切的背后,是开发团队对用户反馈的深度理解和持续改进。他们发现原始SQLCoder在处理日期时间函数时存在困难,有时还会生成错误的列名或表名。同时,社区对能够在小GPU上运行的模型有着巨大需求。于是,SQLCoder2和SQLCoder-7B应运而生,它们不仅解决了这些问题,还更适合生产环境。
SQLCoder如何评估出高准确率的AI模型的?
评估与表现
SQLCoder对每个生成的问题进行了分类,共分为6大类别。接下来的表格将为您展示每个模型在各类别问题中的正确回答率。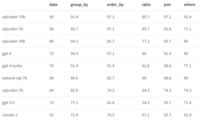
数据海洋里,SQL是捕鱼的网。LLM生成的SQL靠不靠谱?SQL-Eval来评判!
SQL-Eval,听名字就知道它的使命:评估LLM生成的SQL语句的正确性。在开发过程中,开发者们常常陷入一个困境:如何判断一个SQL查询是否“正确”?毕竟,对于同一个问题,可能存在多种正确的SQL写法。
举个例子,如果你想找出最近10位来自多伦多的用户,以下两个查询都是正确的:
1.查询A抓取了用户的ID、用户名和创建时间;
2.查询B则选择了用户的ID、全名和创建时间。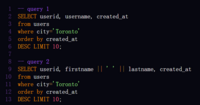
评估方法揭秘
1.展开标准查询的列组合。
2.对每个组合运行查询,得到结果数据框。
3.比较生成查询的结果与标准结果,一致则正确。
SQL-Eval考虑列别名、额外列等变体,确保评估准确。它已在GitHub上开源,等你来体验!
https://github.com/defog-ai/sql-eval
如何快速入门SQLCoder-7b
提示词格式:
### TaskGenerate a SQL query to answer [QUESTION]{user_question}[/QUESTION]### Database SchemaThe query will run on a database with the following schema:{table_metadata_string_DDL_statements}### AnswerGiven the database schema, here is the SQL query that [QUESTION]{user_question}[/QUESTION][SQL]使用环境
? 示例:https://colab.research.google.com/drive/1z4rmOEiFkxkMiecAWeTUlPl0OmKgfEu7
? 演示:https://defog.ai/sqlcoder-demo/
? 模型:https://huggingface.co/defog/sqlcoder-7b-2
? Github:https://github.com/defog-ai/sqlcoder/
结语
SQLCoder-7b的崛起,不仅是一次技术的飞跃,更是对数据洞察民主化的重要一步。
欢迎关注留言交流!
我是李孟聊AI,独立开源软件开发者,SolidUI作者,对于新技术非常感兴趣,专注AI和数据领域,如果对我的文章内容感兴趣,请帮忙关注点赞收藏,谢谢!