
自 5 月 18 日发布并开源 VisualGLM-6B 以来,智谱AI&清华KEG潜心打磨,致力于开发更加强大的多模态大模型。
基于对视觉和语言信息之间融合的理解,我们提出了一种新的视觉语言基础模型 CogVLM。CogVLM 可以在不牺牲任何 NLP 任务性能的情况下,实现视觉语言特征的深度融合。
我们训练的 CogVLM-17B 是目前多模态权威学术榜单上综合成绩第一的模型,在14个数据集上取得了state-of-the-art或者第二名的成绩。

我们可以初步体验 CogVLM 的效果:

在上图中,CogVLM 能够准确识别出 4 个房子(3个完整可见,1个只有放大才能看到);作为对比,GPT-4V 仅能识别出其中的 3 个。
为促进多模态基础模型领域的研究和工业应用,我们将 CogVLM-17B 开源出来,且提供了单台 3090 服务器即可运行的微调代码,供大家研究和使用。
Github:https://github.com/THUDM/CogVLM
Huggingface:https://huggingface.co/THUDM/CogVLM
魔搭社区:https://www.modelscope.cn/models/ZhipuAI/CogVLM
Paper:https://github.com/THUDM/CogVLM/blob/main/assets/cogvlm-paper.pdf
一、模型架构
CogVLM 之所以能取得效果的提升,最核心的思想是“视觉优先”。
之前的多模态模型通常都是将图像特征直接对齐到文本特征的输入空间去,并且图像特征的编码器通常规模较小,这种情况下图像可以看成是文本的“附庸”,效果自然有限。
而CogVLM在多模态模型中将视觉理解放在更优先的位置,使用5B参数的视觉编码器和6B参数的视觉专家模块,总共11B参数建模图像特征,甚至多于文本的7B参数量。
CogVLM 的结构如下所示:
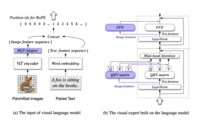
模型共包含四个基本组件:ViT 编码器,MLP 适配器,预训练大语言模型(GPT-style)和视觉专家模块。
ViT编码器:在 CogVLM-17B 中,我们采用预训练的 EVA2-CLIP-E。
MLP 适配器:MLP 适配器是一个两层的 MLP(SwiGLU),用于将 ViT 的输出映射到与词嵌入的文本特征相同的空间。
预训练大语言模型:CogVLM 的模型设计与任何现有的 GPT-style的预训练大语言模型兼容。具体来说,CogVLM-17B 采用 Vicuna-7B-v1.5 进行进一步训练;我们也选择了 GLM 系列模型和 Llama 系列模型做了相应的训练。
视觉专家模块:我们在每层添加一个视觉专家模块,以实现深度的视觉 - 语言特征对齐。具体来说,每层视觉专家模块由一个 QKV 矩阵和一个 MLP 组成。
模型在15亿张图文对上预训练了4096个A100*days,并在构造的视觉定位(visual grounding)数据集上进行二阶段预训练。在对齐阶段,CogVLM使用了各类公开的问答对和私有数据集进行监督微调,使得模型能回答各种不同类型的提问。
二、模型效果
为了更为严格地验证CogVLM的性能和泛化能力,我们在一系列多模态基准上进行了定量评估。这些基准大致分为三类(共 14 个),包括图像字幕(Image Captioning)、视觉问答(Visual QA)、视觉定位(Visual Grounding)。
在这些基准当中,CogVLM-17B 在 10 项基准中取得 SOTA性能,而在另外四项(包括 VQAv2, OKVQA, TextVQA, COCO captioning等)取得第二的成绩。整体性能超越或匹配谷歌的PaLI-X 55B。
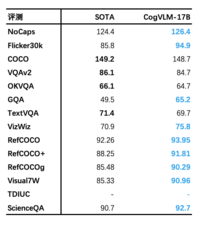
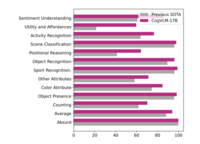
CogVLM 在 10 项评测中取得SOTA效果,4项评测仅次于SOTA。第二张图为 TDIUC 基准评测效果。
此外,我们可以通过几个简单的示例,对比最近比较受关注的 MiniGPT-4、LLaVA-v1.5,可以看出,CogVLM-17B在图像理解、模型幻觉以及文本识别方面都具有不错的效果。
———— 示例 1 ————
GPT-4 vsion中的一个著名例子。目前主流的开源的模型包,括知名的MniGPT-4和最近发布的 LLAVA 1.5,均不能理解该视觉场景的有趣之处,而CogVLM则精准地说出VGA接口充电不合常理。

———— 示例 2 ————
这张图片内容较为复杂,是日常生活的场景。CogVLM精准地说出来所有的菜肴和餐具的种类,并且判断出了镜子(“许多动物甚至不能理解镜子”)是反射而并非真实,且注意到了角落的人的腿。整个复杂的描述中未出现错误与幻觉。相对地,MiniGPT-4和LLaVA-1.5都出现了幻觉现象且不够全面。

———— 示例 3 ————
带文字的图片。CogVLM忠实地描述了场景和相应的文字,而其他模型没有输出文字且有大量幻觉。

三、研究者说
问:CogVLM和VisualGLM之间有什么关联和不同?
答:CogVLM延续了VisualGLM的研究,但进行了较大尺度的改进。首先体现在多模态融合的技术上,CogVLM采用了最新的图像和文本信息融合的方案,在我们文章中已经有相关的说明。其次,VisualGLM 是一个依赖于具体语言模型的多模态模型,而CogVLM则是一个更广阔的系列,不仅有基于GLM的双语模型,也有基于Llama2系列的英文模型。这次开源的 17B 模型就是基于Vicuna-7B 的英文模型。其实我们内部也训练完成了更大的英文模型和基于GLM的双语模型,后面可能也会开源出来。
问:VisualGLM-6B 模型中视觉相关的参数仅为 1.6B,而作为对比,CogVLM-17B 的视觉相关参数达到了 11 B(甚至超过了语言模型的 7B 参数)。为什么要采用更大视觉参数的方式?
答:首先,通过大量的实验,我们得出一个结论,即更大的参数量对视觉多模态模型很重要。
之前有观点认为视觉不需要大模型。因为人们在一些传统的数据集(例如ImageNet-1k等)上做的验证,发现模型变大对性能的提升似乎并不是很大。但之所以出现这个现象,原因在于传统数据集大部分的测试样例太简单了,小的模型足以应对这样的问题。
然而人类世界中视觉模型需要认识的事物远远不止几千、几万类,例如各种品牌商标、名人相貌、地点、动植物品类、商品品类等,小模型不可能记住;同时在这种“开放词典”的设定下,由于可能类别增加,出错的概率也会上升。我们做了一些实验,发现对于这些真实场景中的问题,模型变大往往会带来非常明显的效果提升。
当然,还有一个原因是,之前的视觉大模型往往都是闭源的,大部分很难真正地体验模型大小所带来的性能区别。也是基于此,虽然 CogVLM在性能上已经超过一众大公司的闭源模型(例如PaLI、PaLM-E、BEiT-3、GIT2等),但我们依然选择像 VisualGLM一样,把它开源出来。我们希望能通过开源来进一步地促进多模态模型在研究和工业应用方面的发展。
问:我们在使用图文理解模型的时候,模型经常会给出一些图片中并没有包含的信息。请问该如何减少模型的这种幻觉呢?
答:模型有幻觉,根源还是在于模型能力不足。
之前的多模态模型,无论是MiniGPT-4、VisualGLM-6B还是LLaVA,经常会在描述时说一些明显不存在于图像中的物体或者错误的颜色。本质还是模型无法识别某些特别的视觉表示,从而遵循先验输出在该场景中的常见物体。
在这方面,我们通过特定的微调,对不确定的物体,模型会输出“不清楚”,以此来减少幻觉现象,从而提高用户体验。当然这并不能彻底消除幻觉,但可以大大降低幻觉出现的频次。另外一个有效的解决幻觉的方法,就是用更大的参数,以及更多的训练量。经过这两种方案,CogVLM 的幻觉已经降到一个比较低的水平。
问:从CogView、CogVideo到VisualGLM、RDM、CogVLM等,你的工作一直推动图片理解、视频理解,图片生成,视频生成。你为什么要坚持做多模态的基座模型呢?
答:无论是现实还是虚拟的界面的感知、交互,主要以视觉等为媒介。现在的大语言模型虽然有智能的涌现,但是仍然被关在“笼子”里,它与这个世界是割裂的。一个完整的智能agent,必然是多模态的理解。多模态理解是智能发展和应用的必由之路。也正是基于同样的理解,智谱AI,希望能够在这个方向上趟出一条路来。