
目录
一.引言
二.视频处理
1.视频样式
2.视频截取
◆ 裁切降帧
◆ 处理效果
3.视频分段
三.OCR 处理
1.视频帧处理
2.文本识别结果
3.后续工作与优化
◆ 识别去重
◆ 多线程提效
◆ 片头片尾优化
四.总结
一.引言
视频经常会配套对应的台词或者字幕,通过文本与字幕可以更好地理解视频内容。本文介绍如何使用 moviepy 库处理视频并使用 paddleocr 库实现视频文本识别,从而获取视频中出现的文字信息。
二.视频处理
1.视频样式
样例中我们以老电视剧 <三国演义> 为例,处理其剧集信息并获取对话文本。

视频中字幕展示位置位于视频正下发居中位置,为了减少 OCR 的识别工作量,提高 OCR 识别成功率,我们会优先对视频截取,只保留下方台词部分的关键帧信息。
2.视频截取
◆ 裁切降帧
from moviepy.editor import * # 对视频进行裁剪与缩放 clip = VideoFileClip('/Users/Desktop/1.mkv') print("Ori FPS:{} Duration:{} Height:{} Width:{}".format(clip.fps, clip.duration, clip.w, clip.h)) cut_clip = clip.crop(y2=clip.h - 11, height=70) cut_clip = cut_clip.set_fps(3) print("Cut FPS:{} Duration:{} Height:{} Width:{}".format(cut_clip.fps, cut_clip.duration, cut_clip.w, cut_clip.h))- VideoFileClip
电影文件的视频剪辑类,必传的只有 filename 即视频文件的名称。它支持多种视频格式: .ogov、.mp4、.mpeg、.avi、.mov、.mkv 等。这里下载的 <三国演义> 使用的是 .mkv 格式。
- crop
crop 方法用于裁切视频。x1、y1 代表裁剪区域的左上角坐标。默认为视频的左上角;x2、y2 代表裁剪区域的右下角坐标。默认为视频的右下角。width,height 代表裁剪区域的宽度和高度。如果设置了这两个参数,x2、y2 的值将被忽略。center 代表裁剪区域的中心点坐标,如果设置了这个参数,x1、y1、x2、y2 的值将被忽略。所有坐标值都是以像素为单位的。当剪辑是图像剪辑时,可以进一步通过指定参数来优化裁剪效果。上面的参数含义表示将 clip 视频的底部向上 11 个像素开始裁剪,向上裁剪出 70 个像素高度的新片段,获得剪辑后的新视频。
- set_fps
set_fps 参数是用于设置帧率的。帧率是指在视频中每秒钟展示多少个连续的画面,单位是 fps(frames per second),译为 '每秒帧数'。如果你想让视频播放得更流畅,可以将帧率设置得更高。原始视频帧率较高 FPS=25,由于 OCR 识别相同帧内容可能相同,所以我们 set_fps(3) 以降低需要处理的视频帧数量,提高效率。
◆ 处理效果

Ori FPS:25.0 Duration:2625.36 Height:704 Width:528Cut FPS:3 Duration:2625.36 Height:704 Width:70通过打印视频关键信息,我们得到裁切后的视频参数,可以看到新的视频宽度已缩减,且 FPS 帧率也下降为每秒 3 帧:

这里不同视频字母位置不同,大家可以本地测试几次,就能大致选到合适的位置参数。
3.视频分段
epoch = 10 step = cut_clip.duration / epoch # 截取多个片段 clips = [] index = 0 while index < epoch: # 获取分段的起止时间 start = index * step end = min(start + step, clip.duration) if start < clip.duration: sub_clip = cut_clip.subclip(start, end) print("index: {} start: {} end: {}".format(index, start, end)) clips.append([start, sub_clip]) else: break index += 1为了并发处理视频帧,我们可以将视频分为多段 cut,每一个 cut 启动一个 Process 进行 OCR 识别,所以我们通过 subclip 方法对视频进行了分段截取。这里 start、end 对应视频的秒数,通过 clip.duration 可以获取视频的总长,自定义分段数即可,这里我们划分 10 段:
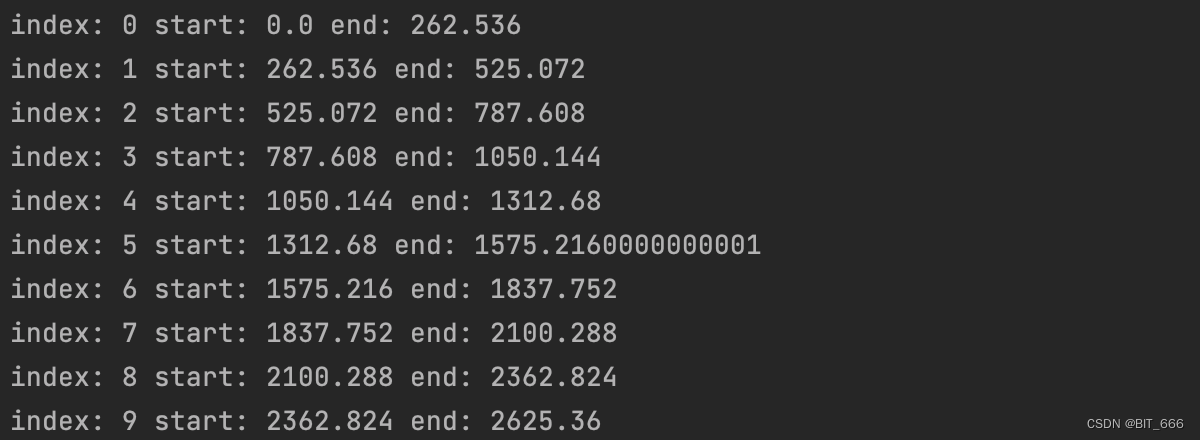
可以通过 save 方法将每个分段保存到目录下供本地检查和校对:
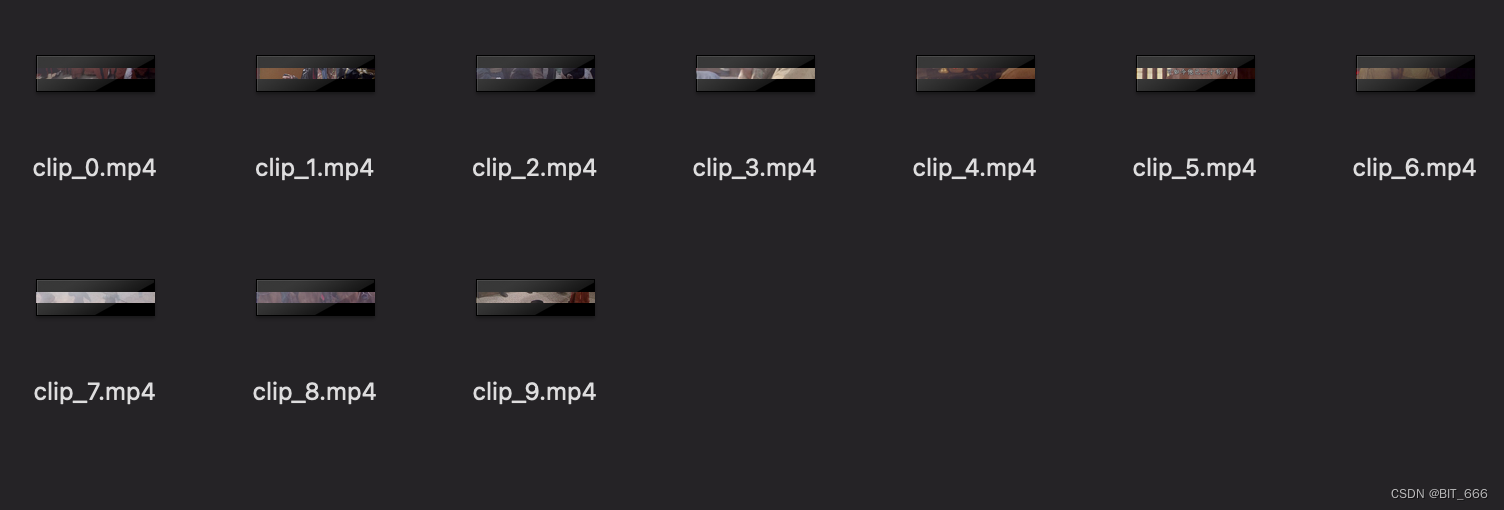
三.OCR 处理
1.视频帧处理
from paddleocr import PaddleOCR def process_frame_by_ocr(st, tmp_clip): ocr = PaddleOCR(use_angle_cls=True, lang="ch", use_gpu=True) frame_rate = 1 / 3 for cnt, cur_frame in enumerate(tmp_clip.iter_frames()): cur_start = frame_rate * (cnt + 1) + st try: # det=True 表示在进行光学字符识别(OCR)之前,先对图像进行检测。 result = ocr.ocr(cur_frame, det=True) if result is not None: see = result[0][0][1] cur_time = int(cur_start) doc_json = {'st': cur_time, "text": see} ocr_text = json.dumps(doc_json, ensure_ascii=False) open('result.json', 'a', encoding='utf-8').write(ocr_text + '\n') except Exception: pass这里引入 paddleocr 库进行视频帧的 OCR 文字识别,由于我们修改刷新率 FPS=3,所以每 s 有3帧视频,这里通过 frame_rate 记录每一帧出现的时间,其次调用 .ocr 方法识别图像,如果 result 识别到字幕即 text,我们会 'a' 添加至我们的 result.json 中并记录该台词出现的时间。下图为运行日志,由于识别过程中可能存在无字幕的情况,针对这类情况直接 pass:
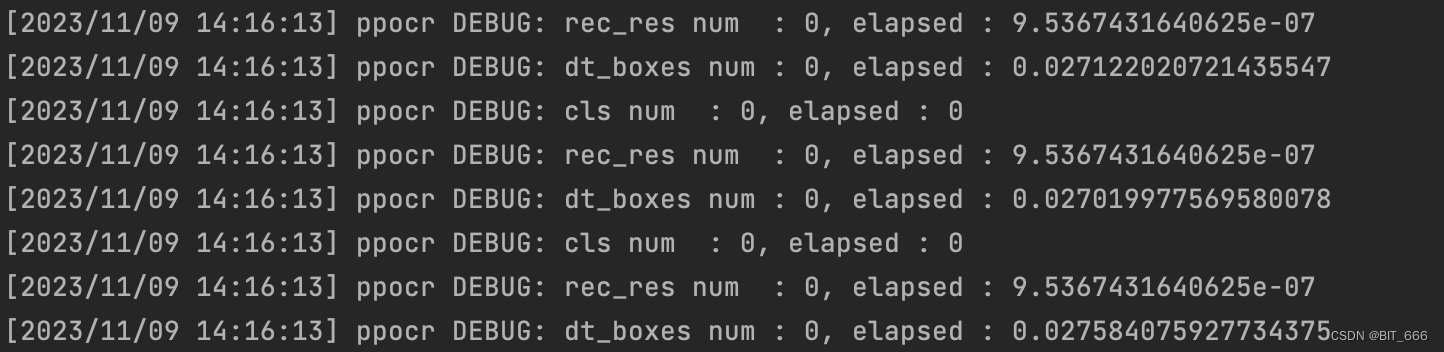
2.文本识别结果

result.json 中会保存字幕在视频中出现的对应时间,text 除了识别内容外,还有一个概率标识其置信度,置信度越高,识别效果越靠谱。

3.后续工作与优化
◆ 识别去重
我们看到,虽然设置了 FPS=3,但是重复的文本还是很多,在得到原始的 result.json 文件后,我们还需要对文件进行去重和优选的步骤,一方面我们可以根据时间先后和字符长度,选择更为完整的句子,另一方面我们可以标胶不同识别结果的置信度,我们可以取数值更高置信度更高的样本作为最终结果。
◆ 多线程提效
我们可以尝试使用 multiprocessing 多线程处理多个分段任务,这里处理一集大约耗时为 5 min,采用多线程可以大大提高处理的效率。
[2023/11/09 14:14:15] ppocr DEBUG: rec_res num : 0, elapsed : 1.1920928955078125e-06...[2023/11/09 14:19:30] ppocr DEBUG: rec_res num : 0, elapsed : 0.0
◆ 片头片尾优化
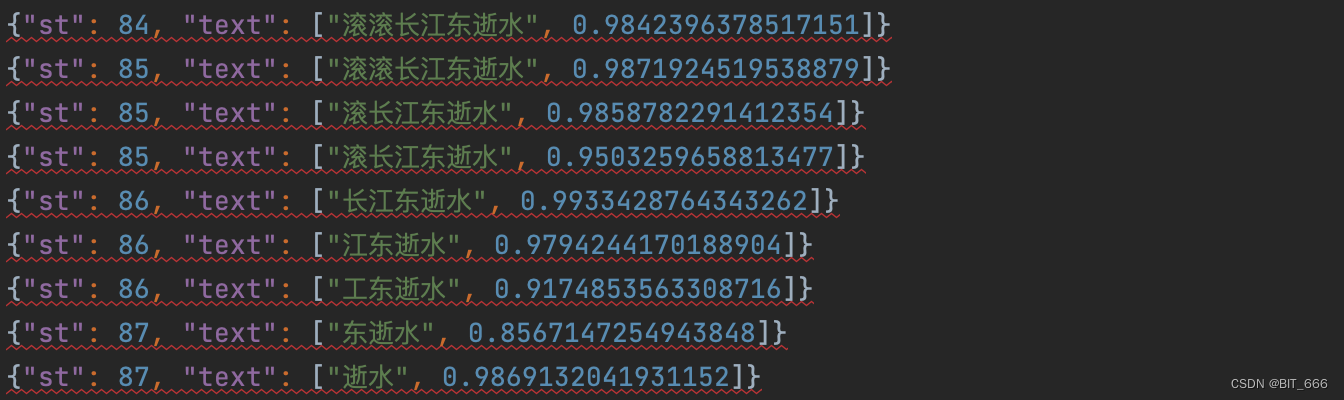
查看 result.json 的前端部分可以看到类似的滚动识别字幕,这是因为片头曲的滚动字幕造成的。我们可以像视频 APP 那样掐头去尾,获取更纯净的视频内容。这与片头片尾时间,最简单的就是我们打开视频掐一下,转换成 s 单位即可。

四.总结
本文介绍了基本的视频截取与识别的方法,就功能性而言,其实现了基本的功能。但是就结果而言,如果想要获取一些传统剧集的字幕与时间,我们可以直接到对应的字幕网站或者解析视频自带的字幕 SRT 文件,肥肠的方便:
