1、安装pdfjs-dist插件,推荐使用2.0.943这个版本
npm install pdfjs-dist@2.0.9432、页面中引入使用
import PDFJS from 'pdfjs-dist'// 文本视图,可复制import { TextLayerBuilder } from 'pdfjs-dist/web/pdf_viewer'import 'pdfjs-dist/web/pdf_viewer.css'PDFJS.workerSrc = require('pdfjs-dist/build/pdf.worker.min')3、页面标签
<div class="pdfContainer"> <div class="pdfOprate"> <!-- 当前页码/页码总数 --> <span class="pdfCount"> <span class="pdfPage">{{pdfPage}}</span> / <span class="pdfPageTotal">{{pdfTotalPages}}</span> </span> </div> <!-- pdf视图 --> <div class="pdfBody" @scroll="pdfScroll($event)"> <div id="pdfBox"> <!-- pdf内容,图片和文本视图 --> <!-- <div class="divBox"> <canvas ></canvas> <div class="textLayer"></div> </div> --> </div> </div></div>3、解析pdf,获取pdf所有页数据,使用canvas渲染,并使用TextLayerBuilder创建文本层,可以复制文本信息
// 使用pdf.js加载和显示PDF文件previewPdf(file){ var that=this const fileReader = new FileReader(); fileReader.onload = function() { const typedArray = new Uint8Array(this.result); // 调用pdf.js的API加载PDF文件 PDFJS.getDocument(typedArray).promise.then(async function(pdf) { that.viewPdfObject=pdf // 获取PDF的总页数 const numPages = pdf.numPages; // 渲染当前显示页码和总页数 this.pdfPage=1 this.pdfTotalPages=numPages const pdfBox = document.getElementById("pdfBox"); // 循环绘制每个页面 for (let pageNum = 1; pageNum <= numPages; pageNum++) { // 获取指定页数据 let page = await pdf.getPage(pageNum) // 获取视图 1是倍率,按照pdf解析出来的原始宽高 const viewport = page.getViewport(1) const divBox=document.createElement("div") divBox.className="divBox" pdfBox.appendChild(divBox) const canvasElement=document.createElement("canvas") const context = canvasElement.getContext("2d"); canvasElement.width = viewport.width; canvasElement.height = viewport.height; divBox.appendChild(canvasElement) // 渲染指定页的内容到canvas上 // 如果你只是展示pdf而不需要复制pdf内容功能,则可以这样写render // page.render({canvasContext: context,viewport}) // 需要复制内容就使用下面的渲染方式 var textContent=await page.render({ canvasContext: context, viewport }).then(() => { return page.getTextContent(); }) // 创建文本图层div const textLayerDiv = document.createElement('div') textLayerDiv.className="textLayer" textLayerDiv.setAttribute('class', 'textLayer') textLayerDiv.setAttribute('style', 'margin:auto;'+'width:'+viewport.width+'px;'+'height:'+viewport.height+'px') // 将文本图层div添加至每页pdf的div中 divBox.appendChild(textLayerDiv) // 创建新的TextLayerBuilder实例 let textLayer = new TextLayerBuilder({ textLayerDiv: textLayerDiv, pageIndex: page.pageIndex, viewport: viewport }) textLayer.setTextContent(textContent) textLayer.render() } }) } fileReader.readAsArrayBuffer(file);},在渲染pdf数据时,当pdf文件很大渲染量很多时,会导致页面卡住,无法执行其他操作;这涉及到队列优先级问题: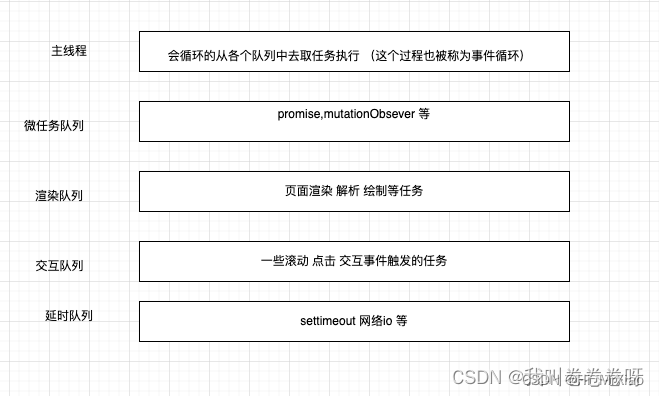
在这里就是因为微任务导致,所以我们这里渲染pdf任务可以每次渲染完一页后等待一定时间才执行下一页的渲染,空出时间给主线程
// 将渲染pdf的代码休眠一定时间,留给主线程sleep(time){ return new Promise((resolve) => { setTimeout(() => { resolve(time) }, time) })},// 创建一个延时队列的任务 主进程会执行渲染队列任务后在执行延时队列任务等待延时,后再创建渲染pdf下一页的微任务(在循环代码的最后使用)await that.sleep(100)在滚动时当前是第几页的页码同步更新展示:需要在渲染每页pdf时将每页的高度存起来,以及每页滚动的临界值
// 每页累加的高度this.scrollHeight=[0]// 每页滚动切换值的临界滚动距离this.scrollHalfHeight=[0]this.heightAll=0$(".pdfBody canvas").each(function (i) {// 滚动到前一页高度的70%,即页码自动更改为下一页 that.heightAll+=this.height*that.zoom*0.7 that.scrollHalfHeight.push(that.heightAll) that.heightAll+=this.height*that.zoom*0.3 that.scrollHeight.push(that.heightAll)})在滚动时,根据当前滚动距离和每页滚动的临界距离相比较,判断当前是第几页
pdfScroll(e){ var pdfBody=document.querySelector(".pdfBody") for (let i=0;i<this.scrollHeight.length;i++){ // 在滚动时,根据当前滚动距离和每页滚动的临界距离相比较,判断当前是第几页 if(pdfBody.scrollTop>=this.scrollHeight[i]&&pdfBody.scrollTop<this.scrollHeight[i+1]){ if (this.pdfPage!=i+1){ this.pdfPage=i+1 } } }}效果如下