哈喽大家好 ! 我是唐宋宋宋,很荣幸与您相见!!
学习目标
目标
什么是正则化?
为什么需要正则化?
什么是过拟合?
了解L1,L2正则化
知道Droupout正则化的方法
了解早停止法、数据增强法的其它正则化方式
总结
什么是正则化?
Regularization,中文翻译过来可以称为正则化,或者是规范化。什么是规则?闭卷考试中不能查书,这就是规则,一个限制。同理,在这里,规则化就是说给损失函数加上一些限制,通过这种规则去规范他们再接下来的循环迭代中,不要自我膨胀。(记住这是重点概念!!!)
为什么需要正则化?
我们首先回顾一下模型训练的过程,模型参数的训练实际上就是一个不断迭代,寻找到一个方程
来拟合数据集。我们需要一个最好的拟合方式来进行预测,那么如何进行拟合呢或者拟合会出现什么问题呢,我们来看一下下面这张图。
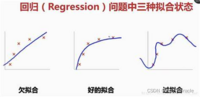
第一张,首先我们看到这条线并没有很好的拟合我们的数据,训练的时候效果不好,可想而知验证效果肯定也是很差的
第三张,我们看到这条线曲曲折折,我们的每一个数据都有一个很好的拟合,我们知道训练过程中会有很多噪声,对于数据有一定的影响,这样的一条线并不能对于我们后续的数据进行一个准确的预测,并且模型太过复杂,总之对我们的回归模型它丧失了一个预测能力。
第二张,我们可以看到数据有一个很好的预测,并且能够直观的预测函数的走向。虽然它在测试集的中准确列不及图三高,但在测试集中我们得到的准确率是最高的,同时泛化能力也是最强的。
我们记住一点正则化的作用就是为了解决我们一个过拟合的问题。
什么是过拟合?
那我们就要说一下什么是过拟合,过拟合”是指机器学习在训练模型时,模型与训练数据贴合的太好了,好到误差基本接近于0了,如图:
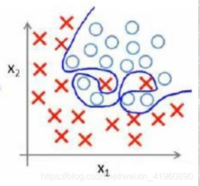
过拟合”会导致模型的“泛化“”能力太差,那什么是“泛化“”能力呢?说的再通俗点,就是模型的通用能力,训练的模型如果只能适用于某种特定的即为苛刻条件,那么这个模型可用的范围,所能承受的抗干扰性(术语叫做鲁棒性)就太差了…
所以为了 防止模型出现“过拟合”的现象,于是就提出了“正则化”这一概念。
了解L1,L2正则化
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,称作 L1正则化 和 L2正则化,或者 L1范数 和 L2范数,是为了限制模型的参数,防止模型过拟合而加在损失函数后面的一项。
区别:
L1是模型各个参数的绝对值之和。
L2是模型各个参数的平方和的开方值。
L1会趋向于产生少量的特征,而其他的特征都是0。
因为最优的参数值很大概率出现在坐标轴上,这样就会导致某一维的权重为0 ,产生稀疏权重矩阵
L2会选择更多的特征,这些特征都会接近于0。
最优的参数值很小概率出现在坐标轴上,因此每一维的参数都不会是0。当最小化||w||时,就会使每 一项趋近于0。
参数正则化作用:
L1: 为模型加入先验, 简化模型, 使权值稀疏,由于权值的稀疏,从而过滤掉一些无用特征,防止过拟合
L2: 根据L2的特性,它会使得权值减小,即使平滑权值,一定程度上也能和L1一样起到简化模型,加速训练的作用,同时可防止模型过拟合
知道Droupout正则化的方法
加入了 dropout 后,输入的特征都存在被随机清除的可能,所以该神经元不会再特别依赖于任何一个输入特征,也就是不会给任何一个输入特征设置太大的权重。通过传播过程,dropout 将产生和 L2 正则化相同的收缩权重的效果。
调试时候使用技巧:
dropout 的缺点是成本函数无法被明确定义,保证损失函数是单调下降的,确定网络没有问题,再次打开droupout才会有效。

了解早停止法、数据增强法的其它正则化方式
早停止法

通常不断训练之后,损失越来越小。但是到了一定之后,模型学到的过于复杂(过于拟合训练集上的数据的特征)造成测试集开始损失较小,后来又变大。模型的w参数会越来越大,那么可以在测试集损失减小一定程度之后停止训练。
如图箭头位置给停掉。
数据增强
指通过剪切、旋转/反射/翻转变换、缩放变换、平移变换、尺度变换、对比度变换、噪声扰动、颜色变换等一种或多种组合数据增强变换的方式来增加数据集的大小。

即使卷积神经网络被放在不同方向上,卷积神经网络对平移、视角、尺寸或照度(或以上组合)保持不变性,都会认为是一个物体。
数据增强的方法有一些传统的平移,旋转,仿射变换等,还有mosaic数据增强,自适应描框等,目的就是为了增加我们数据的多样性来防止对于数据的拟合。
总结:
欠拟合:泛化能力差,训练样本集准确率低,测试样本集准确率低。
过拟合:泛化能力差,训练样本集准确率高,测试样本集准确率低。
合适的拟合程度:泛化能力强,训练样本集准确率高,测试样本集准确率高
欠拟合原因:
训练样本数量少
模型复杂度过低
参数还未收敛就停止循环
欠拟合的解决办法:
增加样本数量
增加模型参数,提高模型复杂度
增加循环次数
查看是否是学习率过高导致模型无法收敛
过拟合原因:
数据噪声太大
特征太多
模型太复杂
过拟合的解决办法:
清洗数据
减少模型参数,降低模型复杂度
增加惩罚因子(正则化),保留所有的特征,但是减少参数的大小(magnitude)。
感谢大家阅读!???