文章目录
前言1. 数据集准备2. 划分数据集3. 生成datasets.txt文件4. 基于数据集制作训练的datasets.yaml文件
前言
平时我们在使用YOLOv5、YOLOv7官方模型进行魔改训练的时候,一般不会用到COCO2017等这样的大型数据集,一般是在自己的自定义数据集或者是一些小的开源数据集上进行调试,这时候就要涉及到数据集的问题。
这里我就VOC格式的数据集如何转成YOLO格式的数据集,如何写训练需要的datasets.yaml文件等问题进行探讨和分享。以我个人实际操作过程中的细节为例,如果有一些细节地方和数据文件位置等问题的,欢迎在评论区讨论交流。
另外YOLOv5、YOLOv7的代码是非常相似的(你懂的),所以两个网络中好多地方是可以互通的,因此在两个网络中制作数据集的操作是可以通用的,具体细节如文件夹地址等注意一下就okk。
【注】:文章中数据集划分以及操作问题是基于 <深度学习视觉-目标检测> 方向为基础,数据集用于YOLOv5/v7做图片目标检测。
1. 数据集准备
这里我划分的数据集是公共数据集,VOC2007trainval + VOC2012trainval。由于两个数据集数据量都很小,所以采用将两个数据集合并成一个数据集进行操作(可以看成是自定义的VOC格式的数据集),也就是之前论文上会遇见的VOC07+12数据集。
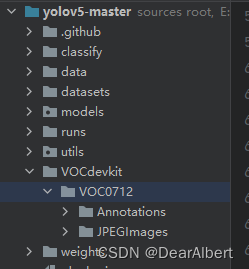
首先准备VOC07+12两个数据集,将两个数据集进行合并(直接将两个数据集的Annotations和JPEGImages两个文件夹中的内容进行合并即可),其中我们只需要Annotations标签文件夹,JPEGImages图片文件夹两个文件夹即可。VOC格式的数据集文件夹划分如下图所示。

基于划分数据集代码制作自己的数据集VOC0712(images-22136,labels-22136),将其放在yolo代码的根目录(也就是放到yolo项目里)下,这就是待划分的数据集文件(自定义数据集)。
【注】: VOC07+12数据集 的制作过程就是将上图VOC2007 + VOC2012中的Annotations和JPEGImages中的数据分别进行合并即可(ctrl+c、ctrl+v)
2. 划分数据集
在yolo根目录下创建voc_to_yolo.py脚本,即划分数据集的脚本。
VOC数据集有20个类,如果是自定义的数据集,需要将类classes进行修改。划分比率自己定,这里80表示 train :val = 8 : 2
voc_to_yolo.py"""# VOC数据集 转 YOLO数据集 格式"""import xml.etree.ElementTree as ETimport pickleimport osfrom os import listdir, getcwdfrom os.path import joinimport randomfrom shutil import copyfileclasses = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]# classes=["ball"]# 划分比率TRAIN_RATIO = 80def clear_hidden_files(path): dir_list = os.listdir(path) for i in dir_list: abspath = os.path.join(os.path.abspath(path), i) if os.path.isfile(abspath): if i.startswith("._"): os.remove(abspath) else: clear_hidden_files(abspath)# size是原图的宽和高def convert(size, box): dw = 1. / size[0] dh = 1. / size[1] x = (box[0] + box[1]) / 2.0 y = (box[2] + box[3]) / 2.0 w = box[1] - box[0] h = box[3] - box[2] x = x * dw w = w * dw y = y * dh h = h * dh return (x, y, w, h)def convert_annotation(image_id): in_file = open('VOCdevkit/VOC0712/Annotations/%s.xml' % image_id, 'rb') out_file = open('VOCdevkit/VOC0712/YOLOLabels/%s.txt' % image_id, 'w') tree = ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) for obj in root.iter('object'): difficult = obj.find('difficult').text cls = obj.find('name').text if cls not in classes or int(difficult) == 1: continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w, h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') in_file.close() out_file.close()wd = os.getcwd()data_base_dir = os.path.join(wd, "VOCdevkit/")if not os.path.isdir(data_base_dir): os.mkdir(data_base_dir)work_sapce_dir = os.path.join(data_base_dir, "VOC0712/")if not os.path.isdir(work_sapce_dir): os.mkdir(work_sapce_dir)annotation_dir = os.path.join(work_sapce_dir, "Annotations/")if not os.path.isdir(annotation_dir): os.mkdir(annotation_dir)clear_hidden_files(annotation_dir)image_dir = os.path.join(work_sapce_dir, "JPEGImages/")if not os.path.isdir(image_dir): os.mkdir(image_dir)clear_hidden_files(image_dir)# 这个部分可以不要yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")if not os.path.isdir(yolo_labels_dir): os.mkdir(yolo_labels_dir)clear_hidden_files(yolo_labels_dir)yolov5_images_dir = os.path.join(data_base_dir, "images/")if not os.path.isdir(yolov5_images_dir): os.mkdir(yolov5_images_dir)clear_hidden_files(yolov5_images_dir)yolov5_labels_dir = os.path.join(data_base_dir, "labels/")if not os.path.isdir(yolov5_labels_dir): os.mkdir(yolov5_labels_dir)clear_hidden_files(yolov5_labels_dir)yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")if not os.path.isdir(yolov5_images_train_dir): os.mkdir(yolov5_images_train_dir)clear_hidden_files(yolov5_images_train_dir)yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")if not os.path.isdir(yolov5_images_test_dir): os.mkdir(yolov5_images_test_dir)clear_hidden_files(yolov5_images_test_dir)yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")if not os.path.isdir(yolov5_labels_train_dir): os.mkdir(yolov5_labels_train_dir)clear_hidden_files(yolov5_labels_train_dir)yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")if not os.path.isdir(yolov5_labels_test_dir): os.mkdir(yolov5_labels_test_dir)clear_hidden_files(yolov5_labels_test_dir)# 这两个部分yolov5_train.txt, yolov5_val.txt可以不要train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')train_file.close()test_file.close()train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')list_imgs = os.listdir(image_dir) # list image_one filesprob = random.randint(1, 100)print("Probability: %d" % prob)for i in range(0, len(list_imgs)): path = os.path.join(image_dir, list_imgs[i]) if os.path.isfile(path): image_path = image_dir + list_imgs[i] voc_path = list_imgs[i] (nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path)) (voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path)) annotation_name = nameWithoutExtention + '.xml' annotation_path = os.path.join(annotation_dir, annotation_name) label_name = nameWithoutExtention + '.txt' label_path = os.path.join(yolo_labels_dir, label_name) prob = random.randint(1, 100) print("Probability: %d" % prob) if (prob < TRAIN_RATIO): # train dataset if os.path.exists(annotation_path): train_file.write(image_path + '\n') convert_annotation(nameWithoutExtention) # convert label copyfile(image_path, yolov5_images_train_dir + voc_path) copyfile(label_path, yolov5_labels_train_dir + label_name) else: # test dataset if os.path.exists(annotation_path): test_file.write(image_path + '\n') convert_annotation(nameWithoutExtention) # convert label copyfile(image_path, yolov5_images_test_dir + voc_path) copyfile(label_path, yolov5_labels_test_dir + label_name)train_file.close()test_file.close()运行脚本,在原数据集中生成如下文件:
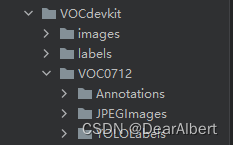
其中images、labels文件夹就是划分后的数据集,这一部分可以直接用于YOLOv5的训练,无需后续再进行 数据地址.txt 文件的生成。YOLOv7不行,YOLOv7必须用.txt文件进行训练。
如果直接用原图片进行训练(YOLOv5支持直接引用图片数据做训练;YOLOv7不支持,需要引用图片数据生成的绝对路径.txt文件训练)。这里说的是YOLOv5中的特殊情况,自定义数据集的yaml文件可以仿照coco.yaml写成如下格式。
mydataset.yaml# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]train: ./VOCdevkit/images/train # 17420 imagesval: ./VOCdevkit/images/val # 4716 images# number of classesnc: 20# Classesnames: ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]【注】:另外脚本生成的几个没有用的文件可以直接删除。其中包括上图在原数据集下生成的YOLOLabels文件夹、下图的在根目录下生成的yolov5_train.txt、yolov5_val.txt文件都可以直接删除。
(这是因为源代码是down网上的代码,不影响使用所以懒得做修改)
3. 生成datasets.txt文件
如果看过YOLOv5/v7代码中的COCO.yaml文件的都清楚,文件中的数据路径用的是txt文件。尤其是v7必须要用txt地址文件进行训练(这里不清楚v7可否直接用图片,但是我想操作起来要修改很多地方的代码,容易产生bug,不如直接生成数据集的地址txt文件方便)
在根目录下创建get_data_img_dir.py脚本,用于生成划分完数据集后的images下train、val中图片的绝对路径。
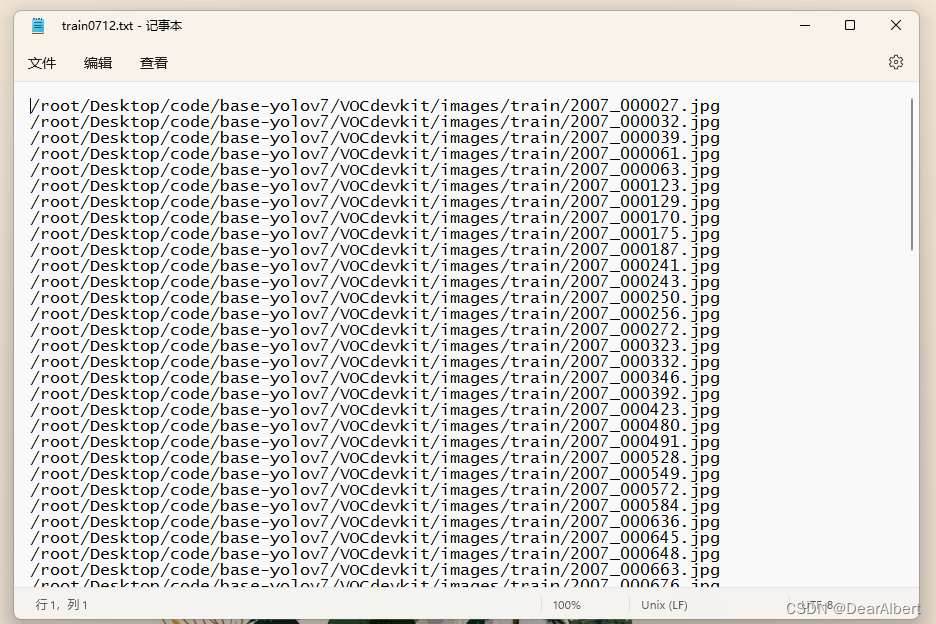
get_data_img_dir.py"""# 制作数据集的步骤:1. voc_to_yolo.py划分数据集,留下images、labels2. get_data_img_dir.py 分别生成images下train、val图片的绝对路径(yolov7训练数据集需要.txt文件)------------------------------------------------------------------------------------------------------------------------# 生成图片数据的绝对路径"""import osdef listdir(path, list_name): # 传入存储的list for file in os.listdir(path): file_path = os.path.join(path, file) if os.path.isdir(file_path): listdir(file_path, list_name) else: list_name.append(file_path)list_name = []path = '/root/Desktop/code/base-yolov7/VOCdevkit/images/val' # 文件夹路径listdir(path, list_name)print(list_name)with open('./val0712.txt', 'w') as f: # 要存入的txt write = '' for i in list_name: write = write + str(i) + '\n' f.write(write)运行脚本,在根目录下生成 train0712.txt、val0712.txt 两个txt文件,这两个文件就是训练集图片数据的绝对地址,文件如下图所示。
我这里是因为要在服务器上训练网络,所以生成的地址是linux系统下的地址。
4. 基于数据集制作训练的datasets.yaml文件
在yolov5/v7训练过程中,将上图生成的txt文件移动到创建的datasets-VOC0712文件夹下,这样数据集就制作完成,接下来就是制作模型训练需要用到的yaml文件,仿照coco.yaml文件制作自己的yaml文件,代码如下图所示。
mydatasets.yaml# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]train: ./datasets/VOC0712/train0712.txt # 17420 imagesval: ./datasets/VOC0712/val0712.txt # 4716 images# number of classesnc: 20# Classesnames: ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]OK,到这一步自定义数据集就整体制作完成。接下来就可以按照模型训练需要注意的地方进行下一步的训练啦!
【注】:由于本人水平有限,如有错误,敬请指正!!!