「多层感知机」手把手带你0基础学懂弄通多层感知机思路【深度学习】附源码及解析
「多层感知机」手把手带你0基础学懂弄通多层感知机【深度学习】附源码及解析
♥️作者:白日参商
?♂️个人主页:白日参商主页
♥️坚持分析平时学习到的项目以及学习到的软件开发知识,和大家一起努力呀!!!
??加油! 加油! 加油! 加油
?欢迎评论 ?点赞?? 收藏 ?加关注+!
文章目录
「多层感知机」手把手带你0基础学懂弄通多层感知机【深度学习】附源码及解析前言一、多层感知机是什么?二、预备知识1.模型组成(划重点)2、Fashion-MNIST数据集 三、数据集预处理1、明确问题2、下载数据集 四、多层感知机的简洁实现1、导入必要的库2、网络搭建3、确定批量大小、学习率、迭代次数4、确定损失函数5、确定优化器6、确定加载数据集方法7、实现8、整体源码9、效果展示 五、总结
前言
随机器学习、深度学习不断的深入我们的学习生活中,越来越多的学生尤其是研究生开始离不开深度学习的学习,但是深度学习是一门知识面非常广的学科,正好我最近在研读花书,想着出几期博客,0基础的带大家逐渐的入门深度学习,今天和大家分享的主要内容为:多层感知机的实现
一、多层感知机是什么?
多层感知机(Multilayer Perceptron,简称 MLP)是一种前馈神经网络,由多个全连接的神经网络层组成。每一层都包含多个神经元,每个神经元与上一层的所有神经元相连,并通过带权重的连接传递信息。多层感知机最常用于分类和回归问题,其中每个神经元的输出都是通过对上一层神经元输出的加权和进行非线性变换得到的。通过不断调整权重和偏置,多层感知机可以学习到输入与输出之间的复杂映射关系。通过在网络中加入一个或多个隐藏层来克服线性模型的限制, 使其能处理更普遍的函数关系类型。 要做到这一点,最简单的方法是将许多全连接层堆叠在一起。 每一层都输出到上面的层,直到生成最后的输出。 我们可以把前层看作表示,把最后一层看作线性预测器。 这种架构通常称为多层感知机(multilayer perceptron),通常缩写为MLP。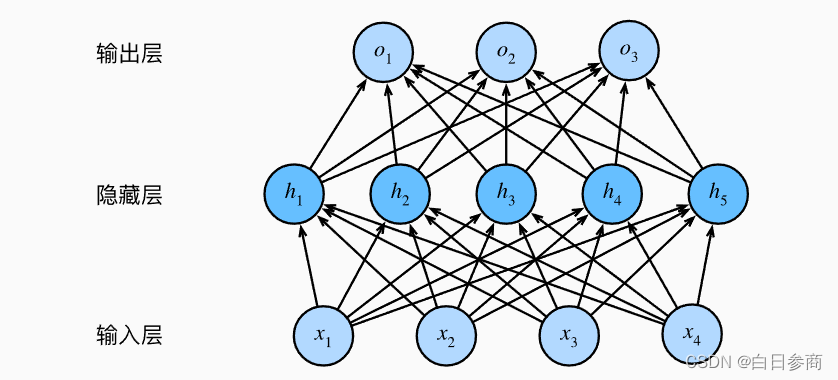
这个多层感知机有4个输入,3个输出,其隐藏层包含5个隐藏单元。 输入层不涉及任何计算,因此使用此网络产生输出只需要实现隐藏层和输出层的计算。 因此,这个多层感知机中的层数为2。 注意,这两个层都是全连接的。 每个输入都会影响隐藏层中的每个神经元, 而隐藏层中的每个神经元又会影响输出层中的每个神经元。
二、预备知识
1.模型组成(划重点)
一个简单的深度学习模型通常包括以下板块:
1、输入层:用于接收输入数据的层,例如图像、文本或音频等。
2、中间层:也称为隐藏层,是模型的核心部分。中间层通常包括多个神经元,每个神经元都会对输入数据进行加权和运算,然后通过激活函数进行非线性变换。
3、输出层:用于输出模型的预测结果,例如分类或回归等。
4、损失函数:用于衡量模型的预测结果与真实值之间的差异,常用的损失函数包括均方误差、交叉熵等。
5、优化器:用于调整模型的参数,使得模型的损失函数达到最小。常用的优化器包括随机梯度下降、Adam等。
6、数据集:用于训练模型的数据集,通常包括训练集、验证集和测试集等。
7、除了以上这些以外我们还需要数据加载函数等等
2、Fashion-MNIST数据集
Fashion-MNIST总共有十个类别的图像。每一个类别由训练数据集6000张图像和测试数据集1000张图像。所以训练集和测试集分别包含60000张和10000张。测试训练集用于评估模型的性能
每一个输入图像的高度和宽度均为28像素。数据集由灰度图像组成。Fashion-MNIST,中包含十个类别,分别是:
T-shirt、trouser、pillover、dress、coat、andal、hirt、sneaker、bag、ankle、boot
三、数据集预处理
1、明确问题
我们现在希望建立一个简单的多层感知机架构,能够对Fashion-MNIST数据集中的十个类别的图像进行精准的分类
2、下载数据集
俗话说得好:巧妇难为无米之炊!我们要解决这个问题,第一步肯定得先把数据集搞到手,以下就是下载数据集的代码,大家只需要运行一遍为了保证代码的简洁性,后续注释掉即可。
import torchimport torchvisionfrom torch.utils import datafrom torchvision import transformsfrom d2l import torch as d2ld2l.use_svg_display()# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式,# 并除以255使得所有像素的数值均在0~1之间trans = transforms.ToTensor()mnist_train = torchvision.datasets.FashionMNIST( root="../data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST( root="../data", train=False, transform=trans, download=True)以上代码实现了以下功能:以上代码实现了以下功能:
1、调用了 d2l.use_svg_display() 函数,以便在 Jupyter Notebook 中显示 SVG 格式的图片。
2、定义了一个 transforms.ToTensor() 实例 trans,用于将图像数据从 PIL 类型转换为 32 位浮点数格式,并将其值除以 255,使得所有像素的数值均在 0~1 之间。
3、使用 torchvision 库读取了 FashionMNIST 数据集的训练集和测试集,并将其转换为上一步定义的 trans 格式。其中,训练集和测试集的数据保存在 mnist_train 和 mnist_test 变量中。如果本地没有下载过 FashionMNIST 数据集,则会在代码中下载并保存到 …/data 目录下。
四、多层感知机的简洁实现
接下来我们将通过高级API更简洁地实现多层感知机并附代码解析注释。
1、导入必要的库
import torch from torch import nn from d2l import torch as d2l| 序号 | 注释 |
|---|---|
| 1 | 导入了 PyTorch 库,并从中导入了 nn 模块 |
| 2 | 导入了 d2l 库中的 PyTorch 工具,并将其命名为 d2l。d2l 是 Dive into Deep Learning 书籍的官方代码库。 |
2、网络搭建
这一部分主要进行网络的搭建、权重的初始化
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 10))def init_weights(m): if type(m) == nn.Linear: nn.init.normal_(m.weight, std=0.01)net.apply(init_weights);| 序号 | 注释 |
|---|---|
| nn.Sequential | 是一个模型容器,它按顺序包含一些模块,每个模块对输入数据进行一些操作,然后将结果传递给下一个模块。在这个例子中,nn.Sequential 包含了三个模块:nn.Flatten()、nn.Linear(784, 256) 和 nn.Linear(256, 10)。nn.Flatten() 将输入数据展平成一维张量,nn.Linear(784, 256) 是一个全连接层,将展平后的输入数据映射到一个大小为 256 的隐藏层,nn.Linear(256, 10) 是另一个全连接层,将隐藏层的输出映射到一个大小为 10 的输出层。最后输出的结果是一个大小为 10 的张量,每个元素代表对应类别的预测概率。 |
| nn.ReLU() | nn.ReLU() 是一个激活函数模块,它将输入数据进行非线性变换,增加模型的表达能力。 |
| init_weights | init_weights 是一个自定义的初始化权重的函数,它对模型中的每个 nn.Linear 模块的权重进行初始化。这里使用了正态分布的随机数来初始化权重,均值为 0,标准差为 0.01。 |
| net.apply(init_weights) | net.apply(init_weights) 将 init_weights 函数应用到 net 模型的每个模块上,从而初始化所有 nn.Linear 模块的权重。 |
这段代码定义了一个包含两个线性层的神经网络,中间使用了 ReLU 激活函数。同时,定义了一个名为 init_weights 的函数,用于对神经网络的权重进行初始化。具体地,对于类型为nn.Linear 的层,使用正态分布来初始化其权重,均值为 0,标准差为 0.01。最后,通过调用 net.apply(init_weights) 来应用该初始化函数,对神经网络的权重进行初始化。
3、确定批量大小、学习率、迭代次数
批量大小设置为256、迭代周期数设置为10,并将学习率设置为0.1。
batch_size, lr, num_epochs = 256, 0.1, 10| 名称 | 注释 |
|---|---|
| batch_size | 每次训练模型时输入的数据批次大小,这里设置为256,表示每次输入256个样本进行训练。 |
| lr | 学习率,用于调整每次更新模型参数的步长,这里设置为0.1,表示每次更新参数时,参数值会乘以0.1的步长进行调整。 |
| num_epochs | 训练轮数,即整个数据集被训练的次数,这里设置为10,表示将整个数据集训练10次。 |
4、确定损失函数
nn.CrossEntropyLoss(reduction=‘none’) 是一个 PyTorch 中的损失函数,用于计算交叉熵损失。
loss = nn.CrossEntropyLoss(reduction='none')具体来说,如果将一个大小为 (batch_size, num_classes) 的模型输出与一个大小为 (batch_size) 的目标标签(即正确的类别)进行比较,nn.CrossEntropyLoss(reduction=‘none’) 将返回一个大小为 (batch_size) 的张量,其中每个元素表示对应样本的损失值。
nn.CrossEntropyLoss 是 PyTorch 中的一个损失函数,它用于多分类问题。其中,reduction 参数用于指定损失函数的计算方式,其取值可以为以下三种:
none:不进行任何计算,直接返回每个样本的损失值。mean:将所有样本的损失值求平均。sum:将所有样本的损失值求和。因此,当 reduction='none' 时,nn.CrossEntropyLoss 返回每个样本的损失值,而不是对所有样本的损失值进行求和或求平均。
5、确定优化器
我们这里在 PyTorch 中使用随机梯度下降(SGD)优化器来更新神经网络模型 net 的参数。其中 lr 是学习率,即每次参数更新时的步长大小。训练过程中,会通过反向传播算法计算损失函数对网络参数的梯度,然后使用 SGD 优化器根据学习率和梯度信息来更新网络参数,从而使损失函数值不断减小,最终得到一个较优的网络模型。
trainer = torch.optim.SGD(net.parameters(), lr=lr)这行代码定义了一个名为 trainer 的优化器,用于对神经网络 net 的参数进行优化。优化器的选择是随机梯度下降(SGD),学习率为 lr。在训练过程中,优化器会根据损失函数的反向传播结果来更新网络参数,从而使得网络的预测结果更加准确。
6、确定加载数据集方法
因为我们在这里用的数据集Fashion-MNIST数据集,这个数据集可以直接通过调用torch中的函数即可进行数据加载
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)这行代码是从d2l库中加载Fashion-MNIST数据集,并将训练集和测试集分别存储在train_iter和test_iter这两个迭代器对象中,每个迭代器对象可以迭代地返回一个批次大小为batch_size的数据样本及其对应的标签。其中,batch_size是一个超参数,表示每个批次中包含的数据样本数量。这行代码的作用是为后续的模型训练和测试提供数据源。
7、实现
d2l.train_ch3() 。它封装了训练模型的过程,包括数据迭代、前向传播、反向传播、参数更新等过程。具体来说,它会遍历数据集中的每个小批量数据,通过前向传播计算出模型的预测值,再通过反向传播求出梯度,最后根据梯度更新模型参数。
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)参数说明:
net:模型train_iter:训练数据集迭代器test_iter:测试数据集迭代器loss:损失函数num_epochs:训练轮数trainer:优化器函数返回:
无返回值,但会输出每轮训练和测试的损失值和准确率。函数实现:首先,定义两个字典变量,分别用于保存训练和测试的损失值和准确率。然后,开始训练模型。在每一轮训练中,遍历训练数据集,对每个小批量数据进行前向传播和反向传播,并调用优化器来更新模型参数。 同时,累加训练损失和准确率,并计算平均值。在每一轮训练结束后,计算测试损失和准确率,并将其保存到字典变量中。最后,输出每轮训练和测试的损失值和准确率。
8、整体源码
import torchfrom torch import nnfrom d2l import torch as d2lnet = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 10))def init_weights(m): if type(m) == nn.Linear: nn.init.normal_(m.weight, std=0.01)net.apply(init_weights)batch_size, lr, num_epochs = 256, 0.1, 10loss = nn.CrossEntropyLoss(reduction='none')trainer = torch.optim.SGD(net.parameters(), lr=lr)train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)9、效果展示
目前展示的效果图是基于Jupyter notebook写的,它会直接生成效果图,后续会出一期如何直接在代码中编写绘制效果图的博客。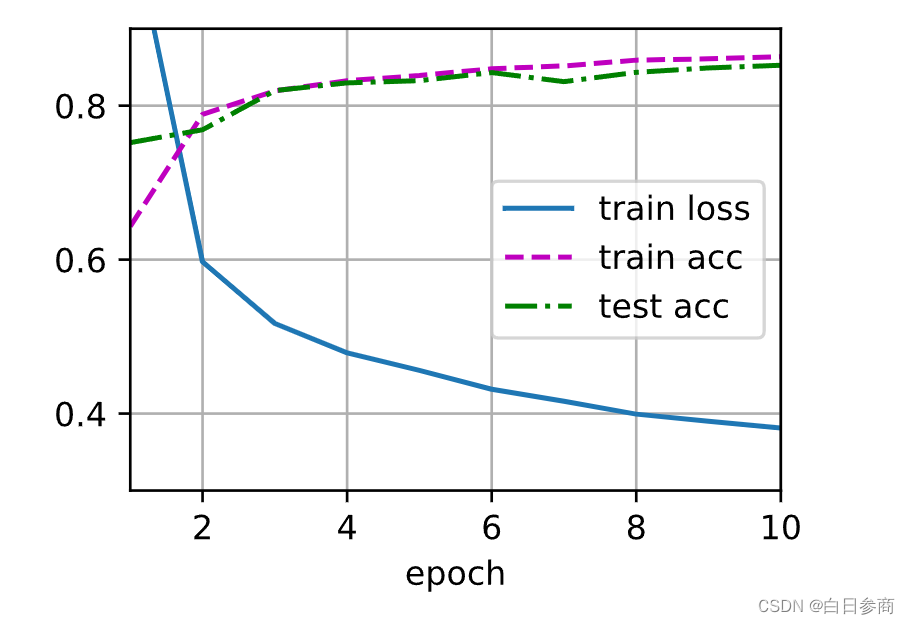
五、总结
经过对多层感知机的学习,有没有感觉其实深度学习也没有那么的晦涩难懂!!!如果您觉得这篇文章对您有帮助!希望能够给博主点赞+关注!!!!!!!!!!!
♥️坚持分析平时学习到的项目以及学习到的软件开发知识,和大家一起努力呀!!!
??加油! 加油! 加油! 加油
?欢迎评论 ?点赞?? 收藏 ?加关注+!
登录后可发表评论
点击登录