?作者:一只大喵咪1201
?专栏:《C++学习》
?格言:你只管努力,剩下的交给时间!
map和set的使用
?关联式容器⚡键对值 ?set⚡构造函数⚡增删查改 ?multiset?map⚡构造函数⚡增删查改⚡operator[] ?multimap?map和set在题目中的应用⚡统计前K个高频单词⚡求两个数组的交集 ?总结
map和set的底层都是二叉搜索树,只是做了更进一步的限制,使其不会出现单只的情况,搜索的时间复杂度保证在O(log2N),具体的底层结构后面本喵再详细介绍,现在先来认识以下set和map
?关联式容器
首先要知道的是序列式容器,这种容器我们之前接触过,比如vector,list,deque等等。
序列式容器:
底层为线性的数据结果(物理上或者逻辑上),容器中的元素储存的是元素本身。而且我们之前在使用序列式容器的时候,插入数据和删除数据只管操作就行,不用考虑其他因素。关联式容器:
存储的是<key,value>结构的键对值,在数据检索时比序列式容器效率更高。插入和删除数据时,要考虑该数据和它前后数据之间的关联性。总的来说,关联式容器存放的数据不同,而且数据前后有一点的关联性。
⚡键对值
键对值:用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息。比如:现在要建立一个英汉互译的字典,那字典中就得右英文单词和与之对应的中文含义,而且它们的关系是一一对应的,此时用就可以使用键对值来存放,如<单词,汉语>。
在STL中,定义了一个键对值的类:

伪代码形式:
template <class T1, class T2>struct pair{typedef T1 first_type;typedef T2 seco_type;T1 first;T2 second;pair():first(T1()),second(T2()){}pair(const T1& a, const T2& b):first(a),second(b){}};make_pair():
该函数是用来制作一个pair类型的匿名对象的:
pair<string, string>("string", "字符串");make_pair("string", "字符串");上面俩句代码是等价的,都是在创建一个pair类型的匿名对象,让你选择你会选择哪种方式呢?
make_pair()是为了让我们更加方便的使用键值对。?set
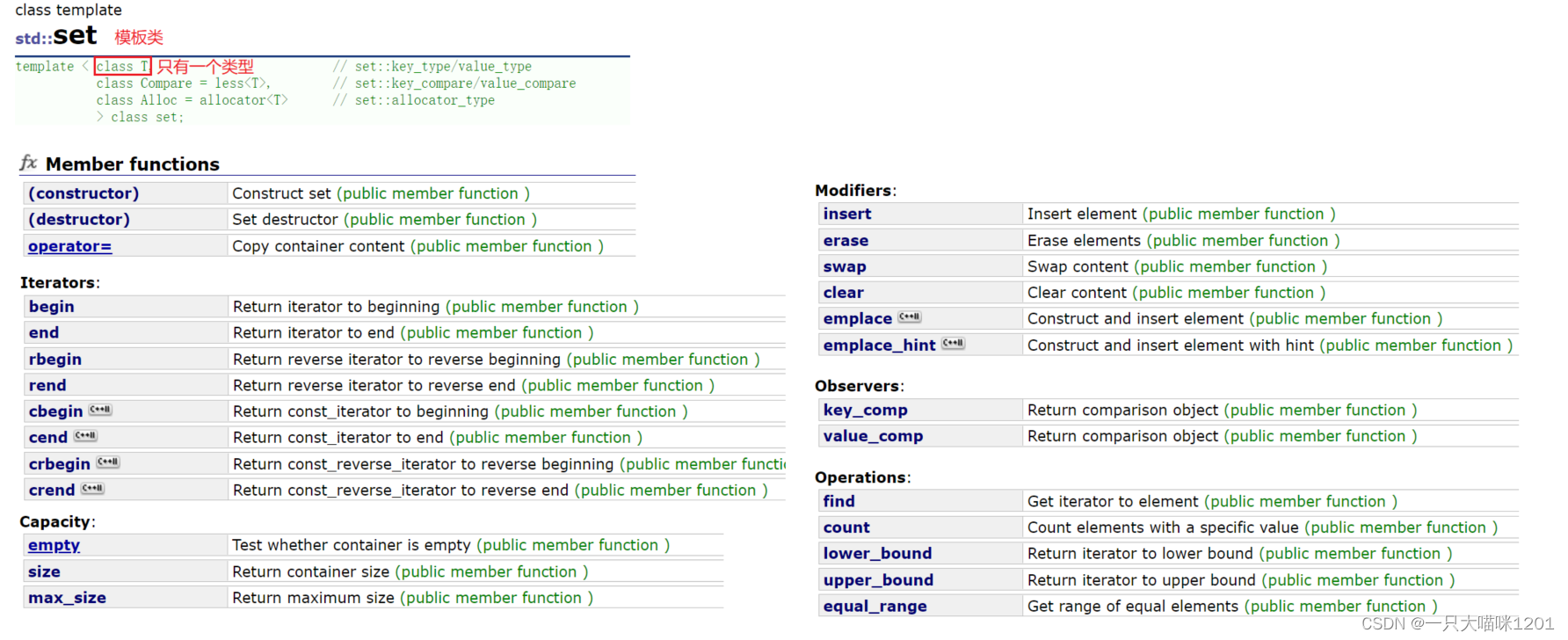
set和之前学习的容器一样,也是一个模板类,但是它的底层是关联式容器,也就是二叉搜索树,并且有很多的成员函数,这些接口相信大家大部分都不陌生。
⚡构造函数

构造函数有三个,分别是默认构造函数、使用迭代器区间的构造函数、拷贝构造函数。
因为底层是二叉搜索树,所有就会涉及到比较,构造函数参数就是比较方式,是一个仿函数,但是默认情况下是有缺省值的。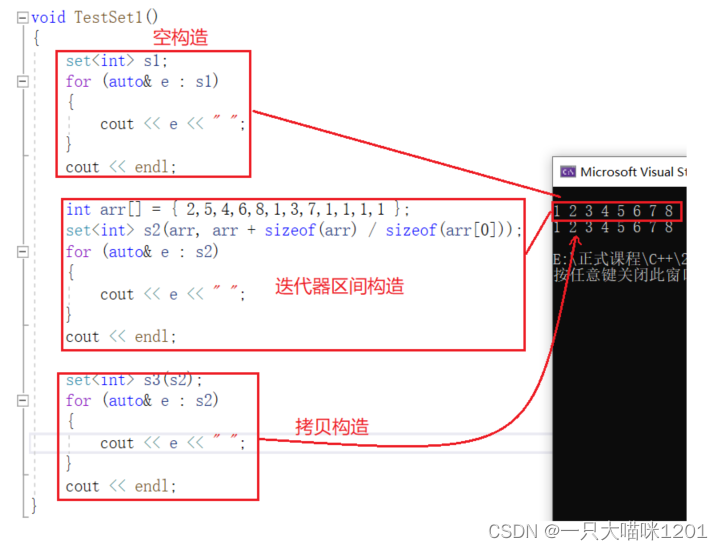
set的去重功能:
上面使用迭代器区间构造s2的时候,原本的数组中有很多个1,但是构造出来的set中,只有一1。
set具有降重的功能,当插入的数据已经存在时就不会再插入,这一点在二叉搜索树中就讲解过。
可以看到,数组中有多个重复数字,用这些数字构造出来的set,里面每个数字只存在一个,重复的都被去除了。
迭代器的中序移动:
在打印set中的数据时,我们发现打印出来的结果是升序的,在学习二叉搜索树的时候我们知道,采用中序遍历的方式打印出来的结果就是升序的。
迭代器++时,移动的顺序就是中序遍历的顺序,所以使用迭代器遍历时得到的结果和中序遍历是一样的。⚡增删查改
insert():
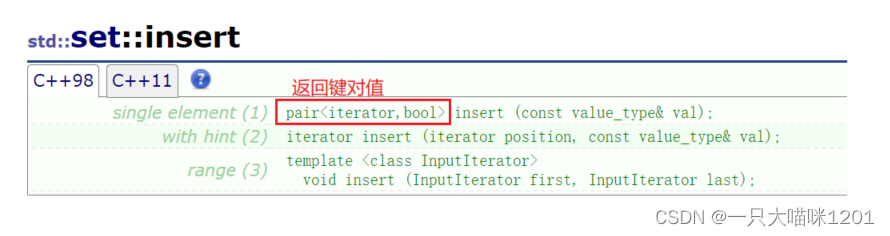
插入函数insert有3个重载函数,其中第一个是插入一个数据,并且返回一个键对值,第二个是指定位置插入,返回插入的位置,第三个是插入一段迭代器区间。
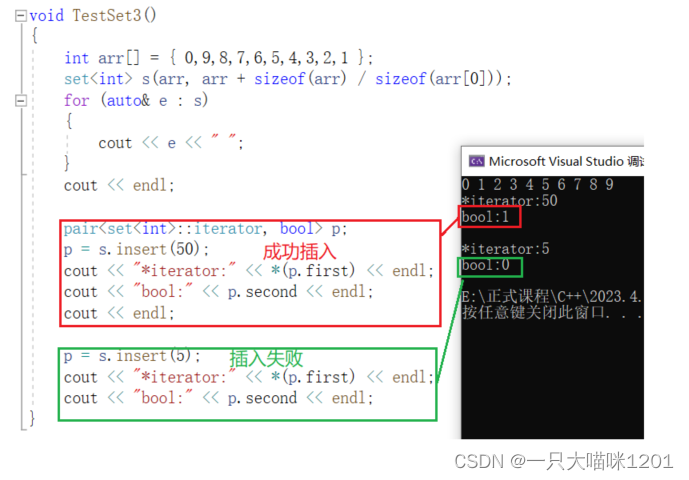
强烈不建议使用指定位置插入。
指定位置向set中插入数据,有可能会破环二叉搜索的结构,除非在插入之前能够确定不会破坏结构。一般情况下我们都不会指定位置插入。
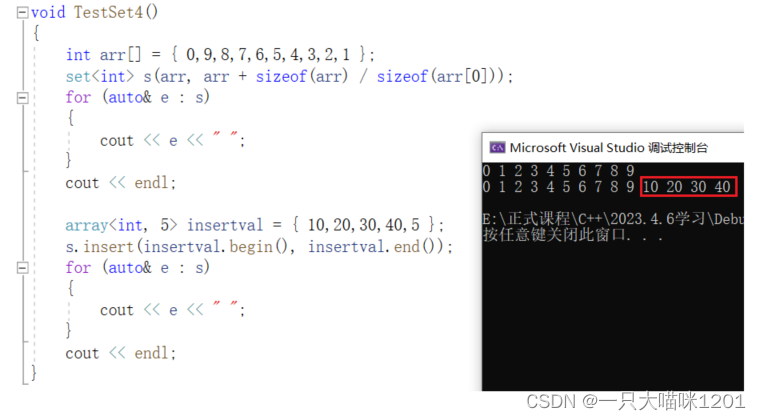
find():
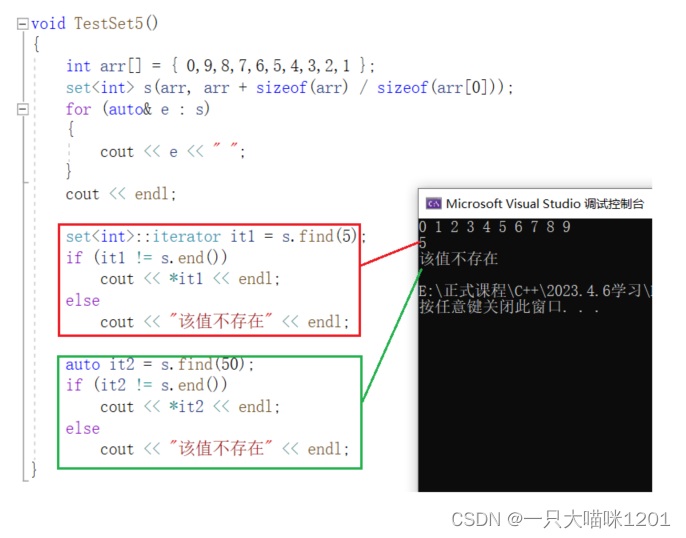
还有一个接口函数可以代替find,该结构名为count():

由于set具有降重功能,里面不会存在重复的数据,所以它在这里的功能是和find一样的,只是不过返回的是数字,而不是迭代器。
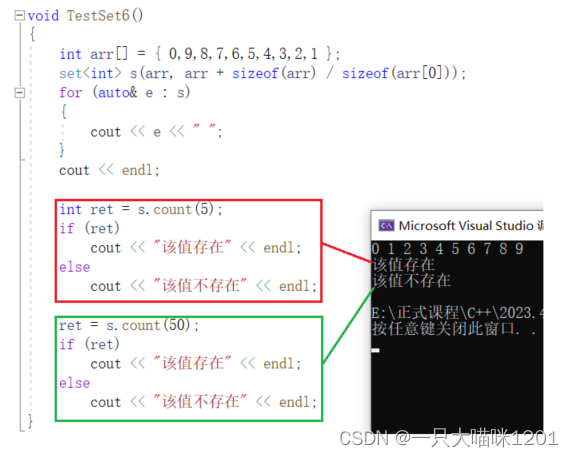
存在时返回值是1,不存在时返回值是0。
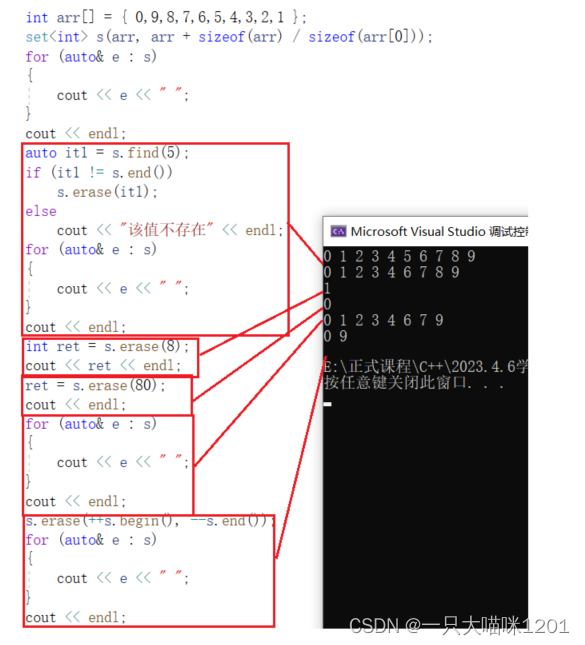
erase():

有三个重载函数,第一个删除指定迭代器位置的值,第二个返回删除指定值的个数,第三个删除迭代器区间中所有数据。
修改:
在二叉搜索树的时候本喵就说过,不支持修改,因为很有可能会破环树的结构,同样的set也不支持修改。
获取上下边界:

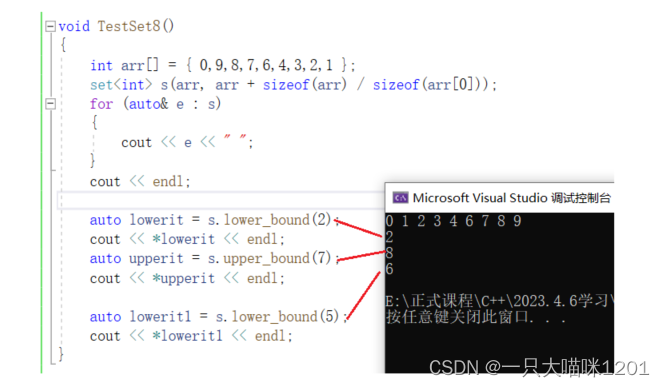
但是这两个接口用的非常少,仅了解就可以。
其他成员函数的使用,包括迭代器,我们在学习vector,list等容器时已经用的炉火纯青了,本喵就不再介绍了,还有一些很不常用的接口,再以后用到的时候再详细介绍。
?multiset
multiset和set在同一个头文件中,而且几乎是一模一样的。
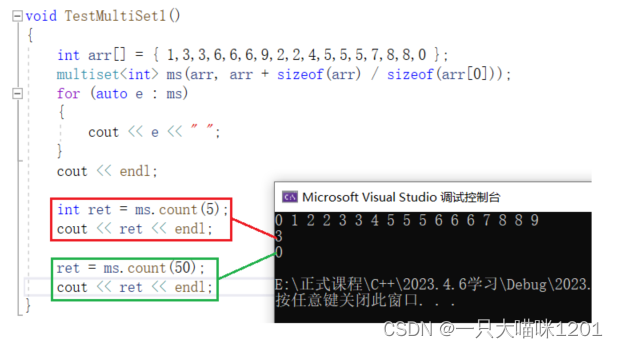
count():
在set中count成员函数和find功能类似,但是在multiset中它就有了它的作用。
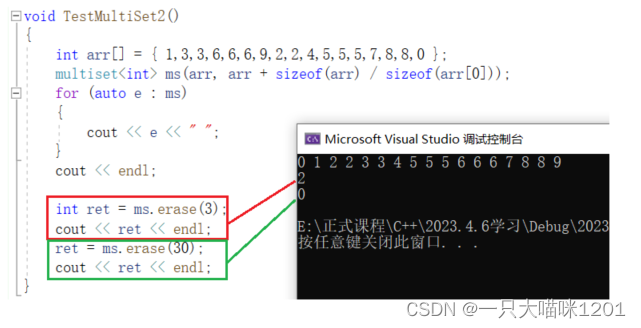
erase():

erase中的第二个重载函数也是给multiset使用的。
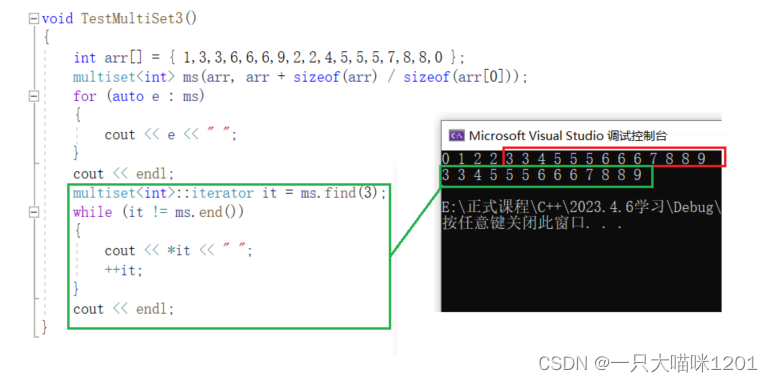
find():
使用find查找multiset中的重复元素时,返回的是哪个呢?
multiset其他方面和set一模一样,本喵就不再介绍了。
?map
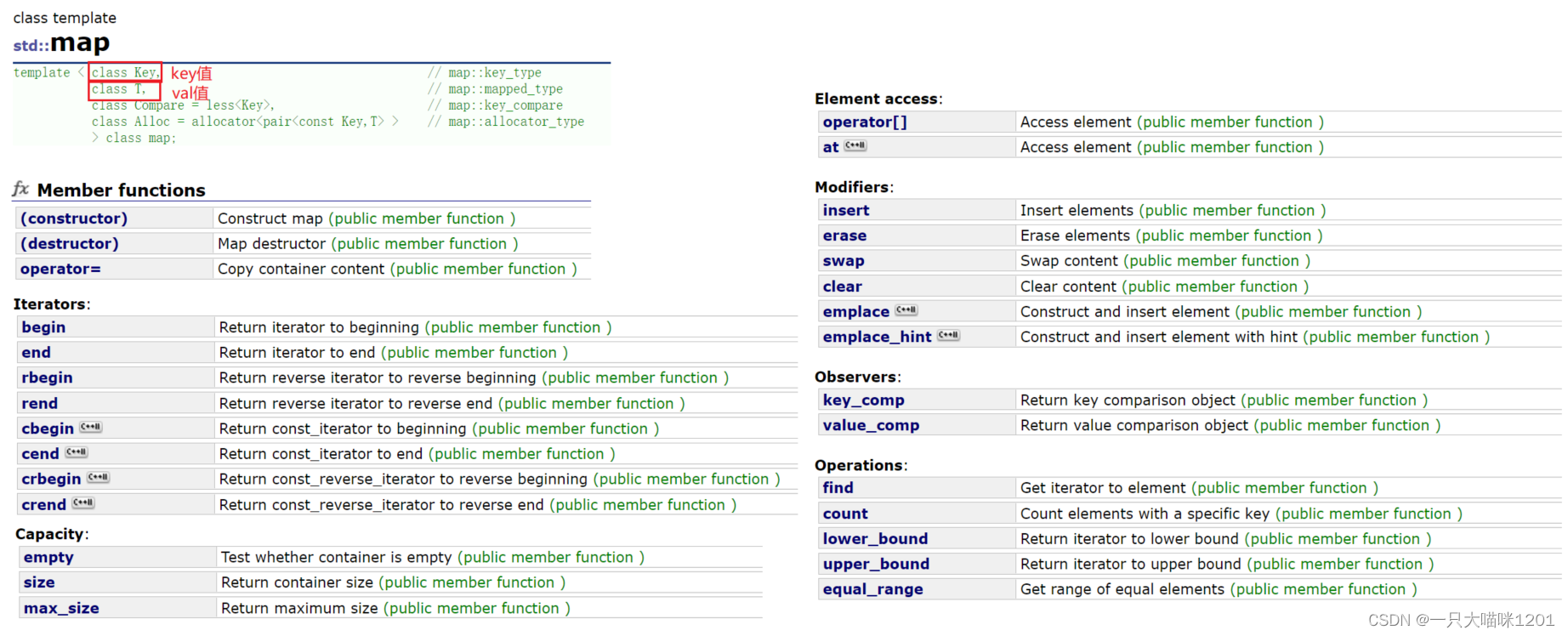
map和set一样,也是一个关联式容器,底层是二叉搜索树。
⚡构造函数

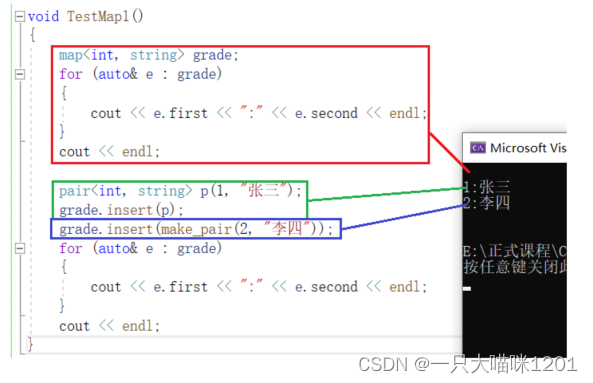
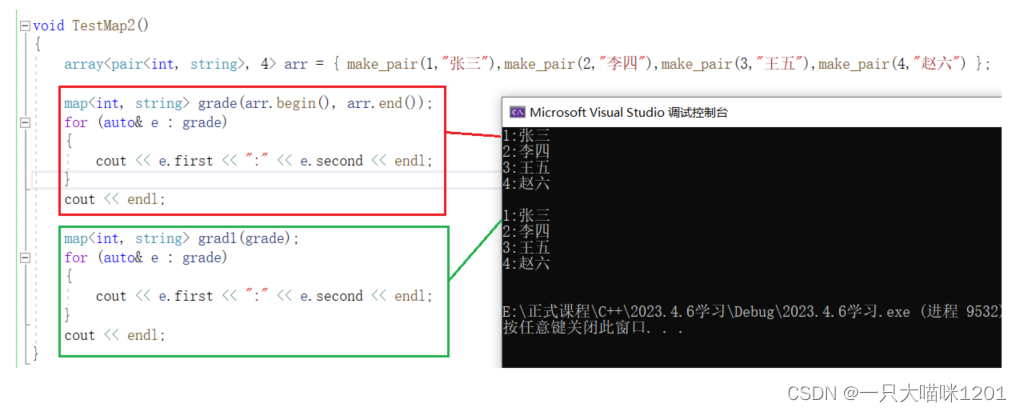
特性:
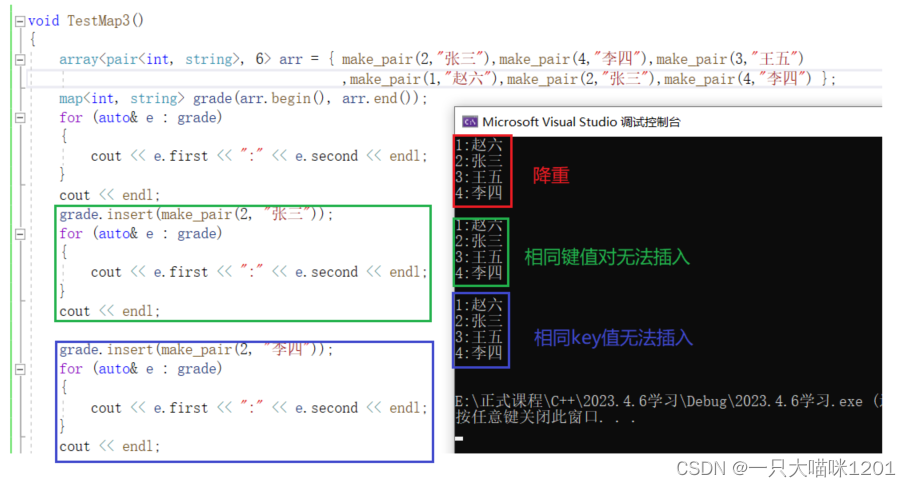
map也具有排序 + 降重的功能,依据只看key值而不管value值。
⚡增删查改
insert():
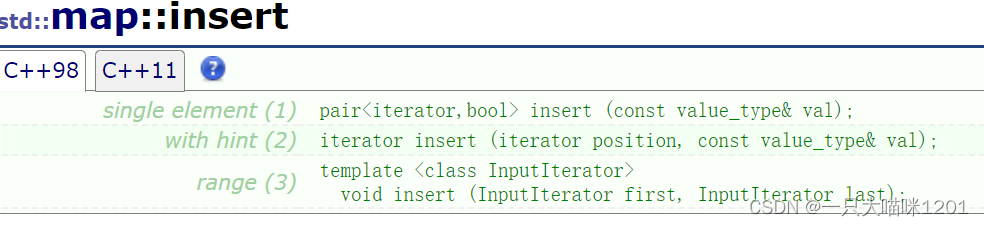
用法和set中的一样,只是map插入的是键值对。
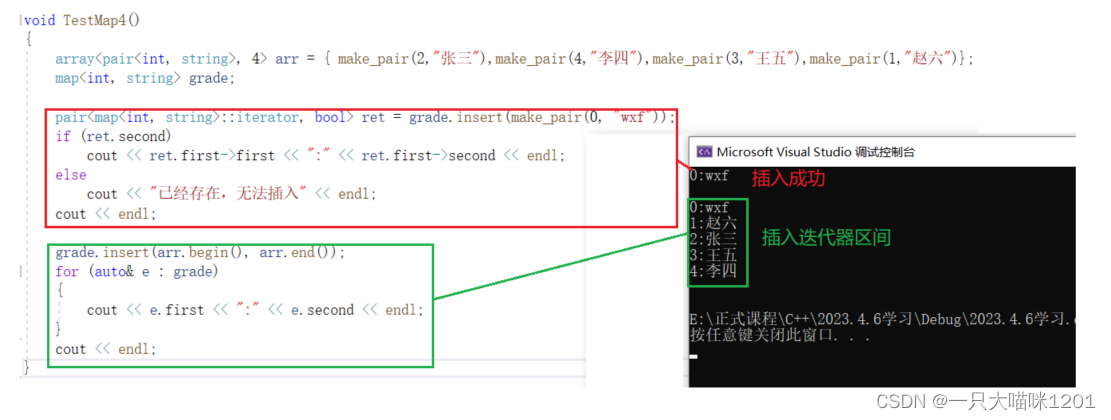
同样强烈不建议使用指定位置插入。
find():

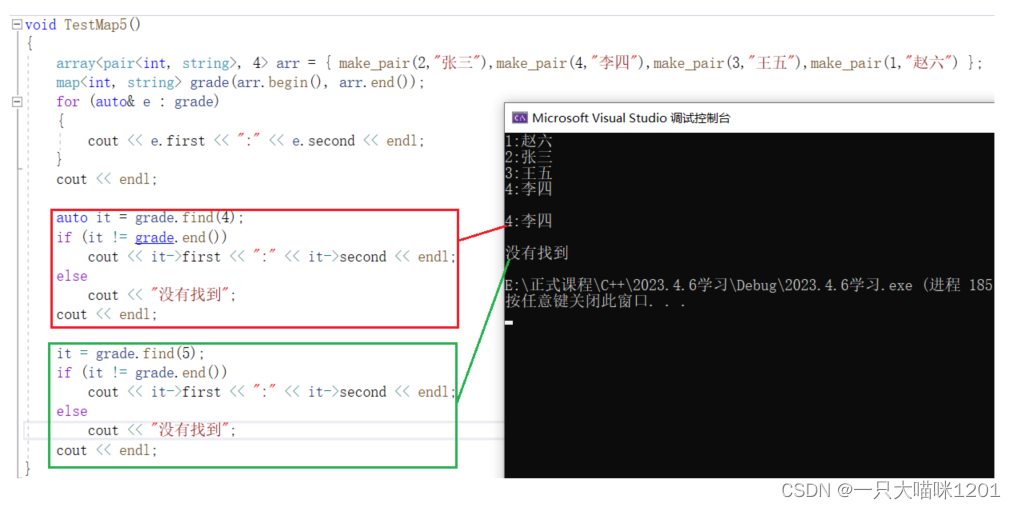
erase():
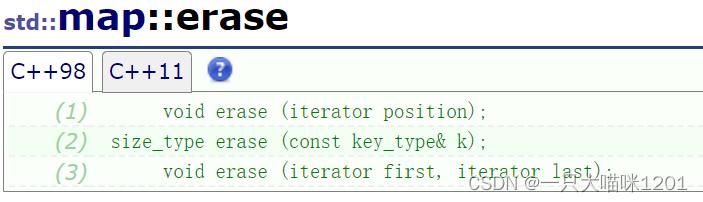
和set中的使用情况一样,除了指定迭代器位置和迭代器区间外,只需要指定键值key就可以删除对应的键值对。
map和set一样,不支持修改,因为可能会破坏二叉搜索树的结构。
除了插入这样的增加操作时,需要一个键值对,其他操作都是根据键值对中的键值key来处理的。⚡operator[]
现在使用map来统计KV模型例子中水果的个数:
void TestMap6(){string arr[] = { "苹果", "西瓜", "香蕉", "草莓", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;for (auto& e : arr){map<string, int>::iterator it = countMap.find(e);//map没有该水果,插入,数量为1if (it == countMap.end()){countMap.insert(make_pair(e,1));}//map中有该水果,数量加1else{it->second++;}}//查看mapfor (auto& e : countMap){cout << e.first << ":" << e.second << endl;}cout << endl;}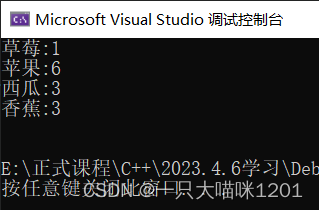
成功统计出了水果的个数,此时水果名是key值,数量是value值。
还有一种非常不可思议的方式:
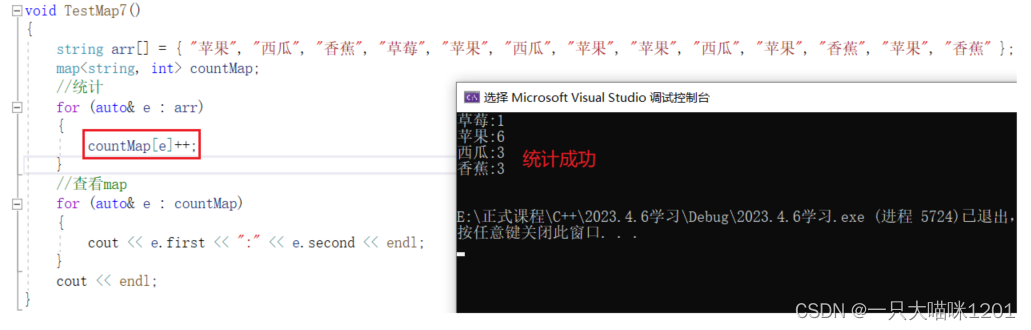
要想知道原因,就必须了解operator[]成员函数。
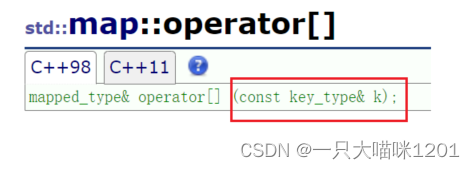

文档中解释,调用operator[]相当于在调用上面那一句代码。可以看到这句代码非常长,得需要好好分析。

这句代码可以这样解释,但是还是有些复杂。
Value& operator[](const K& key){//1.插入2.查找pair<map<K, Value>::iterator, bool> ret = insert(make_pair(key, Value()));//3.修改return ret.first->second;}一个operator[]可以实现3个功能,所以可以代替最开始那一堆逻辑。
countMap[e]++;这句代码是如何实现插入,查找,修改三个功能呢?
首先:insert(e),map中如果不存在e,则插入,返回e的second的引用,也就是计数值。如果存在e,则不插入,直接返回e的second的引用。如果是新插入的e,此时e的second的引用是0,加加后变成了1。如果不是新插入的,对e的second的引用进行加加,数量也就被加加了。这里只是用到了operator[]的插入和修改功能,没有使用到查找。?multimap
multimap和map也是在一个头文件中,使用和map也一样,就像是multiset和set的关系。

mutimap中没有operator[]。
如果有它的话,operator[e]返回的second应该返回哪个呢?毕竟可以找到多个first,所以mutimap不提供operator[]成员函数。
insert():
map和set以及multiset和multimap的用法非常相似,可以相互参考。
?map和set在题目中的应用
⚡统计前K个高频单词

思路分析:
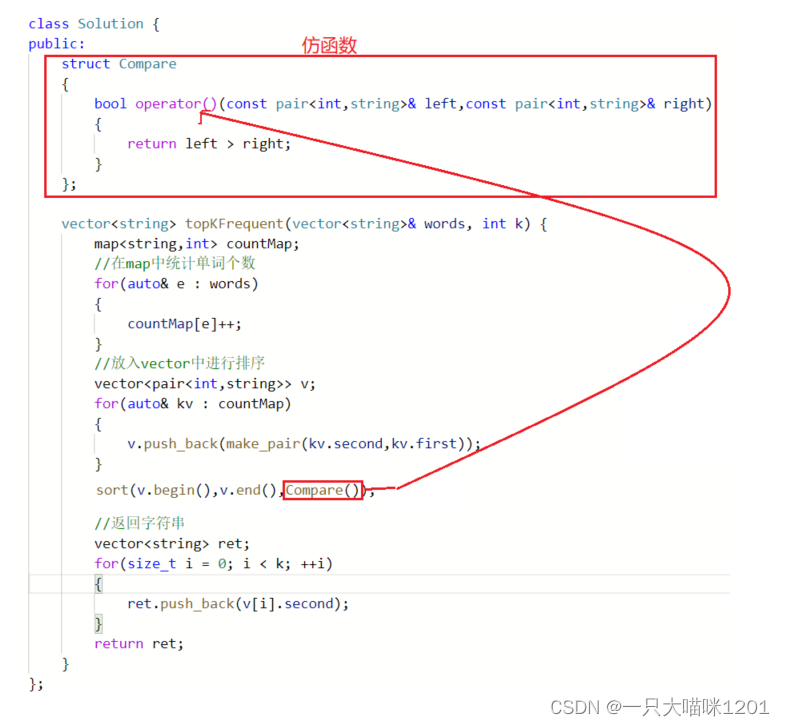

此时的结果"i"和"love"位置不对,这是因为sort采用的快排,快排是一个不稳定的算法,所以采用一个稳定算法就可以。

算法库中提供了稳定的排序算法。

但是此时函数不行,位置还是不对,这是什么原因呢?
原因就在于pair类型中对大于号的重载:
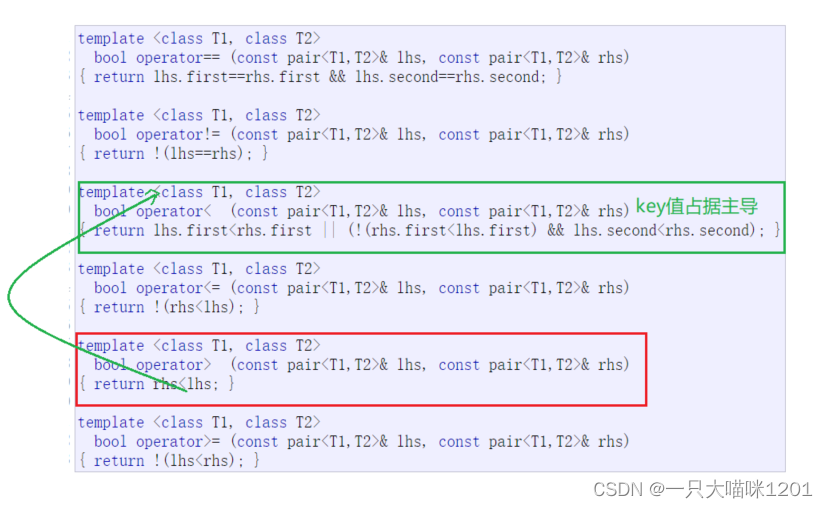
所以需要我们在仿函数中指定更严格的比较方式:

此时就成功了。
⚡求两个数组的交集

思路分析:

上边是思路的示意图。
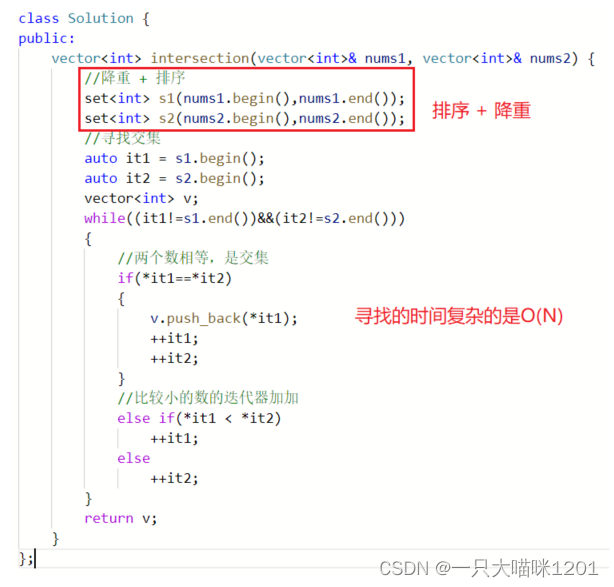

上边代码可以成功通过。
?总结
map和set的使用相对于之前的容器来说确实有一点复杂,主要在一些接口上面。要知道set和multiset以及map和mutimap的区别。