12.网络爬虫—线程队列详讲(实战演示)
网络爬虫—线程队列详讲与实战
线程队列Queue模块介绍 线程和队列的关系生产者消费者模式实战演示王者荣耀照片下载(使用生产者消费者模式)
前言:
?️?️个人简介:以山河作礼。
?️?️:Python领域新星创作者,CSDN实力新星认证
??第一篇文章《1.认识网络爬虫》获得全站热榜第一,python领域热榜第一。
? ?第四篇文章《4.网络爬虫—Post请求(实战演示)》全站热榜第八。
? ?第八篇文章《8.网络爬虫—正则表达式RE实战》全站热榜第十二。
? ?第十篇文章《10.网络爬虫—MongoDB详讲与实战》全站热榜第八,领域热榜第二
??《Python网络爬虫》专栏累计发表十一篇文章,上榜四篇。欢迎免费订阅!欢迎大家一起学习,一起成长!!
??悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。
线程
? ?上一章节我们讲解了多线程,我们来大致回顾一下,如有疑问,可以阅读之前文章《网络爬虫—多线程详讲与实战》帮助理解。
Python 线程是轻量级执行单元,它允许程序同时运行多个线程,每个线程执行不同的任务。Python 的线程有两种实现方式:使用 threading 模块或使用 _thread 模块。
? 使用 threading 模块创建线程:
导入 threading 模块定义一个函数作为线程的执行体创建一个线程对象,将函数作为参数传入调用 start() 方法启动线程例如:
import threadingdef print_numbers(): for i in range(1, 11): print(i)t = threading.Thread(target=print_numbers)t.start()? 使用 _thread 模块创建线程:
导入 _thread 模块定义一个函数作为线程的执行体创建一个线程对象,使用 _thread.start_new_thread() 方法传入函数作为参数调用 time.sleep() 方法等待线程执行完成例如:
import _threadimport timedef print_numbers(): for i in range(1, 11): print(i) time.sleep(1)_thread.start_new_thread(print_numbers, ())time.sleep(10)队列
? ?Python中的队列是一种数据结构,用于存储一组有序的元素。它支持两种基本操作:入队和出队。入队操作将一个元素添加到队列的末尾,而出队操作则从队列的开头移除一个元素。
Python标准库中提供了多种队列实现,包括:
? 1. Queue模块:提供了同步队列的实现,支持多线程环境下的安全操作。
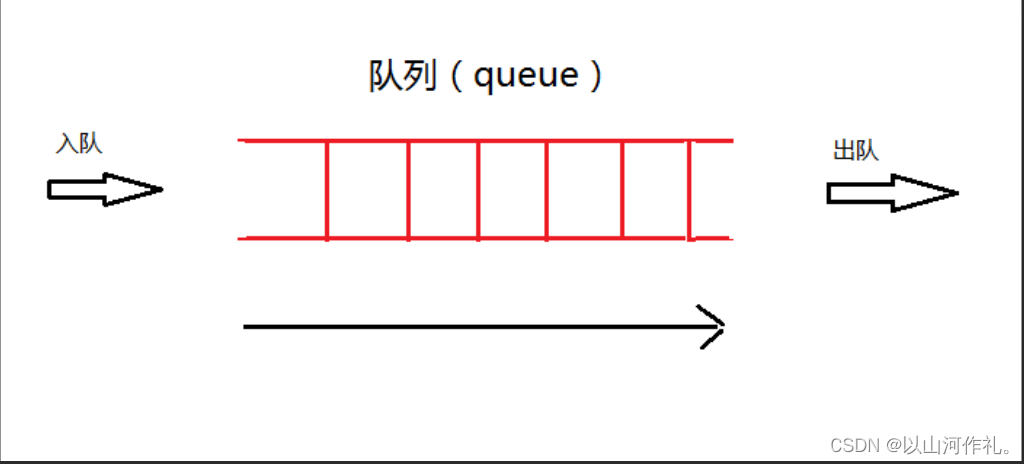
? 2. deque模块:提供了双端队列的实现,可以在队列的两端进行入队和出队操作。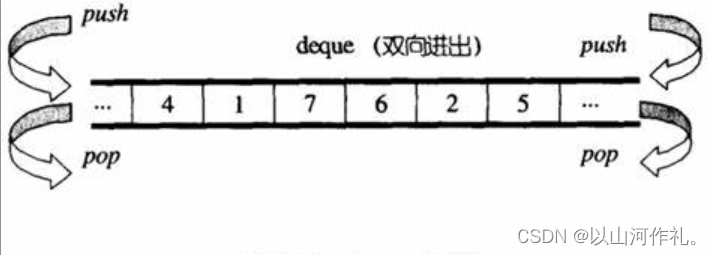
? 3. PriorityQueue模块:提供了优先队列的实现,可以按照元素的优先级进行出队操作。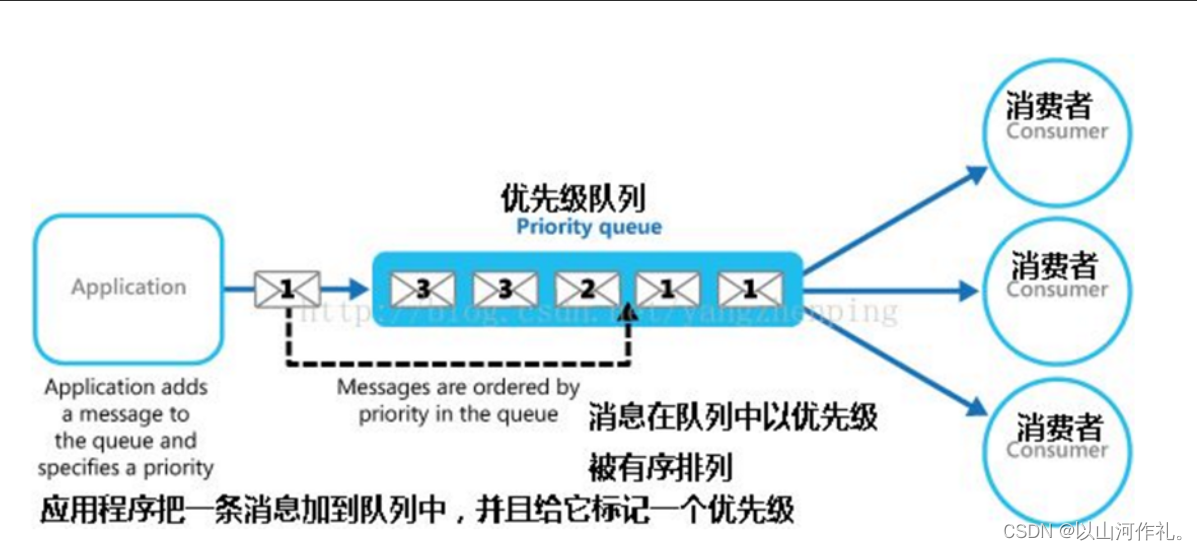
Queue模块介绍
**Queue模块是Python内置的线程安全的队列模块,提供了多种队列类型,**包括FIFO(先进先出)队列、LIFO(后进先出)队列和优先级队列。Queue模块的主要作用是在多线程编程中实现线程之间的通信和同步。
Queue模块中的主要类有三种:
Queue类:FIFO队列,即先进先出队列。
LifoQueue类:LIFO队列,即后进先出队列。
PriorityQueue类:优先级队列,可以给每个元素指定一个优先级,优先级高的元素先出队列。
Queue模块中的主要方法有以下几个:
1. put(item[, block[, timeout]]):将item放入队列中,如果队列已满,则block为True时会阻塞等待,timeout表示等待时间。
get([block[, timeout]]):从队列中取出一个元素,如果队列为空,则block为True时会阻塞等待,timeout表示等待时间。
qsize():返回队列中的元素个数。
empty():判断队列是否为空。
full()`:判断队列是否已满。
task_done():在完成一项工作之后调用,用于通知队列该项工作已完成。
join():阻塞调用线程,直到队列中所有的任务都被处理完毕。
Queue模块的使用可以简化多线程编程,提高程序的可读性和可维护性,避免了多线程编程中常见的问题,如竞争条件和死锁等。
下面是一个使用Queue模块实现的队列示例:
import queue# 创建一个队列对象q = queue.Queue()# 入队操作q.put(1)q.put(2)q.put(3)# 出队操作while not q.empty(): print(q.get())输出结果为:
123在这个示例中,我们首先创建了一个Queue对象,并使用put()方法将三个元素加入队列。然后使用empty()方法检查队列是否为空,并使用get()方法逐个取出队列中的元素。
线程和队列的关系
? ?Python中的线程和队列是密切相关的,因为队列是线程之间共享数据的一种方式,可以用来在多线程环境中传递信息和实现线程之间的协作。
? 线程可以将数据放入队列中,其他线程可以从队列中获取数据。这种方式可以避免线程之间直接访问共享变量带来的并发问题,保证线程安全。
线程和队列的配合使用可以实现许多并发编程的场景,如生产者消费者模式、线程池等。生产者消费者模式是一种常见的并发模式,其中生产者线程生成数据并将其放入队列中,而消费者线程则从队列中获取数据并进行处理。通过使用队列,可以使得生产者和消费者线程之间解耦,从而实现更好的并发性能和可维护性。
线程池是另一种常见的并发模式,其中线程池维护一组线程,可以接受任务并将其放入队列中,线程池中的线程可以从队列中获取任务并进行处理。通过使用线程池和队列,可以实现更高效的任务处理,避免了线程的频繁创建和销毁,从而提高了系统的性能和可伸缩性。
生产者消费者模式
? ?Python生产者消费者模式是一种多线程编程模式,用于解决并发编程中的资源竞争和线程安全问题。
? - 在该模式中,生产者线程负责生产数据并将其放入共享缓冲区中,而消费者线程则从缓冲区中取出数据并进行处理。
? - 生产者和消费者线程之间通过一个共享的缓冲区进行通信,生产者线程将数据放入缓冲区后通知消费者线程,消费者线程从缓冲区取出数据后通知生产者线程,以此循环往复。
在Python中,可以使用Queue模块来实现生产者消费者模式。Queue是一个线程安全的队列,提供了put()和get()方法用于向队列中添加和获取数据。生产者线程通过put()方法将数据放入队列中,消费者线程通过get()方法从队列中取出数据。在多线程环境中,Queue会自动处理线程同步和锁问题,避免了资源竞争和线程安全的问题。
? 下面是一个简单的Python生产者消费者模式的示例代码:
import threadingimport timeimport queueclass Producer(threading.Thread): def __init__(self, queue): threading.Thread.__init__(self) self.queue = queue def run(self): for i in range(10): item = "item " + str(i) self.queue.put(item) print("Producer produced", item) time.sleep(1)class Consumer(threading.Thread): def __init__(self, queue): threading.Thread.__init__(self) self.queue = queue def run(self): while True: item = self.queue.get() print("Consumer consumed", item) time.sleep(2)queue = queue.Queue()producer = Producer(queue)consumer = Consumer(queue)producer.start()consumer.start()producer.join()consumer.join()在这个示例中,Producer类和Consumer类都继承了threading.Thread类,并重写了run()方法。Producer类的run()方法会循环10次,每次生成一个数据并放入队列中,并输出一条生产者生成的信息。Consumer类的run()方法会一直循环,从队列中取出数据并输出一条消费者消费的信息。
最后,创建一个队列实例,创建一个生产者线程和一个消费者线程,并启动它们。使用join()方法等待线程结束。运行以上代码,可以看到生产者线程不断地生成数据并放入队列中,消费者线程不断地从队列中取出数据并进行处理。
实战演示
王者荣耀照片下载(使用生产者消费者模式)
以王者荣耀游戏网站照片为例,我们先使用前面学到的知识来获取它。在使用生产者消费者模式之前,我们需要先用之前的方式将数据获取下来,并保证操作的争正确性,接着我们再开始使用生产者消费者模式来提高效率。
这些照片也可以直接下载,但是下载所有的照片就比较费时间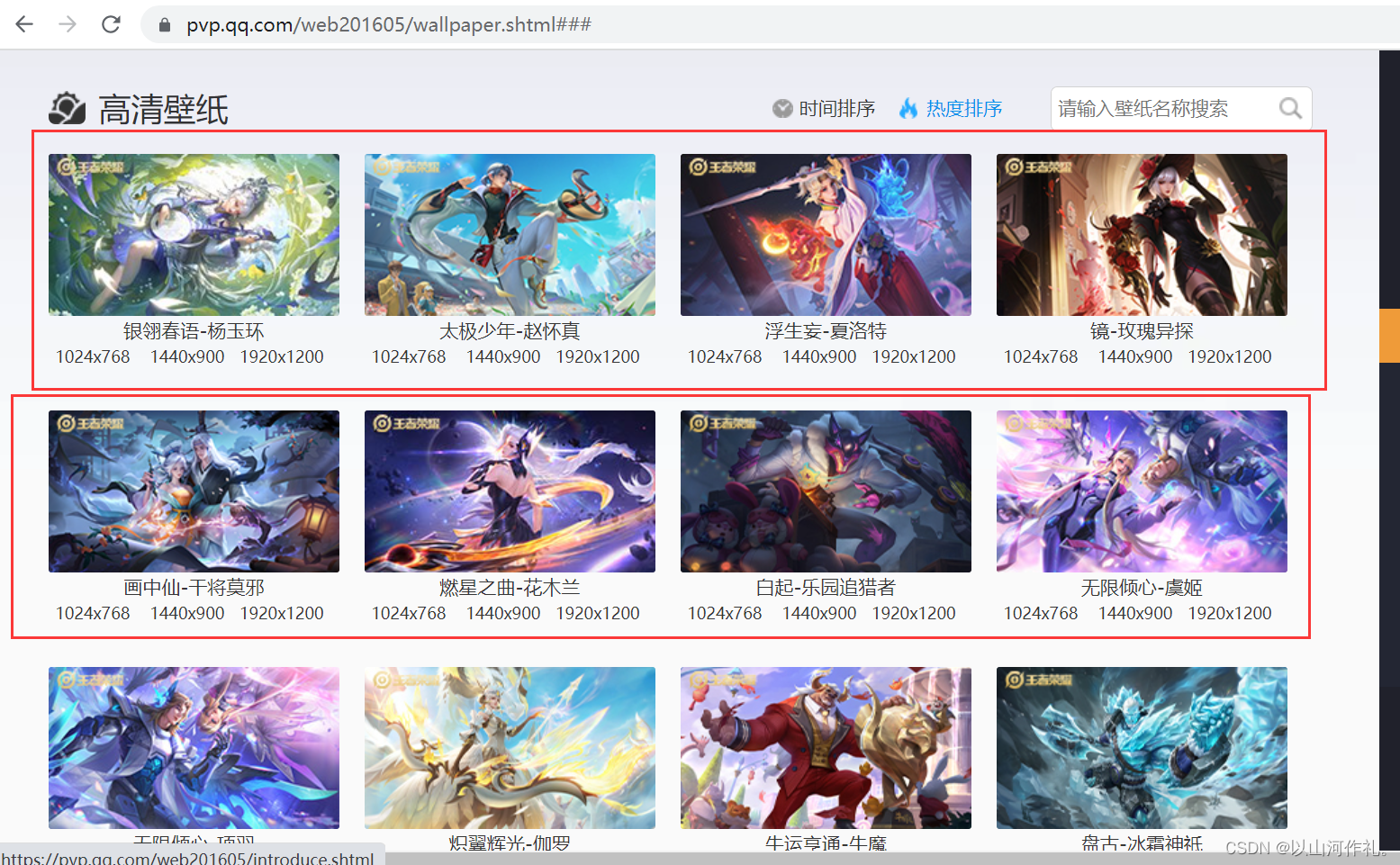
? ?使用我们之前学过的知识,我们先把包含照片数据的连接抓取下来,然后再进行解析,获取我们想要的数据,然后批量下载。
通过检查我们可以看到,左边是我们想要的照片,右边是我们检查的数据,在右边,有照片和一个文档,这个文档里面就包含我们需要的所有数据,包括照片的名字,链接等各种参数。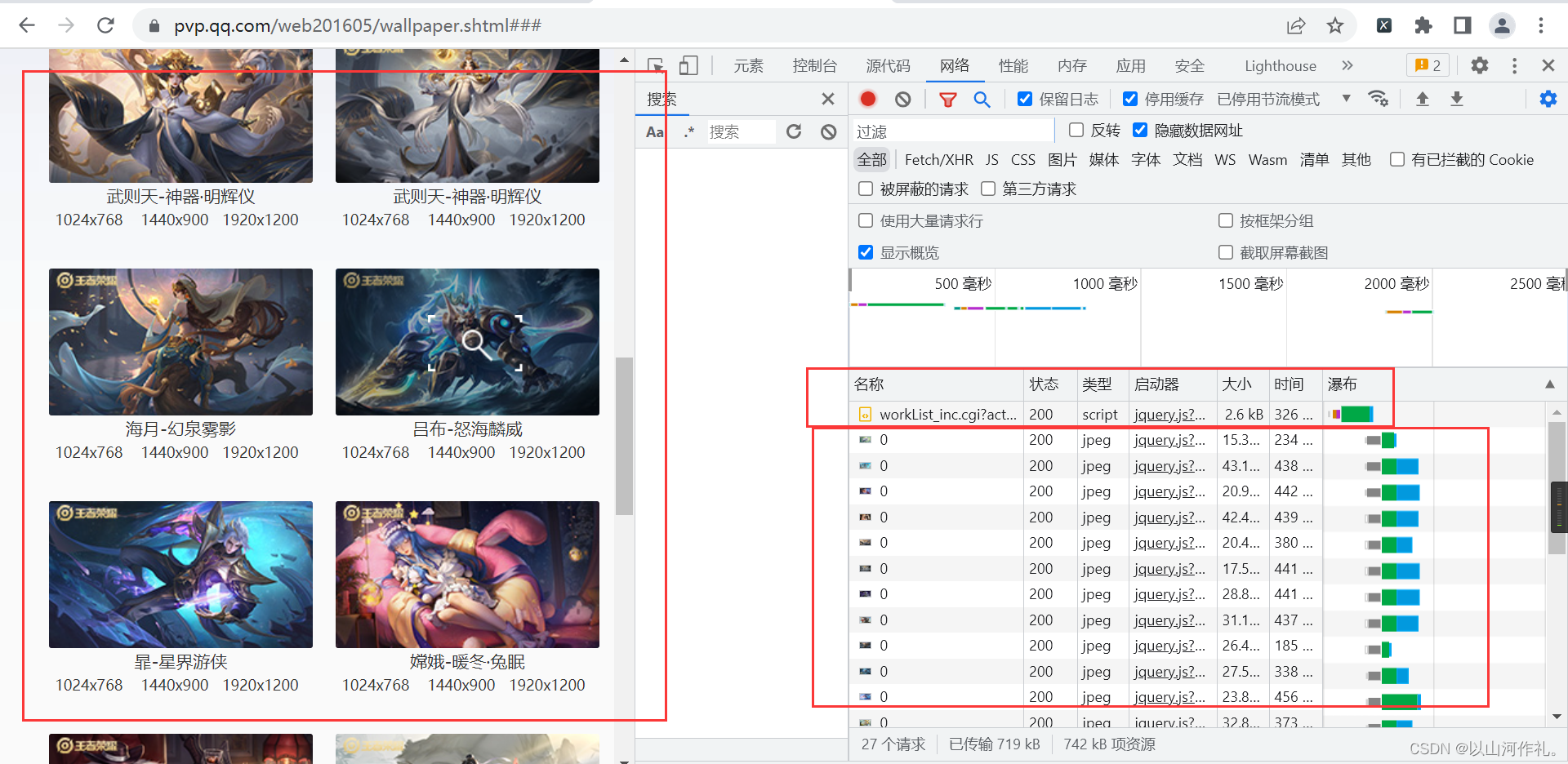
我们来查看文档。
? ?在预览中我们看到下面这些数据,在这些数据中包含的有照片各种数据,接下来我们就要进行分析,获取我们想要的数据。不过第一步还是先通过代码将这些数据获取到本地。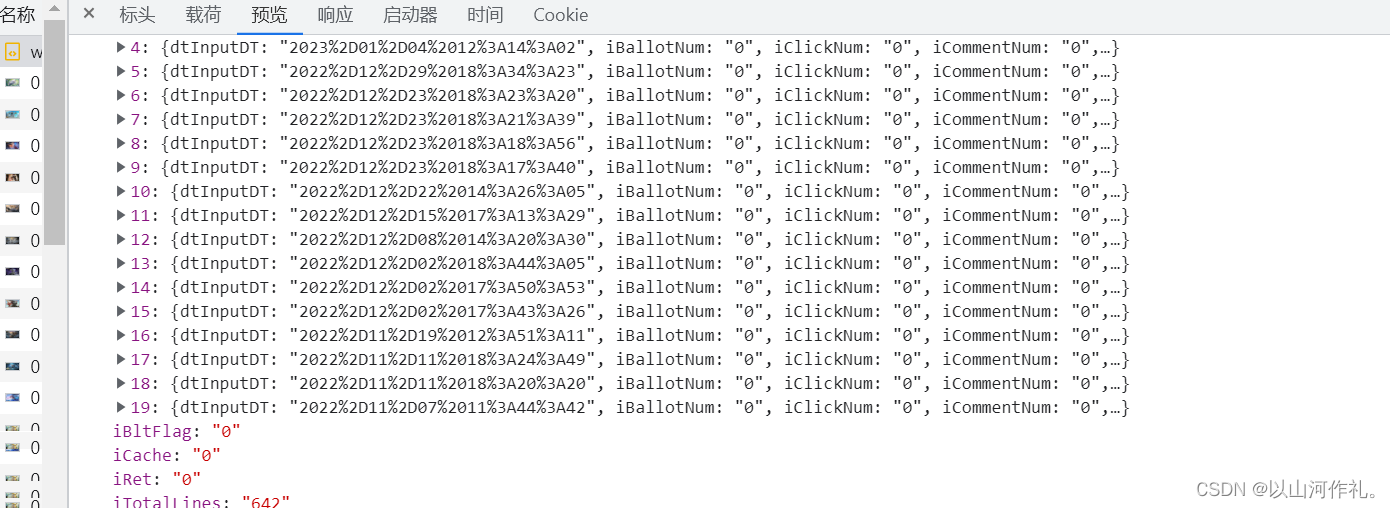

? 理论讲解完毕,我们来写代码!!
import crawlesurl = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi'cookies = { 'RK': 'dudRHvHoV7', 'ptcz': 'e9f27de6b2494bb66582be41b9fbc6f53a75342cb113935ed433754d3149db7d', 'pgv_pvid': '7146443171', 'LW_sid': 'i1M658J0m738G4r6t1c3c2G2R2', 'LW_uid': 'v1I6H8G0c7g8U4y6d1F3h2m2w9', 'eas_sid': 'O1o6S8r037g8B4S6w1c303A3Q9', 'pgv_info': 'ssid=s2960000074', 'pvpqqcomrouteLine': 'index_wallpaper_wallpaper',}headers = { 'authority': 'apps.game.qq.com', 'accept': '*/*', 'accept-language': 'zh-CN,zh;q=0.9', 'cache-control': 'no-cache', 'pragma': 'no-cache', 'referer': 'https://pvp.qq.com/', 'sec-ch-ua': '\"Not_A Brand\";v=\"99\", \"Google Chrome\";v=\"109\", \"Chromium\";v=\"109\"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '\"Windows\"', 'sec-fetch-dest': 'script', 'sec-fetch-mode': 'no-cors', 'sec-fetch-site': 'same-site', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',}params = { 'activityId': '2735', 'sVerifyCode': 'ABCD', 'sDataType': 'JSON', 'iListNum': '20', 'totalpage': '0', 'page': '1', 'iOrder': '0', 'iSortNumClose': '1', 'jsoncallback': '', 'iAMSActivityId': '51991', '_everyRead': 'true', 'iTypeId': '2', 'iFlowId': '267733', 'iActId': '2735', 'iModuleId': '2735', '_': '1680785113806',}response = crawles.get(url, headers=headers, params=params, cookies=cookies)print(response.text)? 通过上述代码,我们可以获取到刚才的数据到本地。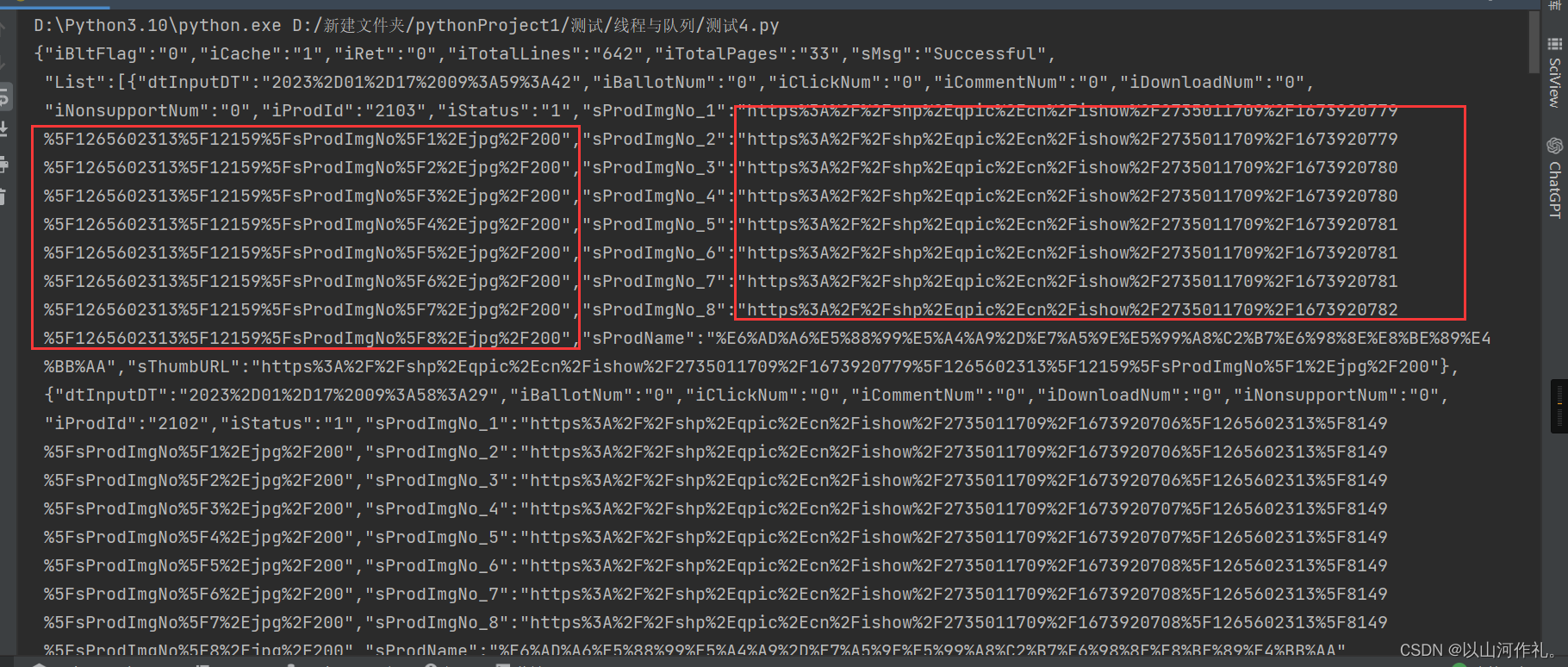
? 通过观察我们发现,数据分为两大部分,我们来对数据进行解析看看。
response = crawles.get(url, headers=headers, params=params, cookies=cookies)print(response.text)for data in response.json['List']: # 从字典中获取需要的数据 image_name = parse.unquote(data['sProdName']) image_url = str(parse.unquote(data['sProdImgNo_6'])) print(image_name, image_url)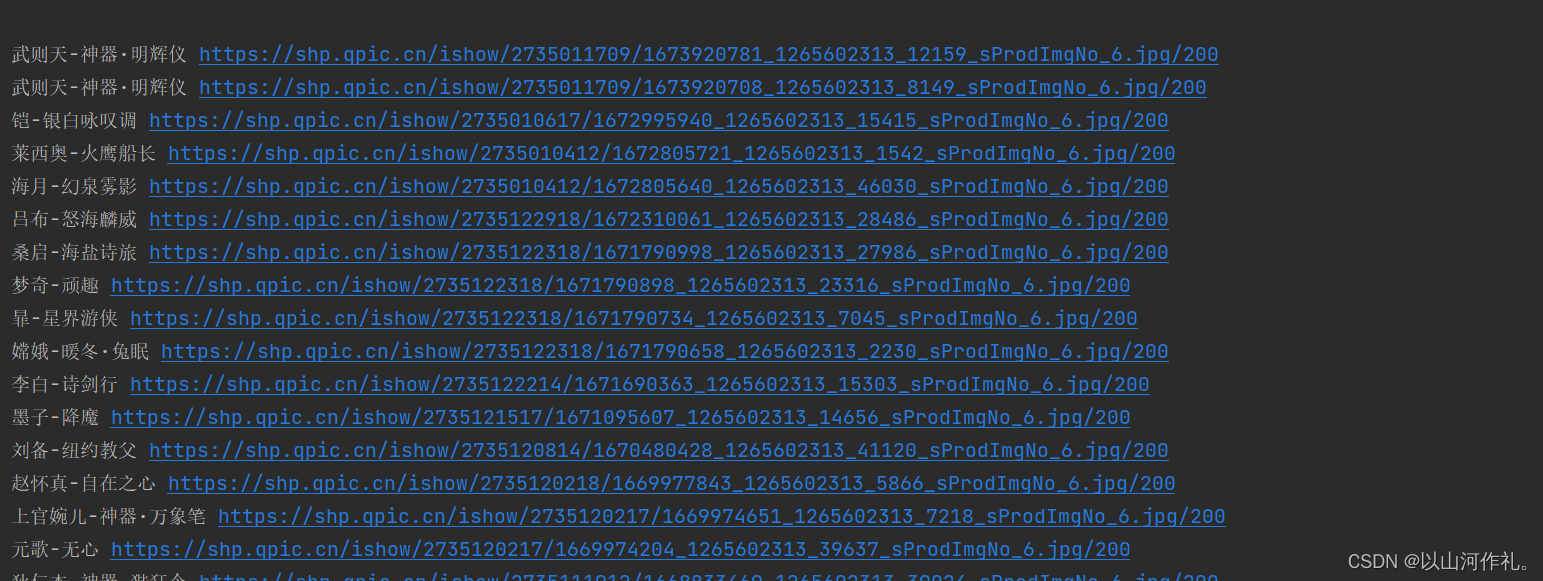
? 我们得到了一页数据,包含照片名字和照片链接,我们可以点击照片链接进去查看:
??铠-银白咏叹调
? 接着我们使用循环获取前十页的数据并保存(数据较多,且下载较慢,仅展示部分内容)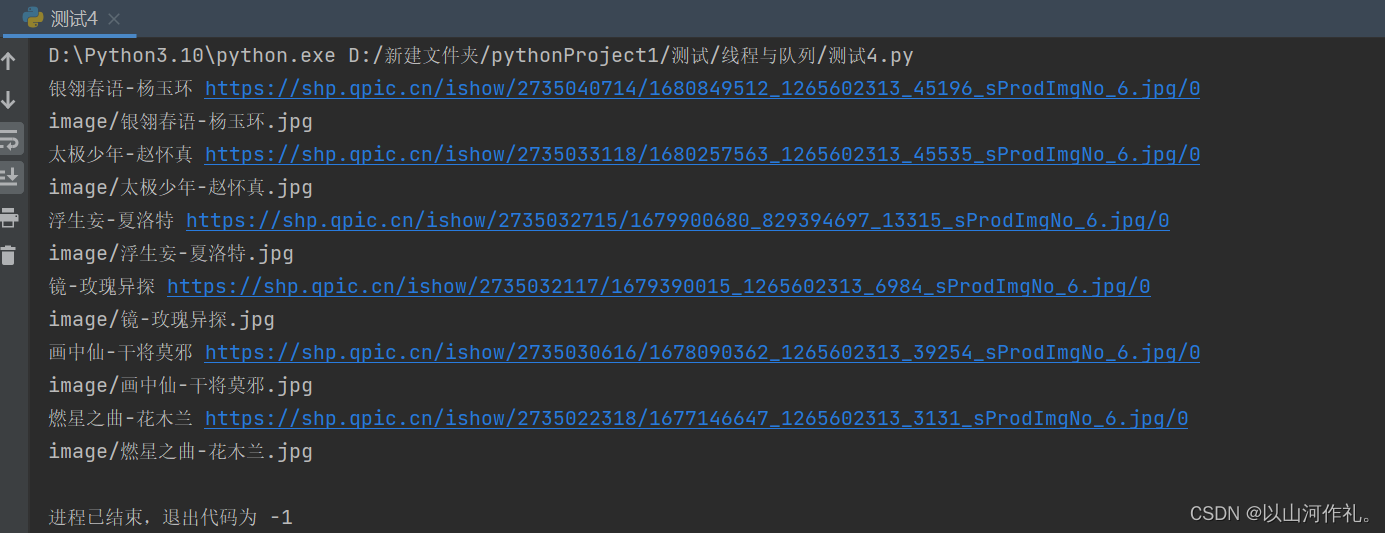
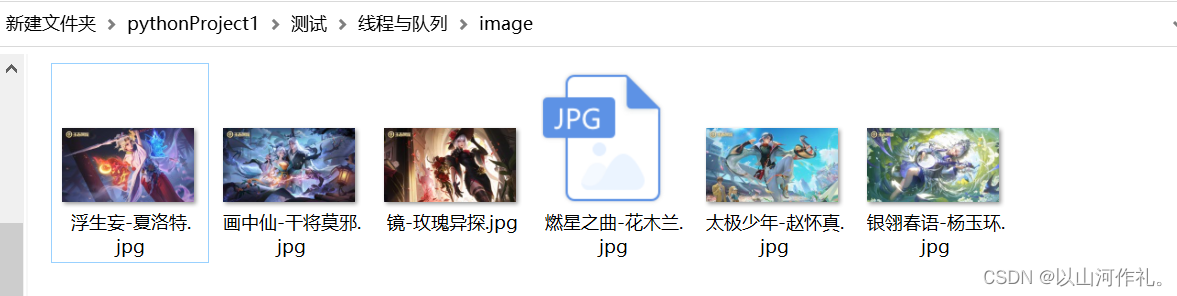
? ?到此我们完成了第一部分,接下来我们来完成第二部分,将代码封装成函数然后使用队列来操作方便我们获取数据:
? 完整代码如下:
from os.path import existsfrom queue import Queuefrom threading import Thread, BoundedSemaphorefrom urllib import parseimport crawlesq = Queue(6)lock = BoundedSemaphore(3)s = 0url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi'cookies = { 'RK': 'dudRHvHoV7', 'ptcz': 'e9f27de6b2494bb66582be41b9fbc6f53a75342cb113935ed433754d3149db7d', 'pgv_pvid': '7146443171', 'LW_sid': 'i1M658J0m738G4r6t1c3c2G2R2', 'LW_uid': 'v1I6H8G0c7g8U4y6d1F3h2m2w9', 'eas_sid': 'O1o6S8r037g8B4S6w1c303A3Q9', 'pgv_info': 'ssid=s2960000074', 'pvpqqcomrouteLine': 'index_wallpaper_wallpaper',}headers = { 'authority': 'apps.game.qq.com', 'accept': '*/*', 'accept-language': 'zh-CN,zh;q=0.9', 'cache-control': 'no-cache', 'pragma': 'no-cache', 'referer': 'https://pvp.qq.com/', 'sec-ch-ua': '\"Not_A Brand\";v=\"99\", \"Google Chrome\";v=\"109\", \"Chromium\";v=\"109\"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '\"Windows\"', 'sec-fetch-dest': 'script', 'sec-fetch-mode': 'no-cors', 'sec-fetch-site': 'same-site', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',}params = { 'activityId': '2735', 'sVerifyCode': 'ABCD', 'sDataType': 'JSON', 'iListNum': '20', 'totalpage': '0', 'page': '1', 'iOrder': '0', 'iSortNumClose': '1', 'jsoncallback': '', 'iAMSActivityId': '51991', '_everyRead': 'true', 'iTypeId': '2', 'iFlowId': '267733', 'iActId': '2735', 'iModuleId': '2735', '_': '1680785113806',}def page_data_get(page_value): """数据获取""" params['page'] = str(page_value) response = crawles.get(url, headers=headers, params=params, cookies=cookies) for data in response.json['List']: # 从字典中获取需要的数据 image_name = parse.unquote(data['sProdName']) image_url = str(parse.unquote(data['sProdImgNo_6'])).replace('.jpg/200', '.jpg/0') q.put((image_name, image_url)) # 将数据存放到队列 lock.release() # 解锁def image_save(): """保存文件""" while True: # 让线程一直存活 print(f'目前队列大小{q.qsize()}') try: # 在规定时间内没有再获取图片,代表数据获取结束 image_name, image_url = q.get(timeout=5) except: return iamge_path = f'image/{image_name}.jpg' if exists(iamge_path): # 判断图片是否存储 global s iamge_path = f'image/{image_name}_{s}.jpg' # 如果存在就修改名称 s += 1 print(iamge_path) f = open(iamge_path, 'wb') # 创建文件 f.write(crawles.get(image_url,headers=headers).content) # 请求数据 f.close() # 关闭文件 保存数据for i in range(5): # 消费者模式 先运行 t = Thread(target=image_save) t.start()for page in range(0, 10): # 生产者 lock.acquire() t = Thread(target=page_data_get, args=(page,)) t.start()? 代码讲解:
这段代码使用了生产者-消费者模式实现了多线程爬取图片数据和保存图片的功能。
for i in range(5): # 消费者模式 先运行 t = Thread(target=image_save) t.start()for page in range(0, 10): # 生产者 lock.acquire() t = Thread(target=page_data_get, args=(page,)) t.start()具体来说,使用了Python中的Thread类创建了多个线程,其中包括5个线程用于保存图片数据,以及根据需要生产的页面数创建的若干个线程用于获取图片的数据。为了防止多个线程同时访问同一资源导致数据错误,使用了Lock类来进行线程同步。
其中,生产者线程使用了page_data_get函数获取图片的数据,消费者线程使用了image_save函数来保存图片。
最终,通过多线程的并发执行,实现了高效的图片爬取和保存。
? 结果展示: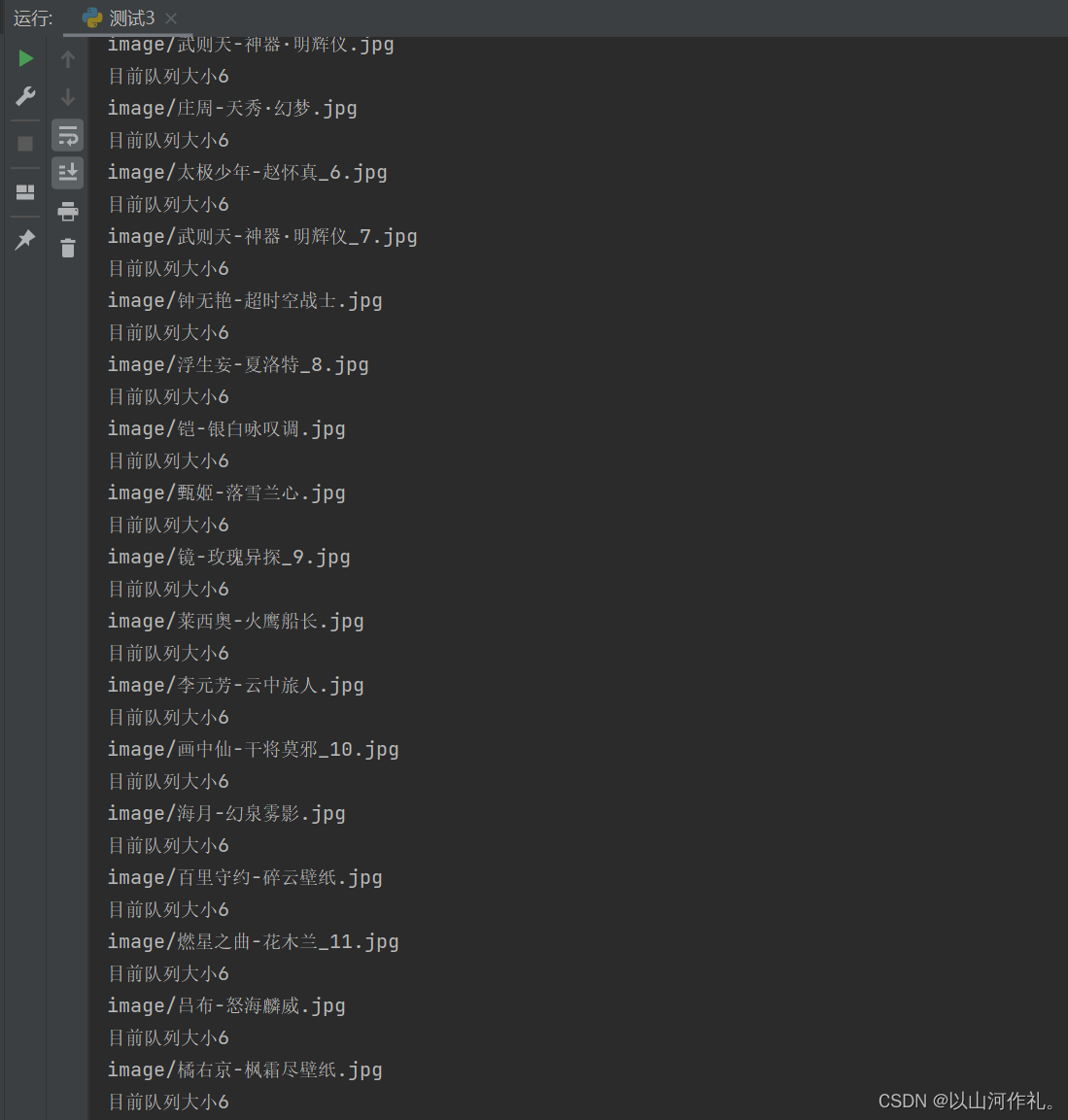
写在最后:
??本专栏所有文章是博主学习笔记,仅供学习使用,爬虫只是一种技术,希望学习过的人能正确使用它。
博主也会定时一周三更爬虫相关技术更大家系统学习,如有问题,可以私信我,没有回,那我可能在上课或者睡觉,写作不易,感谢大家的支持!!???
登录后可发表评论
点击登录