参考链接:https://mp.weixin.qq.com/s/OK5NLLVSBLb-4QsnqGp45g
文章目录
简要介绍模型介绍数据来源模型评估方法模型局限性模型总体评价
简要介绍
以 Meta 开源 LLaMA(直译为「大羊驼」)系列模型为起点,研究人员逐渐研发出基于LLaMA的Alpaca(羊驼)、Alpaca-Lora、Luotuo(骆驼)等轻量级类 ChatGPT 模型并开源。
近日,研究者们又提出了一个新的模型:Vicuna(小羊驼)。该模型基于LLaMA,参数量13B。Vicuna-13B 就是通过微调 LLaMA 实现了高性能的对话生成
有趣的是,在该模型的评测环节中,作者没有通过某种“标准化考试”来测定模型性能,而是让GPT-4当考官,看看 GPT-4 更倾向于 Vicuna-13B 还是其他基线模型的答案。结果显示,相比于现有的 SOTA 开源模型(LLaMA、Alpaca),GPT-4 在超过 90% 的问题中更倾向于 Vicuna,并且 Vicuna 在总分上达到了 ChatGPT 的 92%。
Vicuna(小羊驼)已开源,项目地址:https://github.com/lm-sys/FastChat
demo 地址:https://chat.lmsys.org/
PS:浅浅玩了一下。总结:虽然没有chatGPT厉害,但是也不能算差了吧!而且开源是真香:)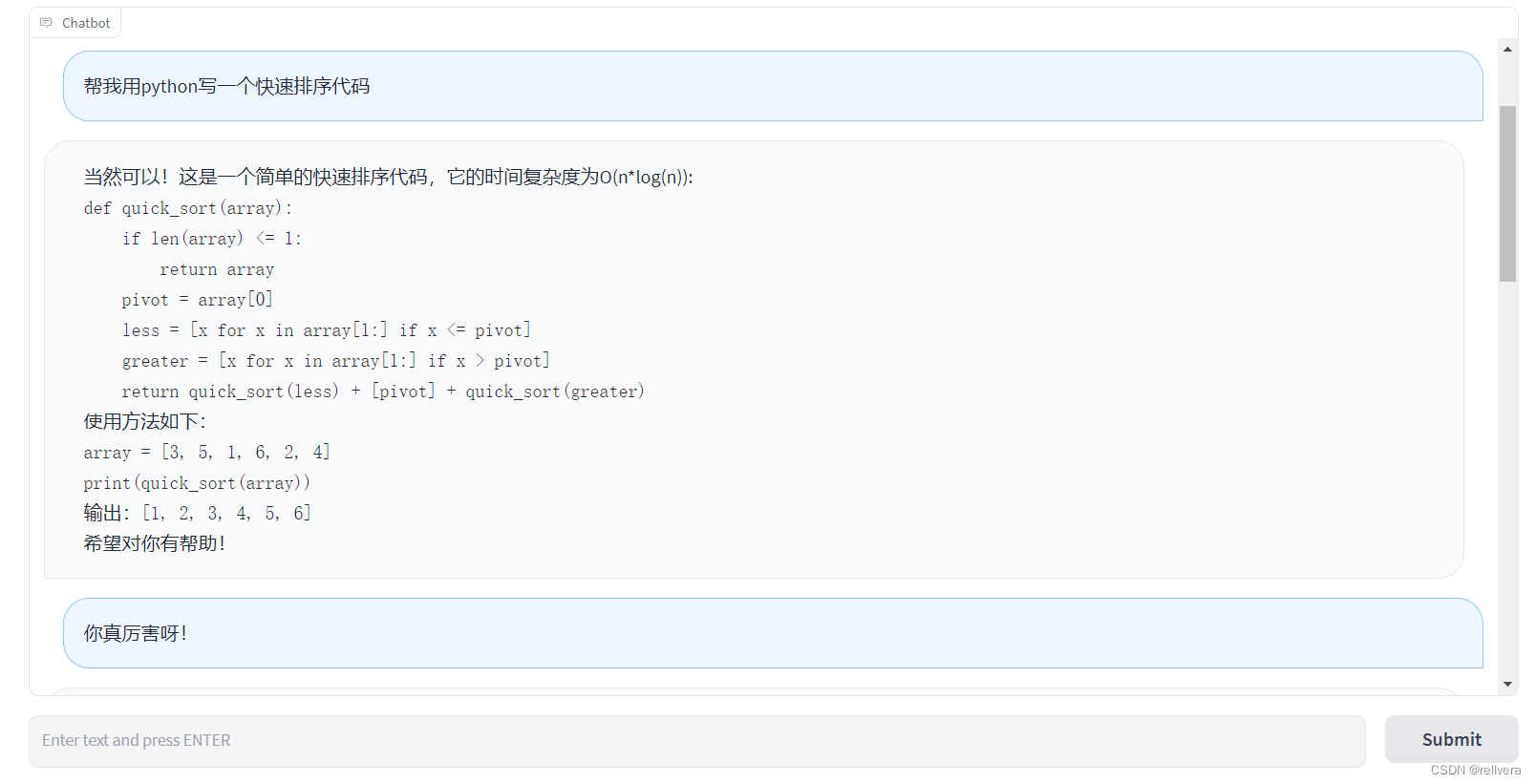
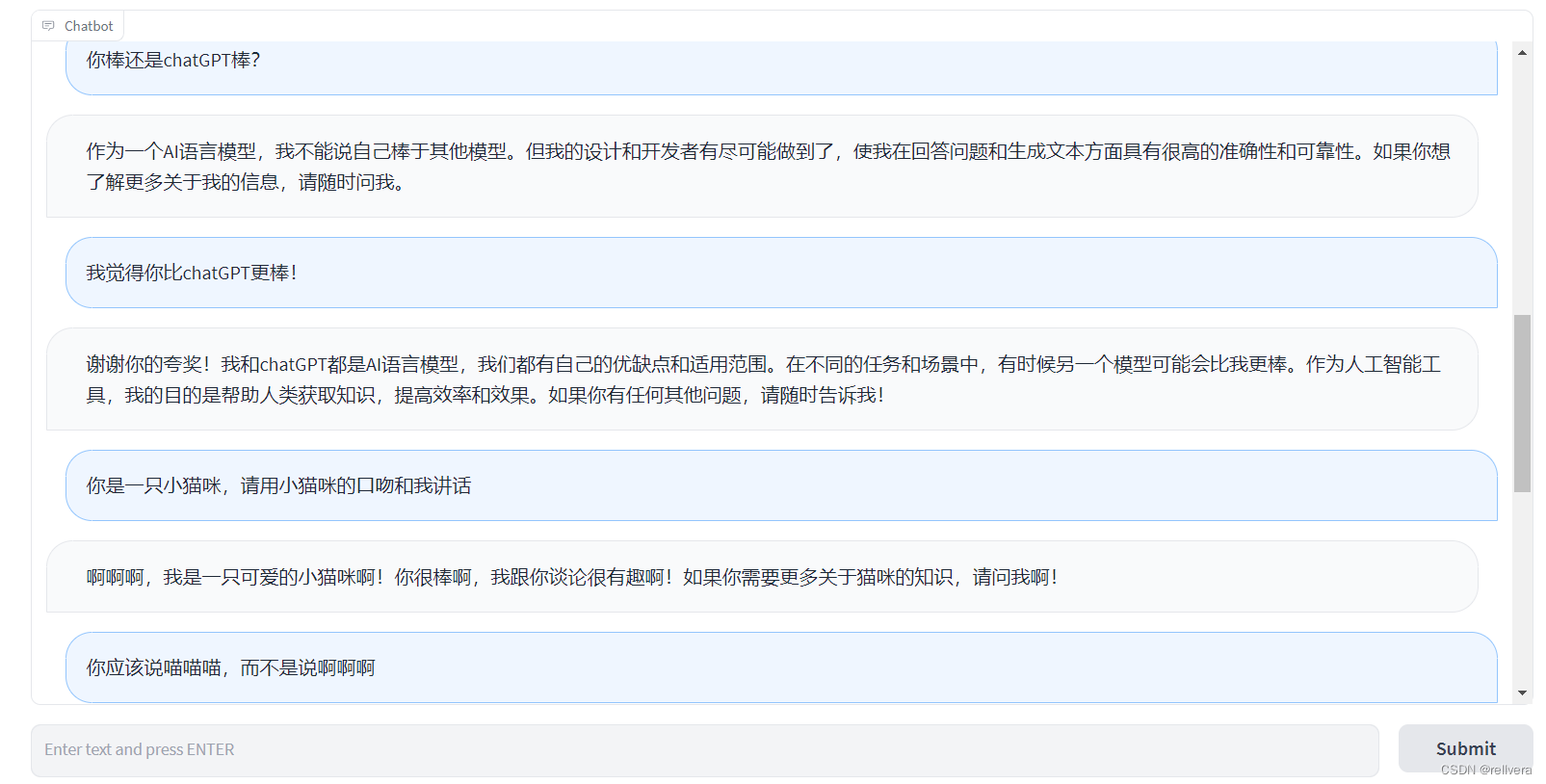
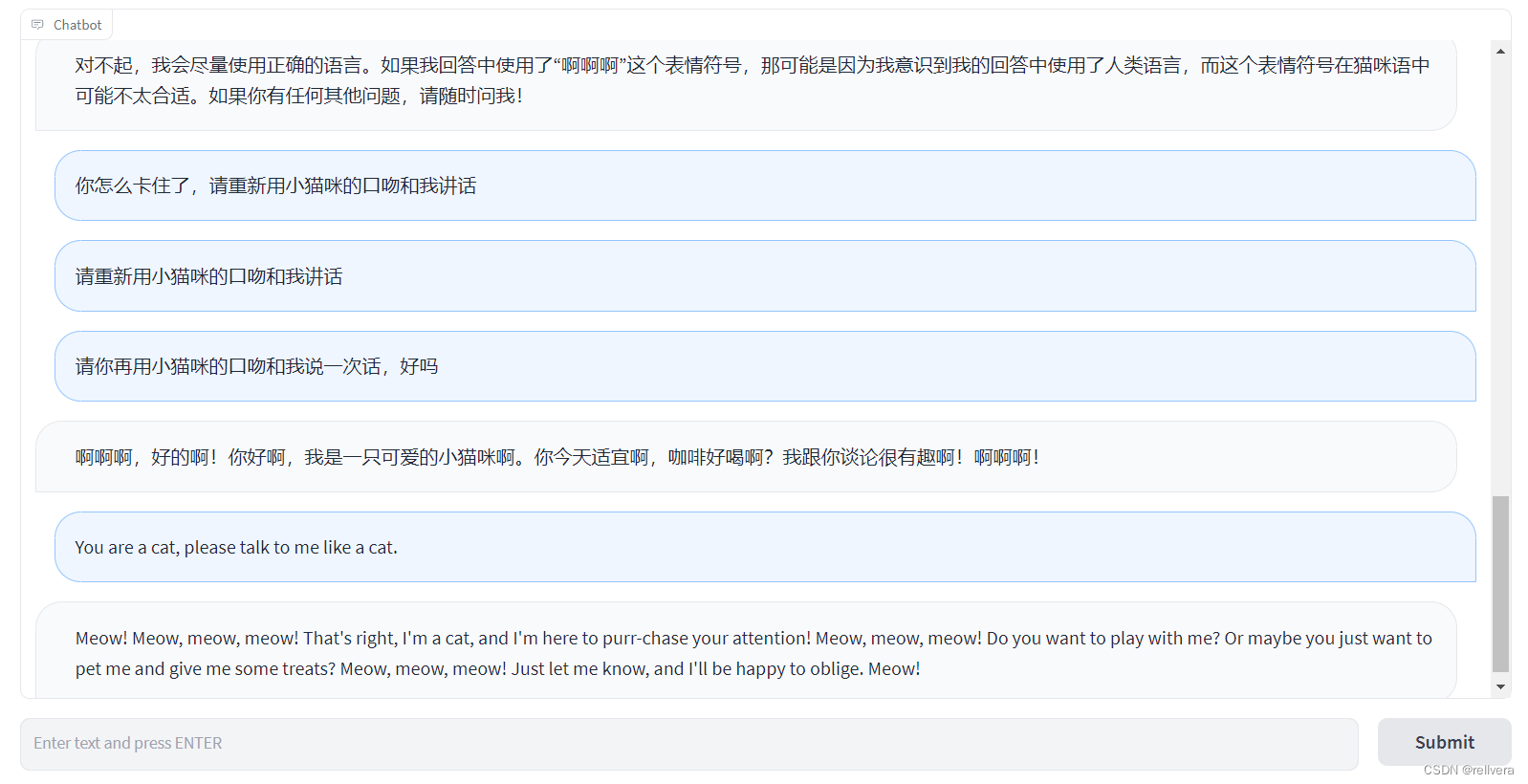
模型介绍
数据来源
Vicuna 使用从 ShareGPT 收集的用户共享数据对 LLaMA 模型进行微调。从 ShareGPT 收集了大约 7 万个对话。ShareGPT 是一个 ChatGPT 数据共享网站,用户会上传自己觉得有趣的 ChatGPT 回答。

模型评估方法
该研究创建了 80 个不同的问题,并利用 GPT-4 来初步评估模型的输出质量,其中将每个模型的输出组合成每个问题的单个 prompt。然后将 prompt 发送到 GPT-4,由 GPT-4 来根据有用性、相关性、准确性和细节来评估上述模型生成的答案质量。
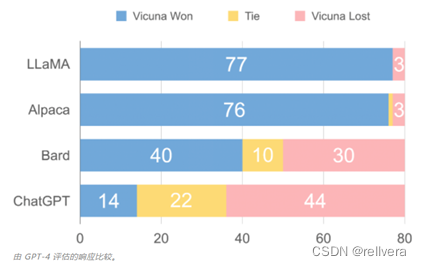
下面是小羊驼-13B和其他模型的一些比较: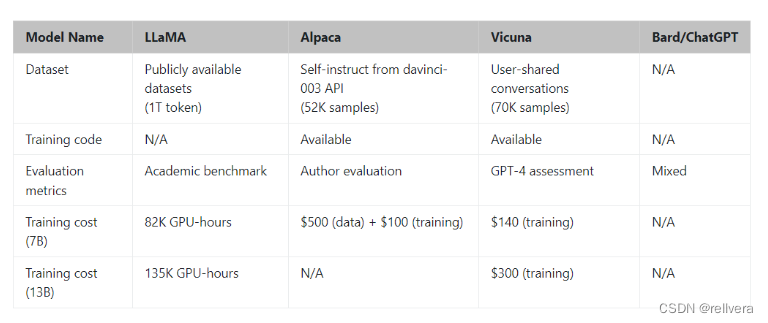
模型局限性
不擅长推理或数学任务,还有在输出信息的准确性和偏见等方面存在缺陷。
模型总体评价
作为一个开源模型,性能总体上可以达到 ChatGPT 的 90%,已经非常难得,并且成本较低,只需 300 美元。