目录
一、brk()系统调用
1、brk()的申请方式
2、brk()系统调用的优缺点
3、brk()系统调用的优化
二、mmap()系统调用
1、mmap基础概念
2、mmap 内存映射原理
3、mmap优点
4、适用场景
我们知道malloc() 并不是系统调用,也不是运算符,而是 C 库里的函数,用于动态分配内存。
malloc 申请内存的时候,会有两种方式向操作系统申请堆内存:
方式一:通过 brk() 系统调用从堆分配内存方式二:通过 mmap() 系统调用在文件映射区域分配内存;一、brk()系统调用
1、brk()的申请方式
一般如果用户分配的内存小于 128 KB,则通过 brk() 申请内存。而brk()的实现的方式很简单,就是通过 brk() 函数将堆顶指针向高地址移动,获得新的内存空间。如下图:
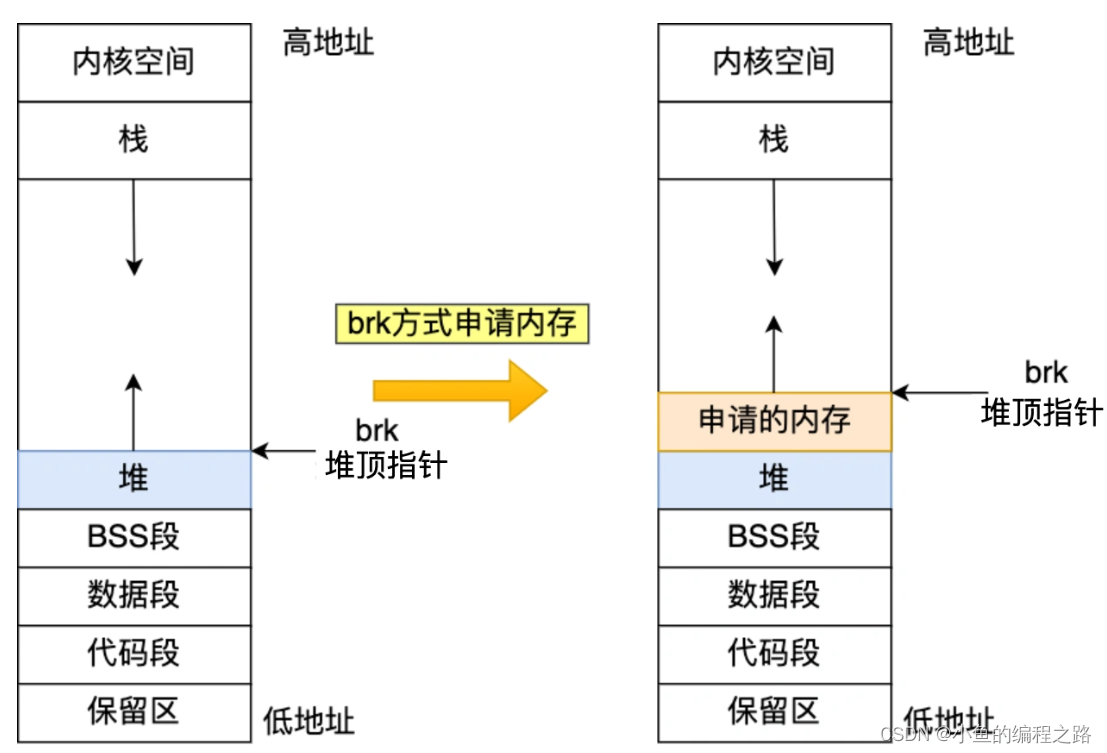
malloc 通过 brk() 方式申请的内存,free 释放内存的时候,并不会把内存归还给操作系统,而是缓存在 malloc 的内存池中,待下次使用,这样就可以重复使用。
2、brk()系统调用的优缺点
所以使用brk()方式的点很明显:可以减少缺页异常的发生,提高内存访问效率。
但它的缺点也同样明显:由于申请的内存没有归还系统,在内存工作繁忙时,频繁的内存分配和释放会造成内存碎片。brk()方式之所以会产生内存碎片,是由于brk通过移动堆顶的位置来分配内存,并且使用完不会立即归还系统,重复使用,如果高地址的内存不释放,低地址的内存是得不到释放的。
正是由于使用brk()会出现内存碎片,所以在我们申请大块内存的时候才会使用mmap()方式,mmap()是以页为单位进行内存分配和管理的,释放后就直接归还系统了,所以不会出现这种小碎片的情况。
3、brk()系统调用的优化
一、Ptmalloc :malloc采用的是内存池的管理方式,Ptmalloc 采用边界标记法将内存划分成很多块,从而对内存的分配与回收进行管理。为了内存分配函数malloc的高效性,ptmalloc会预先向操作系统申请一块内存供用户使用,当我们申请和释放内存的时候,ptmalloc会将这些内存管理起来,并通过一些策略来判断是否将其回收给操作系统。这样做的最大好处就是,使用户申请和释放内存的时候更加高效,避免产生过多的内存碎片。
二、Tcmalloc:Ptmalloc在性能上还是存在一些问题的,比如不同分配区(arena)的内存不能交替使用,比如每个内存块分配都要浪费8字节内存等等,所以一般倾向于使用第三方的malloc。
Tcmalloc是Google gperftools里的组件之一。全名是 thread cache malloc(线程缓存分配器)其内存管理分为线程内存和中央堆两部分。
1.小块内部的分配:对于小块内存分配,其内部维护了60个不同大小的分配器(实际源码中看到的是86个),和ptmalloc不同的是,它的每个分配器的大小差是不同的,依此按8字节、16字节、32字节等间隔开。在内存分配的时候,会找到最小符合条件的,比如833字节到1024字节的内存分配请求都会分配一个1024大小的内存块。如果这些分配器的剩余内存不够了,会向中央堆申请一些内存,打碎以后填入对应分配器中。同样,如果中央堆也没内存了,就向中央内存分配器申请内存。
在线程缓存内的60个分配器分别维护了一个大小固定的自由空间链表,直接由这些链表分配内存的时候是不加锁的。但是中央堆是所有线程共享的,在由其分配内存的时候会加自旋锁(spin lock)。
2.大内存的分配:对于大内存分配(大于8个分页, 即32K),tcmalloc直接在中央堆里分配。中央堆的内存管理是以分页为单位的,同样按大小维护了256个空闲空间链表,前255个分别是1个分页、2个分页到255个分页的空闲空间,最后一个是更多分页的小的空间。这里的空间如果不够用,就会直接从系统申请了。
3.ptmalloc与tcmalloc的不足:都是针对小内存分配和管理;对大块内存还是直接用了系统调用。应该尽量避免大内存的malloc/new、free/delete操作。频繁分配小内存,例如:对bool、int、short进行new的时候,造成内存浪费。
三、Jemalloc: jemalloc 是由 Jason Evans 在 FreeBSD 项目中引入的新一代内存分配器。它是一个通用的malloc实现,侧重于减少内存碎片和提升高并发场景下内存的分配效率,其目标是能够替代 malloc。下面是Jemalloc的两个重要部分:
1.arena:arena 是 jemalloc 最重要的部分,内存由一定数量的 arenas 负责管理。每个用户线程都会被绑定到一个 arena 上,线程采用 round-robin 轮询的方式选择可用的 arena 进行内存分配,为了减少线程之间的锁竞争,默认每个 CPU 会分配 4 个 arena,各个 arena 所管理的内存相互独立。
struct arena_s { atomic_u_tnthreads[2];tsdn_t*last_thd; arena_stats_tstats; // arena的状态 ql_head(tcache_t)tcache_ql;ql_head(cache_bin_array_descriptor_t)cache_bin_array_descriptor_ql;malloc_mutex_ttcache_ql_mtx; prof_accum_tprof_accum;uint64_tprof_accumbytes; atomic_zu_toffset_state; atomic_zu_textent_sn_next; // extent的序列号生成器状态 atomic_u_tdss_prec; atomic_zu_tnactive; // 激活的extents的page数量 extent_list_tlarge; // 存放 large extent 的 extents malloc_mutex_tlarge_mtx; // large extent的锁 extents_t extents_dirty; // 刚被释放后空闲 extent 位于的地方 extents_t extents_muzzy; // extents_dirty 进行 lazy purge 后位于的地方,dirty -> muzzy extents_t extents_retained; // extents_muzzy 进行 decommit 或 force purge 后 extent 位于的地方,muzzy -> retained arena_decay_tdecay_dirty; // dirty --> muzzy arena_decay_tdecay_muzzy; // muzzy --> retained pszind_textent_grow_next;pszind_tretain_grow_limit;malloc_mutex_textent_grow_mtx; extent_tree_textent_avail; // heap,存放可用的 extent 元数据 malloc_mutex_textent_avail_mtx; // extent_avail的锁 bin_tbins[NBINS]; // 所有用于分配小内存的 bin base_t*base; // 用于分配元数据的 base nstime_tcreate_time; // 创建时间};2.extent:管理 jemalloc 内存块(即用于用户分配的内存)的结构,每一个内存块大小可以是 N * page_size(4KB)(N >= 1)。每个 extent 有一个序列号(serial number)。一个 extent 可以用来分配一次 large_class 的内存申请,但可以用来分配多次 small_class 的内存申请。
struct extent_s { uint64_te_bits; // 8字节长,记录多种信息 void*e_addr; // 管理的内存块的起始地址 union {size_te_size_esn; // extent和序列号的大小size_te_bsize; // 基本extent的大小}; union {/* * S位图,当此 extent 用于分配 small_class 内存时,用来记录这个 extent 的分配情况, * 此时每个 extent 的内的小内存称为 region */arena_slab_data_te_slab_data; atomic_p_te_prof_tctx; // 一个计数器,用于large object};}二、mmap()系统调用
1、mmap基础概念
mmap 是一种内存映射文件的方法,即将一个文件或者其他对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一映射关系。
实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必调用read,write等系统调用函数。相反,内核空间的这段区域的修改也直接反映用户空间,从而可以实现不同进程的文件共享。如下图所示:
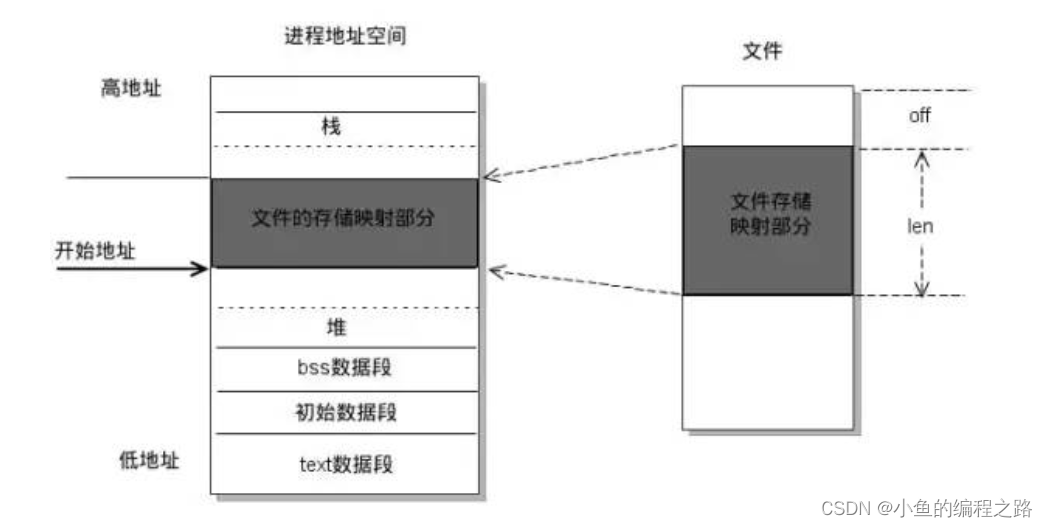
由上图可以看出,进程的虚拟地址空间,由多个虚拟内存区域构成。虚拟内存区域是进程的虚拟地址空间中的一个同质区间,即具有同样特性的连续地址范围。上图中所示的text数据段、初始数据段、Bss数据段、堆、栈、内存映射,都是一个独立的虚拟内存区域。而为内存映射服务的地址空间处在堆栈之间的空余部分。
linux 内核使用的vm_area_struct 结构来表示一个独立的虚拟内存区域,由于每个不同质的虚拟内存区域功能和内部机制不同;因此同一个进程使用多个vm_area_struct 结构来分别表示不同类型的虚拟内存区域。各个vm_area_struct 结构使用链表或者树形结构链接,方便进程快速访问。如下图所示:
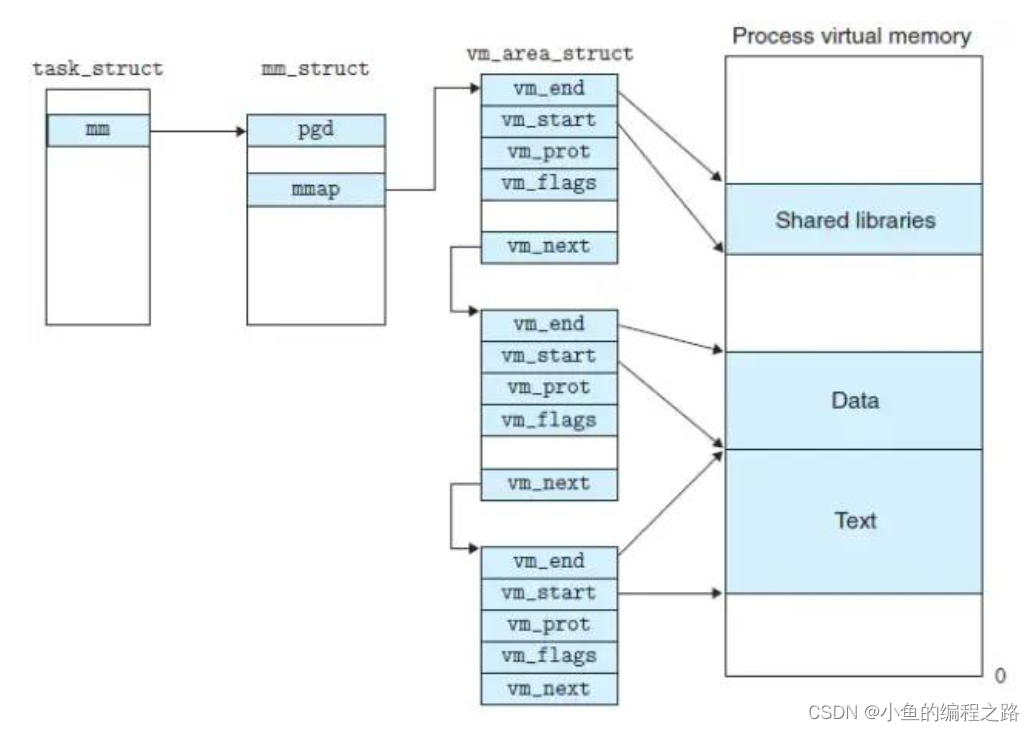
vm_area_struct 结构中包含区域起始和终止地址以及其他相关信息,同时也包含一个vm_ops 指针,其内部可引出所有针对这个区域可以使用的系统调用函数。这样,进程对某一虚拟内存区域的任何操作都需要的信息,都可以从vm_area_struct 中获得。mmap函数就是要创建一个新的vm_area_struct结构 ,并将其与文件的物理磁盘地址相连。
2、mmap 内存映射原理
mmap 内存映射实现过程,总的来说可以分为三个阶段:
(一)进程启动映射过程,并在虚拟地址空间中为映射创建虚拟映射区域
1、进程在用户空间调用函数mmap ,原型:void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
2、在当前进程虚拟地址空间中,寻找一段空闲的满足要求的连续的虚拟地址
3、为此虚拟区分配一个vm_area_struct 结构,接着对这个结构各个区域进行初始化
4、将新建的虚拟区结构(vm_area_struct)插入进程的虚拟地址区域链表或树中
(二)调用内核空间的系统调用函数mmap (不同于用户空间函数),实现文件物理地址和进程虚拟地址的一一映射关系
5、为映射分配新的虚拟地址区域后,通过待映射的文件指针,在文件描述符表中找到对应的文件描述符,通过文件描述符,链接到内核“已打开文集”中该文件结构体,每个文件结构体维护者和这个已经打开文件相关各项信息。
6、通过该文件的文件结构体,链接到file_operations模块,调用内核函数mmap,其原型为:int mmap(struct file *filp, struct vm_area_struct *vma),不同于用户空间库函数。
7、内核mmap函数通过虚拟文件系统inode模块定位到文件磁盘物理地址。
8、通过remap_pfn_range函数建立页表,即实现了文件地址和虚拟地址区域的映射关系。此时,这片虚拟地址并没有任何数据关联到主存中。
(三)进程发起对这片映射空间的访问,引发缺页异常,实现文件内容到物理内存(主存)的拷贝。
前两个阶段仅在于创建虚拟区间并完成地址映射,但是并没有将任何文件数据拷贝至主存。真正的文件读取是当进程发起读或者写操作时。
9、进程的读写操作访问虚拟地址空间这一段映射地址后,通过查询页表,先这一段地址并不在物理页面。因为目前只建立了映射,真正的硬盘数据还没有拷贝到内存中,因此引发缺页异常。
10、缺页异常进行一系列判断,确定无法操作后,内核发起请求掉页过程。
11、调页过程先在交换缓存空间中寻找需要访问的内存页,,如果没有则调用nopage函数把所缺的页从磁盘装入到主存中。
12、之后进程即可对这片主存进行读或者写的操作了,如果写操作改变了内容,一定时间后系统自动回写脏页面到对应的磁盘地址,也即完成了写入到文件的过程。
注:修改过的脏页面并不会立即更新回文件,而是有一段时间延迟,可以调用msync() 来强制同步,这样所写的内容就能立即保存到文件里了。
3、mmap优点
1、对文件的读取操作跨过了页缓存,减少了数据的拷贝次数,用内存读写取代了I/O读写,提高了读取的效率。
2、实现了用户空间和内核空间的高校交互方式,两空间的各自修改操作可以直接反映在映射的区域内,从而被对方空间及时捕捉。
3、提供进程间共享内存及互相通信的方式。不管是父子进程还是无亲缘关系进程,都可以将自身空间用户映射到同一个文件或者匿名映射到同一片区域。从而通过各自映射区域的改动,打到进程间通信和进程间共享的目的。
同时,如果进程A和进程 B 都映射了区域C,当A第一次读取C时候,通过缺页从磁盘复制文件页到内存中,但当B再读C的相同页面时,虽然也会产生缺页异常,但是不会从磁盘中复制文件过来,而是直接使用已经保存再内存中的文件数据。
4、适用场景
可用于实现高效的大规模数据传输。内存空间不足,是制约大数据操作的一个方面,解决方案往往是借助于硬盘空间的协助,补充内存的不足。但是进一步造成大量的文件I/O操作,极大影响效率。这个问题可以通过mmap映射很好地解决。换句话说,但凡需要磁盘空间代替内存的时候,mmap都可以发挥功效。