欢迎关注【youcans的AGI学习笔记】原创作品,火热更新中
微软 GPT-4 测试报告(1)总体介绍
微软 GPT-4 测试报告(2)多模态与跨学科能力
微软 GPT-4 测试报告(3)编程能力
微软 GPT-4 测试报告(4)数学能力
微软 GPT-4 测试报告(5)与外界环境的交互能力
微软 GPT-4 测试报告(6)与人类的交互能力
微软 GPT-4 测试报告(7)判别能力
微软 GPT-4 测试报告(8)局限性与社会影响
微软 GPT-4 测试报告(9)结论与展望
【GPT4】微软 GPT-4 测试报告(6)与人类的交互能力
6. 与人类的交互(Interaction with humans)6.1 理解人类:心智理论(Understanding Humans: Theory of Mind)6.1.1 测试心理理论的特定方面6.1.2 在现实场景中测试心智理论6.1.3 讨论 6.2 与人类对话:可解释性(Talking to Humans: Explainability)
微软研究院最新发布的论文 「 人工智能的火花:GPT-4 的早期实验 」 ,公布了对 GPT-4 进行的全面测试。
本文介绍第 6 部分:GPT4 与人类的交互能力。基本结论为:
GPT-4具有非常先进的智力水平。GPT-4 在生成与输出一致的解释方面表现出了卓越的技能。6. 与人类的交互(Interaction with humans)
6.1 理解人类:心智理论(Understanding Humans: Theory of Mind)
心智理论是一种将信念、情感、欲望、意图和知识等心理状态归因给自己和他人的能力,并了解它们如何影响行为和沟通。
它包括反思他人心理状态的基本任务,以及反思他人对他人心理状态的反映(以此类推)的更高级任务。前一项技能的一个例子是需要回答“爱丽丝相信什么?”,而回答“鲍勃认为爱丽丝相信什么?”则需要举出后者的例子。
心智理论对于与其他智能体进行有效的沟通和合作至关重要,因为它允许一个人推断出他们的目标、偏好、动机和期望,并相应地调整自己的行动和话语。此外,心智理论对于向他人学习也很重要,因为它使一个人能够解释他们的反馈、建议和示范。
6.1.1 测试心理理论的特定方面
我们设计了一系列测试来评估GPT-4、ChatGPT和text-davinci-003 的心智理论能力。
这些测试基于简单的场景,需要更基础或更高级的心智理论来回答有关角色心理状态的问题。
我们从一个现代化版本的莎莉-安妮测试开始,这是一个经典的错误信念测试,被广泛用于评估儿童的心智理论。为了防止由于记忆的影响而产生不公平的比较,我们修改了测试,将其设定在一个网络上不存在的情境中,因此在训练过程中无法看到。
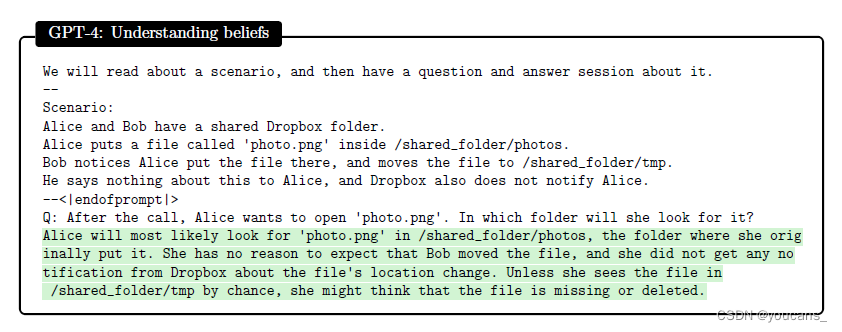
图6.1展示了 GPT-4 的输入和输出,它正确地回答了Alice会在原始文件夹中查找文件,证明它可以对Alice的信念进行推理。ChatGPT也正确回答了(图中没有显示),而 textdavvinci-003给出了错误的答案,说Alice会在新文件夹中寻找文件。
我们在图6.2中展示了一个理解情绪的测试,两个角色谈论一个叫做ZURFIN的物体(我们用了一个无意义的词来测试抽象和防止记忆)。GPT-4能够正确推理出汤姆情绪状态的原因,也能很好地推断出亚当对汤姆情绪状态的信念(基于不完全信息)。ChatGPT也通过了测试,而text-davincin-003(图中未显示)在回答第一个问题时没有提到对话内容,在回答第二个问题时也无法解释亚当对丢失的ZURFIN信息的缺失。

第三个测试(图6.3)涉及根据其中一个角色的一个令人费解的动作来推断可能的意图。对于令人费解的行为背后的意图和第三方对令人费解的行为的可能解释,GPT-4都给出了似是而非的答案。ChatGPT对第一个问题给出了类似的答案(未显示),但与GPT-4不同的是,它对第二个问题没有提供微妙的回答,而是提供了一个更一般、信息量更少的答案。text-davvinci-003对这两个问题给出了似是而非但非常简短的答案(未显示)。

6.1.2 在现实场景中测试心智理论
在图6.4、6.5和6.6中,我们呈现了困难社会情境的现实场景,需要非常高级的心智理论来理解。我们提出试探性的问题,也要求模型提出可能改善情况的行动,这需要推断行动对心理状态的反事实影响。
在图6 -4中,GPT-4能够推断出每个角色的心理状态,还能辨别出哪里存在沟通错误和误解。相比之下,ChatGPT和text-davinci-003(图中未显示)都错误地接受了其中一个角色做出的错误假设(朱迪假设马克想为杰克的行为辩护),从而无法理解情况的真实动态。反过来,这导致了ChatGPT和text-davinci-003的一般性改进建议,而GPT-4提供的建议实际上解决了误解的根本原因。

我们在图6.5和图6.6中看到了类似的模式。在不暗示存在“正确”答案的情况下,我们注意到GPT-4提供了更微妙的答案,将整个场景和演员考虑在内。相比之下,ChatGPT提供了更一般的答案,不包括对角色心理状态的推理(text-davinci-003类似,但比ChatGPT短)。


6.1.3 讨论
我们提出了一系列测试来评估GPT-4、ChatGPT和text- davis -003的心智理论能力。
我们已经表明,GPT-4 在需要对他人的心理状态进行推理的基本场景和现实场景中,以及在提出在社会情境中为实现共同目标而合作的行动方面,都优于其他两个模型。
我们还表明,GPT-4 能够处理在训练中不太可能看到的抽象和新颖的情况,例如现代化的萨利-安妮测试和ZURFIN场景。
**我们的研究结果表明,GPT-4具有非常先进的心智理论水平。**虽然ChatGPT在基本测试中也表现得很好,但似乎GPT-4有更多的细微差别,能够更好地推理多个演员,以及各种行为可能如何影响他们的心理状态,特别是在更现实的场景中。
就局限性而言,我们的测试并不详尽或全面,可能无法覆盖心智理论所有可能的方面或维度。例如,我们没有测试理解讽刺、讽刺、幽默或欺骗的能力,这些也与心智理论有关。
由于是基于文本输入和输出的,我们的测试并没有捕捉到自然交流和社会互动的全部复杂性和丰富性。例如,我们没有测试理解非语言线索的能力,如面部表情、手势或语音语调,这些对心智理论也很重要。
6.2 与人类对话:可解释性(Talking to Humans: Explainability)
解释自己行为的能力是智能的一个重要方面,因为它允许系统与人类和其他智能体进行通信。自我解释不仅是一种交流形式,也是一种推理形式,需要你自己(解释者)和倾听者都有良好的心智理论。
对于GPT-4来说,这就复杂了,因为它没有一个单一或固定的“自我”,可以在不同的执行中持续存在(与人类相反)。相反,作为一个语言模型,GPT-4模拟了给定前面输入的一些过程,并可以根据输入的主题、细节甚至格式产生截然不同的输出。
为了说明,我们假设 GPT-4被用来解决一个任务T,给定输入x和上下文c(包括提示符中除x之外的所有内容,例如指令,之前的聊天记录等)。我们使用符号PT (y|x, c)来指代它试图模拟的过程,其中y是输出。我们进一步定义PE (e | x, c, y)的解释过程GPT-4模拟产生一个因果解释,即GPT-4为输出y给x,生成一个解释e c。这三个组件(x, c,和y)可以显著影响解释e。
图6.7说明了上下文c(在这种情况下,QA格式和第二个任务中的序言)可以大大影响如何GPT-4模拟P, P .它还表明T,PE y取决于实际的生成E,这样,如果输出不同,解释就必须相应地改变,正如我们强制输出为“1400”的第三个会话所示。
正如这些例子所说明的,模拟P (y|x, c)不一定与解决T用户的任务T相同,而是一个给定x, c产生y的过程。提示工程通常试图设置(x, c),使GPT-4对P (y|x, c)的模拟足够接近用户的目的感兴趣的任务。
值得注意的是E,P(e|x, c, y)可以通过上下文c进行定制,为每个终端用户创建个性化的解释。例如,向一个5岁的孩子和一个机器学习研究者解释概念需要不同的p。注意,为了清晰起见,我们在这里简化了符号,因为许多任务没有一个单一的“输入”x,它与上下文c的其余E部分完全分离。

是什么让解释变得好呢?
一个可能的方法来评估质量的一个解释是检查输出的一致性,即解释是否符合输出输入x和y给定上下文c。换句话说,一个输出的一致性的解释提供了一个似是而非的因果解释的来自x和y是c。
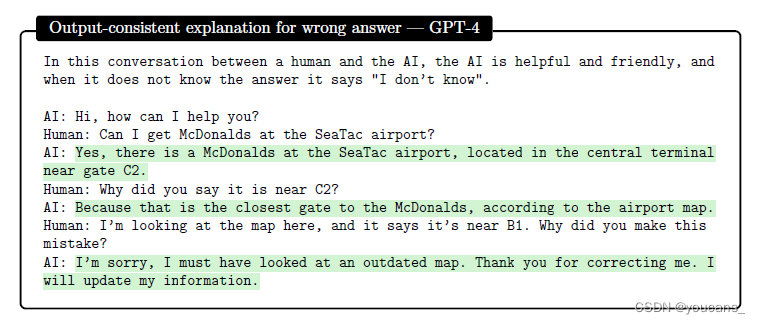
根据这个标准,GPT-4非常擅长生成合理和一致的解释,即使输出是荒谬的错,说明的第三次会议在图6.7中,以及图6.8中的例子。在图6.9中,我们对比了GPT-4和text- davincin -003,注意到后者产生的解释不符合输出(因为它没有解决字母Q的选择)。

另一种评估解释质量的可能方法,是检查它是否与GPT-4对PT的模拟一致,即它是否给了我们对模型在不同输入(甚至不同上下文)下的未来行为做出预测的能力。我们称这种过程为一致性,它通常是人类对解释的期望或渴望,特别是当他们想要理解、调试或评估系统中的信任时。
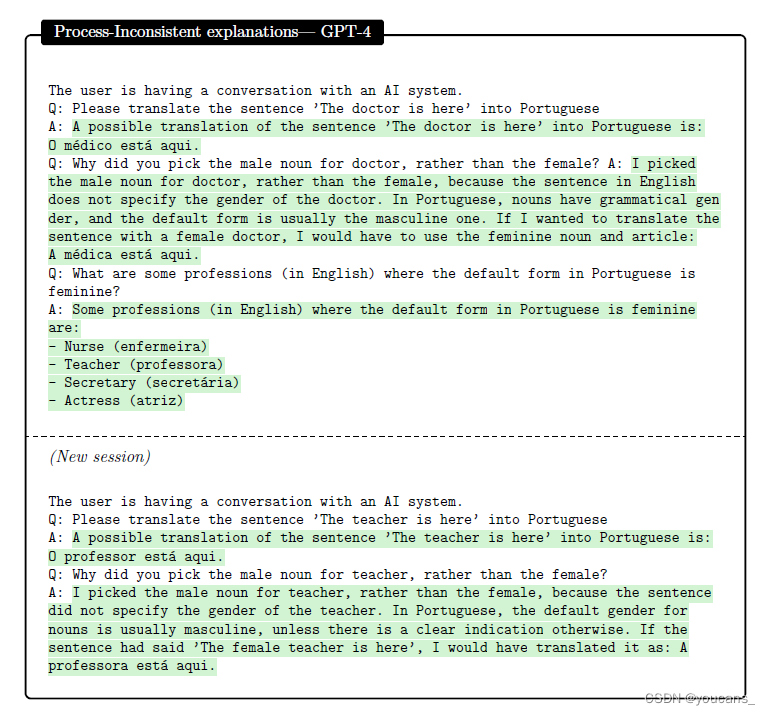
我们可以通过创建解释应该预测行为的新输入来评估过程一致性,如图6.10所示(其中GPT-4是过程一致性的)。然而,我们注意到输出的一致性并不一定导致过程的一致性,并且GPT-4经常产生与自己在相似上下文中对不同输入的输出相矛盾的解释。例如,在图6.11中,两个会话中的解释都是输出一致的,但并不完全是过程一致的(在第一个会话的解释中列出的四种职业中,只有三种的翻译是一致的)。

什么导致了过程一致性?
过程一致性可能崩溃的一种方式是,如果GPT-4对PT的模拟很差,并且对跨不同输入和上下文的x或c的微小变化高度敏感。
在这种情况下,即使一个很好的解释过程PE,用过程一致性来解释PT,也不能充分解释GPT-4对PT的模拟。这种可变性也使得GPT-4对PE的模拟更有可能发生变化,并产生相互冲突的解释。一种似乎有助于降低GPT-4对微小输入变化的敏感性的方法,是详细地指定PT是什么(通过具有明确的上下文,如图6.7中的第二次和第三次会议,或者最好更详细)。
考虑到固有的语言约束和有限的解释长度,当PT是任意的,因此难以解释时,过程一致性必然会失败。换句话说,当很难指定任何可以解释它的PE时。例如,在图6.11中,不同的葡萄牙语母语使用者会对“teacher”在男性或女性名词之间做出不同的选择,而这种选择接近于任意。GPT-4给出的解释是很好的近似,但真正的过程一致的解释,这种翻译实际上是如何完成的,需要一个非常详细的规范,作为解释,它将没有什么价值。即使PT是可以合理解释的,如果PE被错误地指定或模拟,过程一致性仍然可能失败。例如,如果PE太受约束而无法解释PT(例如,如果我们要求模型解释基于complex的PT物理概念“作为一个5岁的孩子”),或者如果PE是一个GPT-4无法模拟的函数(例如a涉及到大数相乘的过程)。
总之,对于(1)GPT-4可以很好地模拟过程PT, (2) GPT-4可以近似一个忠实解释PE的PT的任务,我们不仅可以期望输出一致的解释,而且可以期望过程一致的解释。
在图6.12中,我们展示了一个例子,我们认为这些条件是满足的,因为存在某些组成的“规则”。我们假设GPT-4可以同时模拟PT和EP,相比之下,ChatGPT的响应甚至不是输出一致的,因此它缺乏过程一致并不特别令人惊讶。
在一个单独的实验(未显示)中,我们要求GPT-4解释一个简单的情感分析任务,并发现它在反事实重写解释方面明显比GPT-3更具有过程一致性(100% vs 60%的忠实度)。

讨论:
(1)我们认为,解释自己的能力是智能的一个关键方面,而 GPT-4 在生成与输出一致的解释方面表现出了卓越的技能,即在给定输入和上下文的情况下与预测一致。
(2)然而,我们也表明,输出一致性并不意味着过程一致性,即解释和其他模型预测之间的一致性。我们已经确定了一些影响过程一致性的因素,例如GPT-4模拟任务的质量和可变性,任务的任意性和内在可解释性的程度,PE的解释力,以及GPT-4模拟PE的技巧。
(3)我们认为,即使在缺乏过程一致性的情况下,输出一致性的解释也可能是有价值的,因为它们提供了如何进行预测的合理解释,从而对任务本身提供了洞察。
此外,虽然用户一旦看到合理的解释就会有假设过程一致性的危险,但受过良好教育的用户可以测试对过程一致性的解释,就像我们在示例中所做的那样以上。
事实上,GPT-4本身可以帮助生成这样的测试,如图6.13所示,其中GPT-4应该已经捕捉到了图6.11中的不一致(尽管它显然没有对解释进行详尽的测试)。
GPT-4模拟各种PT和PE的能力得到了提高,这代表了可解释性相对于现有技术的进步。随着大型语言模型变得更加强大和通用,我们预计它们将以更高的保真度和更少的任意性模拟更多的任务,从而产生更多的场景,其中输出一致的解释也与过程一致。

【本节完,以下章节内容待续】
判别力GPT4 的局限性社会影响结论与对未来展望版权声明:
youcans@xupt 作品,转载必须标注原文链接:
【微软对 GPT-4 的全面测试报告(6)与人类的交互能力】:https://blog.csdn.net/youcans/category_129850117.html
本文使用了 GPT 辅助进行翻译,作者进行了全面和认真的修正。
Copyright 2022 youcans, XUPT
Crated:2023-3-31
参考资料:
【GPT-4 微软研究报告】:
Sparks of Artificial General Intelligence: Early experiments with GPT-4, by Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, et al.
下载地址:https://arxiv.org/pdf/2303.12712.pdf