ICLR2022/扩散模型/语义分割:基于扩散模型的标签高效语义分割Label-efficient semantic segmentation with diffusion models
ICLR2022/扩散模型/语义分割:基于扩散模型的标签高效语义分割Label-efficient semantic segmentation with diffusion models
0.摘要1.概述2.相关工作2.1.扩散模型2.2.基于生成模型的图像分割2.3.区分性任务生成模型的表征 3.扩散模型表示3.1.表征分析3.2.基于DDPM的FEW-SHOT语义分割表示 4.实验4.1.讨论 5.结论附录A.预测性能的演变B.DATASETDDPM & DATASETGANC.训练设置D.每一类的IoUsE.数据集细节E.1.类别名E.2.类别的统计数据 F.从MAE中提取表示
论文下载
开源代码
0.摘要
去噪扩散概率模型最近受到了大量关注,因为它们优于其他方法,如GAN,并且目前提供了最先进的生成性能。扩散模型的卓越性能使其在多个应用中成为一个有吸引力的工具,包括绘画、超分辨率和语义编辑。在本文中,我们证明了扩散模型也可以作为语义分割的工具,特别是在标签数据稀缺的情况下。特别是,对于几个预训练的扩散模型,我们研究了来自执行反向扩散过程的马尔可夫步骤的网络的中间激活。我们表明,这些激活有效地从输入图像中捕获语义信息,并且似乎是分割问题的优秀像素级表示。基于这些观察结果,我们描述了一种简单的分割方法,即使只提供少数训练图像,该方法也可以工作。我们的方法在多个数据集上显著优于现有的替代方法,以实现相同的人工监督量
1.概述
去噪扩散概率模型(DDPM)(Sohl-Dickstein等人,2015年;Ho等人,2020年)最近在模拟自然图像分布的各种方法中,无论是在单个样本的真实性还是其多样性方面,都表现得更好(Dhariwal&Nichol,2021)。DDPM的这些优势在应用中得到了成功的利用,例如彩色化(Song等人,2021)、补漆(Song等,2021)、超分辨率(Saharia等人,2021;Li等,2021b)和语义编辑(Meng等人,2021),与GAN相比,DDPM通常取得更令人印象深刻的结果。
然而,到目前为止,DDPM还没有被用作非歧视性计算机视觉问题的有效图像表示的来源。尽管先前的文献已经证明,各种生成范式,如GAN(Donahue&Simonyan,2019)或自回归模型(Chen等人,2020a),可以用于提取常见视觉任务的表示,但目前尚不清楚DDPM是否也可以作为表示学习者。在本文中,我们在语义分割的背景下对这个问题给出了肯定的答案
特别是,我们研究了U-Net网络的中间激活,该网络近似于DDPM中反向扩散过程的马尔可夫步骤。直观地说,这个网络学会了去噪其输入,并且不清楚为什么中间激活应该捕获高级视觉问题所需的语义信息。然而,我们表明,在某些扩散步骤中,这些激活确实捕获了这些信息,因此,可以潜在地用作下游任务的图像表示。考虑到这些观察结果,我们提出了一种简单的语义分割方法,该方法利用了这些表示,即使只提供了几个带标签的图像,也能成功地工作。在几个数据集上,我们表明,在相同的监督量下,我们基于DDPM的分割方法优于现有的基线。
总之,我们论文的贡献如下:
2.相关工作
在本节中,我们简要介绍了与我们的工作相关的现有研究路线。
2.1.扩散模型
扩散模型(Sohl Dickstein等人,2015;Ho等人,2020)是一类生成模型,通过马尔可夫链的端点近似真实图像的分布,马尔可夫链起源于简单的参数分布,通常是标准高斯分布。每一个马尔可夫步骤都是由一个深度神经网络建模的,该网络可以有效地学习用已知的高斯核反转扩散过程。Ho等人强调了扩散模型和分数匹配的等价性(Song&Ermon,2019;2020),表明它们是通过迭代去噪过程将简单已知分布逐渐转换为目标分布的两个不同视角。最近的工作(Nichol,2021;Dhariwal&Nichol(2021)开发了更强大的模型架构以及不同的高级目标,这导致DDPM在生成质量和多样性方面战胜了GAN。DDPM已广泛应用于多种应用,包括图像彩色化(Song等人,2021)、超分辨率(Saharia等人,2021;Li等人,2021b)、上色(Song等,2021)和语义编辑(Meng等人,2021)。在我们的工作中,我们证明了也可以成功地将它们用于语义分割。
2.2.基于生成模型的图像分割
基于生成模型的图像分割是当前一个活跃的研究方向,然而,现有的方法主要基于GAN。第一行工作(Voynov&Babenko,2020;Voynov等人,2021;Melas-Kyriazi等人,2021)基于这样的证据,即最先进的GAN的潜在空间具有与不同影响前地/背景像素的效果相对应的方向,这允许生成合成数据来训练分割模型。然而,这些方法目前只能执行二进制分割,目前还不清楚它们是否可以用于语义分割的一般设置。第二行作品(Zhang等人,2021;Tritrong等人,2021;Xu,2021;Galeev等人,2020)与我们的研究更为相关,它们基于GAN中获得的中间表示。特别是,(Zhang等人,2021)中提出的方法根据这些表示训练像素类预测模型,并确认其标记效率。在实验部分,我们将(Zhang等人,2021)的方法与基于DDPM的方法进行了比较,并展示了我们解决方案的几个独特优势
2.3.区分性任务生成模型的表征
作为表征学习者,生成模型的使用已经被广泛研究用于全球预测(Donahue&Si-monyan,2019;Chen等人,2020a)和密集预测问题(Zhang等人,2021;Tritronge等人,2021;Xu,2021;Xu等人,2021)。尽管先前的工作强调了这些表示的实际优势,例如分布外鲁棒性(Li等人,2021a),但与基于对比学习的替代无监督方法相比,生成模型作为表示学习者受到的关注较少(Chen等人,2020b)。主要原因可能是难以在复杂多样的数据集上训练高质量的生成模型。然而,鉴于DDPM最近在Imagenet上的成功(Deng等人,2009年),我们可以预计,这一方向将在未来吸引更多的关注。
3.扩散模型表示
在接下来一节中,我们研究了通过扩散模型学习的图像表示。首先,我们简要概述了DDPM框架。然后,我们描述了如何使用DDPM提取特征,并研究这些特征可能会捕获什么样的语义信息
背景扩散模型将噪声xT∼(0,I)通过逐渐去噪xT到噪声较小的采样xt转换为采样x0。形式上,我们得到了一个正向扩散过程: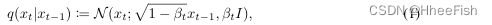
对于某些固定方差表β1,…,βt
重要的是,噪声样本x可以直接从数据x0获得: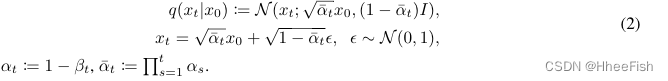
预训练DDPM近似于反向过程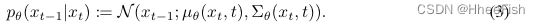
实际上,噪声预测网络 ϵ θ ( x t , t ) \epsilon_θ(x_t,t) ϵθ(xt,t)不是预测方程(3)中的分布平均值,而是预测步长t处的噪声分量;平均值是该噪声分量和xt的线性组合。协方差预测因子 ∑ θ ( x t , t ) ∑_θ(x_t,t) ∑θ(xt,t)可以是标量协方差的固定集合,也可以是学习的(后者被证明可以提高模型质量(Nichol,2021))
去噪模型 ϵ θ ( x t , t ) \epsilon_θ(x_t,t) ϵθ(xt,t)通常由UNet架构的不同变体参数化(Ronneberger等人,2015),在我们的实验中,我们研究了在(Dhariwal&Nichol,2021)中提出的最先进的模型
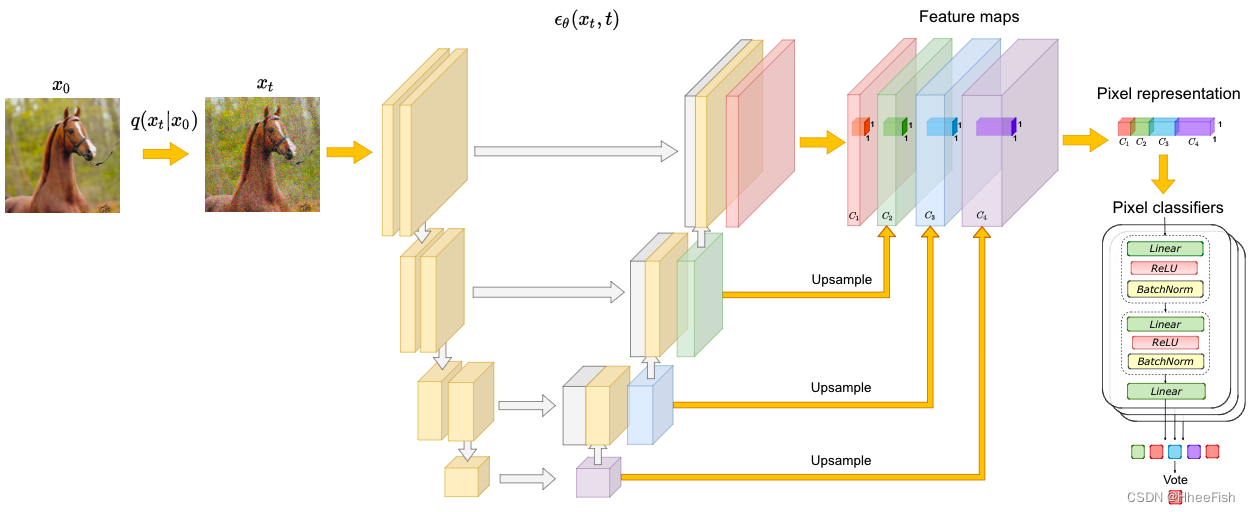
图1:拟议方法概述。(1) x0→xt,通过根据q(xt|x0)添加噪声。(2) 从噪声预测器 ϵ θ ( x t , t ) \epsilon_θ(x_t,t) ϵθ(xt,t)中提取特征图。(3) 通过将特征图上采样到图像分辨率并将其拼接,收集像素级表示。(4) 使用像素级特征向量训练MLP集合,以预测每个像素的类标签
对于给定的真实图像 x 0 ∈ R H × W × 3 x_0∈R^{H×W×3} x0∈RH×W×3,可以从噪声预测网络 ϵ θ ( x t , t ) \epsilon_θ(x_t,t) ϵθ(xt,t)计算出T组激活张量。时间步长t的总体方案如图1所示。首先,我们通过根据等式(2)添加高斯噪声来破坏x0。噪声xt用作UNet模型参数化的 ϵ θ ( x t , t ) \epsilon_θ(x_t,t) ϵθ(xt,t)的输入。然后使用双线性插值将UNet的中间激活上采样到H×W。这允许将他们视作x0像素水平的表示。
3.1.表征分析
我们分析了噪声预测器 ϵ θ ( x t , t ) \epsilon_θ(x_t,t) ϵθ(xt,t)产生的差分表示。我们考虑了在LSUN Horse和FFHQ-256数据集上训练的最先进的DDPM检查点
来自噪声预测器的中间激活捕获语义信息在这个实验中,我们从LSUN Horse和FFHQ数据集中获取了一些图像,并分别手动将每个像素分配给21个和34个语义类中的一个。我们的目标是了解DDPM生成的像素级表示是否有效地捕获有关语义的信息。为此,我们训练了一个多层感知器(MLP),以根据18UNet解码器块之一在特定扩散步骤上产生的特征来预测像素语义标签。注意,我们只考虑解码器激活,因为它们还通过跳过连接聚合编码器激活。MLP在20张图片上进行训练,并在20张保持图片上进行评估。预测性能以平均IoU衡量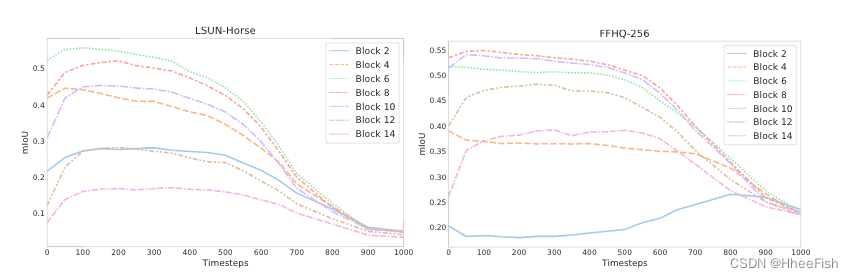
图2:不同UNet解码器块和扩散步骤的基于DDPM的逐像素表示的预测性能演变。区块编号从深到低。信息量最大的特征通常对应于反向扩散过程的后续步骤和UNet解码器的中间层。前面的步骤对应于未提供信息的表示。附录A中提供了其他数据集的图表
不同区块和扩散步骤的预测性能演变如图2所示。区块从深到浅依次编号。图2显示了噪声预测器 ϵ θ ( x t , t ) \epsilon_θ(x_t,t) ϵθ(xt,t)产生的特征的分辨性随不同的块体和扩散步骤而变化。特别是,与反向扩散过程的后续步骤相对应的特征通常更有效地捕获语义信息。相反,与早期步骤相对应的步骤通常没有信息。在不同的块中,UNet解码器中间层产生的特征似乎是所有扩散步骤中信息最丰富的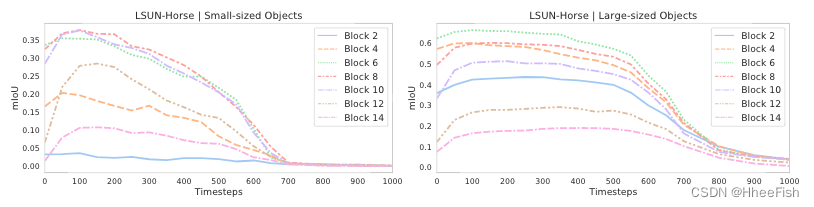
图3:LSUN Horse数据集上具有最小(左)和最大(右)平均面积的类的基于DDPM的逐像素表示的预测性能的演变。在相反的过程中,小尺寸对象的预测性能稍后开始增长。较深的块对于较大的对象信息更丰富,较浅的块对于较小的对象信息更多。附录A中提供了其他数据集的类似评估。
此外,我们还基于注释数据集中的平均面积分别考虑了小型和大型语义类。然后,我们在不同的UNet块和扩散步骤中独立评估这些类的平均IoU。LSUN Horse的结果如图3所示。正如预期的那样,大型对象的预测性能在相反的过程中开始提前增长。更大的块对于较小的对象信息更丰富,而更深的块对于较大的对象信息更多。在这两种情况下,最具区别性的特征仍然对应于中间块。
图2表明,对于某些UNet块和扩散步骤,类似的基于DDPM的表示对应于相同语义的像素。图4显示了由FFHQ检查点从dif融合步骤
图4:由在扩散步骤{50,200,400,600,800}上从UNetdecoder块{6、8、10、12}提取的特征形成的k均值聚类(k=5)的示例。来自中间块的聚类在空间上跨越连贯的语义对象和部分
{50,200,400,600,800}上的块{6、8、10、12}中提取的特征形成的k均值聚类(k=5),并确认聚类可以跨越连贯的语义对象和对象部分。在块B=6中,特征对应于粗语义掩码。在另一个极端,B=12的特征可以区分细粒度的面部部分,但对于粗糙的碎片,其语义意义较小。在不同的扩散步骤中,最有意义的特征与后面的特征相对应。我们将这种行为归因于这样一个事实,即在反向过程的早期阶段,DDPM样本的全局结构尚未出现,因此,在这个阶段很难预测分割掩模。图4中的掩模定性地证实了这种直觉。t=800,掩模很难反映实际图像的内容,而对于较小的值,掩模和图像在语义上是一致的。
3.2.基于DDPM的FEW-SHOT语义分割表示
上述观察到的中间DDPM激活的潜在有效性暗示了它们用作密集预测任务的图像表示。图1示意性地展示了我们的整体图像分割方法,该方法利用了这些表示的可分辨性。更详细地,我们考虑FEW-SHOT半监督设置,当大量未标记图像 X 1 , … , X N ⊂ R H × W × 3 {X_1,…,X_N}⊂R^{H×W×3} X1,…,XN⊂RH×W×3来自特定域是可用的,并且仅有n张训练图片 X 1 , … , X n ⊂ R H × W × 3 {X_1,…,X_n}⊂R^{H×W×3} X1,…,Xn⊂RH×W×3有K类语义分割掩膜 Y 1 , … , Y n ⊂ R H × W × { 1 , . . . , K } {Y_1,…,Y_n}⊂R^{H×W×\{1,...,K\}} Y1,…,Yn⊂RH×W×{1,...,K}
第一步,我们以无监督的方式在整个 X 1 , … , X N {X_1,…,X_N} X1,…,XN上训练扩散模型。然后,该扩散模型用于使用UNet块的子集和扩散步长来提取标记图像的像素级表示。在这项工作中,我们使用了来自UNet解码器的中间块B={5,6,7,8,12}和反向扩散过程的后续步骤t={50,150,250}的表示。这些块和时间步骤是由第3.1节中的见解驱动的,但有意不针对每个数据集进行调整。
虽然在特定时间步长的特征提取是随机的,但我们在第4.1节中消除了所有时间步长的噪声。从所有块B和步长t提取的表示被采样到图像大小并连接,形成训练图像的所有像素的特征向量。像素级表示的总体尺寸为8448。
然后,接下来(Zhang等人,2021),我们在这些特征向量上训练独立多层感知器(MLP)的集合,其目的是预测训练图像中每个可用像素的语义标签。我们采用了来自(Zhang等人,2021)的集成配置和训练设置,并在我们的实验中使用了所有其他方法,详见附录C。
为了分割测试图像,我们提取其基于DDPM的逐像素表示,并使用它们通过集合来预测像素标签。最终预测是通过多数投票得出的。
4.实验
本节通过实验证实了基于DDPM的表示方法在尾数分割问题中的优势。我们从与现有替代方案的彻底比较开始,然后通过额外分析剖析DDPM成功的原因
数据集在我们的评估中,我们主要使用LSUN(Yu等人,2015)和FFHQ-256(Karras等人,2019)中的“卧室”、“猫”和“马”类别。作为每个数据集的训练集,我们考虑了几个图像,这些图像的细粒度语义掩码是按照协议收集的(Zhang等人,2021)。对于每个数据集,聘请一名专业评估员对样本进行注释和测试。我们将收集的数据集表示为Bedroom-28、FFHQ-34、Cat-15、Horse-21,其中数字对应于语义类的数量。
此外,我们考虑了两个数据集,与其他数据集相比,它们具有公开可用的注释和可观的评估集:
每个数据集的注释图像数量见表1。其他详细信息见附录E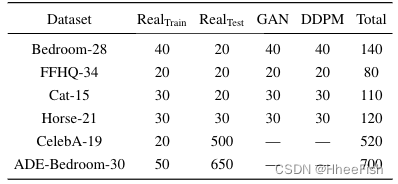
表1:评估中使用的每个数据集的注释图像数量
方法在评估中,我们将我们的方法(表示为DDPM)与解决少数镜头语义分割设置的几种现有方法进行了比较。首先,我们描述了生成大量带注释的合成图像以训练分割模型的基线
DatasetGAN(Zhang等人,2021)-此方法利用GAN生成的像素级特征的可区分性。更详细地说,评估人员注释了一些GAN制作的图像。然后,使用这些图像的潜码来获得中间生成器激活,这些激活被认为是像素级表示。给定这些表示,分类器被训练为预测每个像素的语义标签。然后,该分类器用于标记新闻合成GAN图像,就其而言,该图像用作DeepLabV3分段模型的训练集(Chen等人,2017)。对于每个数据集,我们增加合成图像的数量,直到验证集的性能不饱和。根据(Zhang等人,2021),我们还去除了10%预测最不确定的合成样品DatasetDDPM与DatasetGAN基线相似,唯一的区别是GAN被DDPM替换。我们将此基线用于比较同一场景中基于GAN和基于DDPM的演示。请注意,与DatasetGAN和DatasetDDPM相比,第3.2节中描述的分割方法更加简单,因为它不需要合成数据集生成和训练分割模型的辅助步骤
然后,我们考虑一组基线,这些基线允许直接从真实图像中提取中间激活,并使用它们作为像素级表示,与我们的方法类似。与DatasetGAN和DatasetDDPM相比,由于真实图像和合成图像之间不存在领域差距,这些方法可能是有益的。
MAE(He等人,2021)——最先进的自我监督方法之一,其学习去噪自动编码器以重建缺失的补丁。我们使用ViT-Large(Dosovitskiy等人,2021)作为主干模型,并将补丁大小减少到8×8,以增加特征地图的空间维度。我们使用官方代码2在与DDPM相同的数据集上预处理所有模型。该方法的特征提取在附录F中描述。
SwAV(Caron等人,2020)-一种更新的自我监督方法。我们考虑使用两倍宽的ResNet-50模型进行评估。所有模型都在与DDPM相同的数据集上预训练,也使用官方源代码。输入图像分辨率为256。
GAN Inversion采用最先进的方法(Tov等人,2021)获取真实图像的潜在代码。我们将带注释的真实图像映射到GAN潜在空间,这允许计算中间生成器激活并将其用作像素级表示。
GAN Encoder-当GAN反转努力从LSUN域重建图像时,我们还考虑了用于GAN反转的预训练GAN编码器的激活。
VDVAE(Child,2021)-最先进的自动编码器模型。从编码器和解码器中提取中间激活并连接。虽然LSUN数据集上没有预训练的模型,但我们仅在FFHQ-256上的公共可用检查点4上评估该模型
ALAE(Pidhorskyi等人,2020)采用StyleGANv1生成器,并将编码器网络添加到对抗训练中。我们从编码器模型中提取特征。在我们的评估中,我们在LSUN卧室和FFHQ-10245上使用了公开可用的模型。
生成预训练模型
在我们的实验中,我们使用了最先进的StyleGAN(Karraset al.,2020)模型作为基于GAN的基线,使用最先进的预处理ADM(Dhari-wal&Nichol,2021)作为基于DDPM的方法。由于没有针对FFHQ-256的预训练模型,我们使用官方实施自行训练。对于ADE-Bedroom-30数据集的评估,我们使用在LSUN Bedroom上预训练的模型(包括基线)。对于Celeba-19,我们评估了在FFHQ-256上训练的模型。
主要结果
图5:通过我们的方法在测试图像上预测的分割掩模的示例,以及背景真相注释掩模
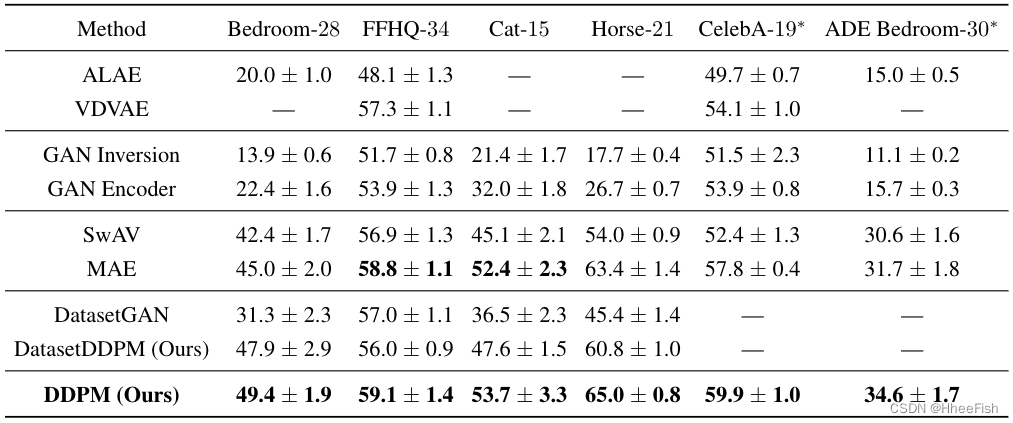
表2:平均IoU方面的分割方法比较。(*)在CelebA-19和ADE卧室-30上,我们分别评估了在FFHQ-256和LSUN卧室上预处理的模型
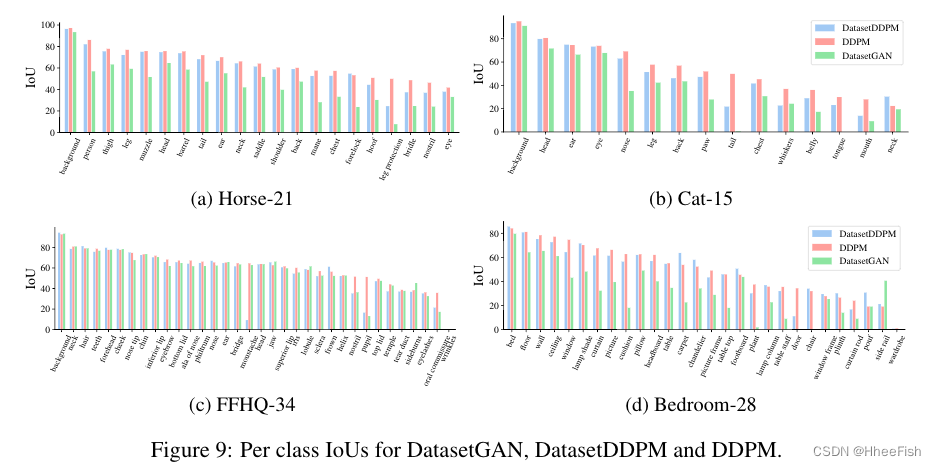
表2给出了两种方法在平均IoU测量方面的比较。结果在不同数据分割的5次独立运行中进行了平均。我们还在附录D中报告了每类IoU。此外,我们在图5中提供了使用我们的方法进行分割的几个定性示例。下面我们重点介绍了几个关键观察结果:
所提出的基于DDPM表示的方法在大多数数据集上显著优于替代选项。MAE基线是基于DDPM的分割的最强竞争对手,并在FFHQ-34和Cat-15数据集上展示了可比较的结果与基于DDPM的分割相比,SwAVbaseline表现不佳。我们将这种行为归因于这样一个事实,即该基线是以区分的方式训练的,并且可以支持细粒度语义分割所需的细节。这一结果与(Cole等人,2021)中的最新发现相一致,该发现表明,最先进的对比方法产生的表征对于细粒度问题来说是次优的DatasetDDPM根据大多数基准测试执行其对手DatasetGAN。注意,这两种方法都使用DeepLabV3网络。我们将这种优势归因于DDPM合成物的更高质量,因此,合成数据和真实数据之间的领域差距更小在大多数数据集上,DDPM比DatasetDDPM更好。我们在下面的讨论部分提供了一个额外的实验来研究这一点总体而言,所提出的基于DDPM的分割优于利用交替生成模型的基线以及以自我监督方式训练的基线。这一结果突出了使用最先进的DDPM作为强大的无监督表示学习者的潜力。
4.1.讨论
训练对真实数据的影响
表3:在真实图像和合成图像上训练时基于DDPM的分割性能。在DDPM生成的数据上训练时,DDPM表现出与数据集DDPM相当的性能。当在GAN生成的数据上进行训练时,DDPM仍然显著优于DatasetGAN,但两者之间的差距缩小了。
所提出的DDPM方法是在带注释的真实图像上训练的,而DatasetDDPM和DatasetGAN是在合成图像上训练,这些图像通常不太自然、多样,并且可能缺少特定类的对象。此外,合成图像很难进行人类注释,因为它们可能有一些扭曲的对象,很难分配给特定的类。在接下来的实验中,我们量化了在真实或合成数据上训练导致的性能下降。具体而言,表3报告了在真实、DDPM生成和GAN生成的注释图像上训练的DDPM方法的性能。可以看出,在生成模型的保真度仍然相对较低的领域,例如LSUN Cat,对真实图像进行训练非常有益,这表明带注释的真实图像是更可靠的监督来源。此外,如果在合成图像上训练DDPM方法,其性能将与DatasetDDPM相当。另一方面,当对GAN生成的样本进行训练时,DDPM显著优于DatasetGAN。我们将此归因于DDPM与GAN相比提供了更具语义价值的像素表示
采样效率
表4:用不同数量的标记训练数据评估所提出的方法。即使使用较少注释的数据,DDPM仍优于表2中的大多数基线
在这个实验中,我们评估了我们的方法在使用无注释数据时的性能。我们为表4中的四个数据集提供了mIoU。重要的是,DDPM仍然能够超过表2中的大多数基线,使用的监督明显较少
随机特征提取的效果在这里,我们研究了我们的方法是否可以从第3.2节中描述的随机特征提取中受益∼N(0,I)采样一次,并在(2)中使用,以获得训练和评估期间的所有时间步长。然后,我们将其与以下随机选项进行比较:
表5:基于DDPM的方法对不同特征提取变化的性能。所有考虑的随机选项提供了与确定性选项类似的mIoU
首先,在训练和评估过程中,针对不同的时间步长t采样不同的 ϵ t \epsilon_t ϵt。第二,在每个训练迭代中对所有时间步长采样不同的噪声;在评估过程中,该方法还使用了看不见的噪声样本
结果如表5所示。可以看出,性能差异很小。我们将此行为归因于以下原因:
我们的方法使用反向扩散过程的后期,其中噪声幅度较低
由于我们利用了UNet模型的深层,噪声可能不会显著影响这些层的激活。
对损坏的输入的鲁棒性
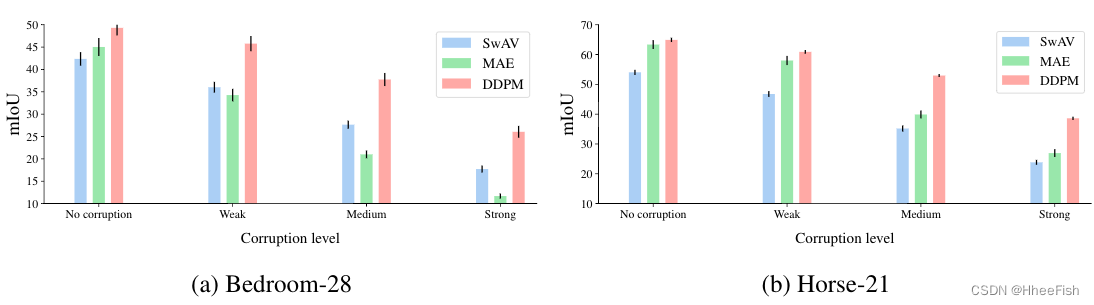
图6:Bedroom-28和Horse-21数据集上不同图像损坏级别的mIoU退化。DDPM表现出更高的鲁棒性,并在所有失真水平下保持其优势
在本实验中,我们研究了基于DDPM的表示的鲁棒性。首先,我们使用Bedroom-28和Horse-21数据集上的DDPM、SwAV和MAE表示来学习干净图像上的像素分类器。然后,从(Hendrycks&Dieterich,2019)中采用的18种不同的腐败类型被应用于测试图像。每个腐败都有五个严重级别。在图6中,我们提供了针对1、3、5个严重级别的所有损坏类型计算的平均IoU,分别表示为“弱”、“中等”和“强”。
可以观察到,所提出的基于DDPM的方法显示出更高的鲁棒性,即使对于严重的图像失真,也优于SwAV和MAE模型
5.结论
本文证明DDPM可以作为区分性计算机视觉问题的表征学习者。与GAN相比,扩散模型允许直接计算真实图像的这些表示,并且不需要学习将图像映射到潜在空间的附加编码器。这种DDPM的优势和优越的生成质量在少数镜头语义分割任务中提供了最先进的性能。基于DDPM的分割的显著限制是需要在手边的数据集上训练高质量的扩散模型,这对于像ImageNet或MSCOCO这样的复杂领域来说可能具有挑战性。然而,鉴于DDPM的研究进展迅速,我们预计它们将在不久的将来达到这些里程碑,从而扩大相应表示的适用范围。
附录
A.预测性能的演变
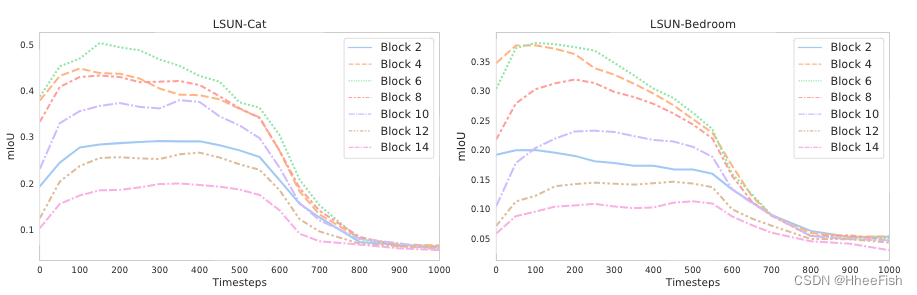
图7:LSUN Cat和LSUN Bedroom上不同UNet块和扩散步骤的基于DDPM的逐像素表示的预测性能演变。区块从深到浅依次编号。
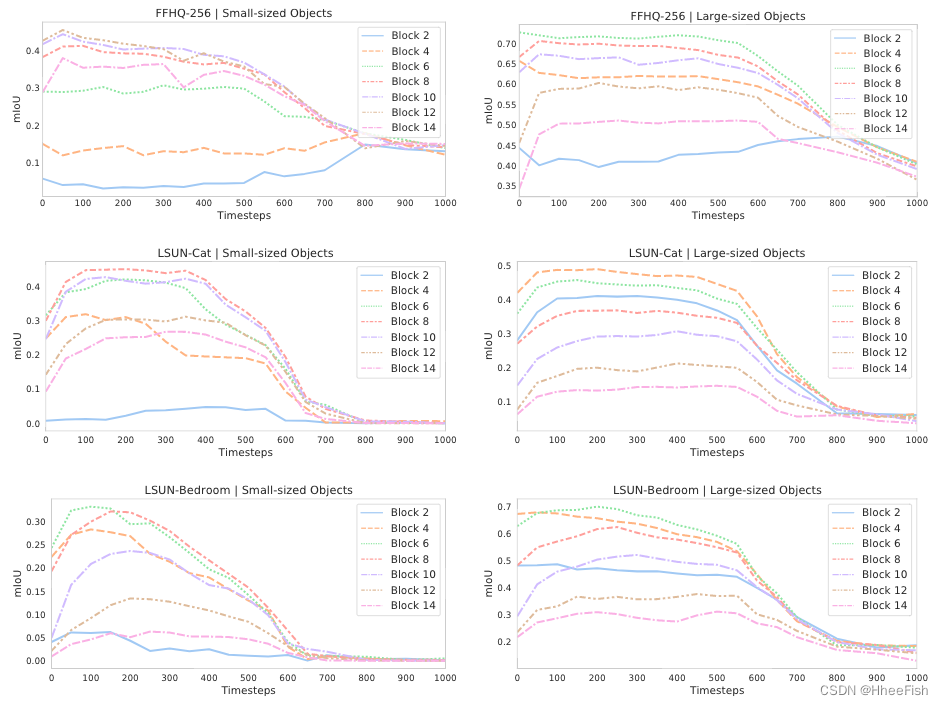
图8:FFHQ-256、LSUN Cat和LSUN Bedroom数据集上基于DDPM的逐像素表示的预测性能的演变,用于具有最小(左)和最大(右)平均面积的类
B.DATASETDDPM & DATASETGAN
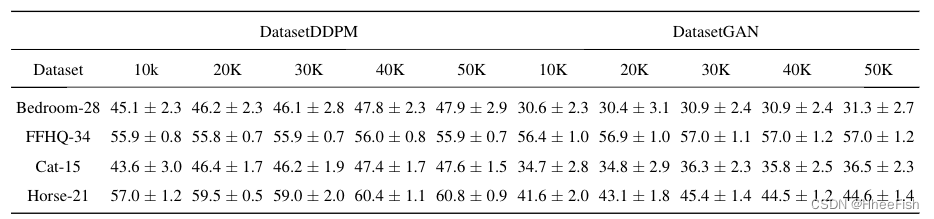
表6:数据集DDPM和数据集GAN的10K性能−训练数据集中的50K合成图像。两种方法的平均IoU在30K时饱和−50Kof合成数据
C.训练设置
MLP的集合由10个独立的模型组成。每个MLP都经过培训∼使用Adam优化器(Kingma&Ba,2015)进行4次预测,收益率为0.001。批处理大小为64。此设置用于所有方法和数据集
MLP架构我们采用了MLP架构(Zhang等人,2021)。具体而言,我们使用具有ReLU非线性和批处理归一化的两个隐藏层的MLP。对于类数小于30的数据集,隐藏层的大小为128和32,对于其他数据集,为256和128
此外,我们评估了所提出方法在Bedroom-28和FFHQ-34数据集上两倍宽/更深MLP的性能,没有观察到任何明显差异,见表7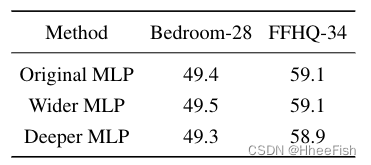
表7:针对两倍更宽/更深的MLP架构,提出的方法在集合中的性能。更具表现力的MLP不会提高性能
D.每一类的IoUs
E.数据集细节
E.1.类别名
Bedroom-28: [bed, footboard, headboard, side rail, carpet, ceiling, chandelier, curtain, cushion,floor, table, table top, picture, pillow, lamp column, lamp shade, wall, window, curtain rod, windowframe, chair, picture frame, plinth, door, pouf, wardrobe, plant, table staff]
FFHQ-34: [background, head, cheek, chin, ear, helix, lobule, bottom lid, eyelashes, iris, pupil,sclera, tear duct, top lid, eyebrow, forehead, frown, hair, sideburns, jaw, moustache, inferior lip, oralcommissure, superior lip, teeth, neck, nose, ala of nose, bridge, nose tip, nostril, philtrum, temple,wrinkles]
Cat-15: [background, back, belly, chest, leg, paw, head, ear, eye, mouth, tongue, tail, nose, whiskers,neck]
Horse-21: [background, person, back, barrel, bridle, chest, ear, eye, forelock, head, hoof, leg, mane,muzzle, neck, nostril, tail, thigh, saddle, shoulder, leg protection]
CelebA-19: [background, cloth, earr, eyeg, hair, hat, lbrow, lear, leye, llip, mouth, neck, neckl,nose, rbrow, rear, reye, skin, ulip]
ADE-Bedroom-30: [wall, bed, floor, table, lamp, ceiling, painting, windowpane, pillow, curtain,cushion, door, chair, cabinet, chest, mirror, rug, armchair, book, sconce, plant, wardrobe, clock,light, flower, vase, fan, box, shelf, television]
E.2.类别的统计数据
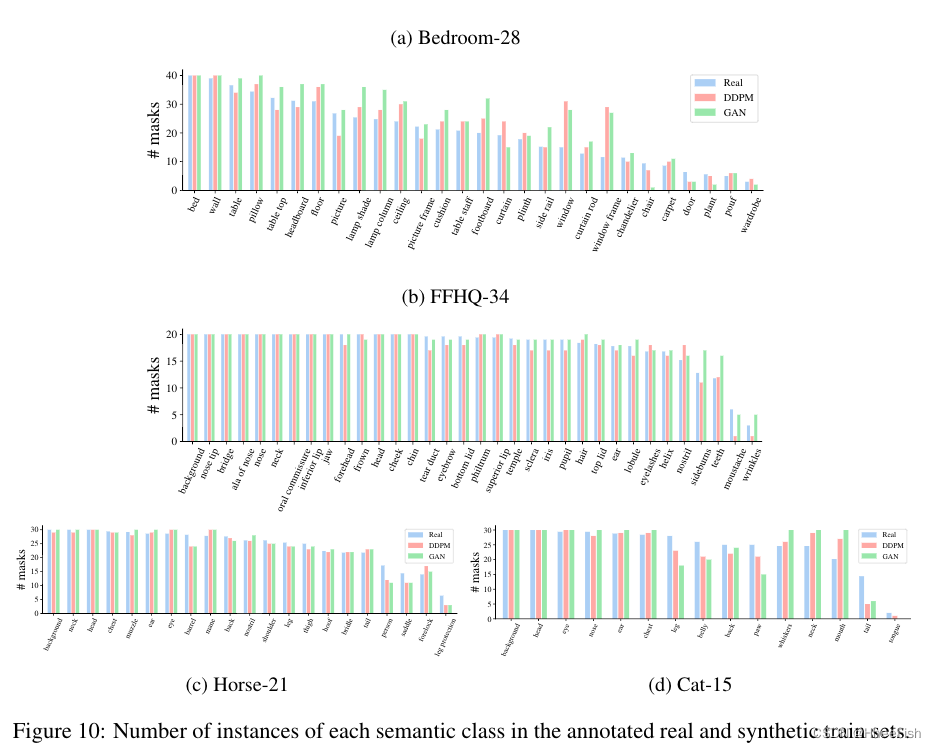
在图10中,我们报告了对注释的真实图像以及由GAN和DDPM生成的注释的合成图像计算的类的统计信息。
F.从MAE中提取表示
为了获得像素表示,我们将模型应用于分辨率为256的完全观察图像(maskratio=0),并从最深的12ViT-L块中提取特征图。每个块的特征图具有1024×32×32维。与其他方法类似,我们将提取的特征图上采样到256×256,并将它们连接起来。像素表示的总体尺寸为12288
此外,我们研究了其他特征提取策略,并获得了以下观察结果:
1.包括来自解码器的激活没有提供任何明显的增益;
2.在自我注意层之后立即提取激活导致稍差的表现;
3.从每一秒的编码器块中提取激活也提供了稍差的结果。
登录后可发表评论
点击登录