单目测距(目标检测+标定+测距)**
实时感知本车周围物体的距离对高级驾驶辅助系统具有重要意义,当判定物体与本车距离小于安全距离时便采取主动刹车等安全辅助功能,这将进一步提升汽车的安全性能并减少碰撞的发生。上一章本文完成了目标检测任务,接下来需要对检测出来的物体进行距离测量。首先描述并分析了相机成像模型,推导了图像的像素坐标系与世界坐标系之间的关系。其次,利用软件标定来获取相机内外参数并改进了测距目标点的选取。最后利用测距模型完成距离的测量并对采集到的图像进行仿真分析和方法验证。5.1 单目视觉测距与双目视觉测距对比**
测距在智能驾驶的应用中发挥着重要作用。测距方法主要包含两类:主动测距与被动测距,主动测距是当前研究的热点内容之一。主动测距方法包括采用传感器、摄像机、激光雷达等车载设备进行测距。摄像头由于价格相对低廉且性能稳定应用较为广泛,本文采用摄像头进行距离测量。单目测距主要运用测距模型结合目标矩形框来进行测距任务,通过目标在图像中的大小位置信息去估算距离。单目测距算法具有计算量小、成本低廉的优点,并且测距误差也可以通过后续的调校来消除,很多算法都在采用基于单目视觉传感器来开发产品。因此相对其他测距方法,单目视觉有更成熟的算法,本文亦采用单目视觉测距。
利用双目视觉可以获取同一物体在成像平面上的像素偏移量。然后可以使用相机焦距、像素偏移以及两个相机之间的实际距离从数学上得出对象之间的距离。与单目测距相比,双目测距虽然更加精确,不需要数据集,但计算量大,速度相对较慢,而且由于使用了两个摄像头,成本也变得更高。
5.2 相机成像模型**
想要得到距离信息需要获得三维真实世界里的点,而由于处理的对像是摄像头捕捉后的二维平面图像,因此如何将二维图像上的某个点转换为三维世界里的点是值得考虑的问题。进一步的,把图像上的点转换到真实世界的点,就需要进行像素坐标系、图像坐标系、相机坐标系以及世界坐标系之间的相互转换。四种坐标系之间的相互关系如图5-1所示。坐标系描述如下: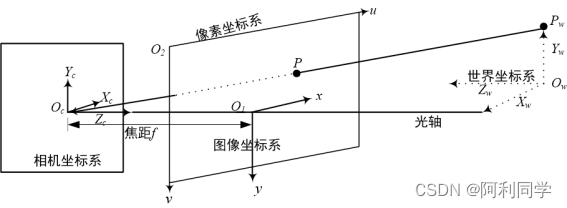 ****
****
(1)像素坐标系。数字图像一般是三维图像并且由众多像素点组合而成的,像素坐标系的原点为O2,以宽度方向为u轴,以高度方向为v轴。
(2)图像坐标系。图像坐标原点为O1,并且像素坐标系和图像坐标系是平行的,以图像宽度方向为x轴,以高度方向为y轴,长度单位为mm。
(3)相机坐标系。相机坐标系原点Oc,Xc轴、Yc轴分别是与图像坐标系下的x轴、y轴相互平行,相机Zc轴和摄像头光轴重合。
(4)世界坐标系。我们所处的环境即是在世界坐标系之下,也就是图5-1中Xw-Yw-Zw平面。Pw通过真实世界上的一点至图像上的P点,完成从世界坐标到图像上坐标的转换。
5.3 坐标系转换
(1)像素坐标系转换到图像坐标系
像素坐标系是以像素来表示各个像素位置信息的,但是它不能够表达出图像中物体的物理大小,因此需要进行坐标系之间的转换。
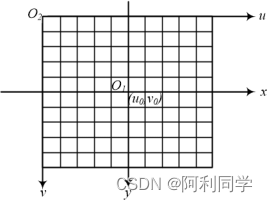
图5-2 图像坐标系在图5-2中,图像坐标系的坐标(x,y)与像素坐标系的坐标(u,v)之间的关系可以表示为: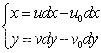
(5.1)式(5.1)中,(u0,v0)是图像中心的像素坐标,dx、dy分别是横向和纵向像素在感光板上的单位物理长度。
写成齐次坐标矩阵的形式为: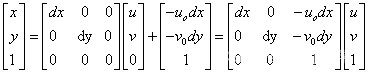
(5.2)# (2)图像坐标系变换到相机坐标系
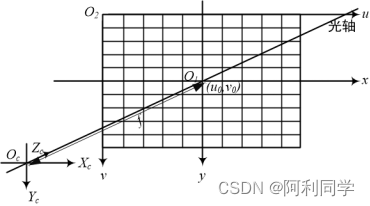
**图5-3 相机坐标系**在图5-3中,OcO1之间的距离为焦距f。图5-4表示了物体成像到图像坐标系的过程,P点、 P'点分别为相机坐标系和图像坐标系下的坐标。
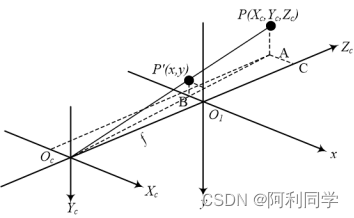
图5-4 相似三角形模型
由上图易知,三角形OcO1B和三角形OcCA相似,三角形OcBP'和三角形OcAP相似,根据相似三角形原理有: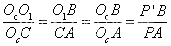
(5.3)并且OcO1的距离为焦距f,结合P(Xc,Yc,Zc),P'(x,y)点坐标,上式可写为: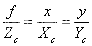
(5.4)进一步推倒可得: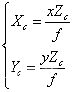
将其写成齐次坐标矩阵的形式为: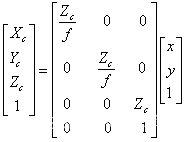
(5.5)(3)相机坐标系变换到世界坐标系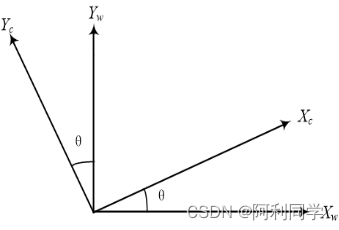
**图5-5相机坐标系到世界坐标系的转换**相机坐标系变换到世界坐标系可以描述为一个旋转平移的过程,分别将旋转和平移的分量加起来就是整个坐标系转换的全过程了。对于旋转过程,假设相机坐标系的Z轴与世界坐标系重合,那么有: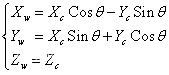
(5.6)同理,绕X轴旋转会得到如下关系: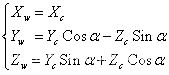
(5.7)绕Y轴旋转会得到如下关系: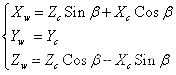
(5.8)对于平移分量来说,可以表达为:
(5.9)得到平移向量和旋转矩阵后,从相机坐标系变换到世界坐标系的公式可以完整的写为: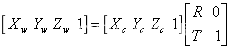
(5.10)其中旋转矩阵R为: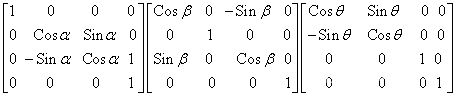
,平移矩阵T表示为:。结合式(5.2),式(5.5),式(5.10),就完成了从像素坐标系到世界坐标系的转换,整合起来为:
(5.11)这样针对图像上的一个点,就可以利用上述公式结合相机内外参数求解出具体的距离值。
5.4 相机内外参数与畸变系数
相机内外参数对图像矫正和测距具有重要意义。内外参数以及畸变系数可以通过相机标定得到机。并且相机都会发生畸变,这对于测量来说显然是不能容忍的,因此消除畸变是十分有必要的
5.4.1相机内外参数
在公式(5.11)中,等号右端第一项为相机的外参数,等号右端第二项表示为相机内参数,内参属于相机内在属性。式中未知参数Zc表示物体到光学中心的距离。同时也说明了,在相机标定的过程中,如果物体相对于相机的位置不同,那么需要对于每一个位置都需要去进行相机标定。
5.4.2相机畸变系数
相机畸变造成了图像平面上某一像素点的真实位置与理想位置不完全重合的现象,因此了解相机畸变现象并对相机进行矫正十分有必要。相机畸变主要包括径向畸变和切向畸变二类。图5-6展示了畸变模型,对于平面上任意理论点P,由与畸变的存在,会使得P点偏移到P'点。图中dr表示相机的径向畸变,dt表示相机的切向畸变。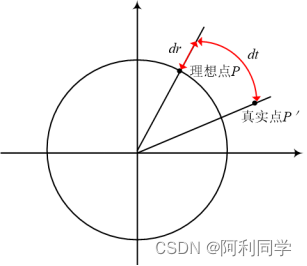
图5-6 相机畸变模型(1)径向畸变
径向畸变与透镜的形状密切相关,而且离透镜中心越远的地方畸变越明显。径向畸变大都表现为桶形畸变和枕型畸变两种方式。畸变的多项调节公式为: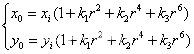
(5.12)其中(xi,yi)是图像平面上的理想点。(x0,y0)是畸变矫正后实际位置点。理想点与成像中心的距离,k1,k2,k3表示为相机径向畸变系数。如果这三个系数都小于零,那么将造成桶型畸变;如果三个系数均都大于零,则将造成枕型畸变。
(2)切向畸变
切向畸变的产生大都由于整个摄像机的组装和制造过程。对于切向畸变来说,可以使用两个切向畸变系数p1和p2进行纠正。
得到上述矫正公式后就可以完成对图像良好的修正。将切向矫正函数与径向矫正函数联合起来后,可以用如下公式表示:
(5.14)由于本文测距是面向自动驾驶领域,其对精度要求很高,畸变会对智能驾驶性能造成深远的负面影响。所以在这些应用中,系统必须使用相机标定法求取 p1和p2以及k1、k2和k3,并且这些参数后续测距模型也将应用到。
5.5 相机标定流程
相机标定可以获得畸变参数和相机内外参数,相机的标定可以分为依赖于标定参照物的标定方法和相机自标定方法两种。前者适用于对精度要求高的应用场合。后者由于标定后的计算结果会产生较大的误差,因此不适用于对精确度要求很高的应用场景。为了追求计算精度,本文采取第一种方法进行标定。
采用matlab进行标定: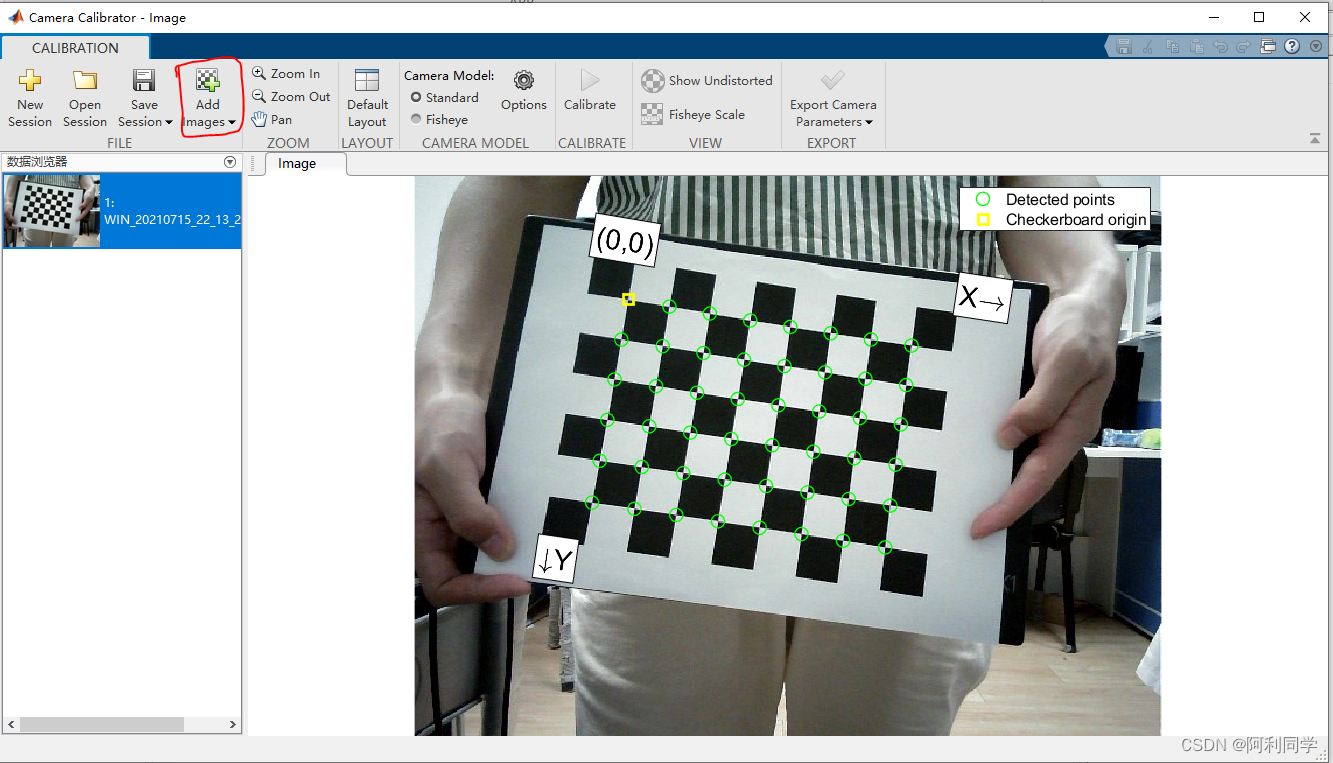
上图为引用图片。
通过采集标定板的图片,然后喂入matlab 获取相机内参。外参。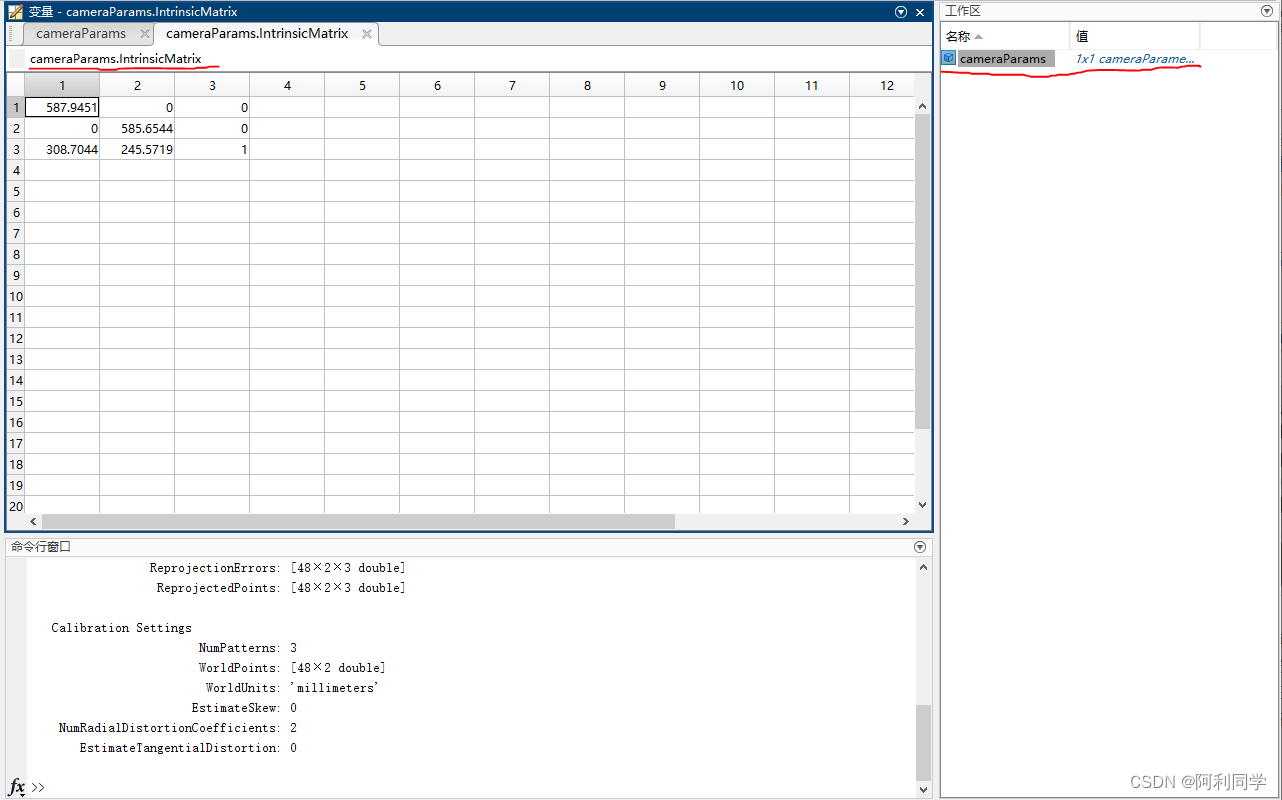
5.6 单目测距模型
在完成了相机畸变矫正和相机内外参数的求取之后,建立了如下的单目测距模型,再结合第四章目标检测获取的矩形框就可以进行距离的求取。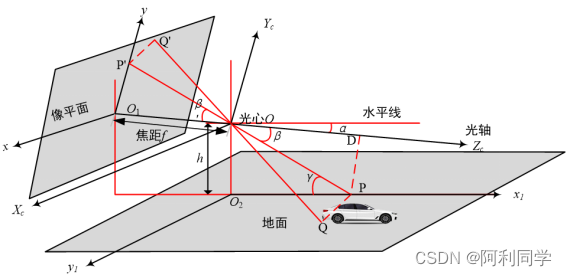
图5-10 测距模型测距模型可以看作是一个凸透镜成像的过程。上图中,Xc-Yc-Zc是相机坐标系,xO1y是图像坐标系,O1O为焦距f,x1O2y1是地面坐标系,OO2为摄像头安装高度h。图中有一辆车在地面上,那么其接地点Q必定在地面上。在单目测距过程中,实际物体上的Q点在成像的图片上对应Q'点,Q'点在y轴上的投影为P'点。水平线与Zc轴的夹角为α,Zc光轴与PP'的夹角为β,直线OP与地面x1轴的夹角为γ。
5.6.1目标点的选取
根据第四章的运行结果将获得图5-11中的目标检测框,并且已知相机内外参数,将其联合起来就可以得到测距值。具体的本文首先要选取参考点(目标点),拟选取目标框底部中点位置作为参考点,并根据大量目标框的获取结果。观察到目标矩形框比目标物实际尺寸略大,因此采取偏移的方式对目标参考点进行矫正以保证测距精确度。本文采取让参考点向上偏移d个像素点,并且获取的是目标框的左上角和右下角坐标,因此参考点坐标可以表示为:
(5.15)其中xL、xR、yR表示红色框的左上角x坐标、右下角x坐标、右下角y坐标。
图5-11 目标点的选取然而上述目标点适合前方物体在本车正前方的场景,当面对场景如图5-12时,目标物会出现在本车侧方位置。如果再把目标框下部中点作为测距目标点,会出现目标点严重偏离车辆正下方的问题,存在目标点出现在汽车中心位置左侧或中心右侧的现象,这会造成测距精度不高的缺点。因此,进一步的对其进行改进,当目标点(xp,yp)与图像下部中点斜率k满足阈值δ时,就会更新xp'的值,新的xp'可以表示为: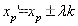
(5.16)其中λ为偏移权重系数,当k值为负时,λ为负;当k值为正时,λ也为正
测量结果


实测6.01米
代码
for path, img, im0s, vid_cap in dataset: img = torch.from_numpy(img).to(device) img = img.half() if half else img.float() # uint8 to fp16/32 img /= 255.0 # 0 - 255 to 0.0 - 1.0 if img.ndimension() == 3: img = img.unsqueeze(0) # Warmup if device.type != 'cpu' and (old_img_b != img.shape[0] or old_img_h != img.shape[2] or old_img_w != img.shape[3]): old_img_b = img.shape[0] old_img_h = img.shape[2] old_img_w = img.shape[3] for i in range(3): model(img, augment=opt.augment)[0] # Inference t1 = time_synchronized() with torch.no_grad(): # Calculating gradients would cause a GPU memory leak pred = model(img, augment=opt.augment)[0] t2 = time_synchronized() distance=object_point_world_position(u, v, h, w, out_mat, in_mat):