Scala之集合(2)

目录
集合基本函数:
(1)获取集合长度
(2)获取集合大小
(3)循环遍历
(4)迭代器
(5)生成字符串
(6)是否包含
衍生集合:
(1)获取集合的头
(2)获取集合的尾
(3)集合最后一个数据
(4)集合初始数据
(5)反转
(6)取前(后)n 个元素
(7)去掉前(后)n 个元素
(8)并集(不去重)
(9)交集
(10)差集
(11)拉链
(12)滑窗
集合的低级函数:
求和:
乘积:
最大值:
最小值:
排序:
简单排序:
从大到小:
从小到大:
排序二元组:
自定义排序:
sortWith排序:
集合计算高级函数:
过滤:
map转化(映射):
转化1:
转化2:
转化3:
扁平化:
flatMap函数:
分组:
Reduce:
1.归约:
2.折叠(fold):
foldLeft():
两个Map的归约(合并):
方法1:
方法二:
集合基本函数:
(1)获取集合长度
val length: Int = list.length(2)获取集合大小
val size: Int = list.size(3)循环遍历
list.foreach(println)(4)迭代器
val iterator: Iterator[Int] = list.iterator while (iterator.hasNext) { println(iterator.next()) }(5)生成字符串
mkString方法是toString底层的方法 toString是加上一些前缀与mkString方法的拼接 val str: String = list.mkString("\t") println(str)(6)是否包含
val bool: Boolean = list.contains(2) println(bool)衍生集合:
调用一个方法 原集合保持不变 生成一个新的集合
(1)获取集合的头
val head: Int = list.head println(head)(2)获取集合的尾
(不是头的就是尾--->去掉头的剩余集合) val tail: List[Int] = list.tail println(tail)(3)集合最后一个数据
val last: Int = list.last println(last)(4)集合初始数据
(不包含最后一个) val init: List[Int] = list.init println(init)(5)反转
val reverse: List[Int] = list.reverse println(reverse)(6)取前(后)n 个元素
取前两个
val ints: List[Int] = list.take(2)取后两个
val ints1: List[Int] = list.takeRight(2)
(7)去掉前(后)n 个元素
去掉前俩返回值为剩下的元素
val ints2: List[Int] = list.drop(2)去掉后俩
val ints3: List[Int] = list.dropRight(2)(8)并集(不去重)
val ints4: List[Int] = list.union(list1)(9)交集
val ints5: List[Int] = list.intersect(list1)(10)差集
val ints6: List[Int] = list.diff(list1)(11)拉链
---就是把两个集合进行拼接成二元组当两个集合元素数量正好相等的时候 恰好组成元组两恶搞集合元素数量不等的时候 会把多余的给舍弃
val tuples: List[(Int, Int)] = list.zip(list1)(12)滑窗
场景:
给一个数组 (-200,50,-10,0,0,-80) 求任意相邻的三个数 成绩最大的是那三个
val list2 = List(-200, 50, -100, 0, -80) val iterator: Iterator[List[Int]] = list2.sliding(3, 1) var result=0 for (elem <- iterator) { if (result<elem.product) { result=elem.product } }参数 窗口大小 步长(一次几个格子) 如果在最后元素少于窗口大小 则依然输出剩下的 product product()方法属于类Abstract Iterator的具体值成员。它用于乘以指定集合的所有元素。
集合的低级函数:
求和:
val sum: Int = ints.sum乘积:
val product: Int = ints.product最大值:
val max: Int = ints.max最小值:
val min: Int = ints.min上述函数都没有()但是他是有参数的 他是一种隐式参数
排序:
简单排序:
排序计算机是采用的快排,默认是从小到大排序,如果需要从大到小需要重写他的参数
从大到小:
val sorted: List[Int] = ints.sorted从小到大:
val ints1: List[Int] = ints.sorted(Ordering.Int.reverse)排序结果的输出可以迭代器也可以for循环
val iterator: Iterator[Int] = sorted.iterator while(iterator.hasNext) { print(iterator.next()+" ") }排序二元组:
val tuples = List(("hello", 10), ("world", 20), ("tuple", 32), ("spark", 58))默认按照第一个元素进行排序
val tuples1: List[(String, Int)] = tuples.sorted(Ordering[(String, Int)])反转排序:它是按照字母的倒叙进行排序
val reverse: List[(String, Int)] = tuples.sorted(Ordering[(String, Int)]).reverse两种排序的运行结果对比:

自定义排序:
按照单词出现的次数排序:
这样是需要自定义的 调用sortBy()函数(By---什么方式)
设置返回类型就是按照什么排序(匿名函数)
val tuples2: List[(String, Int)] = tuples.sortBy((tuples: (String, Int)) => tuples._2)按照单词出现的次数反转排序:
通过sortBy()源码可知他是采用了柯里化写法(闭包---把上层变量定义成常量传给下一层)
val reverse1: List[(String, Int)] = tuples.sortBy((tuples: (String, Int)) => tuples._2)(Ordering[Int]).reverse上述代码在第一次传入参数返回的是以Int类型的集合 在对他进行封装成常量传递给下层 所以 在柯里化的第二个()的时候在设置类型的时候要设置Int类型
sortWith排序:
sortWith参数形式: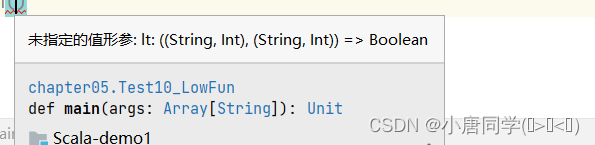
这个就是类似于冒泡排序左边于靠近的右边的进行比较,当不满足某条件的时候进行调换
val tuples3: List[(String, Int)] = tuples.sortWith((lift: (String, Int), right: (String, Int)) => lift._2 > right._2)集合计算高级函数:
下边所写高阶函数都有一个默认的foreach()逻辑,在进行下边操作的时候都会一个一个的传入(遍历)
过滤:
遍历一个集合并从中获取满足指定条件的元素组成一个新的集合 参数为让你填一个函数 int--->BOOL 将集合中元素作为填写函数的传入参数 得到返回结果如果为true 保留 为false 删除 val ints1: List[Int] = ints.filter(i=> i %2 == 0)map转化(映射):
map转化是使用集合的map方法进行结构转化
map方法的参数形式:

转化1:
val ints2: List[Int] = ints.map(i => i * 2)转化2:
val tuples: List[(String, Int)] = ints.map((i:Int) => ("我是", i))转化3:
在Hadoop的hdfs中我们存储的是半结构化数据(一条条的数据字符串)
val list = List("zhangsan,18,男,180", "tangxiaocong,19,男,185") list.map((line:String)=>{ val strings: Array[String] = line.split(",") //构造元组 (strings(0),strings(1),strings(2),strings(3)) })扁平化:
扁平化的使用场景为List集合嵌套List集合,对于这种情况需要使用炸裂
val list1 = List(List(1, 2, 3, 4), List(4, 5, 6, 7), List(7, 8, 9, 10)) val flatten: List[Int] = list1.flatten执行结果:(不去重)

元素必须是可拆分的集合才能调用扁平化
特例:
如果在List中是String则可以使用flatten函数(String是char的集合)
上述情况会把String转换成char的形式
所以在扁平化的时候需要将集合中的字符串转化成List形式(map转化)
val list2 = List("hello world", "hello scala", "hello spark") val list3: List[List[String]] = list2.map((line: String) => { val strings: Array[String] = line.split(",") strings.toList } )让后在进行扁平化(直接调用flatten)
val flatten1: List[String] = list3.flatten
在框架中使用的是flatMap(实际是map+flatten)
flatMap函数:
传入的参数还是map转化的逻辑,让后默认调用flatten函数
val strings1: List[String] = list2.flatMap((line: String) => { line.split(",") } )flattenMap函数需要的参数是集合的形式,是不需要转化成List集合的
分组:
分组之后多组数据转换成了一行数据 生成数据有相同的key value值变成了一个List集合
val tuples1 = List(("A", 10), ("B", 20), ("C", 11), ("D", 15),("A", 16), ("B", 26), ("C", 41), ("D", 35)) val map: Map[String, List[(String, Int)]] = tuples1.groupBy(tuple => tuple._1)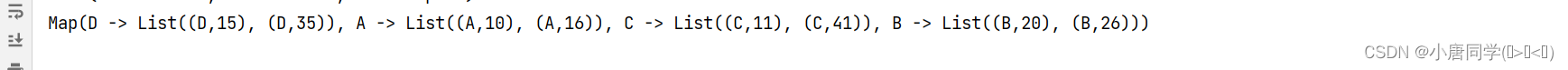
分组条件不止可以为元组的某个值,也可以是自己特定的(通过匿名函数设定)
val ints3 = List(1, 2, 3, 5, 4, 6, 7, 8, 9) val map1: Map[Int, List[Int]] = ints3.groupBy((i: Int) => i % 2)返回值的结果是什么就按照什么进行排序
Reduce:
1.归约:
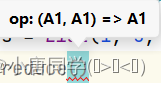
参数表示:输入输出的数据类型是一致的
第一个A1:表示每次调用的结果值
第二个A1:表示当前元素值
第三个A3:本次调用的返回结果, 作为下次的结果值
reduce将第一个初始值作为结果值进行传递 让后直接进行下次reduce(跳过第一个元素从第二个元素开始运行逻辑)
val ints = List(1, 5, 6, 7, 8) val i1: Int = ints.reduce((res: Int, i: Int) => res +i*2)正确结果该是54 输出结果为53 因为运算逻辑为(1+5*2+6*2+7*2+8*2=53)
而我们正确的逻辑应该为1*2+5*2+6*2+7*2+8*2=54

2.折叠(fold):
归约的一种方法

这个函数是采用的柯里化写法第一个()传入初始值(也是结果值),第二个()传入运算逻辑
fold方法就很好的设置了初始值,解决了Reduce方法的缺点
val i2: Int = ints.fold(0)((res: Int, i: Int) => res + i * 2)运行结果:
![]()
foldLeft():
初始值可以为不同类型(常用于Map,tuple)

val tuple: (String, Int) = ints.foldLeft(("sum : elem*2", 0))((res: (String, Int), elem: Int) => { //创建一个新的二元组 (res._1, res._2 + elem * 2) })两个Map的归约(合并):
两个Map集合 一个作为结果存储 一个作为集合遍历
方法1:
val map = mutable.Map(("String", 14), ("Scala", 35)) val map1 = Map(("String", 14), ("Scala", 35), ("Spark", 33)) for (elem <- map1) { val key: String = elem._1 val value: Int = elem._2 if (map.contains(key)) { map.update(key, value + map.getOrElse(key,0)) } else { map.put(key,value) } }上述方法的两个Map(一个是不可变 一个是可变)---不可以重复执行(不稳定,会不断的累加)
方法二:
下边两个Map都是不可变的:
不可变集合 做出改变后要重新返回一个对象
val map2 = Map(("String", 14), ("Scala", 35)) val map3 = Map(("String", 14), ("Scala", 35), ("Spark", 33)) val map4: Map[String, Int] = map2.foldLeft(map3)((mape, elem) => { mape.updated(elem._1, mape.getOrElse(elem._1, 0) + elem._2) }) println(map4)
登录后可发表评论
点击登录