
机器学习:LightGBM算法原理(附案例实战)
作者:i阿极
作者简介:Python领域新星作者、多项比赛获奖者:博主个人首页
???如果觉得文章不错或能帮助到你学习,可以点赞?收藏?评论?+关注哦!???
???如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!?
| 订阅专栏案例:机器学习 |
|---|
| 机器学习:基于逻辑回归对某银行客户违约预测分析 |
| 机器学习:学习k-近邻(KNN)模型建立、使用和评价 |
| 机器学习:基于支持向量机(SVM)进行人脸识别预测 |
| 决策树算法分析天气、周末和促销活动对销量的影响 |
| 机器学习:线性回归分析女性身高与体重之间的关系 |
| 机器学习:基于主成分分析(PCA)对数据降维 |
| 机器学习:基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测 |
| 机器学习:学习KMeans算法,了解模型创建、使用模型及模型评价 |
| 机器学习:基于神经网络对用户评论情感分析预测 |
| 机器学习:朴素贝叶斯模型算法原理(含实战案例) |
| 机器学习:逻辑回归模型算法原理(附案例实战) |
| 机器学习:基于逻辑回归对优惠券使用情况预测分析 |
| 机器学习:基于逻辑回归对超市销售活动预测分析 |
| 机器学习:基于KNN对葡萄酒质量进行分类 |
文章目录
机器学习:LightGBM算法原理(附案例实战)1、LightGBM算法原理2、实验环境3、LightGBM算法案例实战3.1案例背景3.2模型搭建3.3模型预测及评估3.4模型参数调优 总结
1、LightGBM算法原理
LightGBM是一个基于决策树的梯度提升框架,被广泛应用于机器学习任务,如分类、回归和排序等。LightGBM采用了一些独特的技术,例如基于直方图的决策树学习和GOSS(Gradient-based One-Side Sampling)等,以提高模型的训练效率和准确性。
LightGBM的核心思想是采用基于直方图的决策树算法。直方图是对特征值进行离散化处理后,将连续的数值分段成多个区间,每个区间内的数值数量作为该区间的计数值。然后通过直方图算法来优化决策树的分裂点选择,从而提高决策树的训练效率。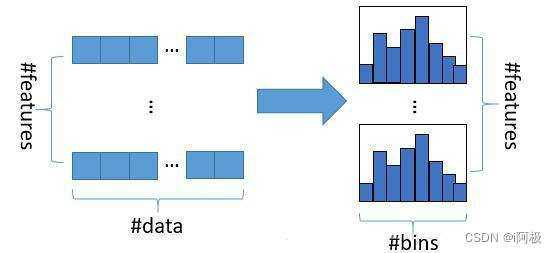
具体来说,LightGBM采用了以下几种优化方法:
基于直方图的决策树算法
LightGBM采用了基于直方图的算法来对连续特征进行离散化处理,将特征值分段成多个区间,计算每个区间内的样本数量,然后根据区间的计数值来选择最佳的分裂点。这种方法避免了对特征进行排序和遍历的操作,从而提高了训练速度。
基于梯度的单边采样
LightGBM采用了基于梯度的单边采样算法来加速训练过程。该算法在每次迭代时,优先选择梯度较大的样本进行训练,从而可以快速找到最佳的模型参数。
基于直方图的特征选取
LightGBM还采用了基于直方图的特征选取算法,该算法通过计算每个特征的直方图信息来评估特征的重要性,然后根据特征重要性的排序选择最佳的特征集合。
带深度的叶节点优化
LightGBM采用了带深度的叶节点优化算法,该算法可以避免过拟合问题,提高模型的泛化能力。具体来说,该算法通过限制叶节点的深度来控制模型的复杂度,从而防止模型在训练数据上过拟合。
2、实验环境
Python 3.9
Anaconda
Jupyter Notebook
3、LightGBM算法案例实战
3.1案例背景
投资商经常会通过多个不同渠道投放广告,以此来获得经济利益。在本案例中我们选取公司在电视、广播和报纸上的投入,来预测广告收益,这对公司策略的制定是有较重要的意义。
3.2模型搭建
读取数据
import pandas as pddf = pd.read_excel('/home/mw/input/XG3004/广告收益数据.xlsx')df.head()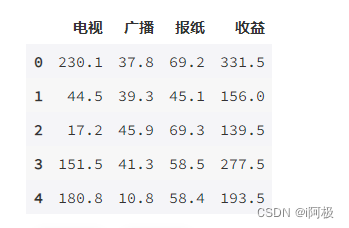
提取特征变量和目标变量
X = df.drop(columns='收益') y = df['收益'] 划分训练集和测试集
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)模型训练和搭建
from lightgbm import LGBMRegressormodel = LGBMRegressor()model.fit(X_train, y_train)
3.3模型预测及评估
预测测试数据
y_pred = model.predict(X_test)y_pred[0:5]
预测值和实际值对比
a = pd.DataFrame() # 创建一个空DataFrame a['预测值'] = list(y_pred)a['实际值'] = list(y_test)a.head()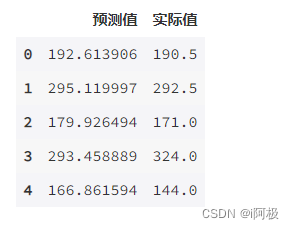
手动输入数据进行预测
X = [[71, 11, 2]]model.predict(X)
查看R-square
from sklearn.metrics import r2_scorer2 = r2_score(y_test, model.predict(X_test))r2
查看评分
model.score(X_test, y_test)
特征重要性
model.feature_importances_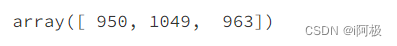
3.4模型参数调优
参数调优
from sklearn.model_selection import GridSearchCV # 网格搜索合适的超参数parameters = {'num_leaves': [15, 31, 62], 'n_estimators': [20, 30, 50, 70], 'learning_rate': [0.1, 0.2, 0.3, 0.4]} # 指定分类器中参数的范围model = LGBMRegressor() # 构建模型grid_search = GridSearchCV(model, parameters,scoring='r2',cv=5)cv=5表示交叉验证5次,scoring='r2’表示以R-squared作为模型评价准则
输出参数最优值
grid_search.fit(X_train, y_train) # 传入数据grid_search.best_params_ # 输出参数的最优值
重新搭建LightGBM回归模型
model = LGBMRegressor(num_leaves=31, n_estimators=50,learning_rate=0.3)model.fit(X_train, y_train)查看得分
model.score(X_test, y_test)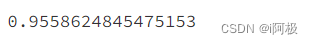
总结
总之,LightGBM是一种高效的集成学习框架,它采用了多种优化方法来提高训练速度和准确性,能够在大规模数据集上实现高效的训练和预测。
?文章下方有交流学习区!一起学习进步!???
?创作不易,如果觉得文章不错,可以点赞?收藏?评论?
?你的支持和鼓励是我创作的动力❗❗❗