我走后,他们会给你们加班费,会给你们调休,这并不是他们变好了,而是因为我来过。------龙哥
文章目录
一、位图1.位图概念2.位图实现及测试3.位图应用和面试题 二、哈希切分(hashfunc + 除留余数法 控制切分的范围)1.哈希切分2.单个子文件太大怎么办?(分两种情况讨论) 三、布隆过滤器1.位图优缺点和布隆过滤器的提出(哈希和位图的结合)2.布隆过滤器的应用场景3.布隆过滤器实现(hashfunc + 除留余数法 控制位图开多大)4.布隆过滤器的删除5.布隆过滤器的面试题
一、位图
1.位图概念
1.
大厂经典的面试题,给你40亿个不重复的无符号整数,让你快速判断一个数是否在这40亿个数中,最直接的思路就是遍历这40亿个整数,逐一进行比对,当然这种方式可以倒是可以,但是效率未免太低了。
另一种方式就是排序+二分的查找,因为二分查找的效率还是比较高的,logN的时间复杂度,但是磁盘上面无法进行排序,排序要支持下标的随机访问,这40亿个整数又无法加载到内存里面,你怎么进行排序呢?所以这样的方式也是不可行的。
那能不能用红黑树或者哈希表呢?红黑树查找的效率是logN,哈希表可以直接映射,查找的效率接近常数次,虽然他们查找的效率确实很快,但是40亿个整数,那就是160亿字节,10亿字节是1GB,16GB字节红黑树和哈希表怎么能存的下呢?这还没有算红黑树的三叉链结构,每个结点有三个指针,而且哈希表每个结点会有一个next指针,算上这些的话需要的内存会更大,所以用红黑树或哈希表也是无法解决问题的。
2.
题目说的是判断在不在,并且都是无符号的整数,也就是正整数,那我们能不能用一个比特位来标识某个数在或不在呢?0标识不存在,1标识存在,这不就能解决问题了吗?所以我们采取位图的方式来解决这个问题。
如果一个数用一个比特位来标识,则42亿多个数就是42亿多个比特位,2的29次方个字节,2的30次方字节是1GB,所以我们开的空间大小就是512MB,申请512MB内存还是够的。

3.
在内存中我们肯定是不能按照bit位来申请内存的,这不符合内存管理的机制,最小申请的内存也是1byte,则在位图里面我们就开出来一个个的char,用每个char的比特位来直接对应数字,这就是直接定址法,第一个char能够表示的数字是0-7,第二个char能够表示的数字是8-15,第三个char能够表示的数字是16-23……以此类推,判断某一个数在第几个char上面/8即可,判断在char上的哪个比特位%8即可,这就完成了位图中对应数字的标识,比特位为1表示这个数字存在,为0表示不存在。
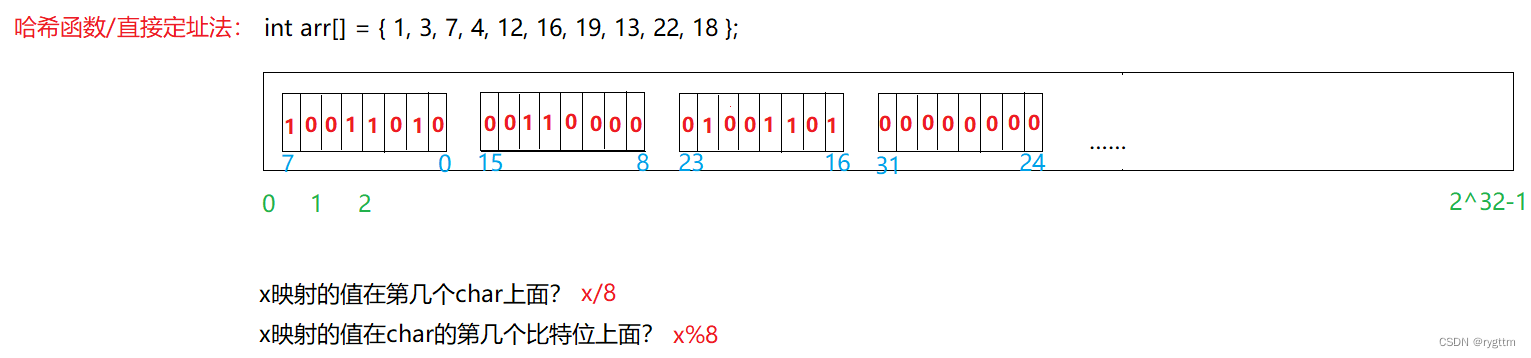
2.位图实现及测试
1.
位图的功能主要分为三个函数,对某一比特位的置1 set(),对某一比特位的置0 reset(),对某一比特位是1还是0进行判断test()。
对于set,想要让某一比特位变为1其他位不变,则可以用1按位或对应的比特位,那就只需让1向高位移动j位,然后用位图中对应的char进行按位或等即可。
对于reset,想要让某一比特位变为0其他位不变,则可以用0按位与对应的比特位,那就只需让1向高位移动j位,然后按位取反,最后用位图中对应的char进行按位与等即可。
对于test,我们可以让对应比特位按位与1,其他比特位按位与0,这样其他比特位都是0,如果测试的比特位是1,则结果是非0,那就是true,如果测试的比特位是0,则结果是0,那就是false。
有些编译器下bool值是4个字节,如果是4个字节则返回的时候要发生整型提升,但我的编译器是1个字节,无须整型提升,直接返回即可。
// 非类型模板参数template <size_t N>class bitset{public:bitset(){_bits.resize(N / 8 + 1, 0);//可能开的比特位恰好满足数字的个数,也可能最多浪费7个比特位//_bits.resize(N << 3 + 1, 0);//位运算符优先级过低,这里先进行+运算,则结果和我们预想的不一致,发生错误。}void set(size_t x){size_t i = x / 8;size_t j = x % 8;_bits[i] |= 1 << j;}void reset(size_t x){size_t i = x / 8;size_t j = x % 8;_bits[i] &= ~(1 << j);}bool test(size_t x){size_t i = x / 8;size_t j = x % 8;return _bits[i] & (1 << j);//这里不是&=,因为test不改变位图,只是判断一下而已//有些编译器bool值是四个字节,返回时会发生整型提升,高位补符号位,但这些都不重要,只要是非0就行,判断为真//我的编译器bool值是一个字节}private:vector<char> _bits;};2.
在位图这里有些老铁容易将其和字节序的大小端混淆,从而在进行比特位移动的时候会产生误解,认为如果是小端,则向高位移动就是向左移动,如果是大端则向高位移动就是向右移动,这是错误的,在移动比特位这里我们不需要考虑这么多,无论是大端机器还是小端机器针对的都是整型的单个字节序,而且只要你用<<那就是向高位移动,用>>就是向低位移动,不要去看方向,而且大端机的数据高位和低位确实和我们日常的习惯不符合,但是CPU会在内存中处理数据,你不需要过多考虑。你只需要记住<<是让数据向地址的高位移动,>>是让数据向地址的低位移动。

3.
下面是位图的测试代码,如果要开42亿多比特位的话,可以用-1转成无符号整数的方式来表示42亿,当然也可以通过语言自带的预定义宏来表示42亿多。
从任务管理器中也可以看到运行进程申请的内存的确是512MB多一些,因为还有其他的信息也需要占用内存。
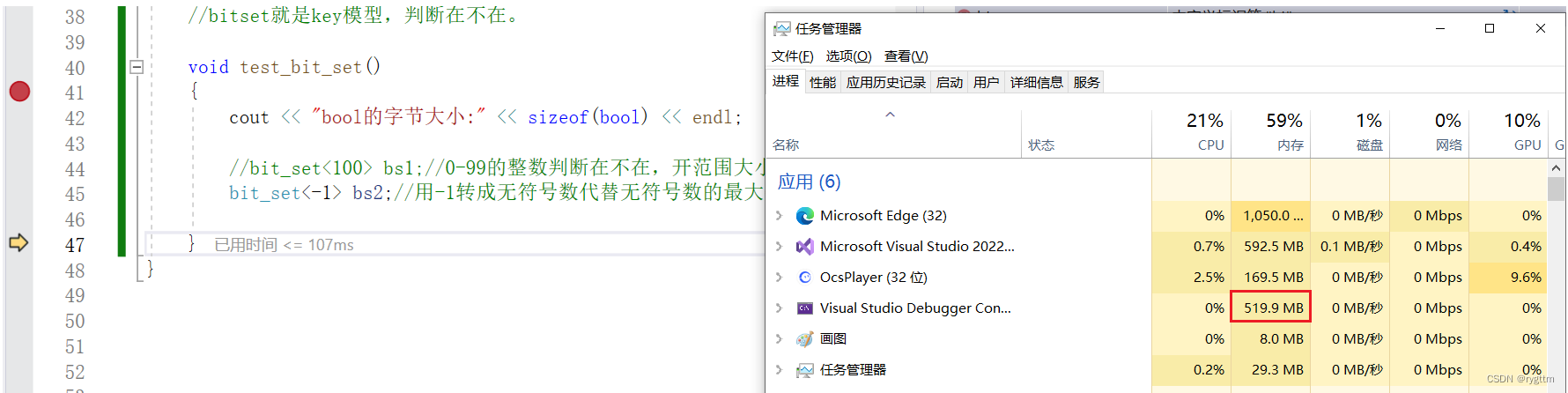

void test_bitset(){cout << "bool的字节大小:" << sizeof(bool) << endl;//bitset<100> bs1;//0-99的整数判断在不在,开范围大小bitset<-1> bs2;//用-1转成无符号数代替无符号数的最大数42亿9千万,0xffffffff,INT_MAX是21亿,用UINT_MAXbs2.set(10);bs2.set(10000);bs2.set(99999);bs2.set(88888);cout << bs2.test(10) << endl;cout << bs2.test(10000) << endl;cout << bs2.test(99) << endl;cout << bs2.test(100) << endl;cout << bs2.test(101) << endl;cout << bs2.test(88888) << endl;bs2.reset(10000);bs2.reset(88888);cout << endl;cout << bs2.test(10) << endl;cout << bs2.test(10000) << endl;cout << bs2.test(99) << endl;cout << bs2.test(100) << endl;cout << bs2.test(101) << endl;cout << bs2.test(88888) << endl;}3.位图应用和面试题
1.
之前是判断整数是否出现,现在是判断只出现一次的整数,那就说明有的整数出现了多次,其实解决起来也很简单,我们只需要开两个位图即可,用两个比特位去标识即可,00代表出现0次,01代表出现1次,10或者11什么的我们就不管了,他们统一表示出现一次以上。
有人可能会觉得100亿个整数太多了,担心位图存不下,别说100亿,就是1000亿,1w亿都能存的下,因为位图存的是一个范围内有多少种数,与数据的个数完全无关,仅仅和数据的范围有关系,所以根本不用担心存不下这样的事情,因为整数最多就42亿多个。
template <size_t N>class twobitset{public:twobitset()//初始化列表会初始化{}void set(size_t x){if (!_bs1.test(x) && !_bs2.test(x)){//出现0次,则搞成01_bs2.set(x);}else if(!_bs1.test(x) && _bs2.test(x)){//出现1次,则搞成10_bs1.set(x);_bs2.reset(x);}//10出现1次以上,不需要变他}void PrintOnce(){for (size_t i = 0; i < N; i++){if (!_bs1.test(i) && _bs2.test(i)){//如果是01,说明出现一次,可以打印出来cout << i << endl;}}}private:bitset<N> _bs1;//用的是我们自己写的bitset,编译器优先在wyn命名空间找bitset<N> _bs2;};void test_twobitset(){twobitset<100> tbs;int arr[] = { 3,5,3,99,99,67,45,51,52,52 };for (auto e : arr){tbs.set(e);}tbs.PrintOnce();}2.
我们可以开两个位图,分别给两个有100亿整数的文件各自开一个位图,将各个文件中的整数映射到各自的位图当中,然后分别遍历比对两个位图,当两个比特位同时为1时,表示对应的整数同时在两个文件中出现,即为两个文件交集中元素的一员。或者可以分别对两个位图中的每一个char进行按位与,同时为1的比特位会留下,留下的比特位就是文件的交集整数。
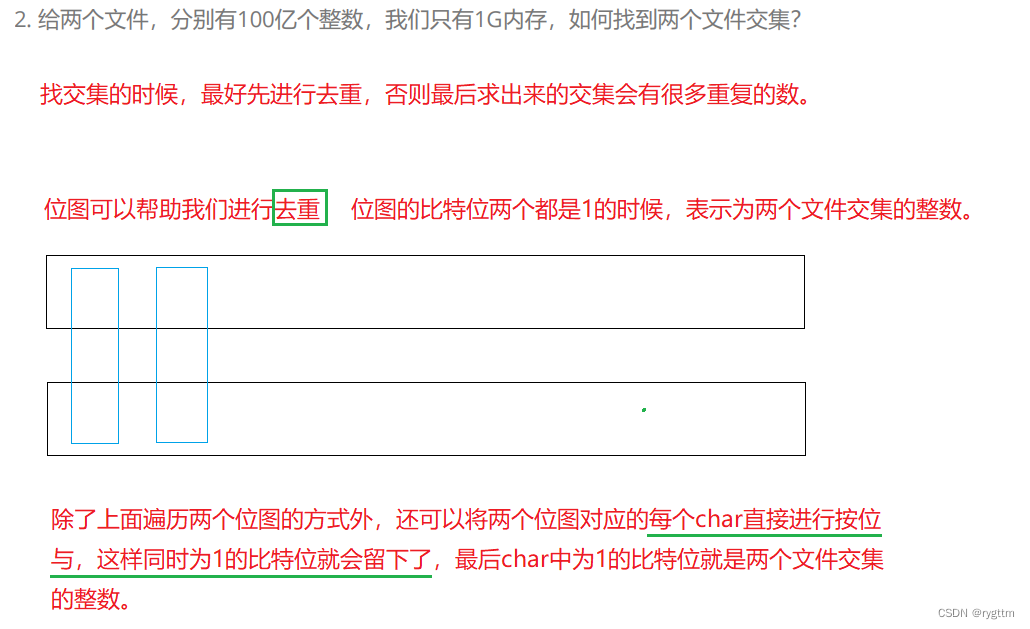
3.
这道题和第一个其实是一样的,只不过第一个求的是只出现一次的,这个求的是不超过两次的,那就是出现1次和2次的,也很简单两个比特位的组合即可表示出现次数为0 1 2 2次以上的这四种情况,所以实现起来也比较简单,和第一题一样开两个位图即可解决。

二、哈希切分(hashfunc + 除留余数法 控制切分的范围)
1.哈希切分
1.
这样的题目典型就是KV模型的问题,即通过key IP找对应的value 出现次数,对于KV模型的问题首先想到的就是用map来统计次数,但是100G大小的文件是无法加载到内存的,所以直接用map是不行的。
有人可能会想到用位图来解决这里的问题,多开几个位图,用多个比特位的组合来表示次数,这样的想法也是不行的,你怎么知道次数最多是几次呢?如果出现次数最多是10w次呢?你要开多少个位图呢?内存够开那么多位图吗?所以这样的方式也是不行的。

2.
既然直接用map存储无法解决,那就间接用map进行存储KV键值对。切分大文件变成小文件,让小文件中的内容能够加载到内存里面,能够用map存储起来。
首先试想一下,平均切分100G文件可以吗?如果平均切分的话,则某些多次出现的IP可能会被散列到不同的子文件当中,每次内存只能加载一个子文件的内容,此时统计出的最多IP次数在大文件中是最多的吗?这当然是不确定的,所以平均切分的方式万万不可行,因为相同的IP有可能在平均切分的过程中被散列到不同的子文件,则会导致每个子文件中出现次数最多的IP是不可靠的。
3.
在切分文件的这一步中就要用到哈希切分了,我们可以将IP进行字符串哈希算法的转换,将其转换为整型,控制映射的范围为0-99,即用转换为整型后的值去%100,那么相同的IP就一定会映射到同一个文件当中,此时每个子文件就相当于一个冲突哈希桶,里面装着的都是出现多次的IP,当然也有可能是只出现一次的IP,反正这些都不重要,只要出现多次的IP没有散列到不同的子文件,分到相同的子文件即可。
此时每个子文件中出现次数最多的IP的次数和在大文件中出现的次数是相同的,则我们只需要一个字符串对象,存储当前子文件中出现次数最多的IP即可,然后依次遍历后面的子文件,若次数大于上一个文件中出现次数最多的IP,那就更新字符串对象即可。
2.单个子文件太大怎么办?(分两种情况讨论)
1.
如果哈希切分后的单个子文件还是太大该怎么办呢?
此时要分为两种情况,如果子文件中冲突的IP大多是不相同的IP,那么map是会统计不下的,此时就需要我们换个字符串hashfunc,递归哈希切分这个子文件,可以改变一下哈希函数中除留余数法,模的大小,但除留余数法还是挺好用的,如果你觉得不太好用,你也可以尝试其他的哈希函数,我个人推荐继续使用除留余数法,改变一下模的大小,再换个hashfunc,重新建立映射关系,递归将这个子文件进行哈希切分,直到map能够统计这个子文件中的IP内容为止。
另一种情况就是,如果子文件中冲突的IP大多是相同的IP,此时虽然文件的大小表面上看来很大,map有可能存不下,但是不要忘了,map是可以去重的呀,虽然你文件很大,但是大多数的IP都是重复的IP,map当然是可以存的下的,对于大量出现的IP只需要++对应的出现次数value即可。
2.
具体实现的方案是这样的,上来先遍历子文件内容,将每个内容构造成键值对插入到map里面,如果map存不下,则在插入的过程中会出现内存不够的情况,insert会报错,那其实就是new结点失败,new失败是会抛异常的,我们只要捕获这个异常即可,此时说明这个子文件中大多是不同的IP,那么只需要递归哈希切分这个子文件即可。
如果map能够存的下,则正常统计出 出现次数最多的IP即可,无须进行其他任何操作。

三、布隆过滤器
1.位图优缺点和布隆过滤器的提出(哈希和位图的结合)
1.
位图是一个个的比特位作为存储内容的vector构成的,他利用了直接定址法的思想,并且每个整数都能映射到位图的唯一位置,不会有哈希冲突的情况发生,而且由于是比特位构成的,那也能突出他空间消耗非常的小。
但位图也有他的缺点,它适用于解决K模型的问题,KV模型用位图解决是不太适合的,并且位图只能针对于整型,对于其他类型无法支持。

2.
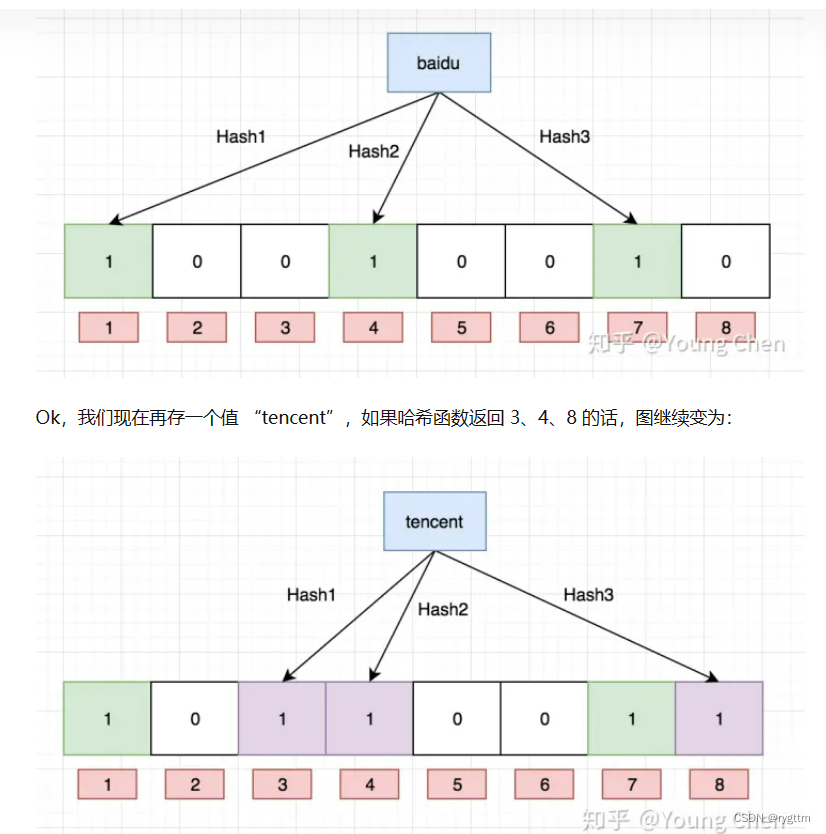
对于位图只能解决整型情况下的K模型,而对于字符串这样类型的K模型问题便无法支持的情况,有大佬将哈希和位图结合提出了布隆过滤器。
即 将字符串通过hashfunc转换为整形后通过除留余数法得到哈希地址,但这样的操作势必会出现哈希冲突,因为字符串是无限的,而整数是有限的,在除留余数得到哈希地址的过程中,肯定会有两个字符串同时映射到相同的哈希地址处,这样的情况就是我们所说的哈希冲突,有可能本身insert没有被映射到位图中,但是当test(“insert”)的时候,他的映射位置和sort重合,那么对应的比特位被sort置为1了已经,则insert被误判为存在于位图当中,此时就出现了误判的问题。
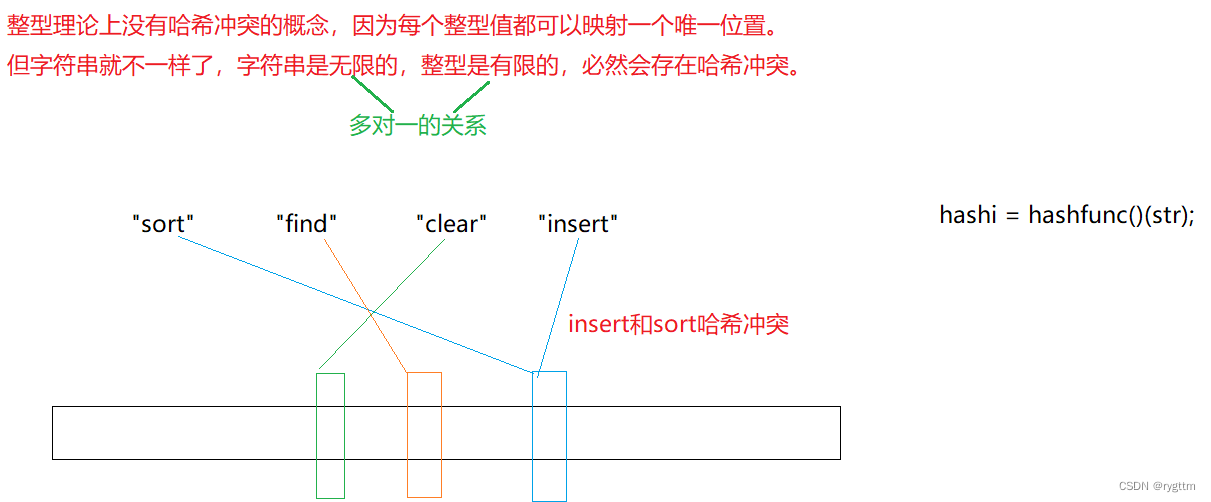
3.
我们如何解决布隆过滤器误判的问题呢?首先误判这样的问题肯定是不能消除的,因为不管你hashfunc处理的再好,但字符串是无限的啊,永远都会存在哈希冲突的情况,所以是无法消除这样的问题的,我们只能降低误判的概率,让布隆过滤器对于K模型在不在的问题判断的更加精确一点,想要完全精确这是不可能的。
4.
布隆过滤器判断在是不准确的,但是不在一定是准确的,因为在有可能是他的比特位和其他的字符串冲突了,但是如果判断不在,那相应比特位是0,表示当前test的字符串的的确确是不在的。
在开位图大小这里我们优点无法确定,因为如果用直接映射的话,我们不清楚字符串转换为的整数最大是多少,最小是多少,所以我们用除留余数法来控制位图开多大。

降低误判率就是通过一个字符串通过多个hashfunc映射位图中多个不同的位置,只有多个位置同时为1时才表示存在,有一个为0即表示不存在,这样的方式只能降低误判率,因为有可能多个位置都发生了冲突,两个字符串映射到的三个比特位恰好是相同的,这样的情况也是有可能发生的。
5.
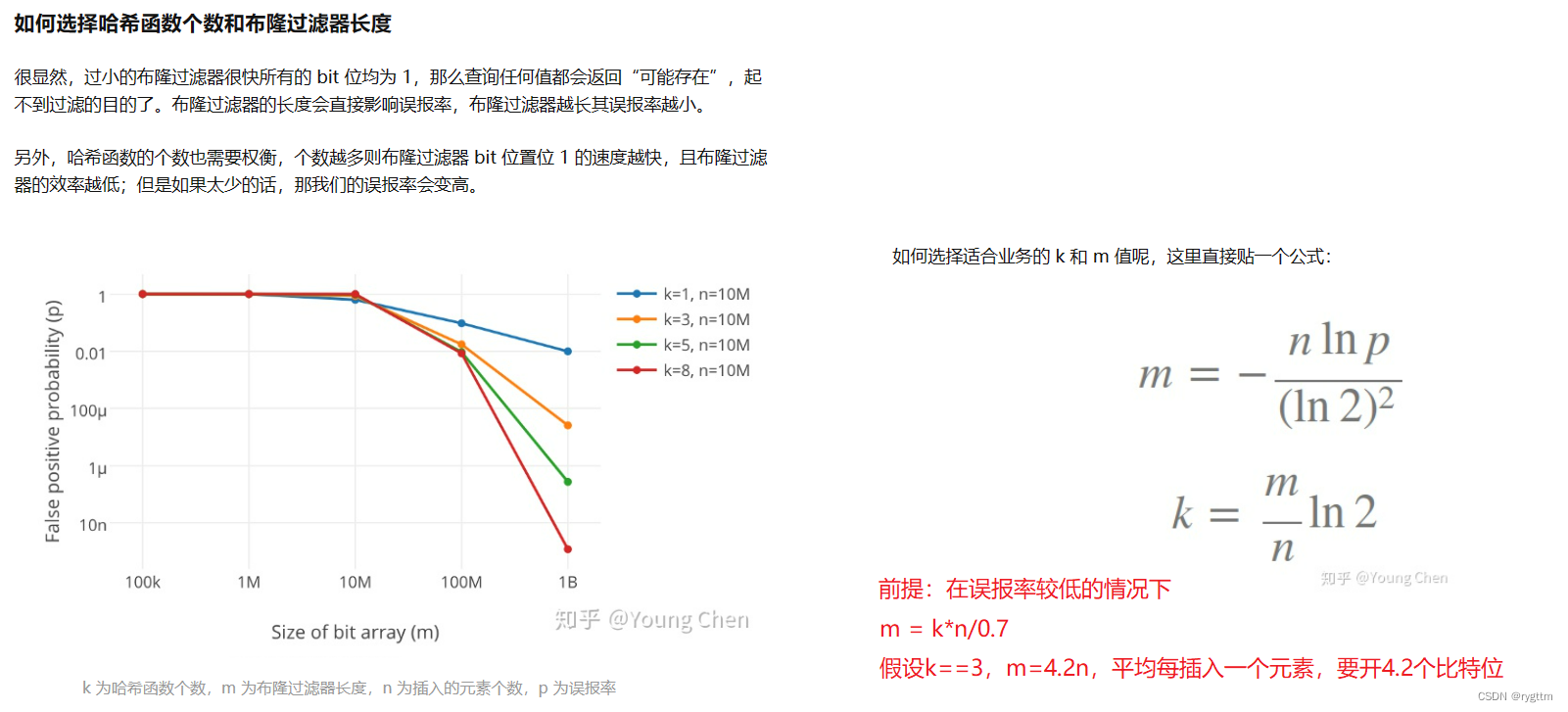
我们如何选择哈希函数个数和布隆过滤器长度呢?
哈希函数选择过多,则布隆过滤器bit位置被置为1的速度就越快,布隆过滤器也会容易误判,哈希函数选择太少的话,误报率也会变高,因为没有其他的选择,各个字符串只有一个bit位,如果冲突,则必然发生误报。
布隆过滤器的长度越短,则很快所有的bit位置就会被置为1,这也会影响布隆过滤器的判断准确性,如果布隆过滤器的长度越长,则误报率其实会越低,因为各个字符串的映射位置会分散开来,不易产生误报,只是空间消耗会上升,所以布隆过滤器的长度也不宜过于长。
6.
如何选择哈希函数个数和布隆过滤器的长度,下面文章进行了详细解释,并贴出了一个公式,假设在3个哈希函数的情况下,如果想要让误报率较低,则在位图中每set一个元素,大概要开4.2个比特位。
详解布隆过滤器的原理,使用场景和注意事项
2.布隆过滤器的应用场景
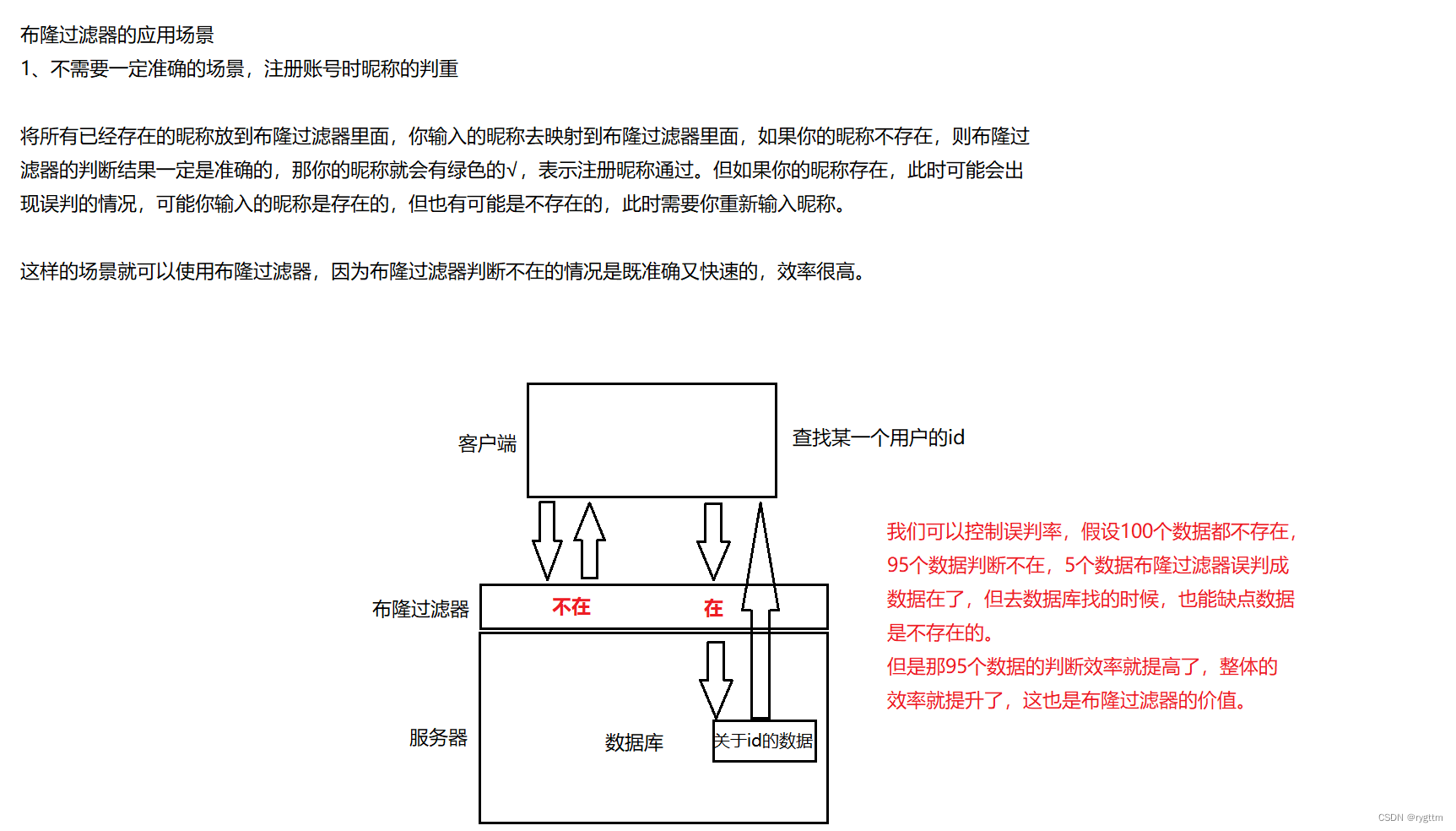
布隆过滤器一般适用于不需要准确判断的场景,比如下面列举的昵称判重,查找用户id等情况下,都可以使用布隆过滤器。
3.布隆过滤器实现(hashfunc + 除留余数法 控制位图开多大)
1.
布隆过滤器的底层就是用位图来实现的,实现起来还是比较简单的,增加几个hashfunc,多去映射几个位置,在set的时候将多个哈希位置设为1,测试的时候,只要有一个位置是0,则没有必要继续判断下去,返回false即可,当前测试的字符串一定是不存在的。
2.
下面代码中X代表布隆过滤器的长度倍数,即插入N个元素时,布隆过滤器要开的长度为X×N的大小,默认布隆过滤器判断在不在的元素类型为string,如果你想判断其他元素类型,可以自己去传对应的模板参数,但hashfunc也可能需要换一下,需要能够将你所传的类型转为整型。
3.
除4个hashfunc外,你也可以测试3个 5个等等,你也可以改变布隆过滤器的长度倍数等等,进行逐一的测试比较。
struct BKDRHash{size_t operator()(const string& key){size_t hash = 0;for (auto ch : key){hash *= 131;hash += ch;}return hash;}};struct APHash{size_t operator()(const string& key){unsigned int hash = 0;int i = 0;for (auto ch : key){if ((i & 1) == 0){hash ^= ((hash << 7) ^ (ch) ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ (ch) ^ (hash >> 5)));}++i;}return hash;}};struct DJBHash{size_t operator()(const string& key){unsigned int hash = 5381;for (auto ch : key){hash += (hash << 5) + ch;}return hash;}};struct JSHash{size_t operator()(const string& s){size_t hash = 1315423911;for (auto ch : s){hash ^= ((hash << 5) + ch + (hash >> 2));}return hash;}};//布隆过滤器不仅可以存字符串,也可以存其他类型,只要最后能转换成整型完成取模映射就行,取模是比较常用的哈希函数//平均存储一个值,开辟X个比特位template <size_t N, size_t X = 8, class K = string,class Hashfunc1 = BKDRHash, class Hashfunc2 = APHash, class Hashfunc3 = DJBHash, class Hashfunc4 = JSHash>class BloomFilter{public:void set(const K& key){size_t hash1 = Hashfunc1()(key) % (X * N);size_t hash2 = Hashfunc2()(key) % (X * N);size_t hash3 = Hashfunc3()(key) % (X * N);size_t hash4 = Hashfunc4()(key) % (X * N);_bs.set(hash1);_bs.set(hash2);_bs.set(hash3);_bs.set(hash4);}bool test(const K& key){size_t hash1 = Hashfunc1()(key) % (X * N);if (!_bs.test(hash1)){return false;}size_t hash2 = Hashfunc2()(key) % (X * N);if (!_bs.test(hash2)){return false;}size_t hash3 = Hashfunc3()(key) % (X * N);if (!_bs.test(hash3)){return false;}size_t hash4 = Hashfunc4()(key) % (X * N);if (!_bs.test(hash4)){return false;}//上面判断不在的情况一定是准确的。return true;//这里可能会存在误判,多个哈希位置都和别的字符串冲突了}private:std::bitset<N * X> _bs;//如果size_t类型×X过后,size_t类型存不下,也可以选择换long long类型};下面是布隆过滤器代码的测试接口,代码难度并不大,你可以看看具体的逻辑,然后进行接口调用即可。
void test_bloomFilter2(){srand(time(0));const size_t N = 10000;BloomFilter<N> bf;std::vector<std::string> v1;std::string url = "https://www.cnblogs.com/-clq/archive/2012/0X/31/2X281X3.html";for (size_t i = 0; i < N; ++i){v1.push_back(url + std::to_string(i));}for (auto& str : v1){bf.set(str);}// v2跟v1是相似字符串集,但是不一样std::vector<std::string> v2;for (size_t i = 0; i < N; ++i){std::string url = "https://www.cnblogs.com/-clq/archive/2012/0X/31/2X281X3.html";url += std::to_string(999999 + i);v2.push_back(url);}size_t n2 = 0;for (auto& str : v2){if (bf.test(str)){++n2;}}cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;// 不相似字符串集std::vector<std::string> v3;for (size_t i = 0; i < N; ++i){string url = "zhihu.com";url += std::to_string(i + rand());//rand()总共只有3w多个不重复的数据,所以测试数据N多了以后,这里+i让其不重复v3.push_back(url);}size_t n3 = 0;for (auto& str : v3){if (bf.test(str)){++n3;}}cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;}4.布隆过滤器的删除
1.
布隆过滤器最好不要支持reset接口,因为可能会相互影响。但如果强行支持reset,则可以通过多开位图的方式来实现,用比特位的组合来标识当前比特位的哈希冲突个数,即为计数器的方式来标识,这样可以不影响其他的字符串存储情况。

2.
但如果采用计数方式来实现reset,也就是布隆过滤器的删除,会存在一些问题。比如你不小心将某一个字符串多次重复删除,此时计数会进行- -,但如果是0- -呢?有可能还会发生越界访问等问题。所以计数方式也有他的缺陷,最好不要强制增加布隆过滤器的reset操作。
5.布隆过滤器的面试题
1.
近似算法其实就是布隆过滤器来实现,将所有的query转换成整数,然后将整数进行除留余数法后完成映射,整数范围最多是42亿,42亿比特位才占用512MB,1G的空间用来开位图一定是够用的,而且我们是可以自己控制位图的大小的,我们想开多大就开多大,我们只开200MB可以吗?当然是可以的,哈希函数的个数,布隆过滤器的长度都是我们自己可以控制的,这是除留余数法给我们带来的最大的好处,因为我们是不清楚字符串转换为整型后是多大的,所以可以通过%N来将他转换后的整型控制在0 - N-1里面。此时将其中一个文件所有的query添加到布隆过滤器中,遍历另一个文件内容,看遍历到的query是否存在于布隆过滤器里面,当然可能会出现误判的情况,但题目要求给出近似算法即可。

2.
对于精确算法来说,核心还是使用哈希切分的思想,将两个大文件分别使用哈希切分,切分成1000个小文件,AB大文件各自遍历query语句,两个大文件的哈希切分函数用的是相同的,相同的query一定会各自进入到对应编号的小文件,然后再分别比对对应的小文件里的query语句,此时进行比对可以用哈希表的方式,先对两个小文件各自去重一下,或者用底层为红黑树的map也可以,因为此时文件已经被哈希切分的很小了,内存可以存的下。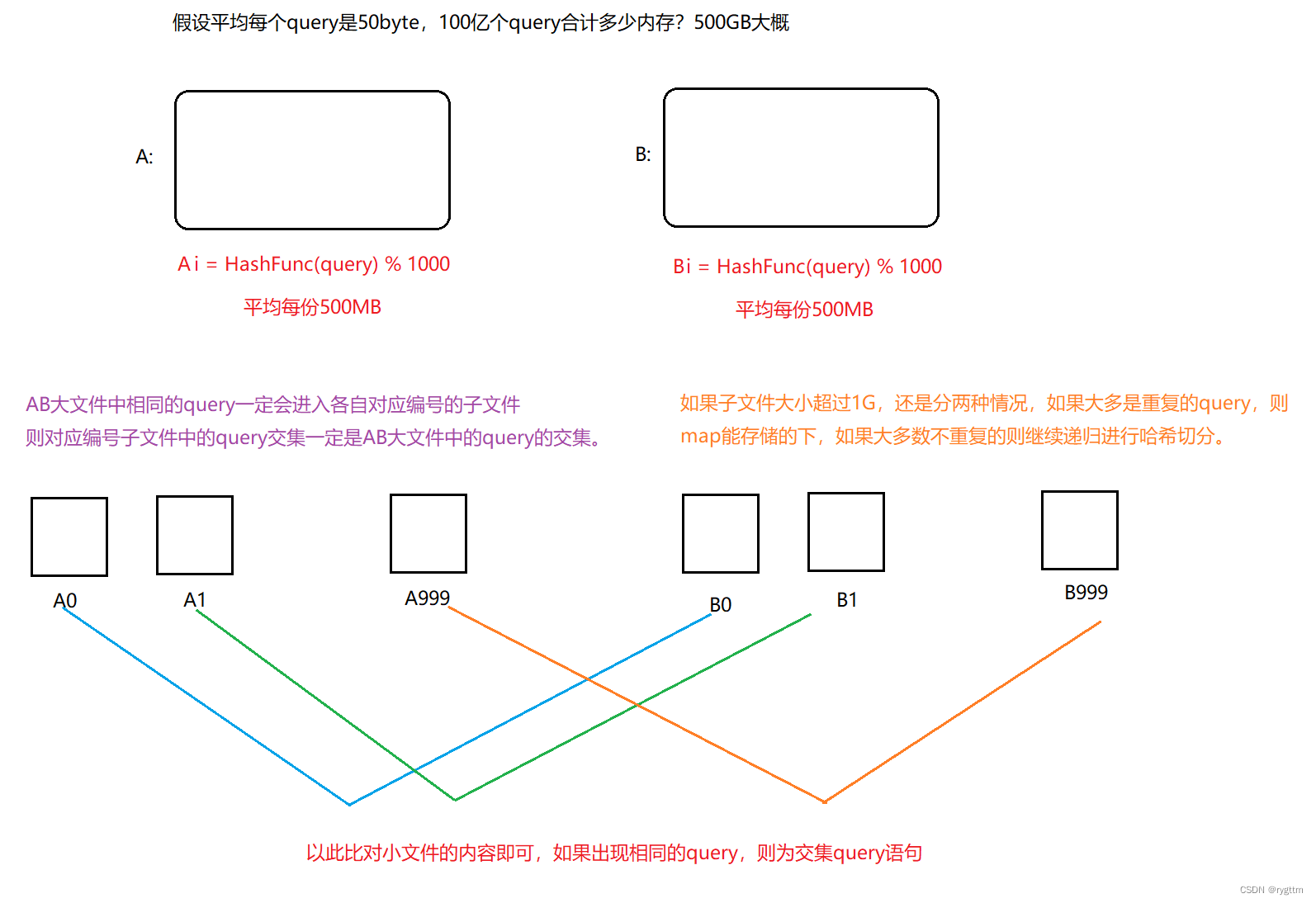
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=2iu03uh9z2ios