机器学习:基于逻辑回归对某银行客户违约预测分析
作者:i阿极
作者简介:Python领域新星作者、多项比赛获奖者:博主个人首页
???如果觉得文章不错或能帮助到你学习,可以点赞?收藏?评论?+关注哦!???
???如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!?
| 专栏案例:机器学习 |
|---|
| 机器学习:基于主成分分析(PCA)对数据降维 |
| 机器学习:学习k-近邻(KNN)模型建立、使用和评价 |
| 机器学习:基于支持向量机(SVM)进行人脸识别预测 |
| 决策树算法分析天气、周末和促销活动对销量的影响 |
| 机器学习:线性回归分析女性身高与体重之间的关系 |
| 机器学习:基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测 |
| 机器学习:学习KMeans算法,了解模型创建、使用模型及模型评价 |
文章目录
机器学习:基于逻辑回归对某银行客户违约预测分析一、实验目的二、实验原理三、实验环境四、实验内容五、实验步骤1.逻辑回归2.业务理解3.读取数据4.数据理解5.数据准备6.逻辑回归模型训练7.模型评价 总结
一、实验目的
1.理解逻辑回归原理
2.掌握scikit-learn操作逻辑回归方法
二、实验原理
机器学习是博大精深的,除了我们上一次说的线性回归,还有一类重要的回归就是逻辑回归。逻辑回归其实用于二分分类问题,用于判断一个离散性的特征得到的标签类型的概率。举个例子,你是否喜欢一首歌是通过很多这个歌的特征(如节奏、强度等)来判断的,那么我们的数据集就是各种歌的特征,而返回的结果则是一个非1即0,不是喜欢就是不喜欢的结果: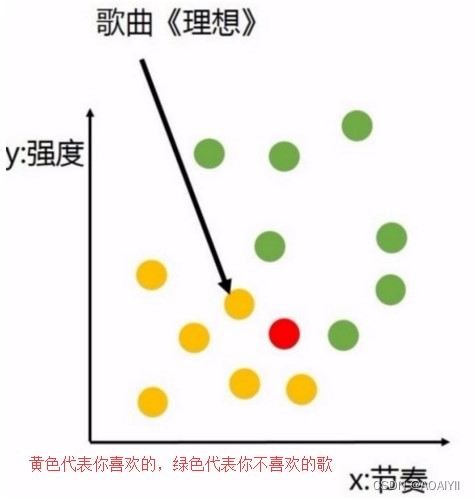
而机器学习可以做到什么呢?它会通过模型形成一个决策面,在你喜欢和不喜欢的歌之间划出一条分界线,就像这样: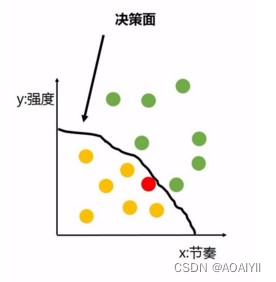
用线性回归的拟合线已经无法很好的表示结果了,这时候就是使用逻辑回归来分类的时候了,而对于Logistic Regression来说,其思想也是基于线性回归(Logistic Regression属于广义线性回归模型)。其公式如下:
其中,
被称作sigmoid函数,我们可以看到,Logistic Regression算法是将线性函数的结果映射到了sigmoid函数中。sigmoid的函数图形如下: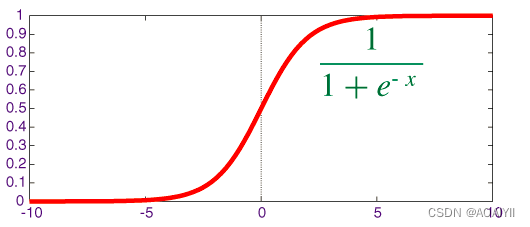
我们可以看到,sigmoid的函数输出是介于(0,1)之间的,中间值是0.5,于是之前的公式 hθ(x) 的含义就很好理解了,因为 hθ(x) 输出是介于(0,1)之间,也就表明了数据属于某一类别的概率,例如 :
hθ(x)hθ(x)<0.5 则说明当前数据属于A类;
hθ(x)hθ(x)>0.5 则说明当前数据属于B类。
所以我们可以将sigmoid函数看成样本数据的概率密度函数
三、实验环境
Python 3.6.1以上
Jupyter
四、实验内容
根据逻辑回归,分析银行违约客户的各项特征,推测某一客户违约的情况
五、实验步骤
1.逻辑回归
逻辑回归用于二分分类问题,回归是一种极易理解的模型,就相当于y=f(x),表明自变量x与因变量y的关系。最常见问题有如医生治病时的望、闻、问、切,之后判定病人是否生病或生了什么病,其中的望闻问切就是获取自变量x,即特征数据,判断是否生病就相当于获取因变量y,即预测分类。
2.业务理解
某银行违约客户信息表如下:(这里只展示了部分数据)我们通过银行客户资料违约情况表来做逻辑回归分析,其中的年龄、教育、工龄、地址、收入、 负债率、信用卡负债、其他负债就是获取自变量x,即特征数据,判断是否违约就相当于获取因变量y,即预测分类。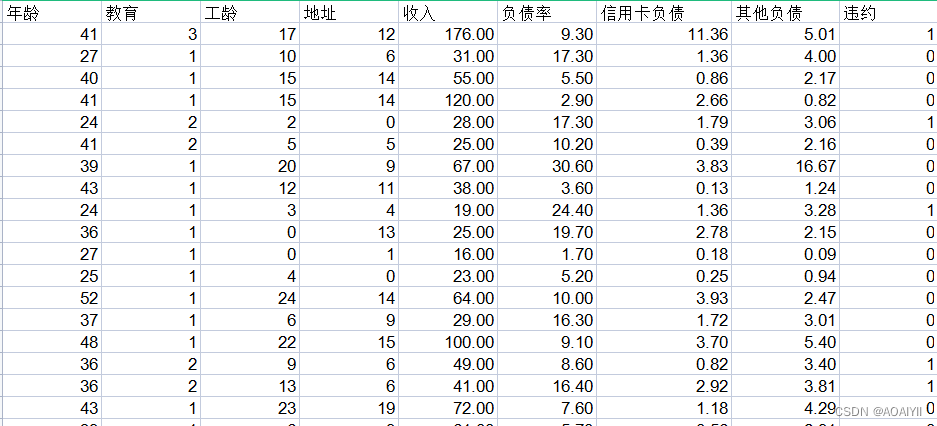
3.读取数据
1.编写代码,读取数据
import numpy as npimport pandas as pddata = pd.read_excel(r'D:\CSDN\数据分析\逻辑回归\loandata.xls')data.head()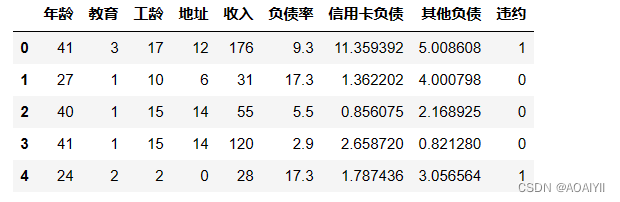
4.数据理解
1.查看数据结构
data.shape
说明:loandata.xls数据位700行9列
2.查看数据列名称
data.columns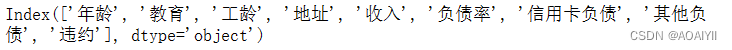
说明:loandata.xls中列名称为:‘年龄’‘教育’‘工龄’‘地址’‘收入’‘负债率’‘信用卡负债’‘其他负债’’违约‘
5.数据准备
数据准备就是获得特征数据和预测分类
1.删除’违约‘这一列数据得到特征数据
X_Data = data.drop(['违约'],axis = 1)X_Data.head()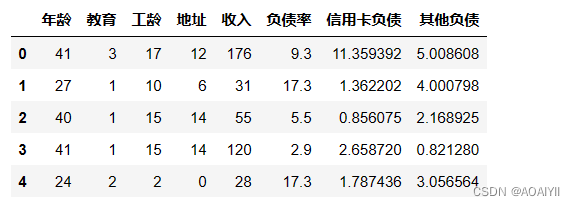
2.获取’违约‘这列数据得到预测分类
y_data = np.ravel(data[['违约']])y_data[0:5]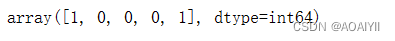
6.逻辑回归模型训练
1.创建新的特征矩阵
X2_data = data.drop(['年龄','教育','收入','其他负债','违约'],axis=1) X2_data.head() 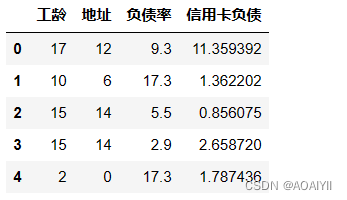
2.建立训练数据和测试数据
train_test_split是交叉验证中常用的函数,功能是从样本中随机的按比例选取训练数据(train)和测试数据(test)
第1个参数:所要划分的样本特征
第2个参数:所要划分的样本标签
random_state:它的用途是在随机划分训练集和测试集时候,划分的结果并不是那么随机,也即,确定下来random_state是某个值后,重复调用这个函数,划分结果是确定的
from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(X2_data,y_data,random_state=1) print(X_train.shape) print(X_test.shape) 
3.进行逻辑训练
#导入逻辑回归包 from sklearn.linear_model import LogisticRegression # 创建模型:逻辑回归 lr = LogisticRegression() #训练模型 lr.fit(X_train,y_train)4.查看训练模型参数
lr.coef_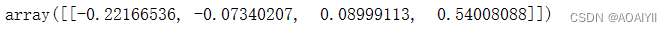
5.查看截距
#训练模型截距 lr.intercept_ 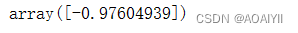
6.预测数据
使用模型的predict方法对划分的X测试数据可以进行预测得值“违约”情况
lr.predict(X_test) 
7.模型评价
1.我们使用“准确率"来评估模型:
#模型评价的平均正确率 lr.score(X_test,y_test) 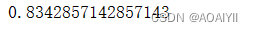
得到的结果准确率为0.834
总结
逻辑回归用于二分分类问题,回归是一种极易理解的模型,就相当于y=f(x),表明自变量x与因变量y的关系。最常见问题有如医生治病时的望、闻、问、切,之后判定病人是否生病或生了什么病,其中的望闻问切就是获取自变量x,即特征数据,判断是否生病就相当于获取因变量y,即预测分类。