目录
1. ResNet 介绍
2. ResNet 网络介绍(ResNet34)
3. 搭建ResNet 网络
residual block
ResNet
pre 传播
layer1
layer2
layer3、4
全连接层的forward
ResNet 网络的参数个数
summary
4. 训练网络
5. 预测图片
6. Code
7. 迁移学习
1. ResNet 介绍
ResNet 的亮点:
超深的网络结构,可以突破1000层提出residual 模块使用Batch Normalization 抑制过拟合,丢弃Dropout方法针对第一点,我们知道加深网络层对于提升网络性能至关重要。然而实际情况中,网络层的加深会导致学习无法进行,性能会更差。因为网络的深度会导致梯度消失或者梯度爆炸的问题
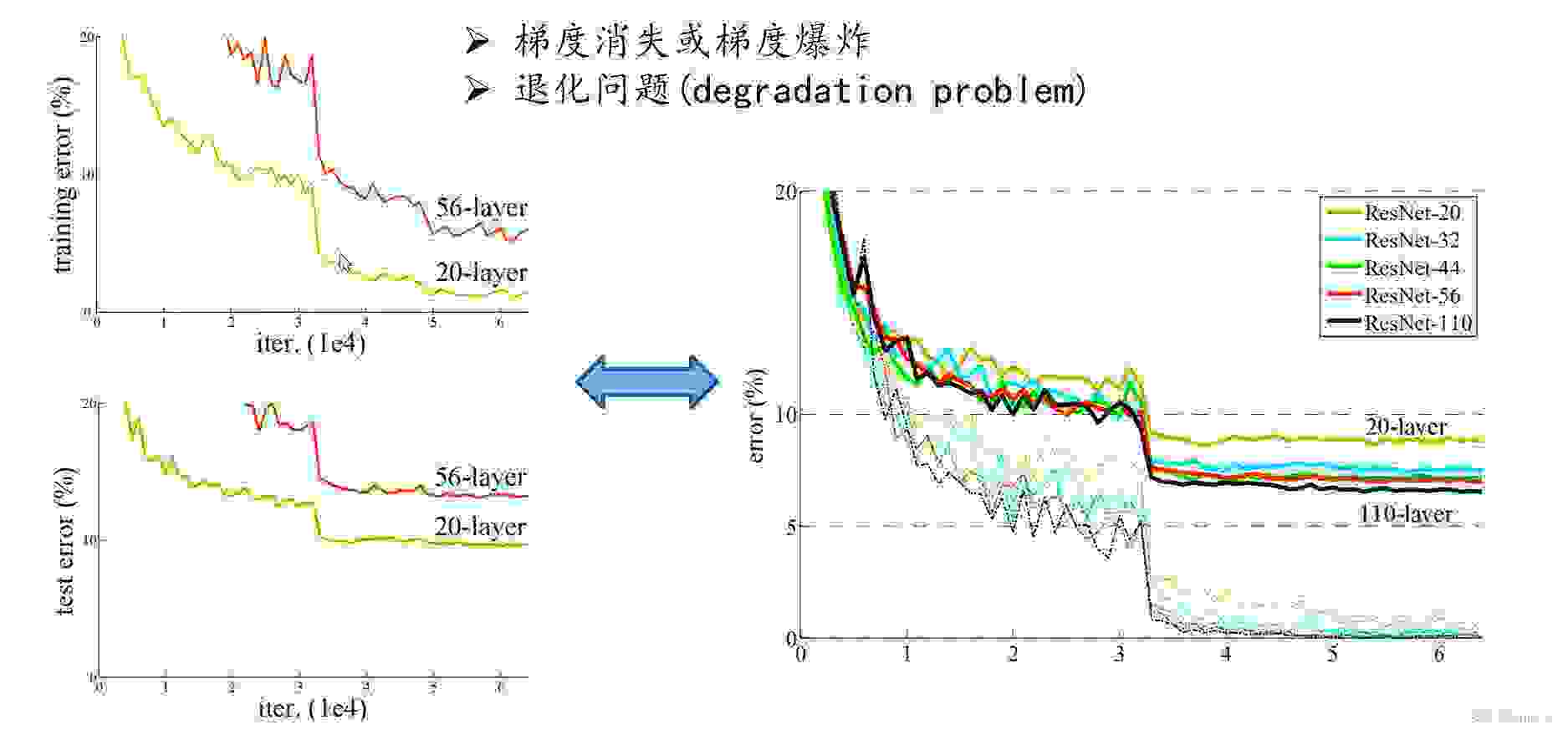
因为层数的加深,反向传播的时候,更新权重w的时候,根据链式法则可能要乘上很多项。
例如传过来的是个0.5,那么网络层数深就会导致 0.5 的n次方,从而导致梯度消失,网络无法学习。同理,梯度爆炸是 > 1的概念。
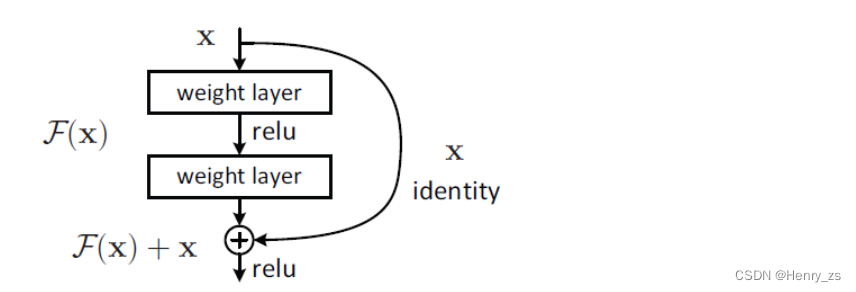
ResNet 提出了一个residual block 残差块的概念,如图。通过右面的一种shortcut 捷径的方式,这样在反向传播的时候,shortcut 就可以将梯度传递过来,从而解决梯度消失或者爆炸的问题。通过这个快捷路径,从而解决了网络加深的问题。
然后,ResNet 使用了 BN (Batch Normalization)代替了Dropout 方法。
根据之前的预处理方式,我们知道,将数据限定到相似的范围内可以帮助网络更好的训练(之前看吴恩达视频的时候,说是特征缩放到类似的区间,这样损失函数就会是一个类似于碗的样子,这样方便梯度下降。否则,可能会是一个碗被挤压的样子,在steep的一边,梯度就会来回横跳)。例如之前的ToTensor,Normalize 等等。
但是之前都是对数据进行特征缩放,然而我们Normalization后的数据经过网络的时候就已经不是之前归一化之类的数据了,所以BN的思想是在每一层后也正规化一下

经过上面的变换,就可以将每一个 batch 的数据变成mean = 0 ,std = 1的分布
这里要注意以下两点:
因为bias 是上下平移,而归一化的时候bias有没有都一样,所以这里的卷积可以不需要bias这里是将每一个batch 所以的图像都做BN变换,具体的设置如下
2. ResNet 网络介绍(ResNet34)
ResNet 因为加入了shortcut 捷径的方式可以加深更多的网络层。这里常见的resnet有如下的几种,这里只介绍ResNet34
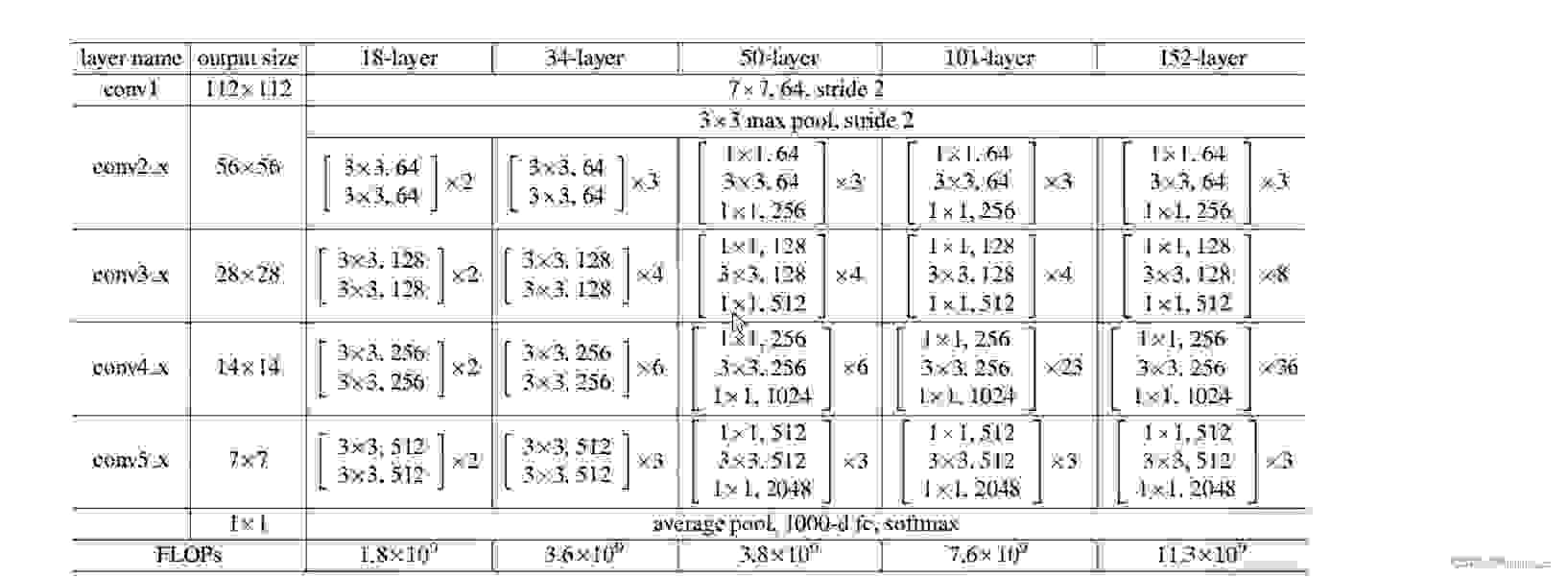
这里50、101、152 每个residual block 第一个都是 1*1 是为了改变特征图的size。观察可以发现,例如conv3_x 、conv4_x、conv5_x 的第一个残差块的第一层右面的shortcut都是虚线
这是因为这里的shortcut需要用1 * 1 的卷积核改变size

并且在conv3_x 、conv4_x、conv5_x 残差块的第一层 3*3 卷积核的stride也发生了变化
因为步长发生了变化,所以这里输出特征图和输入的size以及不是一样了。而右面的shortcut想要和左面的发生叠加,要保证shape一样,所以右面的shortcut上面需要一个1*1 的卷积核来改变size
3. 搭建ResNet 网络
residual block
因为ResNet 网络里面包含很多的residual block
3*3 代表卷积核的size ,64 代表卷积核的个数 = 图像输出的深度
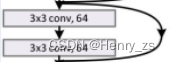
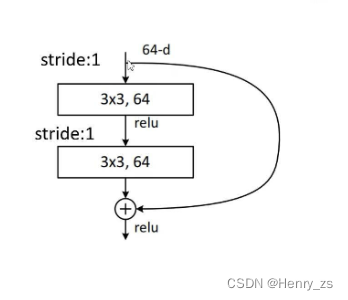
就是网络中上面的结构,所以先将它们封装成一个类

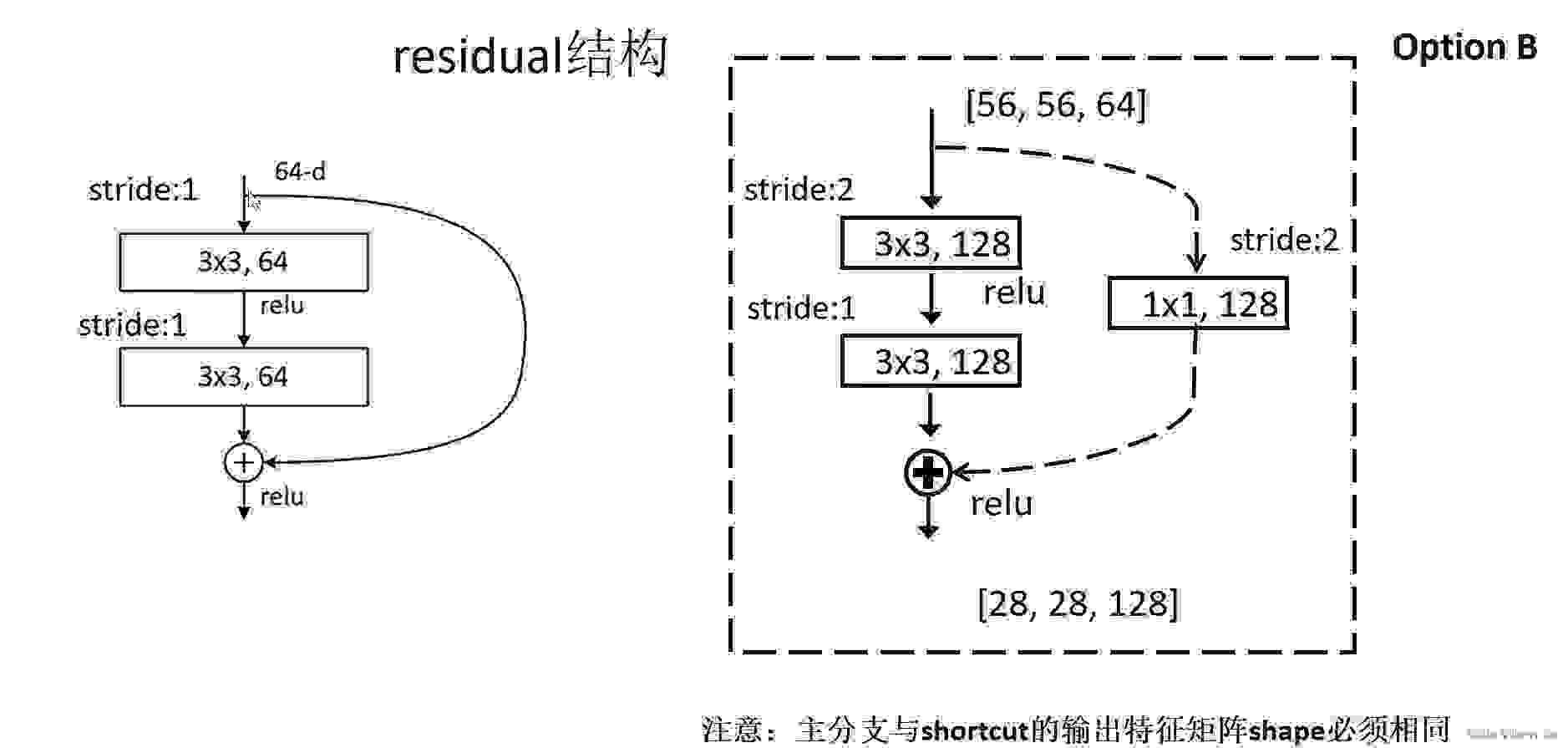
因为residual 结构都是两个3*3 卷积构成的,所以这里先将Conv2d的kernel_size 设置为3
网络结构中没有标stride的都是默认为1,但是这里第一个stride不能直接等于1,因为有的层第一个是2,不是1---------> 所有shortcut是虚线对应的第一个卷积核
然后,经过BN层,ReLU层,残差块的第二个卷积都是3*3 ,且默认stride = 1
这里padding =1 的原因
图像输出的size = (in - 3 + 2*1) / 1 + 1 = in 才能保证输出的size是等于输入的如果stride = 2,那么out = (in - 3 + 2*1) / 2 + 1 =in / 2 + 0.5 = in / 2 (向下取整),这样就会将输出的size变成一半,所以conv3_x 、conv4_x、conv5_x 残差块的第一层和上面的size是不一样的。那么右面的捷径就不能由上面直接流过来,因为size不一样没法相加。所以对应的shortcut是虚线,需要特殊的 1*1 卷积核改变size 并且,由于BN,所以不需要偏置 b接下来定义forward:

残差块的传播分为两类,一类是左边主路的传播,这里定义成left。
右边是快捷路径,这里分为两种情况,一种是上游直接传过来,另一种是图像size被改变需要1*1卷积核做运算。如果是第一种,那么为None,residual = x,如果被改变,就为新的shortcut。最后和左边的out相加,经过ReLU输出就可以了
ResNet
为了方便图像维度的讲解,这里会传入一个batch = 10 的224*224*3 的彩色图像
为了不引起误会,后面描述的依旧是batch而不是10
例如:图像shape:batch*64*56*56 而不是10*64*56*56

pre 传播
首先定义ResNet 前面的传播
![]()

因为这里图像的输入是224*224*3 的彩色图像。
首先经过7*7 ,stride = 2 的卷积核,这里padding = 3的原因是为了保证输出size是输入的一半
再经过3*3 最大池化层,就可以将图像的输出维度控制在:batch*64*56*56
这里的stride、padding 都是为了保证图像的size 满足
layer1
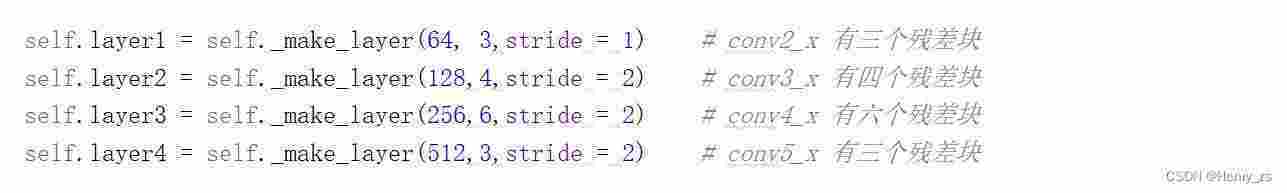
这里_make_layer 第一个参数为残差块里面卷积核的size,3、4、6、3为每层包含残差块的个数
首先看第一层

layer2
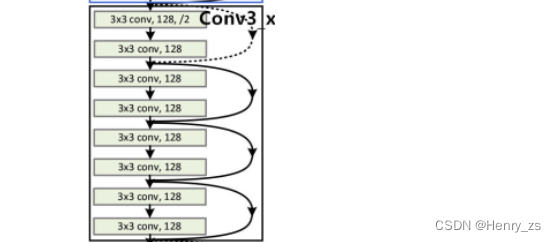
如图,第二层(conv3_x)的第一个残差块已经发生了变化,
这里的变化是指:
stride 由 1变成了2,所以会导致图像的size 变为原来的一半并且图像的深度变成了原来的2倍(因为size减少,少了一部分的特征,所以就拿深度来弥补了)
layer3、4
layer3和layer4都是和layer2一样的
经过layer3的shape是:batch*256*14*14
经过layer4的shape是:batch*512*7*7
全连接层的forward
全连接层:

forward:

ResNet 网络的参数个数
网络的参数个数可由以下得到:
model = ResNet()print("Total number of paramerters in networks is {} ".format(sum(x.numel() for x in model.parameters())))ResNet 参数个数为:
![]()
summary
ResNet 网络基本上都是3*3 的卷积核组成的3*3 卷积核在stride = 1、padding = 1的情况下,不改变图像的size。所以大部分的shortcut捷径可以直接传递和输出相加而conv3_x、conv4_x、conv5_x 由于卷积核的stride =2,导致输出特征图是输入特征图的一半。那么捷径从上游传过来的size就是2倍了,所以这里需要1*1 stride = 2的卷积核去减半shortcut 的size图像的size减半,相当于提取的特征减少。那么为了更好的提取特征,就将输出特征图的个数变为原来的2倍 = 卷积核的个数
4. 训练网络
训练网络的代码不做讲解,具体的可以看这篇文章:
pytorch 搭建 LeNet 网络对 CIFAR-10 图片分类 https://blog.csdn.net/qq_44886601/article/details/127498256
https://blog.csdn.net/qq_44886601/article/details/127498256
主要对GPU训练的部分做讲解:
首先判断设备:

然后将网络扔到设备上:

然后训练的时候,输入也需要传到GPU

最后就是测试的时候

5. 预测图片
这里读取的时候需要注意,因为训练的时候实在GPU上,这里我预测的时候实在cpu上,所以读取网络参数的时候,代码要变成下面这样


预测图像

这里有一个注意点:
因为CIFAR10 图像的size 都是32*32 的,而ResNet网络的输入是224*224。那么预处理时候需要将图像放大,这里就会很模糊。所以在预测的时候,有个smart point就是,将预测的图像也转换成32*32,然后再放大成224*224。这样预测的精度就会上升

处理结果:
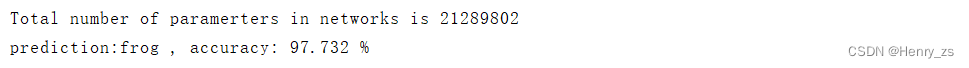
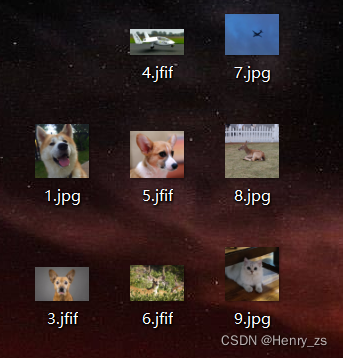
这里网上随便找了几张图片,都能预测对且有较好的准确率:
6. Code
ResNet 网络部分:
import torch.nn as nnfrom torch.nn import functional as Fclass ResidualBlock(nn.Module): # 搭建 残差结构 def __init__(self, inchannel, outchannel, stride=1, shortcut=None): super(ResidualBlock, self).__init__() self.left = nn.Sequential( # stride 不是1,因为有的残差块第一层 的stride = 2;对应残差块的虚线实线 nn.Conv2d(inchannel,outchannel,kernel_size=3,stride =stride,padding = 1,bias = False), nn.BatchNorm2d(outchannel), nn.ReLU(inplace=True), # 第二个卷积核的stride = 1 nn.Conv2d(outchannel,outchannel,kernel_size=3,stride = 1,padding=1,bias=False), # 输入和输出的特征图size一样 nn.BatchNorm2d(outchannel), ) self.right = shortcut # 捷径块 def forward(self,x): out = self.left(x) # 实线,特征图的输入和输出size一样;虚线,shortcut部分要经过1*1卷积核改变特征图size residual = x if self.right is None else self.right(x) out += residual # 加完之后在 ReLU out = F.relu(out) return outclass ResNet(nn.Module): # 搭建ResNet 网络 def __init__(self, num_classes=10): super(ResNet,self).__init__() self.pre = nn.Sequential( # 输入:batch * 3 * 224 * 224 # 输出特征图size = (224 - 7 + 2*3) / 2 + 1 = 112 +0.5 = 112 向下取整 nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False), # 输出 [batch,64,112,112] nn.BatchNorm2d(64), nn.ReLU(inplace=True), # 输出特征图size = (112 - 3 + 2*1) / 2 + 1 = 56 +0.5 = 56 向下取整 nn.MaxPool2d(kernel_size=3,stride=2,padding=1) # 输出 [batch,64,56,56] ) self.layer1 = self._make_layer(64, 3,stride = 1) # conv2_x 有三个残差块 self.layer2 = self._make_layer(128,4,stride = 2) # conv3_x 有四个残差块 self.layer3 = self._make_layer(256,6,stride = 2) # conv4_x 有六个残差块 self.layer4 = self._make_layer(512,3,stride = 2) # conv5_x 有三个残差块 self.fc = nn.Linear(512,num_classes) # 分类层 def _make_layer(self,channel, block_num,stride = 1): # 构建layer,每个层包含3 4 6 3 个残差块block_num shortcut = None layers = [] # 网络层 if stride != 1: # conv3/4/5_x 的第一层 stride 都是2,并且shortcut 需要特殊操作 # 定义shortcut 捷径,都是1*1 的kernel ,需要保证和left最后相加的shape一样 shortcut = nn.Sequential( nn.Conv2d(int(channel / 2),channel,kernel_size=1,stride=stride,bias=False), nn.BatchNorm2d(channel ) ) layers.append(ResidualBlock(int(channel / 2),channel,stride,shortcut)) else: layers.append(ResidualBlock(channel, channel, stride, shortcut)) for i in range(1,block_num): # 残差块后面几层的卷积是一样的 layers.append(ResidualBlock(channel,channel)) return nn.Sequential(*layers) def forward(self,x): x = self.pre(x) # batch*64*56*56 x = self.layer1(x) # batch*64*56*56 x = self.layer2(x) # batch*128*28*28 x = self.layer3(x) # batch*256*14*14 x = self.layer4(x) # batch*512*7*7 x = F.avg_pool2d(x,7) # batch*512*1*1 x = x.view(x.size(0),-1) # x.size(0)是batch ,保持batch,其余的压成1维 x = self.fc(x) # batch*10(分类的个数) return xmodel = ResNet()#import torch#input = torch.randn((10,3,224,224))#model(input)# 计算网络参数个数print("Total number of paramerters in networks is {} ".format(sum(x.numel() for x in model.parameters())))
训练部分:
import torchimport torch.nn as nnimport torch.optim as optimfrom torchvision import transformsfrom model import ResNetimport torchvisiondevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 判断是cpu还是gpu运行print("using {} device.".format(device))data_transform =transforms.Compose([ transforms.Resize((224,224)), # 变换成(224,224)满足ResNet的输入 transforms.ToTensor(), # 变成Tensor,改变通道顺序等等 transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# 训练集 5W 张图片trainset = torchvision.datasets.CIFAR10(root = './data',train = True,download= True,transform=data_transform)trainloader = torch.utils.data.DataLoader(trainset,batch_size = 36,shuffle = True)# 测试集 1W 张图片testset = torchvision.datasets.CIFAR10(root = './data',train = False,download= True,transform=data_transform)testloader = torch.utils.data.DataLoader(testset,batch_size = 36,shuffle = False)# CIFAR10 十个分类类别的labelclasses = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')net = ResNet() # 载入网络net.to(device)loss_function = nn.CrossEntropyLoss() # 定义损失函数optimizer = optim.Adam(net.parameters() , lr=0.0001) # 定义优化器best_acc = 0.0save_path = './resNet34.pth' # 网络权重文件保存路径for epoch in range(5): # train net.train() running_loss = 0.0 for step, data in enumerate(trainloader,start= 0): images, labels = data optimizer.zero_grad() # 梯度清零 out = net(images.to(device)) # 前向传播 loss = loss_function(out, labels.to(device)) # 计算损失 loss.backward() # 反向传播 optimizer.step() # 梯度下降 running_loss += loss.item() # 损失值 # test net.eval() acc = 0.0 total = 0 with torch.no_grad(): for test_data in testset: test_images, test_labels = test_data # 取出测试集的image和label outputs = net(test_images.to(device)) # 前向传播 predict_y = torch.max(outputs, dim=1)[1] # 取出最大的预测值 acc += (predict_y == test_labels.to(device)).sum().item() # 正确 +1 total+= test_labels.size(0) accurate = acc / total # 计算整个test上面的正确率 print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' % (epoch + 1, running_loss / step, accurate)) if accurate > best_acc: best_acc = accurate torch.save(net.state_dict(), save_path)print('Finished Training')预测部分:
import torchvision.transforms as transforms # 预处理import torchfrom PIL import Imagefrom model import ResNetdata_transform =transforms.Compose([ transforms.Resize((32,32)), transforms.Resize((224,224)), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])classes = ('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')net = ResNet()net.load_state_dict(torch.load('./resNet34.pth',map_location = 'cpu')) # 加载网络训练的参数im = Image.open('./2.png')im = data_transform(im) # 图像维度 (C,H,W)im = torch.unsqueeze(im,dim = 0) # 增加维度,第0维增加1 ,维度(1,C,H,W)net.eval() # 打开eval模式with torch.no_grad(): outputs = net(im) # 预测图像 predict = torch.max(outputs,dim = 1)[1].data.numpy() # 取出最大的结果 pro = torch.softmax(outputs, dim=1) rate = pro.max().numpy() * 100 print('prediction:%s , accuracy: %.3f %%'%( classes[int(predict)],rate))
7. 迁移学习

迁移学习其实就是将别人学习过的权重拿来用,将它们作为初始值训练的过程
因为最后的分类往往是根据自己的设置,建议将官方的权重copy,然后加一个分类层就可以了
例如:将原网络的输出再加一个全连接层
