真火!
作为最近一段时间人工智能领域内的顶流之一,AIGC(AI-Generated Content)早已火爆出圈,频登各大互联网平台热搜。
cite: 微软亚洲研究院官方微博
这段时间以来,基于深度学习的内容生成在图像、视频、语音、音乐、文本等生成领域都取得了令人瞩目的成果,也越来越多的身边人在讨论AIGC。但你知道AIGC背后的有哪些技术支持吗?
实际上,最早引爆AIGC话题的是AI作图,它是以Stable Diffusion技术为基础实现的。以前,AI 作图还只是简单的风格迁移、头像生成、磨皮、P图等功能应用,直到Stable Diffusion模型的降临,AI 作图发生了质的变化,人们第一次见识到了生产力AI的力量:画家、设计师不用再绞尽脑汁思考色彩、构图,只要告诉 Stable Diffusion 模型自己想要什么,就能言出法随般地生成高质量图片。
那么我能不能自己实现一个以Stable Diffusion模型为基础的AIGC作画应用呢?
答案是可以的!最近我恰好受邀参与了亚马逊云科技【云上探索实验室】活动,利用Amazon的SageMaker平台搭建了自己的 AIGC 应用,整个过程只用了不到20分钟。
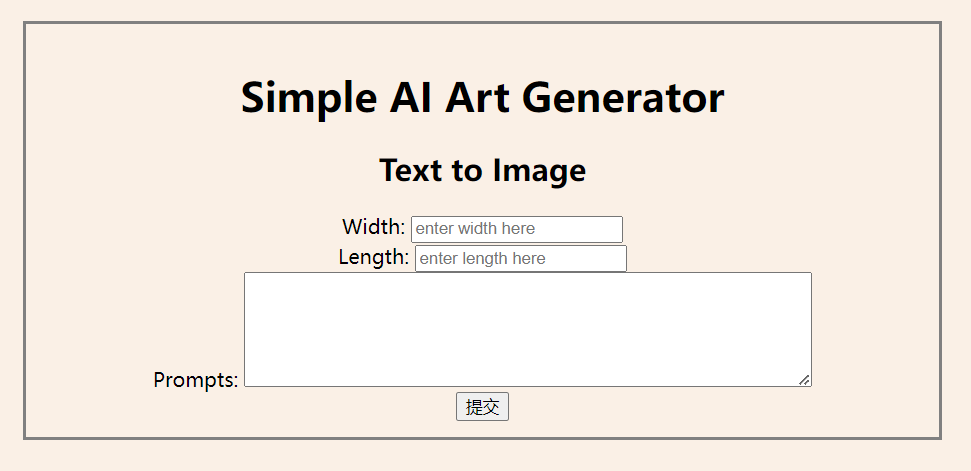
使用 Amazon SageMaker 基于Stable Diffusion模型搭建的AIGC应用
总体而言,在Amazon SageMaker上搭建AIGC应用的体验十分出色,不仅仅是流程清晰,简单易实现。使用者可以直接从Hugging Face上提取预训练的模型,参考Amazon提供的简明教程,使得SageMaker可以很容易地将模型转化为Web应用。
下面是一些图像生成的结果:
感觉还不错,现在我们就来复盘一些怎么利用亚马逊云服务使用Amazon SageMaker在20分钟内搭建一个属于自己的AIGC应用。
我将首先简单说明AIGC是什么以及讲解Stable Diffusion的技术原理。然后介绍Amazon SageMaker是做什么的。之后将基于Amazon SageMaker搭建AIGC应用的整体流程复盘一遍。最后对该应用进行测试和功能评价。
文章目录
1. 什么是Stable Diffusion?1.1. 人工智能自动生成内容:AIGC介绍1.2. Stable Diffusion原理解析 2. 什么是Amazon SageMaker?3. 通过Amazon SageMaker搭建基于Stable Diffusion模型的AIGC应用3.1. 创建Notebook3.2. 利用Hugging Face克隆模型3.3. 了解模型的超参数3.4. 配置和微调Stable Diffusion模型3.5. 部署和使用训练好的模型3.6. 清理资源3.7. 整体流程的视频介绍 4. 对Stable Diffusion模型的评估4.1. CPU和GPU对生成速度的影响4.2. 超参数对模型性能的影响 5. 总结5.1. 基于Amazon SageMaker搭建的AIGC应用的功能评价5.2. 对开发过程有帮助的产品文档汇总
1. 什么是Stable Diffusion?
1.1. 人工智能自动生成内容:AIGC介绍
人工智能自动生成内容(AIGC)是一种基于人工智能(AI)技术的内容创作方法,旨在快速、高效地生成高质量、有创意的文本、图像、音频或视频等多种形式的内容。借助先进的深度学习和自然语言处理技术,AIGC能够理解和学习人类语言、语境、知识和创意,从而根据用户需求生成各种类型的内容。这其中尤其以Stable Diffusion为代表性技术和应用,它用于从自然语言描述生成数字图像。

1.2. Stable Diffusion原理解析
Stable Diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。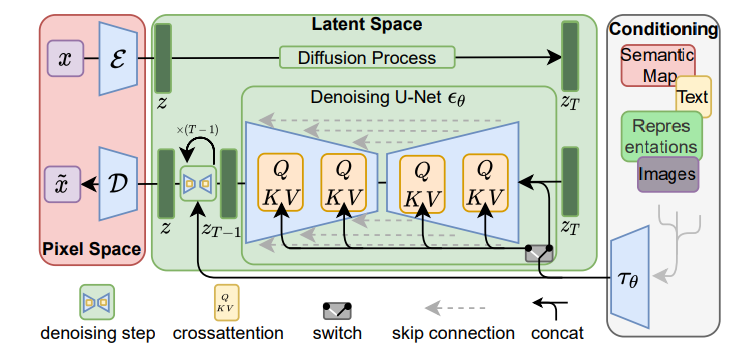
它包含三个模块:感知压缩、扩散模型和条件机制。
(1) 图像感知压缩(Perceptual Image Compression)
图像感知压缩通过VAE自编码模型对原图进行处理,忽略掉原图中的高频细节信息,只保留一些重要、基础的特征。该模块并非必要,但是它的加入能够大幅降低训练和采样的计算成本,大大降低了图文生成任务的实现门槛。
基于感知压缩的扩散模型的训练过程有两个阶段:(1)训练一个自编码器;(2)训练扩散模型。在训练自编码器时,为了避免潜在表示空间出现高度的异化,作者使用了两种正则化方法,一种是KL-reg,另一种是VQ-reg,因此在官方发布的一阶段预训练模型中,会看到KL和VQ两种实现。在Stable Diffusion中主要采用AutoencoderKL这种正则化实现。
具体来说,图像感知压缩模型的训练过程如下:给定图像 x ∈ R H × W × 3 x\in \mathbb{R}^{H\times W\times 3} x∈RH×W×3,我们先利用一个编码器 ε \varepsilon ε来将图像从原图编码到潜在表示空间(即提取图像的特征) z = ε ( x ) z=\varepsilon(x) z=ε(x),其中 z ∈ R h × w × c z\in \mathbb{R}^{h\times w\times c} z∈Rh×w×c。然后,用解码器从潜在表示空间重建图片 x ~ = D ( z ) = D ( ε ( x ) ) \widetilde{x}=\mathcal{D}(z)=\mathcal{D}(\varepsilon(x)) x =D(z)=D(ε(x))。训练的目标是使 x = x ~ x=\widetilde{x} x=x 。
(2) 隐扩散模型(Latent Diffusion Models)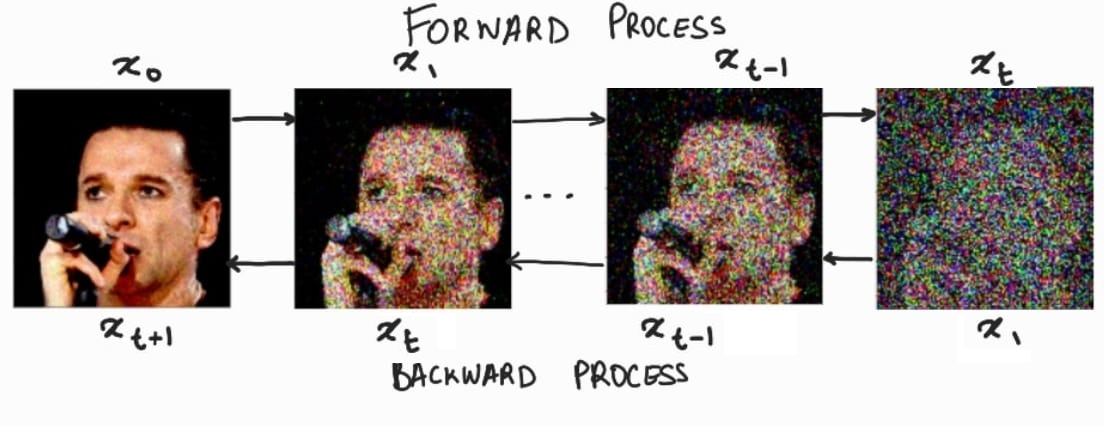
扩散模型(DM)从本质上来说,是一个基于马尔科夫过程的去噪器。其反向去噪过程的目标是根据输入的图像 x t x_t xt去预测一个对应去噪后的图像 x t + 1 x_{t+1} xt+1,即 x t + 1 = ϵ t ( x t , t ) , t = 1 , . . . , T x_{t+1}=\epsilon_t(x_t,t),\ t=1,...,T xt+1=ϵt(xt,t), t=1,...,T。相应的目标函数可以写成如下形式: L D M = E x , ϵ ∼ N ( 0 , 1 ) , t = [ ∣ ∣ ϵ − ϵ θ ( x t , t ) ∣ ∣ 2 2 ] L_{DM}=\mathbb{E}_{x,\epsilon\sim\mathcal{N(0,1),t}}=[||\epsilon-\epsilon_\theta(x_t,t)||_{2}^{2}] LDM=Ex,ϵ∼N(0,1),t=[∣∣ϵ−ϵθ(xt,t)∣∣22]这里默认噪声的分布是高斯分布 N ( 0 , 1 ) \mathcal{N(0,1)} N(0,1),这是因为高斯分布可以应用重参数化技巧简化计算;此处的 x x x指的是原图。
而在潜在扩散模型中(LDM),引入了预训练的感知压缩模型,它包括一个编码器 ε \varepsilon ε 和一个解码器 D \mathcal{D} D。这样在训练时就可以利用编码器得到 z t = ε ( x t ) z_t=\varepsilon(x_t) zt=ε(xt),从而让模型在潜在表示空间中学习,相应的目标函数可以写成如下形式: L L D M = E ε ( x ) , ϵ ∼ N ( 0 , 1 ) , t = [ ∣ ∣ ϵ − ϵ θ ( z t , t ) ∣ ∣ 2 2 ] L_{LDM}=\mathbb{E}_{\varepsilon(x),\epsilon\sim\mathcal{N(0,1),t}}=[||\epsilon-\epsilon_\theta(z_t,t)||_{2}^{2}] LLDM=Eε(x),ϵ∼N(0,1),t=[∣∣ϵ−ϵθ(zt,t)∣∣22]
(3) 条件机制(Conditioning Mechanisms)
条件机制,指的是通过输入某些参数来控制图像的生成结果。这主要是通过拓展得到一个条件时序去噪自编码器(Conditional Denoising Autoencoder,CDA) ϵ θ ( z t , t , y ) \epsilon_\theta(z_t,t,y) ϵθ(zt,t,y)来实现的,这样一来我们就可通过输入参数 y y y 来控制图像生成的过程。
具体来说,论文通过在UNet主干网络上增加cross-attention机制来实现CDA,选用UNet网络是因为实践中Diffusion在UNet网络上效果最好。为了能够从多个不同的模态预处理参数 y y y,论文引入了一个领域专用编码器(Domain Specific Encoder) τ θ \tau_\theta τθ,它将 y y y映射为一个中间表示 τ θ ( y ) ∈ R M × d r \tau_\theta(y)\in\mathbb{R}^{M\times d_r} τθ(y)∈RM×dr,这样我们就可以很方便的将 y y y设置为各种模态的条件(文本、类别等等)。最终模型就可以通过一个cross-attention层映射将控制信息融入到UNet的中间层,cross-attention层的实现如下: A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K ⊤ d ) ⋅ V Attention(Q,K,V)=softmax(\frac{QK^\top}{\sqrt{d}})\cdot V Attention(Q,K,V)=softmax(d QK⊤)⋅V Q = W Q ( i ) ⋅ φ i ( z t ) , K = W K ( i ) ⋅ τ θ ( y ) , V = W V ( i ) ⋅ τ θ ( y ) Q=W_{Q}^{(i)}\cdot \varphi_i(z_t),\quad K=W_{K}^{(i)}\cdot \tau_\theta(y),\quad V=W_{V}^{(i)}\cdot \tau_\theta(y) Q=WQ(i)⋅φi(zt),K=WK(i)⋅τθ(y),V=WV(i)⋅τθ(y)其中 φ i ( z t ) ∈ R N × d ϵ i \varphi_i(z_t)\in \mathbb{R}^{N\times d_{\epsilon}^{i}} φi(zt)∈RN×dϵi 是UNet的一个中间表征; W Q ( i ) W_{Q}^{(i)} WQ(i)、 W K ( i ) W_{K}^{(i)} WK(i)和 W V ( i ) W_{V}^{(i)} WV(i)分别是三个权重矩阵。此时,带有条件机制的隐扩散模型的目标函数可以写成如下形式:
L L D M = E ε ( x ) , y , ϵ ∼ N ( 0 , 1 ) , t = [ ∣ ∣ ϵ − ϵ θ ( z t , t , τ θ ( y ) ) ∣ ∣ 2 2 ] L_{LDM}=\mathbb{E}_{\varepsilon(x),\ y,\ \epsilon\sim\mathcal{N(0,1),\ t}}=[||\epsilon-\epsilon_\theta(z_t,\ t,\ \tau_\theta(y))||_{2}^{2}] LLDM=Eε(x), y, ϵ∼N(0,1), t=[∣∣ϵ−ϵθ(zt, t, τθ(y))∣∣22]
2. 什么是Amazon SageMaker?
Amazon SageMaker 是一种完全托管式的机器学习服务,旨在帮助开发者和数据科学家快速、轻松地构建、训练和部署机器学习模型。Amazon SageMaker 提供了一个集成的开发环境,降低了创建机器学习解决方案的复杂性和成本。Amazon云服务提供了三层架构,即框架和基础架构服务-机器学习服务-人工智能服务相结合的服务架构,其中Amazon SageMaker是中间层服务的支撑平台,为机器学习提供自定义训练和部署服务。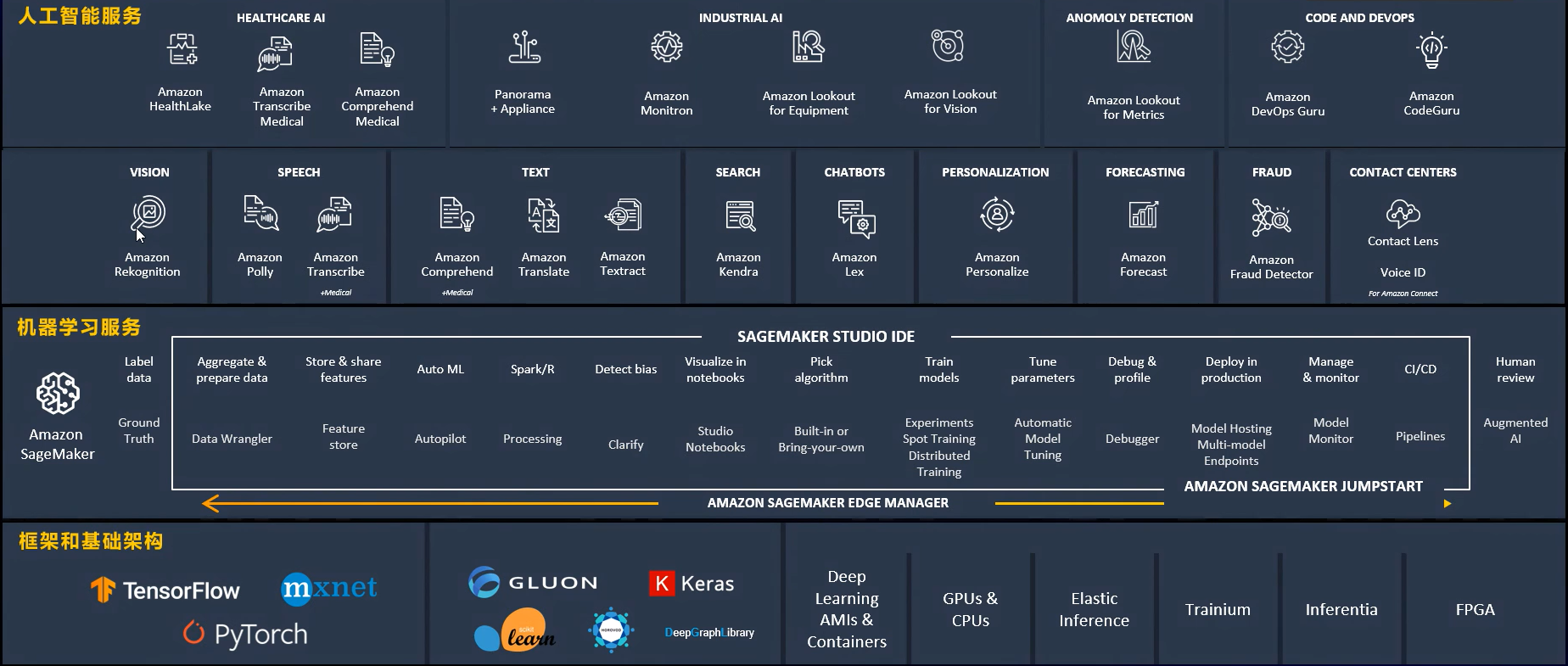
3. 通过Amazon SageMaker搭建基于Stable Diffusion模型的AIGC应用
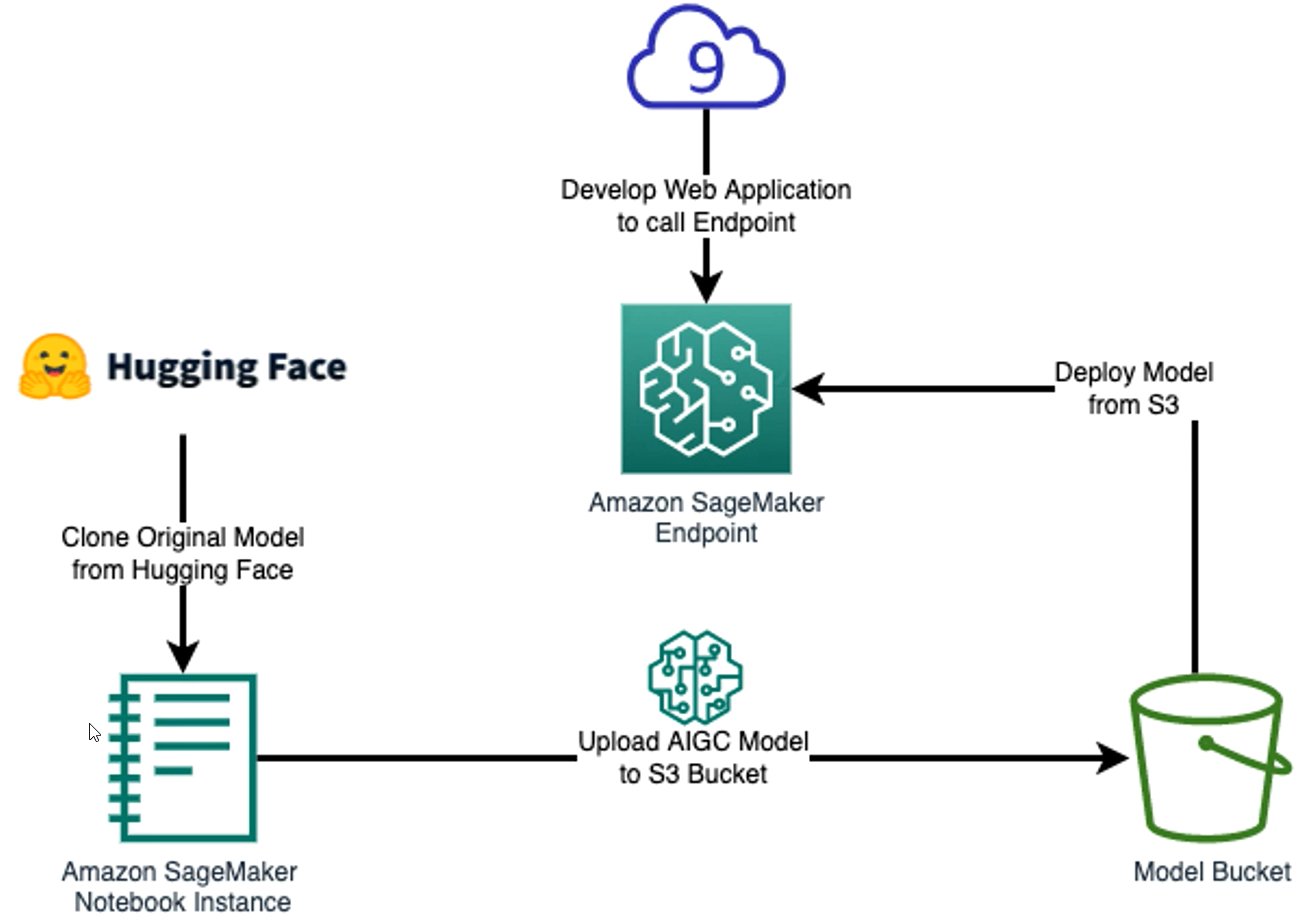
在我们开始部署Stable Diffusion模型之前,先来了解一下整体的实验架构。整体流程分为两大部分,首先是在Amazon SageMaker Notebook中加载并准备AIGC模型,模型已经在机器学习开源社区Hugging Face中准备好了,我们需要把它加载到Notebook中。然后将模型上传并部署该模型到Endpoint上,创建属于自己的AIGC应用。
3.1. 创建Notebook
为了部署和使用我们的AIGC模型,我们采用Amazon SageMaker Notebook来编写代码和训练模型。
首先我们进入到自己的 控制台主页(AWS Management Console),在最上方的搜索栏中搜索“Amazon SageMaker”,点击进入即可。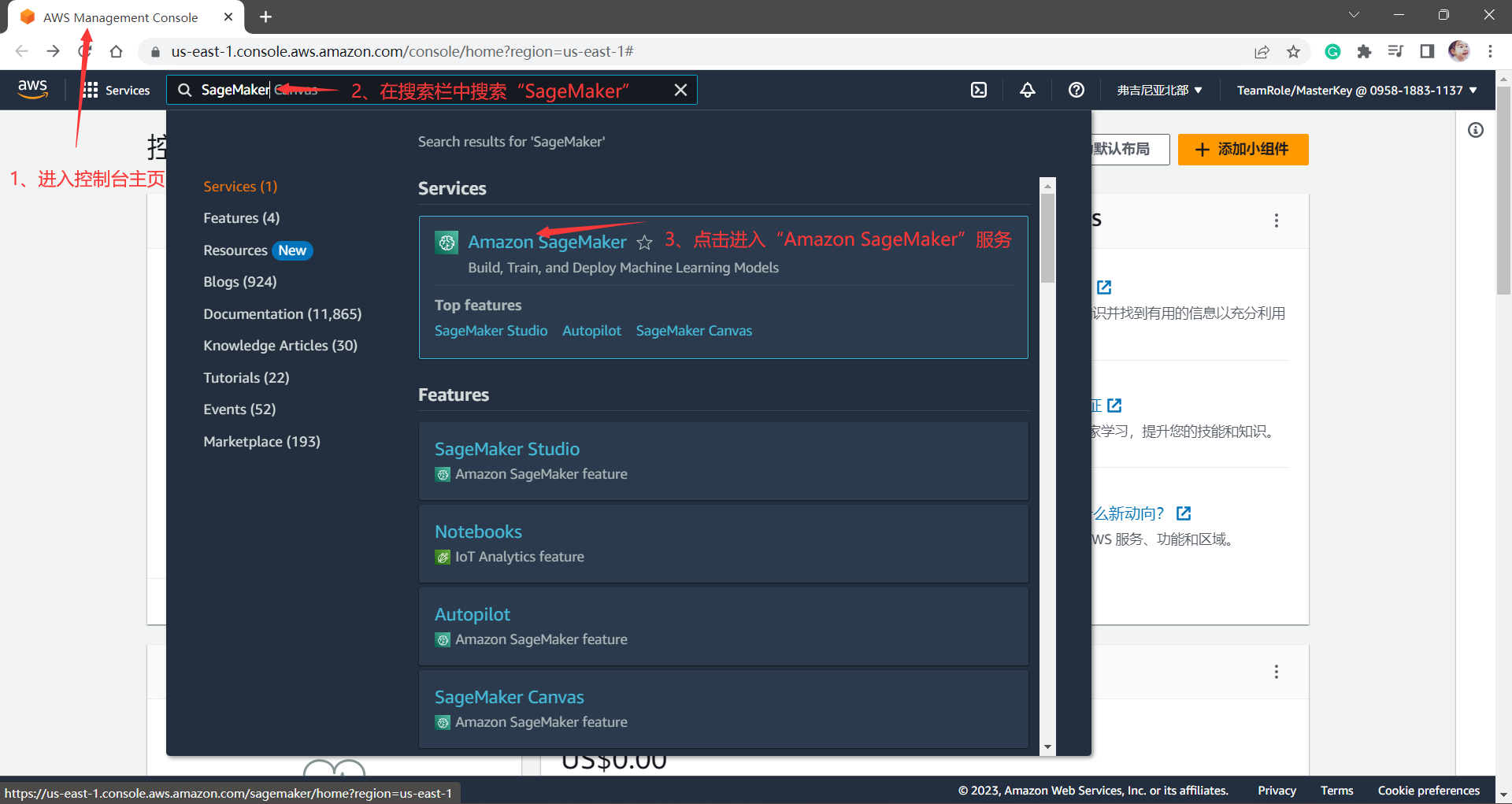
然后,我们在左侧的目录中选择“笔记本”-“笔记本实例”,进入到笔记本实例控制页。在这里,我们点击“创建笔记本实例”来创建一个新的实例。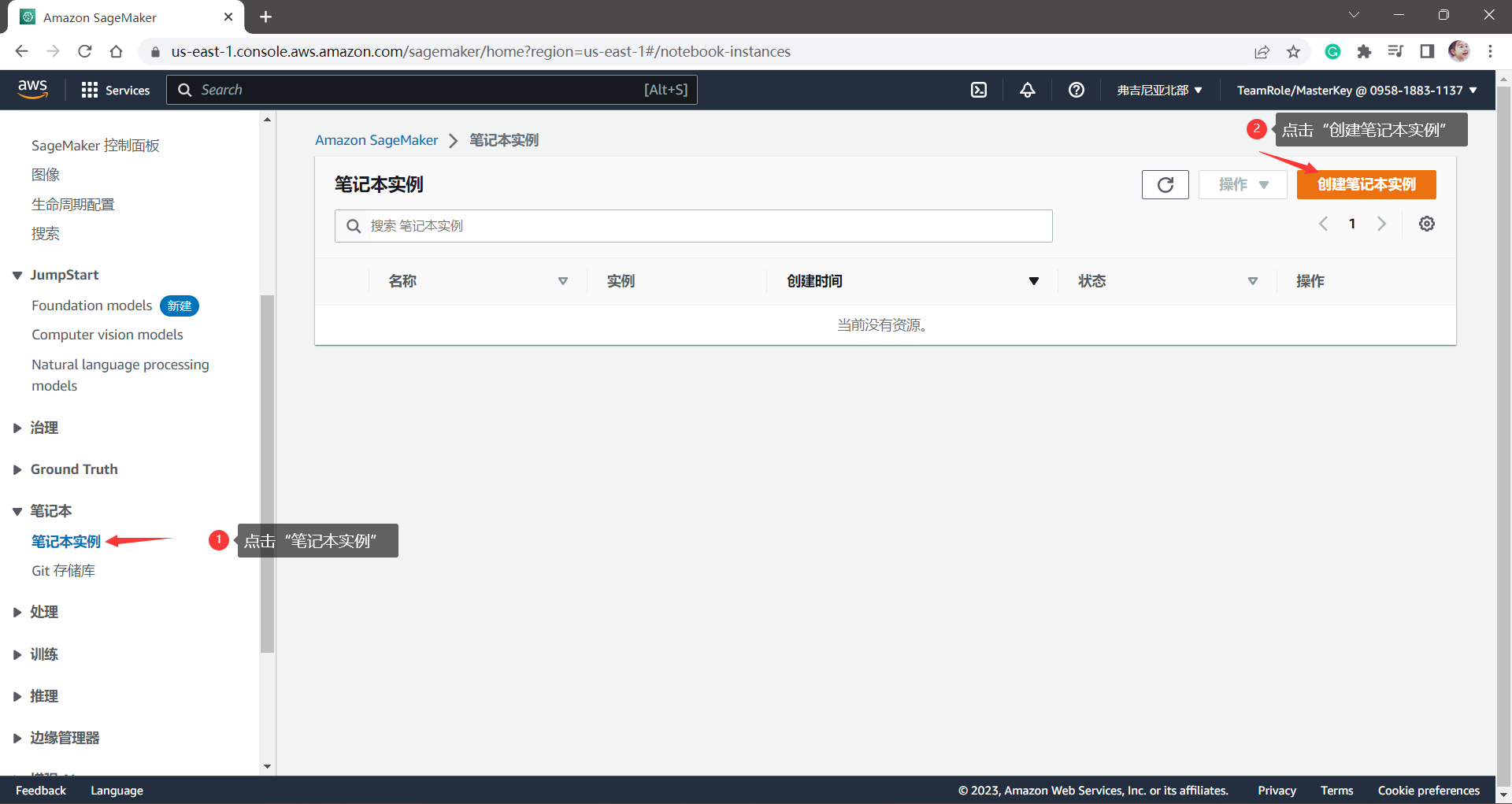
之后在创建笔记本实例详情页中配置笔记本实例的基本信息。主要配置以下4部分信息:(1)笔记本实例名称;(2)笔记本实例类型;(3)平台标识符(操作系统及Jupyter Notebook版本);(4)实例存储大小(卷大小)。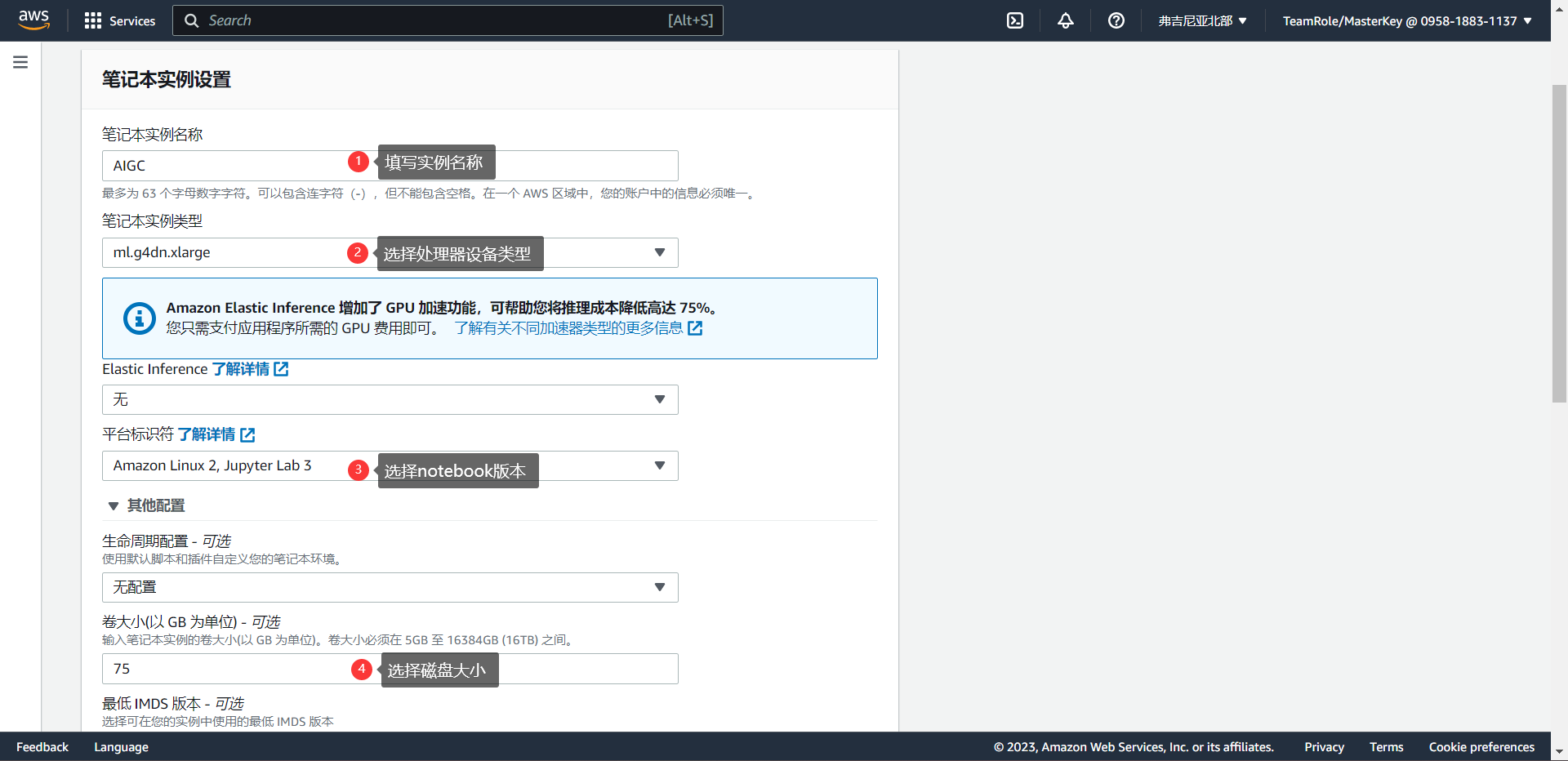
如果遇到无“IAM 角色”的问题,那就采用默认配置创建一个新角色即可。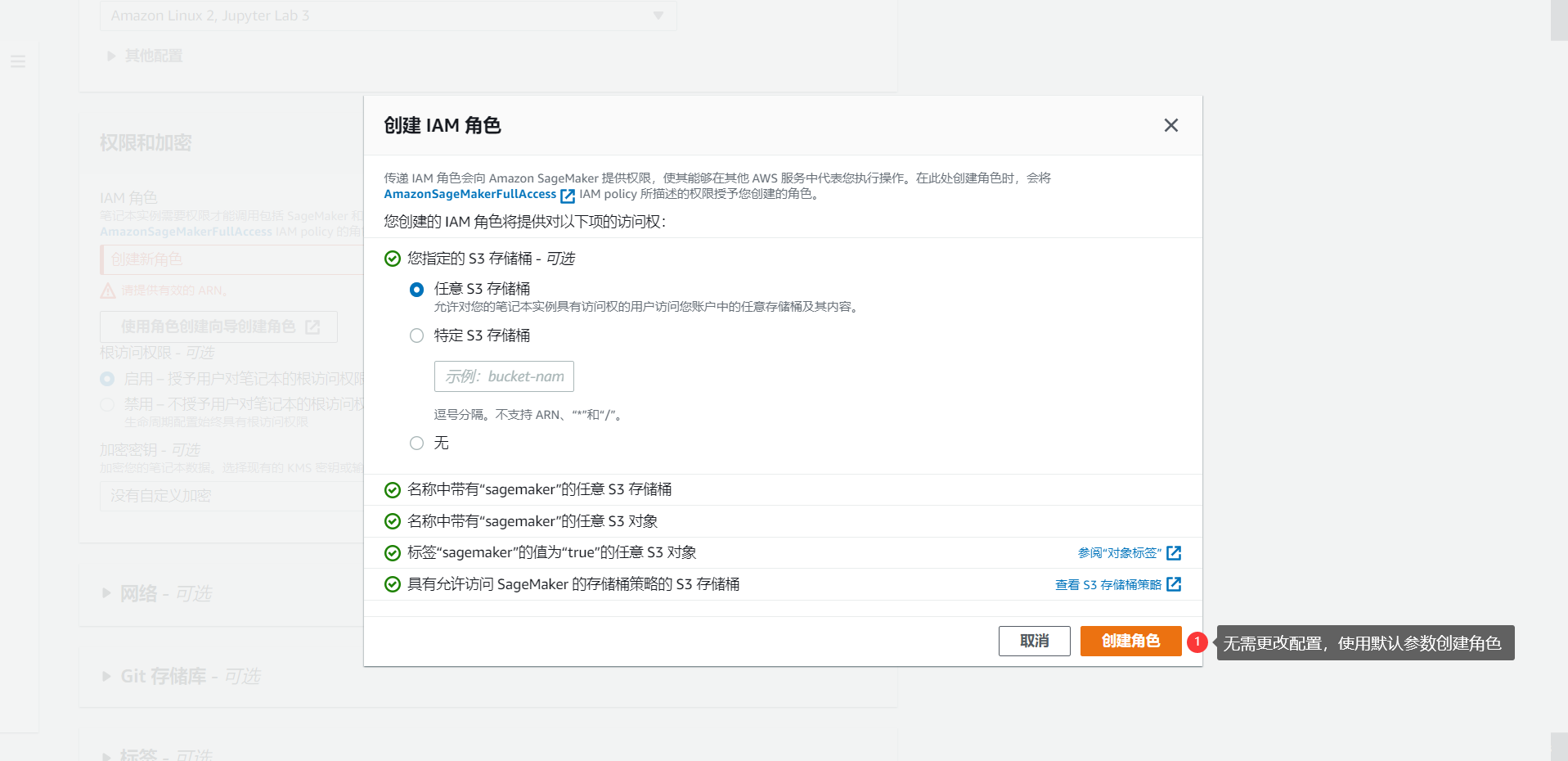
以上步骤完成之后点击“创建笔记本实例”就可以了,点击之后,需要等待一段时间(约5分钟)才能完成创建。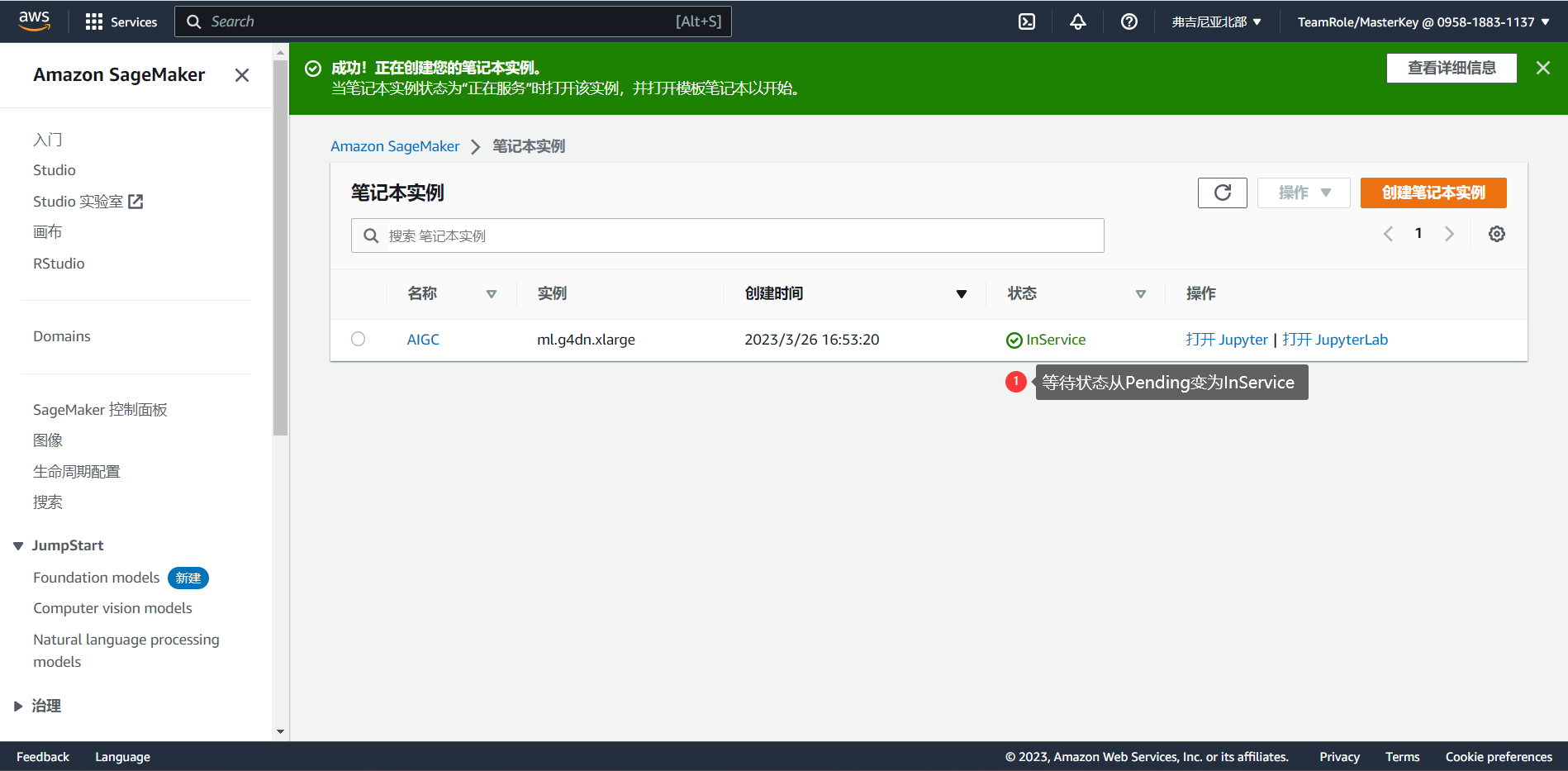
这里已经为大家准备好了相关的代码,打开链接(https://static.us-east-1.prod.workshops.aws/public/73ea3a9f-37c8-4d01-ae4e-07cf6313adac/static/code/notebook-stable-diffusion-ssh-inference.ipynb),下载保存Notebook代码文件。
下载好代码(ipynb)文件之后,我们在笔记本实例页面点击“打开Jupyter”,然后上传代码。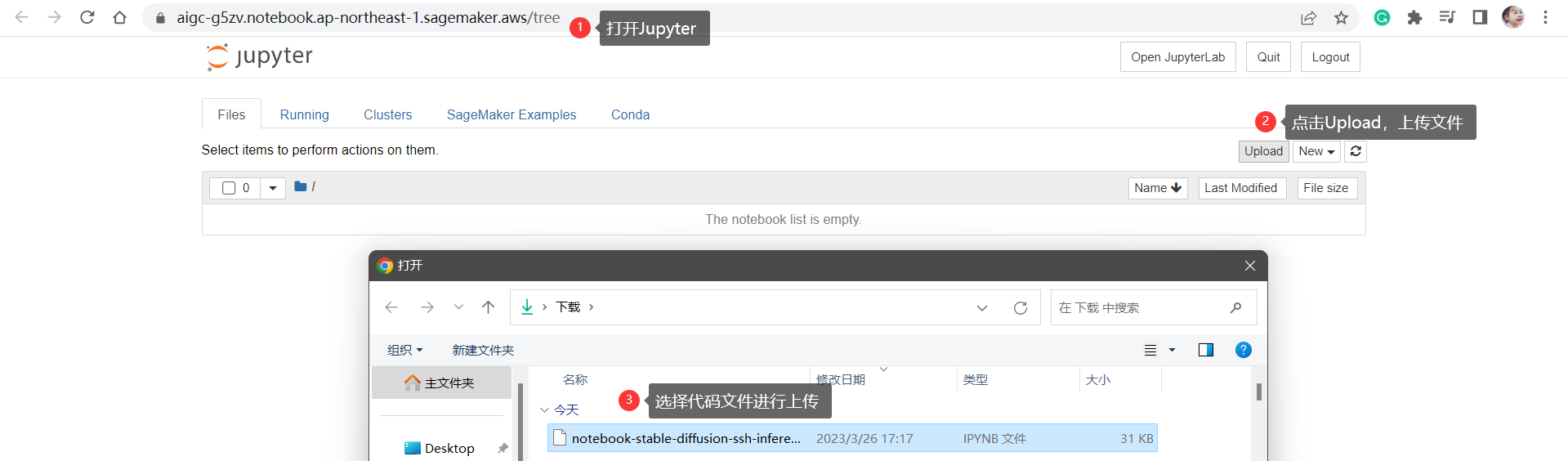
选择好文件后,点击蓝色的“Upload”按键,即可完成上传。然后我们打开刚刚上传的notebook,可以看到该文件就是一个完整的Stable Diffusion训练代码,这里我们的run kernel选择conda_pytorch_38或conda_pytorch_39,因为机器学习代码是用pytorch写的。
在这里,我们首先使用Shift+Enter运行1.1安装及环境配置工作中的两段代码,为接下来的实验配置好环境。
以下是一些使用Jupyter Notebook的快捷键汇总。
3.2. 利用Hugging Face克隆模型
Hugging Face是一个人工智能/机器学习的开源社区和平台,在Hugging Face上有Stable Diffusion V1.4和Stable Diffusion V2.1两个版本,无论使用V1.4版本还是V2.1版本,我们都要把模型下载下来。
# Clone the Stable Diffusion model from HuggingFace#### Stable Diffusion V1SD_SPACE="CompVis/"SD_MODEL = "stable-diffusion-v1-4"#### Stable Diffusion V2# SD_SPACE="stabilityai/"# SD_MODEL = "stable-diffusion-2-1"之后克隆模型仓库,等待模型下载完毕。
3.3. 了解模型的超参数
在正式训练模型之前,我们来了解一下模型的超参数设置以及它们的含义。
prompt (str or List[str]):引导图像生成的文本提示或文本列表height (int, optional, 默认为 V1模型可支持到512像素,V2模型可支持到768像素):
生成图像的高度(以像素为单位)width (int, optional, 默认为 V1模型可支持到512像素,V2模型可支持到768像素):
生成图像的宽度(以像素为单位)num_inference_steps (int, optional, defaults to 50):
降噪步数。更多的去噪步骤通常会以较慢的推理为代价获得更高质量的图像guidance_scale (float, optional, defaults to 7.5):
较高的指导比例会导致图像与提示密切相关,但会牺牲图像质量。 如果指定,它必须是一个浮点数。 guidance_scale<=1 被忽略。negative_prompt (str or List[str], optional):
不引导图像生成的文本或文本列表。不使用时忽略,必须与prompt类型一致(不应小于等于1.0)num_images_per_prompt (int, optional, defaults to 1):
每个提示生成的图像数量
在这其中,height、width和num_images_per_prompt会直接影响到GPU的内存开销。height、width和num_images_per_prompt越大,所需要的GPU开销就越大。
以上是主要要考虑的超参数,如果想进行更精细的调整,可以参考 pipeline_stable_diffusion.py,539-593行。
3.4. 配置和微调Stable Diffusion模型
在确定好超参数之后,我们就可以配置并使用刚才微调的模型了。首先使用stableDiffusionPipeline加载stable-diffusion-v1-4(或stable-diffusion-v2-1),即SD_MODEL=stable-diffusion-v1-4
接下来,通过输入prompts和调整超参数,我们就可以用Stable Diffusion模型来生成图像了,例如:
# move Model to the GPUtorch.cuda.empty_cache()pipe = pipe.to("cuda")# V1 Max-H:512,Max-W:512# V2 Max-H:768,Max-W:768print(datetime.datetime.now())# 提示词,一句话或者多句话prompts =[ "An eagle flying in the water", "A pig kite flying in the sky",]generated_images = pipe( prompt=prompts, height=512, # 生成图像的高度 width=512, # 生成图像的宽度 num_images_per_prompt=1 # 每个提示词生成多少个图像).images # image here is in [PIL format](https://pillow.readthedocs.io/en/stable/)print(f"Prompts: {prompts}\n")print(datetime.datetime.now())for image in generated_images: display(image)在这里,我们设置了两个提示词:
An eagle flying under the water一只在水里翱翔的老鹰A pig kite flying in the sky
一只在天上飞翔的风筝猪
生成的结果如下:
3.5. 部署和使用训练好的模型
在确定模型可以正常使用之后,我们可以将模型部署到终端节点(Endpoint),这个过程分为两个阶段:
创建Stable Diffusion模型的推理节点将模型部署到Cloud 9中作为Web应用Amazon SageMaker 可以让我们将模型构建成自定义的推理脚本,该推理脚本可以直接接收json格式的输入,然后返回生成的图像数据。
# 提交json数据,接收生成的图像数据response = predictor[SD_MODEL].predict(data={ "prompt": [ "An eagle flying in the water", # "A pig kite flying in the sky", ], "height" : 512, "width" : 512, "num_images_per_prompt":1 })# 解码生成的图像decoded_images = [decode_base64_image(image) for image in response["generated_images"]]#visualize generationfor image in decoded_images: display(image)我们构建的推理脚本将模型的功能解耦成两个函数,实际上就是读取模型以及读取超参数和prompts:
def model_fn(model_dir): # Load stable diffusion and move it to the GPU pipe = StableDiffusionPipeline.from_pretrained(model_dir, torch_dtype=torch.float16) pipe = pipe.to("cuda") return pipedef predict_fn(data, pipe): # get prompt & parameters prompt = data.pop("prompt", "") # set valid HP for stable diffusion height = data.pop("height", 512) width = data.pop("width", 512) num_inference_steps = data.pop("num_inference_steps", 50) guidance_scale = data.pop("guidance_scale", 7.5) num_images_per_prompt = data.pop("num_images_per_prompt", 1) # run generation with parameters generated_images = pipe( prompt=prompt, height=height, width=width, num_inference_steps=num_inference_steps, guidance_scale=guidance_scale, num_images_per_prompt=num_images_per_prompt, )["images"] # create response encoded_images = [] for image in generated_images: buffered = BytesIO() image.save(buffered, format="JPEG") encoded_images.append(base64.b64encode(buffered.getvalue()).decode()) # create response return {"generated_images": encoded_images}在这之后,我们要使用Hugging Face将stable-diffusion-v1-4模型上传到 Amazon S3桶。
from sagemaker.s3 import S3Uploadersd_model_uri=S3Uploader.upload(local_path=f"{SD_MODEL}.tar.gz", desired_s3_uri=f"s3://{sess.default_bucket()}/stable-diffusion")#init variableshuggingface_model = {}predictor = {}from sagemaker.huggingface.model import HuggingFaceModel# create Hugging Face Model Classhuggingface_model[SD_MODEL] = HuggingFaceModel( model_data=sd_model_uri, # path to your model and script role=role, # iam role with permissions to create an Endpoint transformers_version="4.17", # transformers version used pytorch_version="1.10", # pytorch version used py_version='py38', # python version used)# deploy the endpoint endpoint, Estimated time to spend 5min(V1), 8min(V2)predictor[SD_MODEL] = huggingface_model[SD_MODEL].deploy( initial_instance_count=1, instance_type="ml.g4dn.xlarge", endpoint_name=f"{SD_MODEL}-endpoint")到这里为止,我们就已经创建好了Stable Diffusion模型的推理节点。然后我们在 AWS Cloud9 中为模型创建Web应用。
回到控制台主页,在搜索栏搜索Cloud9,并点击进入服务。
然后点击“Create environment”创建 AWS Cloud9 环境,我们只需要设置环境实例的名称即可,其余保持默认。有几个可调整选项:
lnstance type是实例的硬件类型,其中t2.micro是免费的类型。Platform是操作系统类型。Timeout是实例休眠时间,如果长时间没有访问,它会自动通知服务,防止持续计费。 设置好自己的实例属性之后,点击Create即可创建Cloud9环境实例。等待实例创建成功,即可点击“Open”打开实例IDE。
之后我们在控制台中输入以下命令:
cd ~/environmentwget https://static.us-east-1.prod.workshops.aws/public/73ea3a9f-37c8-4d01-ae4e-07cf6313adac/static/code/SampleWebApp.zipunzip SampleWebApp.zip这是一套简单的Web程序框架,包含:
后端代码 app.py:接收前端请求并调用 SageMaker Endpoint 将文字生成图片。两个前端html文件 image.html 和 index.html。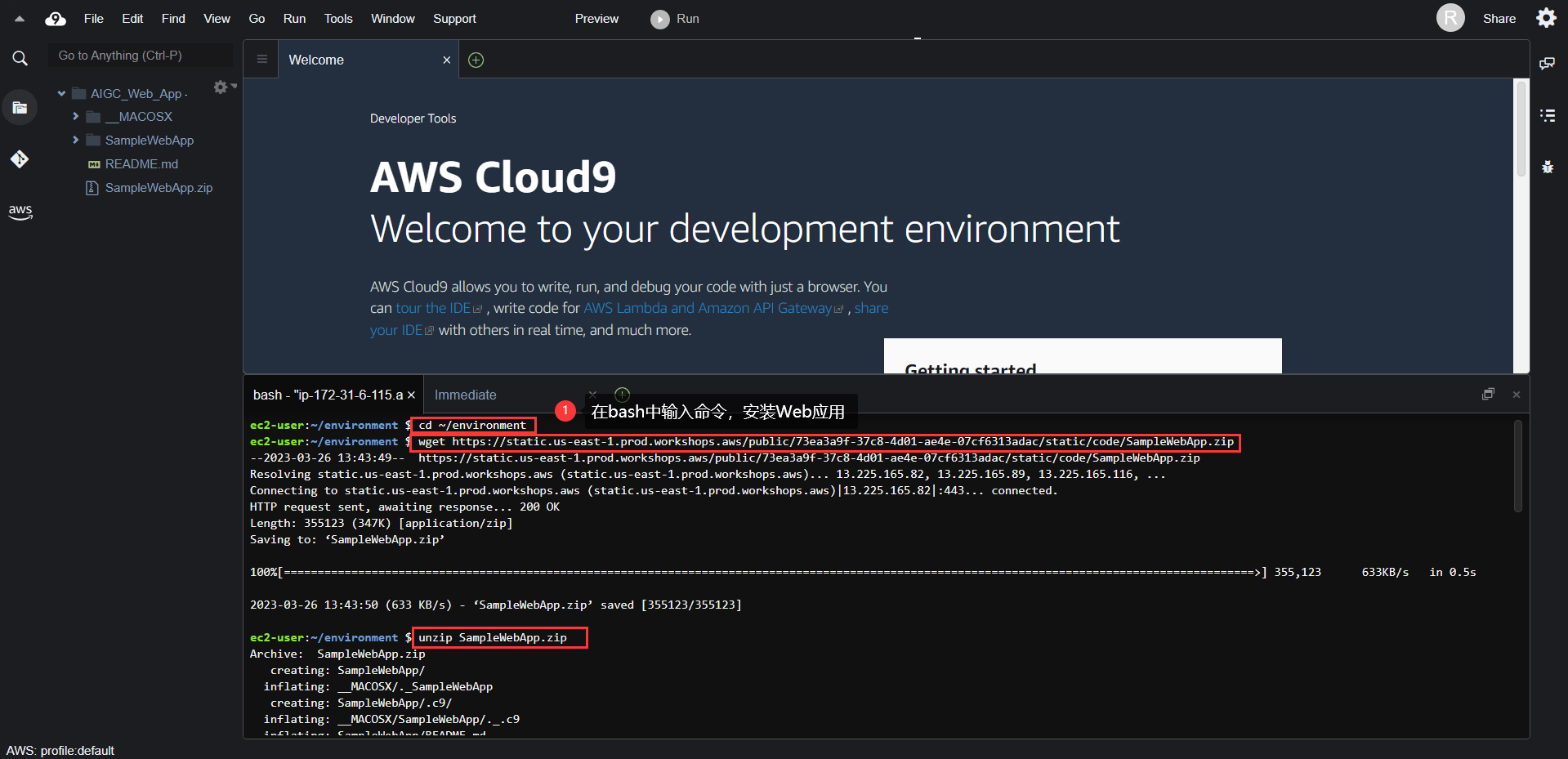
然后,在控制台中输入命令安装 Flask和boto3。
pip3 install Flaskpip3 install boto3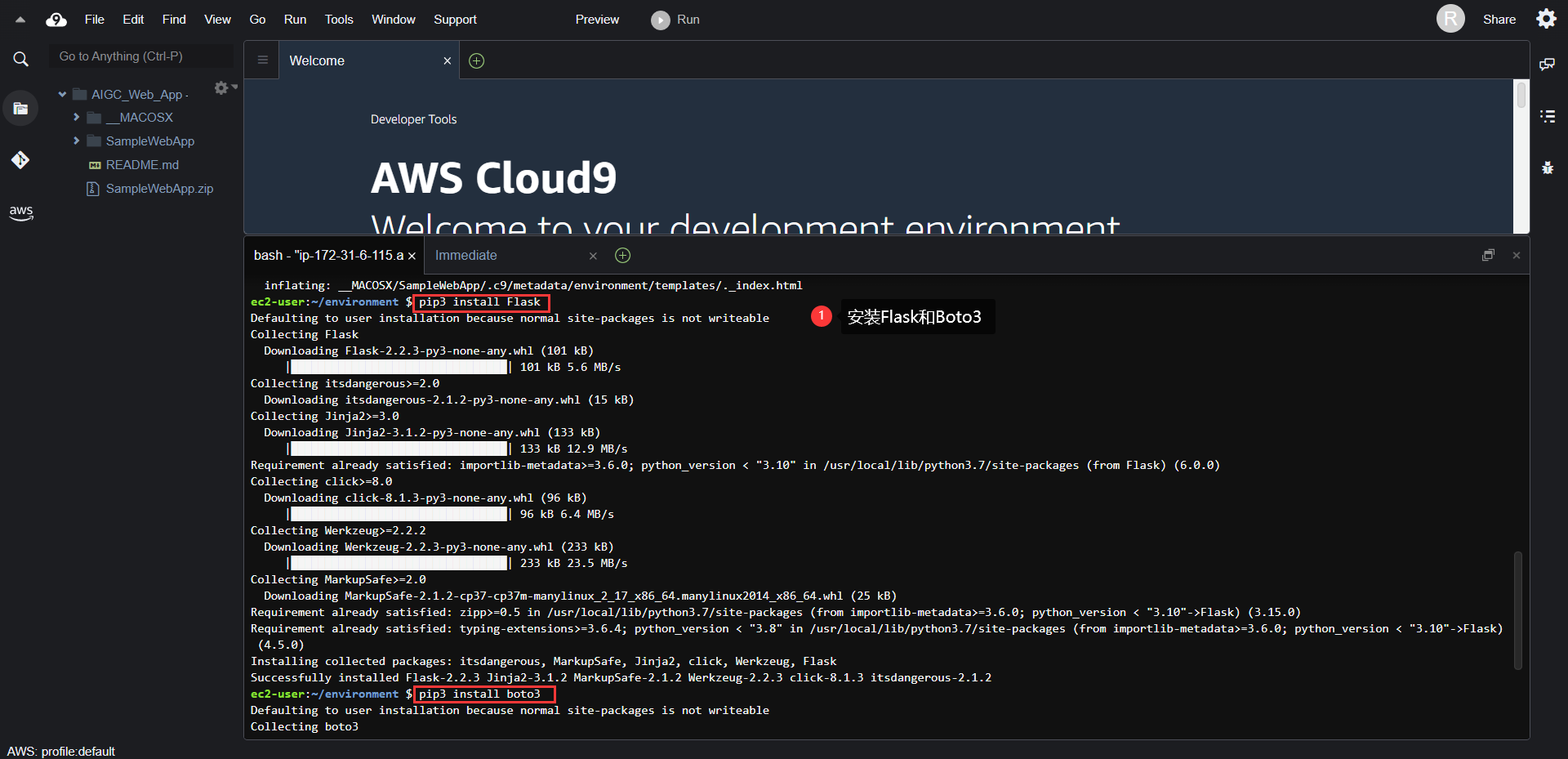
之后在左侧项目文件夹中打开 app.py,运行它。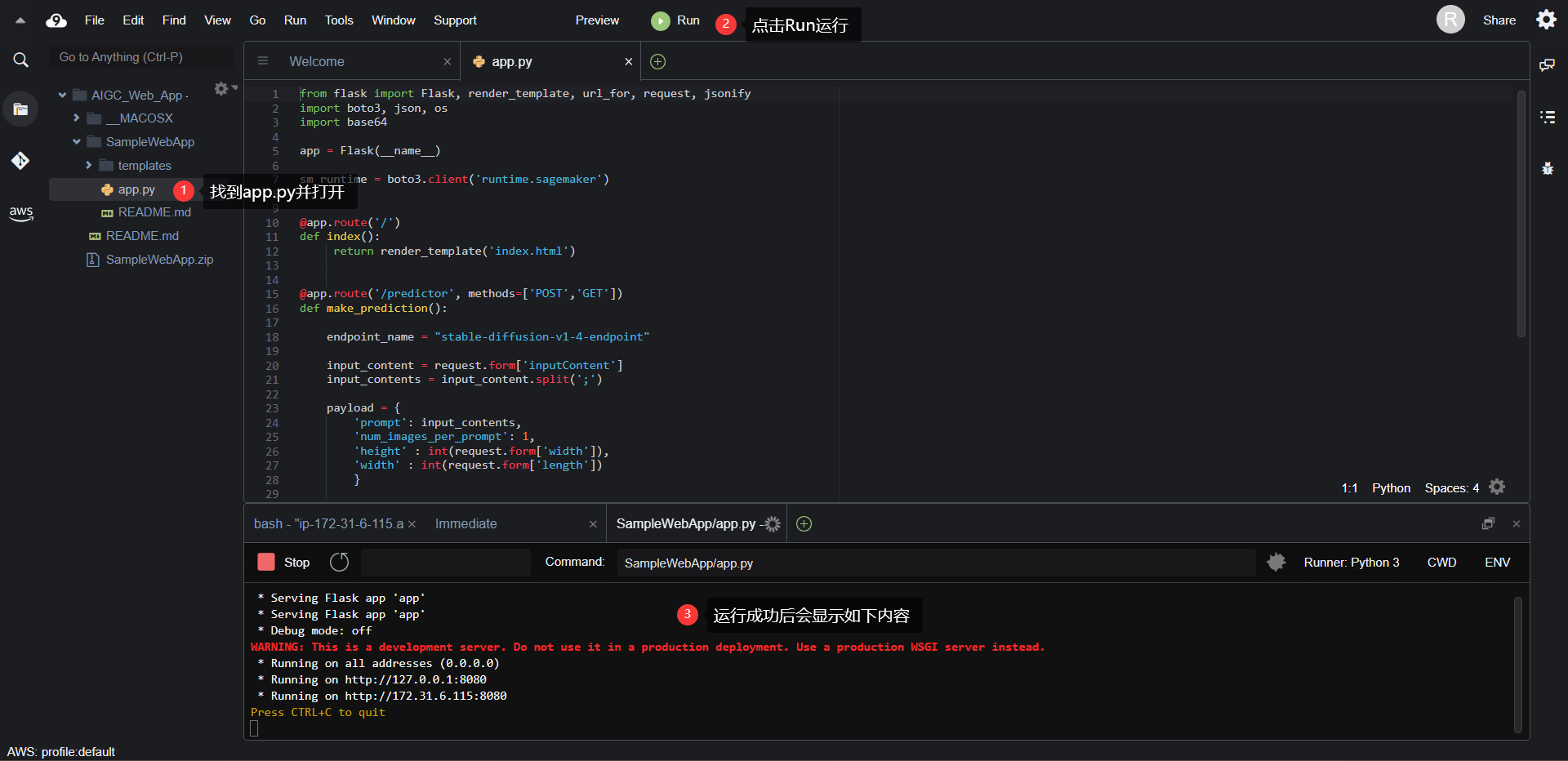
然后我们点击 Run 按钮左侧的 “Preview”,选择“Preview Running Application”,就可以预览页面啦。在这个页面上输入prompt和width、length,会返回对应生成的图像。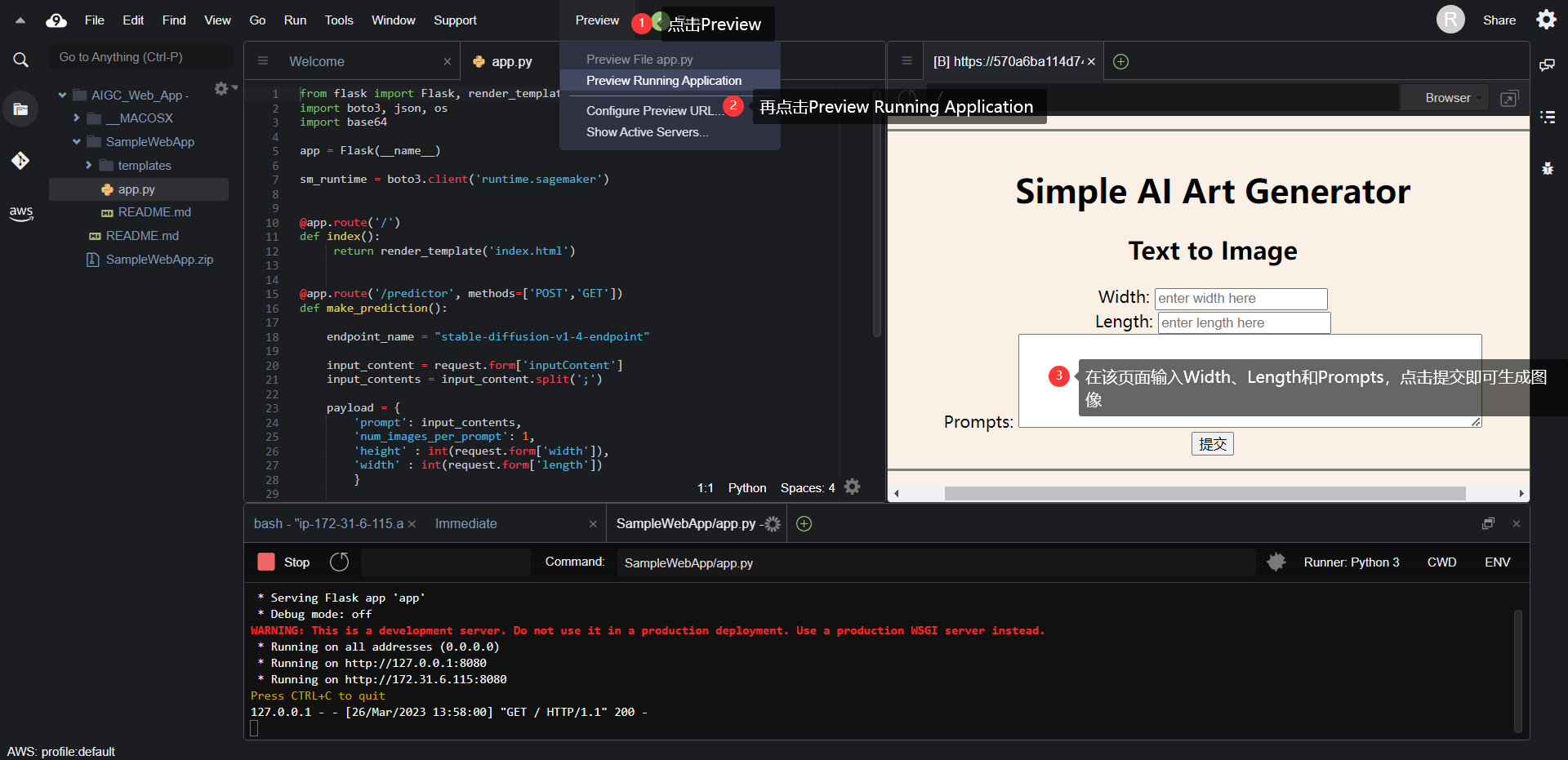
3.6. 清理资源
完成实验的运行之后,一定要停止并删除自己创建的Notebook和Cloud9的所有资源,以确保不会继续计费。当然这一点在 Notebook的代码 中也提到了,这里再次强调。
3.7. 整体流程的视频介绍
(1)创建Amazon SageMaker Notebook来编写代码和使用模型。
【亚马逊云科技】如何使用SageMaker Notebook搭建自己的Stable Diffusion模型?
(2)在 AWS Cloud9 中为模型创建Web应用
【亚马逊云科技】教你用Cloud9搭建自己的Stable Diffusion服务
4. 对Stable Diffusion模型的评估
由于本次实验不涉及模型的训练,因此超参数或者训练步数对模型性能、过拟合效应的影响无法被反映出来。为了评估模型的性能,我在这里设计了两个实验探究模型在不同情况下的效率区别。
4.1. CPU和GPU对生成速度的影响
我们选用ml.t3.medium(2CPU+4G内存)和ml.g4dn.xlarge(4CPU+16G内存+16G显存)来探究不同设备情况下生成图像速度的区别。对于每一种stable diffusion模型,我将height和width设为最大,num_images_per_prompt设为1。
| 设备 | stable-diffusion-v1-4 | stable-diffusion-v2-1 |
|---|---|---|
| ml.t3.medium | 9s | 11s |
| ml.g4dn.xlarge | 8s | 9s |
可以观察到,stable-diffusion-v2-1的图像生成速度相对于v1-4略慢,GPU的图像生成速度相对于CPU要快。
4.2. 超参数对模型性能的影响
在上文中我们已经提到,height、width和num_images_per_prompt会直接影响到GPU的内存开销。我们在这里选用ml.g4dn.xlarge设备来探究超参数变化对stable-diffusion-v1-4模型的图像生成速度会带来怎么样的影响。
| 超参数 | 配置1 | 配置2 | 配置3 | 配置4 |
|---|---|---|---|---|
| height&width | 512 | 256 | 128 | 64 |
| num_images_per_prompt | 1 | 1 | 1 | 1 |
| 用时 | 8s | 5s | 4s | 4s |
可以观察到,随着生成图像的height&width减小,生成图像的用时也在减少,但减少的幅度并非是线性的,可以预见的是,当图像小于128时,继续减小对图像的生成速度不会再有显著的影响。
| 超参数 | 配置1 | 配置2 | 配置3 | 配置4 |
|---|---|---|---|---|
| height&width | 512 | 512 | 512 | 512 |
| num_images_per_prompt | 4 | 3 | 2 | 1 |
| 用时 | 24s | 20s | 17s | 8s |
可以观察到,随着一次性生成图像数量的增加,生成所需要的时间也会同步增加,两者之间近似成正比关系。
5. 总结
5.1. 基于Amazon SageMaker搭建的AIGC应用的功能评价
我认为,可以从以下五个方面对Amazon SageMaker的功能进行评价:
模型训练功能在Amazon SageMaker Notebook中,我们可以直接从Hugging Face下载所需要的预训练模型。在本次体验中,我们可以很容易地获取Stable Diffusion V1.4和V2.1两个版本,并且在使用的过程中,可以很方便地参考文档来理解各个超参数的含义和作用,快速实现模型的微调。模型部署功能
训练好的模型不仅可以很方便地进行使用和微调,Amazon SageMaker也提供了多种部署教程,例如将模型打包成推理节点,以及使用Cloud9服务搭建带有UI的Web应用。速度与易用性
Amazon SageMaker提供了多种实例类型供用户选择,对于不同的实例设备,可能会有使用体验上的差别,但毫无疑问的是,实例的初始化和使用是十分快捷方便的。生态丰富度
虽然本次体验只带大家完成了AIGC应用的搭建,但Amazon SageMaker还包括了一系列机器学习和人工智能应用以及相对应的IDE,例如还可以基于Amazon SageMaker构建细粒度情感分析应用、使用Amazon SageMaker构建机器学习应用等等。可视化能力
Amazon SageMaker提供了Jupyter Notebook的全部功能,也就具备了实时对表格、图像输出进行可视化的能力。此外在Cloud9服务中,也可以对部署的Web应用进行快速预览。对于JumpStart的训练过程,Amazon SageMaker也提供了监控终端节点的功能。
然而,Stable Diffusion模型本身并不完美,尽管在生成图像方面具有令人印象深刻的性能,但它也存在一些明显的局限性,包括但不限于:
分辨率不够,尽管v2.1版本相对于v1.4版本在分辨率上有了巨大的提升,但仍然不够,想要生成高质量的图片,需要很长的时间和足够的调试耐心。仅适用英文,如果能加入中文或多语言数据进行训练,会有更广泛的应用场景。对细节的处理不足,所生成的图像第一眼看过去是很惊艳的,但如果放大观察细节部分,会出现很多错位、扭曲的现象。5.2. 对开发过程有帮助的产品文档汇总
以上提到的内容的相关介绍以及有关文档可参考:
Amazon SageMaker 入门教程:https://aws.amazon.com/cn/sagemaker/getting-started/Amazon SageMaker产品介绍:https://aws.amazon.com/cn/sagemaker/Amazon SageMaker产品文档:https://docs.aws.amazon.com/zh_cn/sagemaker/index.htmlStable Diffusion 模型文档(HuggingFace):https://huggingface.co/spaces/stabilityai/stable-diffusionStable Diffusion 模型文档(StabilityAI):https://stability.ai/blog/stable-diffusion-public-release通过云上探索实验室,开发者可以学习实践云上技术,用技术实验、产品体验、案例应用等方式,亲身感受最新、最热门的亚马逊云科技开发者工具与服务。发挥自己的想象和创造,以文章、视频、代码 Demo 等形式将自己的技术心得分享给其他开发者小伙伴。一同创造分享,互助启发,玩转云上技术。云上探索实验室不仅是体验的空间,更是分享的平台。
本次亚马逊云科技举办的活动「云上探索实验室」,活动的主题是从实践中探索机器学习边界。一共有三个可体验的教程,分别是:使用 Amazon SageMaker 构建机器学习应用、基于 Amazon SageMaker构建细粒度情感分析应用、使用 Amazon SageMaker基于Stable Diffusion模型,快速搭建你的第一个AIGC应用。开启云上探索实验室1,和我来一起体验Amazon SageMaker吧。

https://dev.amazoncloud.cn/experience ↩︎