写在前面:
在学习自动驾驶领域上的强化学习过程中,我决定使用highwy-env库建设的模拟器来进行环境构建,但是翻阅了众多教程(包含国内国外)之后,发现教程内容过旧,因为随着2023年的到来,highway-env库也进行了更新,前两年的教程无一例外都使用了老旧版本的函数和返回值。
highway-env是什么东西?
安装方式:(默认最新版)pip install highway-env
首先先列出我发现的新库中的改动:
以前返回值有四个:
observation, reward, done, info = env.step(action)
现在返回值有五个:
observation, reward, terminated, truncated, info = env.step(action)
我推测以前的环境数据形式是ndarray数组:
data = env.reset()
data = (arragry([[ndarray],[],[],...,[]]),type==dtype32)
现在的环境数据形式是元组:
data = env.reset()
data = ((arragry([[ndarray],[],[],...,[]]),type==dtype32,{reward:{},terminated:{},...,})
基于以上改动,那么在代码中的数据处理部分也会相应地发生改变。特别是在使用多个库的时候,需要注意版本关联问题。
参考的一些代码
我的虚拟环境配置:(GPU)
虚拟环境是什么东西?来人,喂它吃九转大肠。

其中必须用到的主要有以下几个:
基于 python 3.8.0
pytorch
gym
highway
tqdm
matplotlib
pygame
numpy
highway-env
使用DoubleDQN算法进行训练,此后还有在此基础上的其他改动。
默认创建python文件double_dqn.py,以下为文件中代码,拼在一起就是完整的。
注释是英文是因为我做的是英文的项目,简单翻译即可。
所使用的库
import osimport copyimport randomimport timeimport numpy as npimport matplotlib.pyplot as pltfrom tqdm import tqdmimport torchimport torch.nn as nnimport torch.nn.functional as Fimport gymimport highway_env检测设备并初始化默认十字路口环境
# set devicedevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")# Author: Da Xuanzi 2023-2-17# Define the environmentenv = gym.make("intersection-v0")# detailsenv.config["duration"] = 13env.config["vehicles_count"] = 20env.config["vehicles_density"] = 1.3env.config["reward_speed_range"] = [7.0, 10.0]env.config["initial_vehicle_count"] = 10env.config["simulation_frequency"] = 15env.config["arrived_reward"] = 2env.reset()十字路口环境的结构:
env.config{ "observation": { "type": "Kinematics", "vehicles_count": 15, "features": ["presence", "x", "y", "vx", "vy", "cos_h", "sin_h"], "features_range": { "x": [-100, 100], "y": [-100, 100], "vx": [-20, 20], "vy": [-20, 20], }, "absolute": True, "flatten": False, "observe_intentions": False }, "action": { "type": "DiscreteMetaAction", "longitudinal": False, "lateral": True }, "duration": 13, # [s] "destination": "o1", "initial_vehicle_count": 10, "spawn_probability": 0.6, "screen_width": 600, "screen_height": 600, "centering_position": [0.5, 0.6], "scaling": 5.5 * 1.3, "collision_reward": IntersectionEnv.COLLISION_REWARD, "normalize_reward": False}构建网络
可以自定义隐藏层节点个数
class Net(nn.Module): def __init__(self, state_dim, action_dim): # super class super(Net, self).__init__() # hidden nodes define hidden_nodes1 = 1024 hidden_nodes2 = 512 self.fc1 = nn.Linear(state_dim, hidden_nodes1) self.fc2 = nn.Linear(hidden_nodes1, hidden_nodes2) self.fc3 = nn.Linear(hidden_nodes2, action_dim) def forward(self, state): # define forward pass of the actor x = state # state # Relu function double x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) out = self.fc3(x) return out构建学习器
class Replay: # learning def __init__(self, buffer_size, init_length, state_dim, action_dim, env): self.buffer_size = buffer_size self.init_length = init_length self.state_dim = state_dim self.action_dim = action_dim self.env = env self._storage = [] self._init_buffer(init_length) def _init_buffer(self, n): # choose n samples state taken from random actions state = self.env.reset() for i in range(n): action = self.env.action_space.sample() observation, reward, done, truncated, info = self.env.step(action) # gym.env.step(action): tuple (obversation, reward, terminated, truncated, info) can edit # observation: numpy array [location] # reward: reward for *action # terminated: bool whether end # truncated: bool whether overflow (from done) # info: help/log/information if type(state) == type((1,)): state = state[0] # if state is tuple (ndarray[[],[],...,[]],{"speed":Float,"cashed":Bool,"action":Int,"reward":dict,"agent-reward":Float[],"agent-done":Bool}),we take its first item # because after run env.reset(), the state stores the environmental data and it can not be edited # we only need the state data -- the first ndarray exp = { "state": state, "action": action, "reward": reward, "state_next": observation, "done": done, } self._storage.append(exp) state = observation if done: state = self.env.reset() done = False def buffer_add(self, exp): # exp buffer: {exp}=={ # "state": state, # "action": action, # "reward": reward, # "state_next": observation, # "done": terminated,} self._storage.append(exp) if len(self._storage) > self.buffer_size: self._storage.pop(0) # remove the last one in dict def buffer_sample(self, n): # random n samples from exp buffer return random.sample(self._storage, n)构建学习对象
PATH = 你的文件夹绝对路径/相对路径
class DOUBLEDQN(nn.Module): def __init__( self, env, # gym environment state_dim, # state size action_dim, # action size lr = 0.001, # learning rate gamma = 0.99, # discount factor batch_size = 5, # batch size for each training timestamp = "",): # super class super(DOUBLEDQN, self).__init__() self.env = env self.env.reset() self.timestamp = timestamp # for evaluation purpose self.test_env = copy.deepcopy(env) self.state_dim = state_dim self.action_dim = action_dim self.gamma = gamma self.batch_size = batch_size self.learn_step_counter = 0 self.is_rend = False self.target_net = Net(self.state_dim, self.action_dim).to(device)#TODO self.estimate_net = Net(self.state_dim, self.action_dim).to(device)#TODO self.ReplayBuffer = Replay(1000, 100, self.state_dim, self.action_dim, env)#TODO self.optimizer = torch.optim.Adam(self.estimate_net.parameters(), lr=lr) def choose_our_action(self, state, epsilon = 0.9): # greedy strategy for choosing action # state: ndarray environment state # epsilon: float in [0,1] # return: action we chosen # turn to 1D float tensor -> [[a1,a2,a3,...,an]] # we have to increase the speed of transformation ndarray to tensor if not it will spend a long time to train the model # ndarray[[ndarray],...[ndarray]] => list[[ndarray],...[ndarray]] => ndarray[...] => tensor[...] if type(state) == type((1,)): state = state[0] temp = [exp for exp in state] target = [] target = np.array(target) # n dimension to 1 dimension ndarray for i in temp: target = np.append(target,i) state = torch.FloatTensor(target).to(device) # randn() return a set of samples which are Gaussian distribution # no argments -> return a float number if np.random.randn() <= epsilon: # when random number smaller than epsilon: do these things # put a state array into estimate net to obtain their value array # choose max values in value array -> obtain action action_value = self.estimate_net(state) action = torch.argmax(action_value).item() else: # when random number bigger than epsilon: randomly choose a action action = np.random.randint(0, self.action_dim) return action def train(self, num_episode): # num_eposide: total turn number for train loss_list = [] # loss set avg_reward_list = [] # reward set episode_reward = 0 rend = 0 # tqdm : a model for showing process bar for episode in tqdm(range(1,int(num_episode)+1)): done = False state = self.env.reset() each_loss = 0 step = 0 if type(state) == type((1,)): state = state[0] while not done: if self.is_rend: self.env.render() step +=1 action = self.choose_our_action(state) observation, reward, done, truncated, info = self.env.step(action) exp = { "state": state, "action": action, "reward": reward, "state_next": observation, "done": done, } self.ReplayBuffer.buffer_add(exp) state = observation # sample random batch in replay memory exp_batch = self.ReplayBuffer.buffer_sample(self.batch_size) # extract batch data action_batch = torch.LongTensor( [exp["action"] for exp in exp_batch] ).to(device) reward_batch = torch.FloatTensor( [exp["reward"] for exp in exp_batch] ).to(device) done_batch = torch.FloatTensor( [1 - exp["done"] for exp in exp_batch] ).to(device) # Slow method -> Fast method when having more data state_next_temp = [exp["state_next"] for exp in exp_batch] state_temp = [exp["state"] for exp in exp_batch] state_temp_list = np.array(state_temp) state_next_temp_list = np.array(state_next_temp) state_next_batch = torch.FloatTensor(state_next_temp_list).to(device) state_batch = torch.FloatTensor(state_temp_list).to(device) # reshape state_batch = state_batch.reshape(self.batch_size, -1) action_batch = action_batch.reshape(self.batch_size, -1) reward_batch = reward_batch.reshape(self.batch_size, -1) state_next_batch = state_next_batch.reshape(self.batch_size, -1) done_batch = done_batch.reshape(self.batch_size, -1) # obtain estimate Q value gather(dim, index) dim==1:column index estimate_Q_value = self.estimate_net(state_batch).gather(1, action_batch) # obtain target Q value detach:remove the matched element max_action_index = self.estimate_net(state_next_batch).detach().argmax(1) target_Q_value = reward_batch + done_batch * self.gamma * self.target_net( state_next_batch ).gather(1, max_action_index.unsqueeze(1))# squeeze(1) n*1->1*1, unsqueeze(1) 1*1->n*1 # mse_loss: mean loss loss = F.mse_loss(estimate_Q_value, target_Q_value) each_loss += loss.item() # update network self.optimizer.zero_grad() loss.backward() self.optimizer.step() # update target network # load parameters into model if self.learn_step_counter % 10 == 0: self.target_net.load_state_dict(self.estimate_net.state_dict()) self.learn_step_counter +=1 reward, count = self.eval() episode_reward += reward # you can update these variables if episode_reward % 100 == 0: rend += 1 if rend % 5 == 0: self.is_rend = True else: self.is_rend = False # save period = 1 if episode % period == 0: each_loss /= step episode_reward /= period avg_reward_list.append(episode_reward) loss_list.append(each_loss) print("\nepisode:[{}/{}], \t each_loss: {:.4f}, \t eposide_reward: {:.3f}, \t step: {}".format( episode, num_episode, each_loss, episode_reward, count )) # episode_reward = 0 # create a new directory for saving path = PATH + "/" + self.timestamp try: os.makedirs(path) except OSError: pass # saving as timestamp file np.save(path + "/DOUBLE_DQN_LOSS.npy", loss_list) np.save(path + "/DOUBLE_DQN_EACH_REWARD.npy", avg_reward_list) torch.save(self.estimate_net.state_dict(), path + "/DOUBLE_DQN_params.pkl") self.env.close() return loss_list, avg_reward_list def eval(self): # evaluate the policy count = 0 total_reward = 0 done = False state = self.test_env.reset() if type(state) == type((1,)): state = state[0] while not done: action = self.choose_our_action(state, epsilon = 1) observation, reward, done, truncated, info = self.test_env.step(action) total_reward += reward count += 1 state = observation return total_reward, count构建运行函数
超参数可以自己设置 lr gamma
if __name__ == "__main__": # timestamp named_tuple = time.localtime() time_string = time.strftime("%Y-%m-%d-%H-%M", named_tuple) print(time_string) # create a doubledqn object double_dqn_object = DOUBLEDQN( env, state_dim=105, action_dim=3, lr=0.001, gamma=0.99, batch_size=64, timestamp=time_string, ) # your chosen train times iteration = 20 # start training avg_loss, avg_reward_list = double_dqn_object.train(iteration) path = PATH + "/" + time_string np.save(path + "/DOUBLE_DQN_LOSS.npy", avg_loss) np.save(path + "/DOUBLE_DQN_EACH_REWARD.npy", avg_reward_list) torch.save(double_dqn_object.estimate_net.state_dict(), path + "/DOUBLE_DQN_params.pkl") torch.save(double_dqn_object.state_dict(), path + "/DOUBLE_DQN_MODEL.pt")使用数据进行绘制图片
新建文件draw_figures.py
?处自己替换成自己的路径
import matplotlib.pyplot as pltimport numpy as npLoss = r"?\?\DOUBLE_DQN_LOSS.npy"Reward = r"?\?\DOUBLE_DQN_EACH_REWARD.npy"avg_loss = np.load(Loss)avg_reward_list = np.load(Reward)# print("loss", avg_loss)# print("reward", avg_reward_list)plt.figure(figsize=(10, 6))plt.plot(avg_loss)plt.grid()plt.title("Double DQN Loss")plt.xlabel("epochs")plt.ylabel("loss")plt.savefig(r"?\figures\double_dqn_loss.png", dpi=150)plt.show()plt.figure(figsize=(10, 6))plt.plot(avg_reward_list)plt.grid()plt.title("Double DQN Training Reward")plt.xlabel("epochs")plt.ylabel("reward")plt.savefig(r"?\figures\double_dqn_train_reward.png", dpi=150)plt.show()
提纳里手动分割线
Dueling_DQN
以上基本稍作改动即可
class Net(nn.Module): def __init__(self, state_dim, action_dim): """ Initialize the network : param state_dim: int, size of state space : param action_dim: int, size of action space """ super(Net, self).__init__() hidden_nodes1 = 1024 hidden_nodes2 = 512 self.fc1 = nn.Linear(state_dim, hidden_nodes1) self.fc2 = nn.Linear(hidden_nodes1, hidden_nodes2) self.fc3 = nn.Linear(hidden_nodes2, action_dim + 1) def forward(self, state): """ Define the forward pass of the actor : param state: ndarray, the state of the environment """ x = state # print(x.shape) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) out = self.fc3(x) return outclass Replay: # learning def __init__(self, buffer_size, init_length, state_dim, action_dim, env): self.buffer_size = buffer_size self.init_length = init_length self.state_dim = state_dim self.action_dim = action_dim self.env = env self._storage = [] self._init_buffer(init_length) def _init_buffer(self, n): # choose n samples state taken from random actions state = self.env.reset() for i in range(n): action = self.env.action_space.sample() observation, reward, done, truncated, info = self.env.step(action) # gym.env.step(action): tuple (obversation, reward, terminated, truncated, info) can edit # observation: numpy array [location] # reward: reward for *action # terminated: bool whether end # truncated: bool whether overflow (from done) # info: help/log/information if type(state) == type((1,)): state = state[0] # if state is tuple (ndarray[[],[],...,[]],{"speed":Float,"cashed":Bool,"action":Int,"reward":dict,"agent-reward":Float[],"agent-done":Bool}),we take its first item # because after run env.reset(), the state stores the environmental data and it can not be edited # we only need the state data -- the first ndarray exp = { "state": state, "action": action, "reward": reward, "state_next": observation, "done": done, } self._storage.append(exp) state = observation if done: state = self.env.reset() done = False def buffer_add(self, exp): # exp buffer: {exp}=={ # "state": state, # "action": action, # "reward": reward, # "state_next": observation, # "done": terminated,} self._storage.append(exp) if len(self._storage) > self.buffer_size: self._storage.pop(0) # remove the last one in dict def buffer_sample(self, n): # random n samples from exp buffer return random.sample(self._storage, n)class DUELDQN(nn.Module): def __init__( self, env, state_dim, action_dim, lr=0.001, gamma=0.99, batch_size=5, timestamp="", ): """ : param env: object, a gym environment : param state_dim: int, size of state space : param action_dim: int, size of action space : param lr: float, learning rate : param gamma: float, discount factor : param batch_size: int, batch size for training """ super(DUELDQN, self).__init__() self.env = env self.env.reset() self.timestamp = timestamp self.test_env = copy.deepcopy(env) # for evaluation purpose self.state_dim = state_dim self.action_dim = action_dim self.gamma = gamma self.batch_size = batch_size self.learn_step_counter = 0 self.is_rend =False self.target_net = Net(self.state_dim, self.action_dim).to(device) self.estimate_net = Net(self.state_dim, self.action_dim).to(device) self.ReplayBuffer = Replay(1000, 100, self.state_dim, self.action_dim, env) self.optimizer = torch.optim.Adam(self.estimate_net.parameters(), lr=lr) def choose_action(self, state, epsilon=0.9): # greedy strategy for choosing action # state: ndarray environment state # epsilon: float in [0,1] # return: action we chosen # turn to 1D float tensor -> [[a1,a2,a3,...,an]] # we have to increase the speed of transformation ndarray to tensor if not it will spend a long time to train the model # ndarray[[ndarray],...[ndarray]] => list[[ndarray],...[ndarray]] => ndarray[...] => tensor[...] if type(state) == type((1,)): state = state[0] temp = [exp for exp in state] target = [] target = np.array(target) # n dimension to 1 dimension ndarray for i in temp: target = np.append(target, i) state = torch.FloatTensor(target).to(device) # randn() return a set of samples which are Gaussian distribution # no argments -> return a float number if np.random.randn() <= epsilon: # when random number smaller than epsilon: do these things # put a state array into estimate net to obtain their value array # choose max values in value array -> obtain action action_value = self.estimate_net(state) action_value = action_value[:-1] action = torch.argmax(action_value).item() else: # when random number bigger than epsilon: randomly choose a action action = np.random.randint(0, self.action_dim) return action def calculate_duelling_q_values(self, duelling_q_network_output): """ Calculate the Q values using the duelling network architecture. This is equation (9) in the paper. :param duelling_q_network_output: tensor, output of duelling q network :return: Q values """ state_value = duelling_q_network_output[:, -1] avg_advantage = torch.mean(duelling_q_network_output[:, :-1], dim=1) q_values = state_value.unsqueeze(1) + ( duelling_q_network_output[:, :-1] - avg_advantage.unsqueeze(1) ) return q_values def train(self, num_episode): # num_eposide: total turn number for train loss_list = [] # loss set avg_reward_list = [] # reward set episode_reward = 0 # tqdm : a model for showing process bar for episode in tqdm(range(1,int(num_episode)+1)): done = False state = self.env.reset() each_loss = 0 step = 0 if type(state) == type((1,)): state = state[0] while not done: if self.is_rend: self.env.render() step += 1 action = self.choose_action(state) observation, reward, done, truncated, info = self.env.step(action) exp = { "state": state, "action": action, "reward": reward, "state_next": observation, "done": done, } self.ReplayBuffer.buffer_add(exp) state = observation # sample random batch in replay memory exp_batch = self.ReplayBuffer.buffer_sample(self.batch_size) # extract batch data action_batch = torch.LongTensor( [exp["action"] for exp in exp_batch] ).to(device) reward_batch = torch.FloatTensor( [exp["reward"] for exp in exp_batch] ).to(device) done_batch = torch.FloatTensor( [1 - exp["done"] for exp in exp_batch] ).to(device) # Slow method -> Fast method when having more data state_next_temp = [exp["state_next"] for exp in exp_batch] state_temp = [exp["state"] for exp in exp_batch] state_temp_list = np.array(state_temp) state_next_temp_list = np.array(state_next_temp) state_next_batch = torch.FloatTensor(state_next_temp_list).to(device) state_batch = torch.FloatTensor(state_temp_list).to(device) # reshape state_batch = state_batch.reshape(self.batch_size, -1) action_batch = action_batch.reshape(self.batch_size, -1) reward_batch = reward_batch.reshape(self.batch_size, -1) state_next_batch = state_next_batch.reshape(self.batch_size, -1) done_batch = done_batch.reshape(self.batch_size, -1) # get estimate Q value estimate_net_output = self.estimate_net(state_batch) estimate_Q = self.calculate_duelling_q_values(estimate_net_output) estimate_Q = estimate_Q.gather(1, action_batch) # get target Q value max_action_idx = ( self.estimate_net(state_next_batch)[:, :-1].detach().argmax(1) ) target_net_output = self.target_net(state_next_batch) target_Q = self.calculate_duelling_q_values(target_net_output).gather( 1, max_action_idx.unsqueeze(1) ) target_Q = reward_batch + done_batch * self.gamma * target_Q # compute mse loss loss = F.mse_loss(estimate_Q, target_Q) each_loss += loss.item() # update network self.optimizer.zero_grad() loss.backward() self.optimizer.step() # update target network if self.learn_step_counter % 10 == 0: self.target_net.load_state_dict(self.estimate_net.state_dict()) self.learn_step_counter += 1 reward, count = self.eval() episode_reward += reward # save period = 1 if episode % period == 0: each_loss /= step episode_reward /= period avg_reward_list.append(episode_reward) loss_list.append(each_loss) print("\nepisode:[{}/{}], \t each_loss: {:.4f}, \t eposide_reward: {:.3f}, \t step: {}".format( episode, num_episode, each_loss, episode_reward, count )) # epoch_reward = 0 path = PATH + "/" + self.timestamp # create a new directory for saving try: os.makedirs(path) except OSError: pass np.save(path + "/DUELING_DQN_LOSS.npy", loss_list) np.save(path + "/DUELING_DQN_EACH_REWARD.npy", avg_reward_list) torch.save(self.estimate_net.state_dict(), path + "/DUELING_DQN_params.pkl") self.env.close() return loss_list, avg_reward_list def eval(self): # evaluate the policy count = 0 total_reward = 0 done = False state = self.test_env.reset() if type(state) == type((1,)): state = state[0] while not done: action = self.choose_action(state, epsilon=1) state_next, reward, done, _, info = self.test_env.step(action) total_reward += reward count += 1 state = state_next return total_reward, countif __name__ == "__main__": # timestamp for saving named_tuple = time.localtime() # get struct_time time_string = time.strftime( "%Y-%m-%d-%H-%M", named_tuple ) # have a folder of "date+time ex: 1209_20_36 -> December 12th, 20:36" duel_dqn_object = DUELDQN( env, state_dim=105, action_dim=3, lr=0.001, gamma=0.99, batch_size=64, timestamp=time_string, ) path = PATH + "/" + time_string # Train the policy iterations = 10 avg_loss, avg_reward_list = duel_dqn_object.train(iterations) np.save(path + "/DUELING_DQN_LOSS.npy", avg_loss) np.save(path + "/DUELING_DQN_EACH_REWARD.npy", avg_reward_list) torch.save(duel_dqn_object.estimate_net.state_dict(), path + "/DUELING_DQN_params.pkl") torch.save(duel_dqn_object.state_dict(), path + "/DUELING_DQN_MODEL.pt")DDQN+OtherChanges
三层2D卷积
# add CNN structureclass Net(nn.Module): def __init__(self, state_dim, action_dim): # initalize the network # state_dim: state space # action_dim: action space super(Net, self).__init__() # nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding) # in_channel : input size = in_channels * in_N * in_N # out_channel : define # kernel_size : rules or define # stride: step length # padding: padding size # out_N = (in_N - Kernel_size + 2 * Padding)/ Stride +1 self.cnn = nn.Sequential( # the first 2D convolutional layer nn.Conv2d(1, 4, kernel_size=3, padding=1), nn.BatchNorm2d(4), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=1), # the second 2D convolutional layer nn.Conv2d(4, 8, kernel_size=3, padding=1), nn.BatchNorm2d(8), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=1), # the third 2D convolutional layer ---- my test and try or more convolutional layers nn.Conv2d(8, 4, kernel_size=3, padding=1), nn.BatchNorm2d(4), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=1), ) hidden_nodes1 = 1024 hidden_nodes2 = 512 self.fc1 = nn.Linear(4 * 1 * 9, hidden_nodes1) self.fc2 = nn.Linear(hidden_nodes1, hidden_nodes2) self.fc3 = nn.Linear(hidden_nodes2, action_dim) def forward(self, state): # define forward pass of the actor x = state # state x = self.cnn(x) x = x.view(x.size(0), -1) # Relu function double x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) out = self.fc3(x) return outclass Replay: def __init__(self, buffer_size, init_length, state_dim, action_dim, env): self.buffer_size = buffer_size self.init_length = init_length self.state_dim = state_dim self.action_dim = action_dim self.env = env self._storage = [] self._init_buffer(init_length) def _init_buffer(self, n): # choose n samples state taken from random actions state = self.env.reset() for i in range(n): action = self.env.action_space.sample() observation, reward, done, truncated, info = self.env.step(action) # gym.env.step(action): tuple (obversation, reward, terminated, truncated, info) can edit # observation: numpy array [location] # reward: reward for *action # terminated: bool whether end # truncated: bool whether overflow (from done) # info: help/log/information if type(state) == type((1,)): state = state[0] # if state is tuple (ndarray[[],[],...,[]],{"speed":Float,"cashed":Bool,"action":Int,"reward":dict,"agent-reward":Float[],"agent-done":Bool}),we take its first item # because after run env.reset(), the state stores the environmental data and it can not be edited # we only need the state data -- the first ndarray exp = { "state": state, "action": action, "reward": reward, "state_next": observation, "done": done, } self._storage.append(exp) state = observation if done: state = self.env.reset() done = False def buffer_add(self, exp): # exp buffer: {exp}=={ # "state": state, # "action": action, # "reward": reward, # "state_next": observation, # "done": terminated,} self._storage.append(exp) if len(self._storage) > self.buffer_size: self._storage.pop(0) # remove the last one in dict def buffer_sample(self, N): # random n samples from exp buffer return random.sample(self._storage, N)class DOUBLEDQN_CNN(nn.Module): def __init__( self, env, # gym environment state_dim, # state size action_dim, # action size lr=0.001, # learning rate gamma=0.99, # discount factor batch_size=5, # batch size for each training timestamp="", ): # super class super(DOUBLEDQN_CNN, self).__init__() self.env = env self.env.reset() self.timestamp = timestamp # for evaluation purpose self.test_env = copy.deepcopy(env) self.state_dim = state_dim self.action_dim = action_dim self.gamma = gamma self.batch_size = batch_size self.learn_step_counter = 0 self.is_rend = False self.target_net = Net(self.state_dim, self.action_dim).to(device) self.estimate_net = Net(self.state_dim, self.action_dim).to(device) self.ReplayBuffer = Replay(1000, 100, self.state_dim, self.action_dim, env) self.optimizer = torch.optim.Adam(self.estimate_net.parameters(), lr=lr) def choose_action(self, state, epsilon=0.9): # greedy strategy for choosing action # state: ndarray environment state # epsilon: float in [0,1] # return: action we chosen # turn to 1D float tensor -> [[a1,a2,a3,...,an]] # we have to increase the speed of transformation ndarray to tensor if not it will spend a long time to train the model # ndarray[[ndarray],...[ndarray]] => list[[ndarray],...[ndarray]] => ndarray[...] => tensor[...] if type(state) == type((1,)): state = state[0] #TODO state = ( torch.FloatTensor(state).to(device).reshape(-1, 1, 7, self.state_dim // 7) ) if np.random.randn() <= epsilon: action_value = self.estimate_net(state) action = torch.argmax(action_value).item() else: action = np.random.randint(0, self.action_dim) return action def train(self, num_episode): # num_eposide: total turn number for train count_list = [] loss_list = [] total_reward_list = [] avg_reward_list = [] episode_reward = 0 rend = 0 for episode in tqdm(range(1,int(num_episode)+1)): done = False state = self.env.reset() each_loss = 0 step = 0 if type(state) == type((1,)): state = state[0] while not done: if self.is_rend: self.env.render() step += 1 action = self.choose_action(state) observation, reward, done, truncated, info = self.env.step(action) exp = { "state": state, "action": action, "reward": reward, "state_next": observation, "done": done, } self.ReplayBuffer.buffer_add(exp) state = observation # sample random batch from replay memory exp_batch = self.ReplayBuffer.buffer_sample(self.batch_size) # extract batch data action_batch = torch.LongTensor([exp["action"] for exp in exp_batch]) reward_batch = torch.FloatTensor([exp["reward"] for exp in exp_batch]) done_batch = torch.FloatTensor([1 - exp["done"] for exp in exp_batch]) # Slow method -> Fast method when having more data state_next_temp = [exp["state_next"] for exp in exp_batch] state_temp = [exp["state"] for exp in exp_batch] state_temp_list = np.array(state_temp) state_next_temp_list = np.array(state_next_temp) state_next_batch = torch.FloatTensor(state_next_temp_list) state_batch = torch.FloatTensor(state_temp_list) # reshape state_batch = state_batch.to(device).reshape( self.batch_size, 1, 7, self.state_dim // 7 ) action_batch = action_batch.to(device).reshape(self.batch_size, -1) reward_batch = reward_batch.to(device).reshape(self.batch_size, -1) state_next_batch = state_next_batch.to(device).reshape( self.batch_size, 1, 7, self.state_dim // 7 ) done_batch = done_batch.to(device).reshape(self.batch_size, -1) # get estimate Q value estimate_Q = self.estimate_net(state_batch).gather(1, action_batch) # get target Q value max_action_idx = self.estimate_net(state_next_batch).detach().argmax(1) target_Q = reward_batch + done_batch * self.gamma * self.target_net( state_next_batch ).gather(1, max_action_idx.unsqueeze(1)) # compute mse loss loss = F.mse_loss(estimate_Q, target_Q) each_loss += loss.item() # update network self.optimizer.zero_grad() loss.backward() self.optimizer.step() # update target network if self.learn_step_counter % 10 == 0: self.target_net.load_state_dict(self.estimate_net.state_dict()) self.learn_step_counter += 1 reward, count = self.eval() episode_reward += reward # you can update these variables if episode_reward % 100 == 0: rend += 1 if rend % 5 == 0: self.is_rend = True else: self.is_rend = False # save period = 1 if episode % period == 0: each_loss /= step episode_reward /= period avg_reward_list.append(episode_reward) loss_list.append(each_loss) print("\nepisode:[{}/{}], \t each_loss: {:.4f}, \t eposide_reward: {:.3f}, \t step: {}".format( episode, num_episode, each_loss, episode_reward, count )) # epoch_reward = 0 # create a new directory for saving path = PATH + "/" + self.timestamp try: os.makedirs(path) except OSError: pass # saving as timestamp file np.save(path + "/DOUBLE_DQN_CNN_LOSS.npy", loss_list) np.save(path + "/DOUBLE_DQN_CNN_EACH_REWARD.npy", avg_reward_list) torch.save(self.estimate_net.state_dict(), path + "/DOUBLE_DQN_CNN_params.pkl") self.env.close() return loss_list, avg_reward_list def eval(self): # evaluate the policy count = 0 total_reward = 0 done = False state = self.test_env.reset() if type(state) == type((1,)): state = state[0] while not done: action = self.choose_action(state, epsilon=1) observation, reward, done, truncated, info = self.test_env.step(action) total_reward += reward count += 1 state = observation return total_reward, countif __name__ == "__main__": # timestamp named_tuple = time.localtime() time_string = time.strftime("%Y-%m-%d-%H-%M", named_tuple) print(time_string) # create a doubledqn object double_dqn_cnn_object = DOUBLEDQN_CNN( env, state_dim=105, action_dim=3, lr=0.001, gamma=0.99, batch_size=64, timestamp=time_string, ) # your chosen train times iteration = 20 # start training avg_loss, avg_reward_list = double_dqn_cnn_object.train(iteration) path = PATH + "/" + time_string np.save(path + "/DOUBLE_DQN_CNN_LOSS.npy", avg_loss) np.save(path + "/DOUBLE_DQN_CNN_EACH_REWARD.npy", avg_reward_list) torch.save(double_dqn_cnn_object.estimate_net.state_dict(), path + "/DOUBLE_DQN_CNN_params.pkl") torch.save(double_dqn_cnn_object.state_dict(), path + "/DOUBLE_DQN_CNN_MODEL.pt")经验池
class Net(nn.Module): def __init__(self, state_dim, action_dim): # state_dim: state space # action_dim: action space super(Net, self).__init__() hidden_nodes1 = 1024 hidden_nodes2 = 512 self.fc1 = nn.Linear(state_dim, hidden_nodes1) self.fc2 = nn.Linear(hidden_nodes1, hidden_nodes2) self.fc3 = nn.Linear(hidden_nodes2, action_dim) def forward(self, state): # state: ndarray x = state x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) out = self.fc3(x) return out# Priortized_Replayclass Prioritized_Replay: def __init__( self, buffer_size, init_length, state_dim, action_dim, est_Net, tar_Net, gamma, ): # state_dim: state space # action_dim: action space # env: env self.buffer_size = buffer_size self.init_length = init_length self.state_dim = state_dim self.action_dim = action_dim self.gamma = gamma self.is_rend = False self.priority = deque(maxlen=buffer_size) self._storage = [] self._init_buffer(init_length, est_Net, tar_Net) def _init_buffer(self, n, est_Net, tar_Net): # n: sample number state = env.reset() for i in range(n): action = env.action_space.sample() observation, reward, done, truncated, info = env.step(action) # gym.env.step(action): tuple (obversation, reward, terminated, truncated, info) can edit # observation: numpy array [location] # reward: reward for *action # terminated: bool whether end # truncated: bool whether overflow (from done) # info: help/log/information if type(state) == type((1,)): state = state[0] # if state is tuple (ndarray[[],[],...,[]],{"speed":Float,"cashed":Bool,"action":Int,"reward":dict,"agent-reward":Float[],"agent-done":Bool}),we take its first item # because after run env.reset(), the state stores the environmental data and it can not be edited # we only need the state data -- the first ndarray exp = { "state": state, "action": action, "reward": reward, "state_next": observation, "done": done, } self.prioritize(est_Net, tar_Net, exp, alpha=0.6) self._storage.append(exp) state = observation if done: state = env.reset() done = False def buffer_add(self, exp): # exp buffer: {exp}=={ # "state": state, # "action": action, # "reward": reward, # "state_next": observation, # "done": terminated,} self._storage.append(exp) if len(self._storage) > self.buffer_size: self._storage.pop(0) # add prioritize def prioritize(self, est_Net, tar_Net, exp, alpha=0.6): state = torch.FloatTensor(exp["state"]).to(device).reshape(-1) q = est_Net(state)[exp["action"]].detach().cpu().numpy() q_next = exp["reward"] + self.gamma * torch.max(est_Net(state).detach()) # TD error p = (np.abs(q_next.cpu().numpy() - q) + (np.e ** -10)) ** alpha self.priority.append(p.item()) def get_prioritized_batch(self, N): prob = self.priority / np.sum(self.priority) # random.choices(list,weights=None,*,cum_weights=None,k=1) # weight: set the chosen item rate # k: times for choice # cum_weight: sum of weight sample_idxes = random.choices(range(len(prob)), k=N, weights=prob) importance = (1 / prob) * (1 / len(self.priority)) sampled_importance = np.array(importance)[sample_idxes] sampled_batch = np.array(self._storage)[sample_idxes] return sampled_batch.tolist(), sampled_importance def buffer_sample(self, N): # random n samples from exp buffer return random.sample(self._storage, N)class DDQNPB(nn.Module): def __init__( self, env, state_dim, action_dim, lr=0.001, gamma=0.99, buffer_size=1000, batch_size=50, beta=1, beta_decay=0.995, beta_min=0.01, timestamp="", ): # env: environment # state_dim: state space # action_dim: action space # lr: learning rate # gamma: loss/discount factor # batch_size: training batch size super(DDQNPB, self).__init__() self.timestamp = timestamp self.test_env = copy.deepcopy(env) # for evaluation purpose self.state_dim = state_dim self.action_dim = action_dim self.gamma = gamma self.batch_size = batch_size self.learn_step_counter = 0 self.target_net = Net(self.state_dim, self.action_dim).to(device) self.estimate_net = Net(self.state_dim, self.action_dim).to(device) self.optimizer = torch.optim.Adam(self.estimate_net.parameters(), lr=lr) self.ReplayBuffer = Prioritized_Replay( buffer_size, 100, self.state_dim, self.action_dim, self.estimate_net, self.target_net, gamma, ) self.priority = self.ReplayBuffer.priority # NOTE: right here beta is equal to (1-beta) in most of website articles, notation difference # start from 1 and decay self.beta = beta self.beta_decay = beta_decay self.beta_min = beta_min def choose_action(self, state, epsilon=0.9): # state: env state # epsilon: [0,1] # return action you choose # get a 1D array if type(state) == type((1,)): state = state[0] temp = [exp for exp in state] target = [] target = np.array(target) # n dimension to 1 dimension ndarray for i in temp: target = np.append(target, i) state = torch.FloatTensor(target).to(device) if np.random.randn() <= epsilon: action_value = self.estimate_net(state) action = torch.argmax(action_value).item() else: action = np.random.randint(0, self.action_dim) return action def train(self, num_episode): # num_epochs: training times loss_list = [] avg_reward_list = [] episode_reward = 0 for episode in tqdm(range(1,int(num_episode)+1)): done = False state = env.reset() each_loss = 0 step = 0 rend = 0 if type(state) == type((1,)): state = state[0] while not done: action = self.choose_action(state) observation, reward, done, _, info = env.step(action) # self.env.render() # store experience to replay memory exp = { "state": state, "action": action, "reward": reward, "state_next": observation, "done": done, } self.ReplayBuffer.buffer_add(exp) state = observation # importance weighting if self.beta > self.beta_min: self.beta *= self.beta_decay # sample random batch from replay memory exp_batch, importance = self.ReplayBuffer.get_prioritized_batch( self.batch_size ) importance = torch.FloatTensor(importance ** (1 - self.beta)).to(device) # extract batch data action_batch = torch.LongTensor( [exp["action"] for exp in exp_batch] ).to(device) reward_batch = torch.FloatTensor( [exp["reward"] for exp in exp_batch] ).to(device) done_batch = torch.FloatTensor( [1 - exp["done"] for exp in exp_batch] ).to(device) # Slow method -> Fast method when having more data state_next_temp = [exp["state_next"] for exp in exp_batch] state_temp = [exp["state"] for exp in exp_batch] state_temp_list = np.array(state_temp) state_next_temp_list = np.array(state_next_temp) state_next_batch = torch.FloatTensor(state_next_temp_list).to(device) state_batch = torch.FloatTensor(state_temp_list).to(device) # reshape state_batch = state_batch.reshape(self.batch_size, -1) action_batch = action_batch.reshape(self.batch_size, -1) reward_batch = reward_batch.reshape(self.batch_size, -1) state_next_batch = state_next_batch.reshape(self.batch_size, -1) done_batch = done_batch.reshape(self.batch_size, -1) # get estimate Q value estimate_Q = self.estimate_net(state_batch).gather(1, action_batch) # get target Q value max_action_idx = self.estimate_net(state_next_batch).detach().argmax(1) target_Q = reward_batch + done_batch * self.gamma * self.target_net( state_next_batch ).gather(1, max_action_idx.unsqueeze(1)) # compute mse loss # loss = F.mse_loss(estimate_Q, target_Q) loss = torch.mean( torch.multiply(torch.square(estimate_Q - target_Q), importance) ) each_loss += loss.item() # update network self.optimizer.zero_grad() loss.backward() self.optimizer.step() #TODO # update target network if self.learn_step_counter % 10 == 0: # self.update_target_networks() self.target_net.load_state_dict(self.estimate_net.state_dict()) self.learn_step_counter += 1 step += 1 env.render() # you can update these variables # if episode_reward % 100 == 0: # rend += 1 # if rend % 5 == 0: # self.is_rend = True # else: # self.is_rend = False reward, count = self.eval() episode_reward += reward # save period = 1 if episode % period == 0: # log each_loss /= period episode_reward /= period avg_reward_list.append(episode_reward) loss_list.append(each_loss) print( "\nepoch: [{}/{}], \tavg loss: {:.4f}, \tavg reward: {:.3f}, \tsteps: {}".format( episode, num_episode, each_loss, episode_reward, count ) ) # episode_reward = 0 # create a new directory for saving path = PATH + "/" + self.timestamp try: os.makedirs(path) except OSError: pass np.save(path + "/DOUBLE_DQN_PRIORITIZED_LOSS.npy", loss_list) np.save(path + "/DOUBLE_DQN_PRIORITIZED_REWARD.npy", avg_reward_list) torch.save(self.estimate_net.state_dict(),path + "/DOUBLE_DQN_PRIORITIZED_params.pkl") env.close() return loss_list, avg_reward_list def eval(self): """ Evaluate the policy """ count = 0 total_reward = 0 done = False state = self.test_env.reset() if type(state) == type((1,)): state = state[0] while not done: action = self.choose_action(state, epsilon=1) observation, reward, done, truncated, info = self.test_env.step(action) total_reward += reward count += 1 state = observation return total_reward, countif __name__ == "__main__": # timestamp for saving named_tuple = time.localtime() # get struct_time time_string = time.strftime("%Y-%m-%d-%H-%M", named_tuple) double_dqn_prioritized_object = DDQNPB( env, state_dim=105, action_dim=3, lr=0.001, gamma=0.99, buffer_size=1000, batch_size=64, timestamp=time_string, ) # Train the policy iterations = 10000 avg_loss, avg_reward_list = double_dqn_prioritized_object.train(iterations) path = PATH + "/" + time_string np.save(path + "/DOUBLE_DQN_PRIORITIZED_LOSS.npy", avg_loss) np.save(path + "/DOUBLE_DQN_PRIORITIZED_REWARD.npy", avg_reward_list) torch.save(double_dqn_prioritized_object.estimate_net.state_dict(), path + "/DOUBLE_DQN_PRIORITIZED_params.pkl") torch.save(double_dqn_prioritized_object.state_dict(), path + "/DOUBLE_DQN_PRIORITIZED_MODEL.pt")有些东西可以自己改掉,自己调出的bug才是好bug!(大雾)
写在后面:
关于自定义环境,刚刚花30分钟研究了一下,官方写的教程稀烂(狗头),我自己得到的攻略如下:
找到你的highway-env安装包位置,我的在:E:\formalFiles\Anaconda3-2020.07\envs\autodrive_38\Lib\site-packages\highway_env在highway-env里的envs可以看到多个场景的定义文件,此处拿出intersection_env.py举例,其他的同理。新建一个文件test_env.py,把intersection_env.py的所有内容复制粘贴到里面。
class test(AbstractEnv): # # ACTIONS: Dict[int, str] = { # 0: 'SLOWER', # 1: 'IDLE', # 2: 'FASTER' # } ACTIONS: Dict[int, str] = { 0: 'LANE_LEFT', 1: 'IDLE', 2: 'LANE_RIGHT', 3: 'FASTER', 4: 'SLOWER' }删除除了第一个class以外的所有class定义。这里是把动作区间改成5个。
在envs/_init_.py的末尾加上from highway_env.envs.test_env import *def register_highway_envs(): """Import the envs module so that envs register themselves.""" # my test environment register( id='test-v0',# 引用名 entry_point='highway_env.envs:test'#环境类名 )def _reward(self, action: int) -> float: """Aggregated reward, for cooperative agents.""" return sum(self._agent_reward(action, vehicle) for vehicle in self.controlled_vehicles ) / len(self.controlled_vehicles)def _agent_reward(self, action: int, vehicle: Vehicle) -> float: """Per-agent reward signal.""" rewards = self._agent_rewards(action, vehicle) reward = sum(self.config.get(name, 0) * reward for name, reward in rewards.items()) reward = self.config["arrived_reward"] if rewards["arrived_reward"] else reward reward *= rewards["on_road_reward"] if self.config["normalize_reward"]: reward = utils.lmap(reward, [self.config["collision_reward"], self.config["arrived_reward"]], [0, 1]) return rewarddef _agent_rewards(self, action: int, vehicle: Vehicle) -> Dict[Text, float]: """Per-agent per-objective reward signal.""" scaled_speed = utils.lmap(vehicle.speed, self.config["reward_speed_range"], [0, 1]) return { "collision_reward": vehicle.crashed, "high_speed_reward": np.clip(scaled_speed, 0, 1), "arrived_reward": self.has_arrived(vehicle), "on_road_reward": vehicle.on_road }import highway-envimport gymenv = gym.make("test-v0")env.reset()from typing import Dict, Tuple, Textimport numpy as npfrom highway_env import utilsfrom highway_env.envs.common.abstract import AbstractEnv, MultiAgentWrapperfrom highway_env.road.lane import LineType, StraightLane, CircularLane, AbstractLanefrom highway_env.road.regulation import RegulatedRoadfrom highway_env.road.road import RoadNetworkfrom highway_env.vehicle.kinematics import Vehiclefrom highway_env.vehicle.controller import ControlledVehicleclass test(AbstractEnv): # # ACTIONS: Dict[int, str] = { # 0: 'SLOWER', # 1: 'IDLE', # 2: 'FASTER' # } ACTIONS: Dict[int, str] = { 0: 'LANE_LEFT', 1: 'IDLE', 2: 'LANE_RIGHT', 3: 'FASTER', 4: 'SLOWER' } ACTIONS_INDEXES = {v: k for k, v in ACTIONS.items()} @classmethod def default_config(cls) -> dict: config = super().default_config() config.update({ "observation": { "type": "Kinematics", "vehicles_count": 15, "features": ["presence", "x", "y", "vx", "vy", "cos_h", "sin_h"], "features_range": { "x": [-100, 100], "y": [-100, 100], "vx": [-20, 20], "vy": [-20, 20], }, "absolute": True, "flatten": False, "observe_intentions": False }, "action": { "type": "DiscreteMetaAction", "longitudinal": True, "lateral": True, "target_speeds": [0, 4.5, 9] }, "duration": 13, # [s] "destination": "o1", "controlled_vehicles": 1, "initial_vehicle_count": 10, "spawn_probability": 0.6, "screen_width": 600, "screen_height": 600, "centering_position": [0.5, 0.6], "scaling": 5.5 * 1.3, "collision_reward": -10, "high_speed_reward": 2, "arrived_reward": 5, "reward_speed_range": [7.0, 9.0],# change "normalize_reward": False, "offroad_terminal": False }) return config def _reward(self, action: int) -> float: """Aggregated reward, for cooperative agents.""" return sum(self._agent_reward(action, vehicle) for vehicle in self.controlled_vehicles ) / len(self.controlled_vehicles) def _rewards(self, action: int) -> Dict[Text, float]: """Multi-objective rewards, for cooperative agents.""" agents_rewards = [self._agent_rewards(action, vehicle) for vehicle in self.controlled_vehicles] return { name: sum(agent_rewards[name] for agent_rewards in agents_rewards) / len(agents_rewards) for name in agents_rewards[0].keys() } # edit your reward def _agent_reward(self, action: int, vehicle: Vehicle) -> float: """Per-agent reward signal.""" rewards = self._agent_rewards(action, vehicle) reward = sum(self.config.get(name, 0) * reward for name, reward in rewards.items()) reward = self.config["arrived_reward"] if rewards["arrived_reward"] else reward reward *= rewards["on_road_reward"] if self.config["normalize_reward"]: reward = utils.lmap(reward, [self.config["collision_reward"], self.config["arrived_reward"]], [0, 1]) return reward def _agent_rewards(self, action: int, vehicle: Vehicle) -> Dict[Text, float]: """Per-agent per-objective reward signal.""" scaled_speed = utils.lmap(vehicle.speed, self.config["reward_speed_range"], [0, 1]) return { "collision_reward": vehicle.crashed, "high_speed_reward": np.clip(scaled_speed, 0, 1), "arrived_reward": self.has_arrived(vehicle), "on_road_reward": vehicle.on_road } def _is_terminated(self) -> bool: return any(vehicle.crashed for vehicle in self.controlled_vehicles) \ or all(self.has_arrived(vehicle) for vehicle in self.controlled_vehicles) \ or (self.config["offroad_terminal"] and not self.vehicle.on_road) def _agent_is_terminal(self, vehicle: Vehicle) -> bool: """The episode is over when a collision occurs or when the access ramp has been passed.""" return (vehicle.crashed or self.has_arrived(vehicle) or self.time >= self.config["duration"]) def _is_truncated(self) -> bool: return def _info(self, obs: np.ndarray, action: int) -> dict: info = super()._info(obs, action) info["agents_rewards"] = tuple(self._agent_reward(action, vehicle) for vehicle in self.controlled_vehicles) info["agents_dones"] = tuple(self._agent_is_terminal(vehicle) for vehicle in self.controlled_vehicles) return info def _reset(self) -> None: self._make_road() self._make_vehicles(self.config["initial_vehicle_count"]) def step(self, action: int) -> Tuple[np.ndarray, float, bool, bool, dict]: obs, reward, terminated, truncated, info = super().step(action) self._clear_vehicles() self._spawn_vehicle(spawn_probability=self.config["spawn_probability"]) return obs, reward, terminated, truncated, info def _make_road(self) -> None: """ Make an 4-way intersection. The horizontal road has the right of way. More precisely, the levels of priority are: - 3 for horizontal straight lanes and right-turns - 1 for vertical straight lanes and right-turns - 2 for horizontal left-turns - 0 for vertical left-turns The code for nodes in the road network is: (o:outer | i:inner + [r:right, l:left]) + (0:south | 1:west | 2:north | 3:east) :return: the intersection road """ lane_width = AbstractLane.DEFAULT_WIDTH right_turn_radius = lane_width + 5 # [m} left_turn_radius = right_turn_radius + lane_width # [m} outer_distance = right_turn_radius + lane_width / 2 access_length = 50 + 50 # [m] net = RoadNetwork() n, c, s = LineType.NONE, LineType.CONTINUOUS, LineType.STRIPED for corner in range(4): angle = np.radians(90 * corner) is_horizontal = corner % 2 priority = 3 if is_horizontal else 1 rotation = np.array([[np.cos(angle), -np.sin(angle)], [np.sin(angle), np.cos(angle)]]) # Incoming start = rotation @ np.array([lane_width / 2, access_length + outer_distance]) end = rotation @ np.array([lane_width / 2, outer_distance]) net.add_lane("o" + str(corner), "ir" + str(corner), StraightLane(start, end, line_types=[s, c], priority=priority, speed_limit=10)) # Right turn r_center = rotation @ (np.array([outer_distance, outer_distance])) net.add_lane("ir" + str(corner), "il" + str((corner - 1) % 4), CircularLane(r_center, right_turn_radius, angle + np.radians(180), angle + np.radians(270), line_types=[n, c], priority=priority, speed_limit=10)) # Left turn l_center = rotation @ (np.array([-left_turn_radius + lane_width / 2, left_turn_radius - lane_width / 2])) net.add_lane("ir" + str(corner), "il" + str((corner + 1) % 4), CircularLane(l_center, left_turn_radius, angle + np.radians(0), angle + np.radians(-90), clockwise=False, line_types=[n, n], priority=priority - 1, speed_limit=10)) # Straight start = rotation @ np.array([lane_width / 2, outer_distance]) end = rotation @ np.array([lane_width / 2, -outer_distance]) net.add_lane("ir" + str(corner), "il" + str((corner + 2) % 4), StraightLane(start, end, line_types=[s, n], priority=priority, speed_limit=10)) # Exit start = rotation @ np.flip([lane_width / 2, access_length + outer_distance], axis=0) end = rotation @ np.flip([lane_width / 2, outer_distance], axis=0) net.add_lane("il" + str((corner - 1) % 4), "o" + str((corner - 1) % 4), StraightLane(end, start, line_types=[n, c], priority=priority, speed_limit=10)) road = RegulatedRoad(network=net, np_random=self.np_random, record_history=self.config["show_trajectories"]) self.road = road def _make_vehicles(self, n_vehicles: int = 10) -> None: """ Populate a road with several vehicles on the highway and on the merging lane :return: the ego-vehicle """ # Configure vehicles vehicle_type = utils.class_from_path(self.config["other_vehicles_type"]) vehicle_type.DISTANCE_WANTED = 5 # Low jam distance vehicle_type.COMFORT_ACC_MAX = 6 vehicle_type.COMFORT_ACC_MIN = -3 # Random vehicles simulation_steps = 3 for t in range(n_vehicles - 1): self._spawn_vehicle(np.linspace(0, 80, n_vehicles)[t]) for _ in range(simulation_steps): [(self.road.act(), self.road.step(1 / self.config["simulation_frequency"])) for _ in range(self.config["simulation_frequency"])] # Challenger vehicle self._spawn_vehicle(60, spawn_probability=1, go_straight=True, position_deviation=0.1, speed_deviation=0) # Controlled vehicles self.controlled_vehicles = [] for ego_id in range(0, self.config["controlled_vehicles"]): ego_lane = self.road.network.get_lane(("o{}".format(ego_id % 4), "ir{}".format(ego_id % 4), 0)) destination = self.config["destination"] or "o" + str(self.np_random.randint(1, 4)) ego_vehicle = self.action_type.vehicle_class( self.road, ego_lane.position(60 + 5*self.np_random.normal(1), 0), speed=ego_lane.speed_limit, heading=ego_lane.heading_at(60)) try: ego_vehicle.plan_route_to(destination) ego_vehicle.speed_index = ego_vehicle.speed_to_index(ego_lane.speed_limit) ego_vehicle.target_speed = ego_vehicle.index_to_speed(ego_vehicle.speed_index) except AttributeError: pass self.road.vehicles.append(ego_vehicle) self.controlled_vehicles.append(ego_vehicle) for v in self.road.vehicles: # Prevent early collisions if v is not ego_vehicle and np.linalg.norm(v.position - ego_vehicle.position) < 20: self.road.vehicles.remove(v) def _spawn_vehicle(self, longitudinal: float = 0, position_deviation: float = 1., speed_deviation: float = 1., spawn_probability: float = 0.6, go_straight: bool = False) -> None: if self.np_random.uniform() > spawn_probability: return route = self.np_random.choice(range(4), size=2, replace=False) route[1] = (route[0] + 2) % 4 if go_straight else route[1] vehicle_type = utils.class_from_path(self.config["other_vehicles_type"]) vehicle = vehicle_type.make_on_lane(self.road, ("o" + str(route[0]), "ir" + str(route[0]), 0), longitudinal=(longitudinal + 5 + self.np_random.normal() * position_deviation), speed=8 + self.np_random.normal() * speed_deviation) for v in self.road.vehicles: if np.linalg.norm(v.position - vehicle.position) < 15: return vehicle.plan_route_to("o" + str(route[1])) vehicle.randomize_behavior() self.road.vehicles.append(vehicle) return vehicle def _clear_vehicles(self) -> None: is_leaving = lambda vehicle: "il" in vehicle.lane_index[0] and "o" in vehicle.lane_index[1] \ and vehicle.lane.local_coordinates(vehicle.position)[0] \ >= vehicle.lane.length - 4 * vehicle.LENGTH self.road.vehicles = [vehicle for vehicle in self.road.vehicles if vehicle in self.controlled_vehicles or not (is_leaving(vehicle) or vehicle.route is None)] def has_arrived(self, vehicle: Vehicle, exit_distance: float = 25) -> bool: return "il" in vehicle.lane_index[0] \ and "o" in vehicle.lane_index[1] \ and vehicle.lane.local_coordinates(vehicle.position)[0] >= exit_distance哦,都要一个可视化是吧?来了来了。
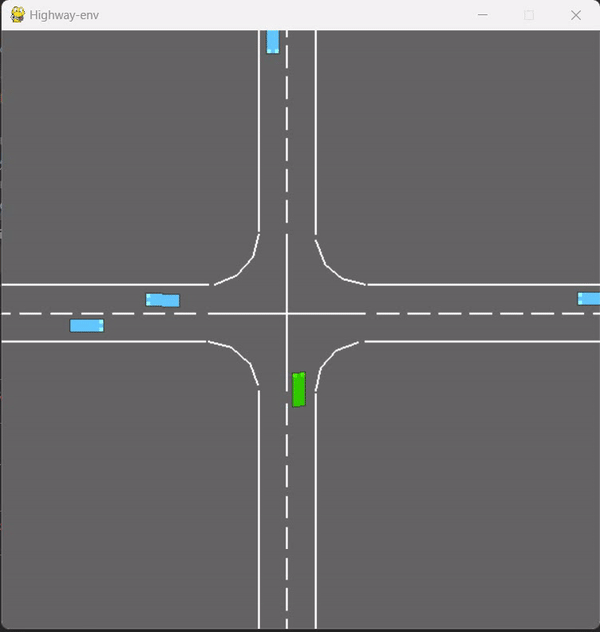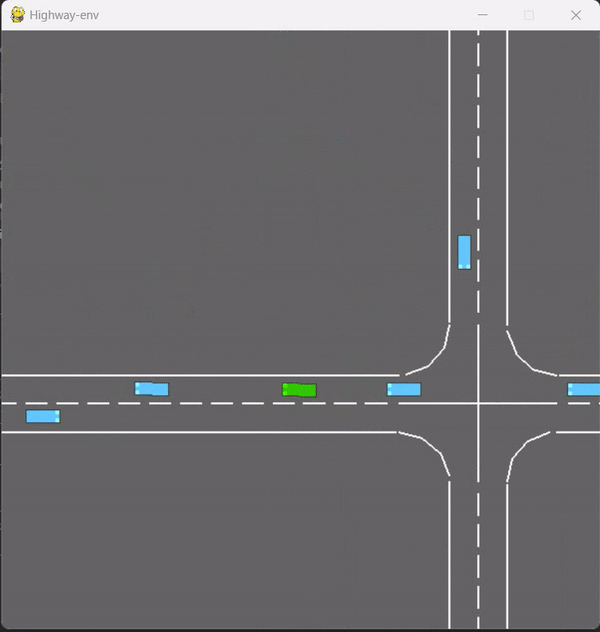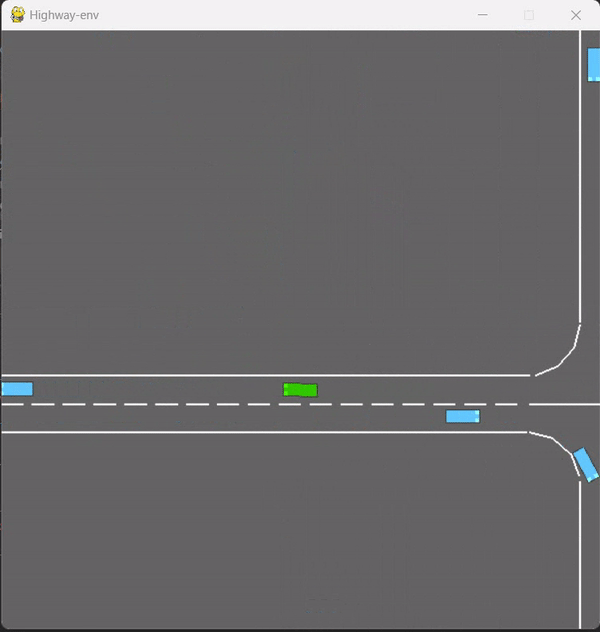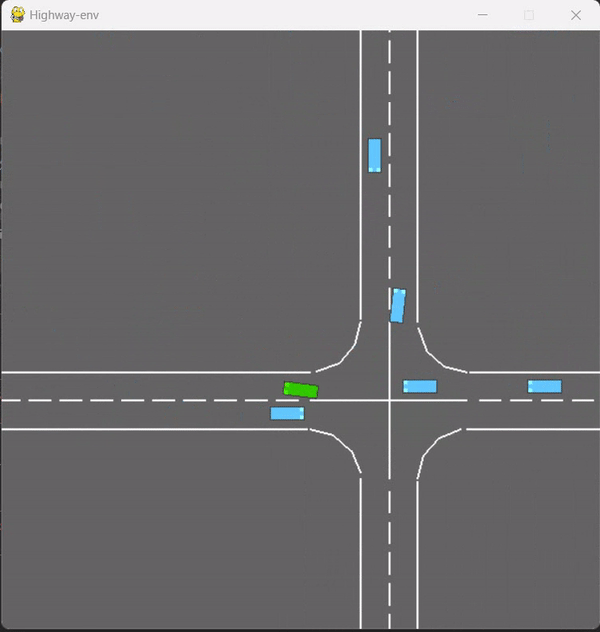
在test-v0下,用double_dqn.py训练的图:(action_dim==5)
目前是单智能体,后续的多智能体需要调整输入的数据和动作,以及控制小车的数量,做为后续的待定改进点。
其他?等我写好 多智能体 0-0!
待好心人补充....毕竟这里是无人区啊(悲)

终有一日,我会成为神一样的提纳里先生!