Java8提供了Stream(流)处理集合的关键抽象概念,它可以对集合进行操作,可以执行非常复杂的查找、过滤和映射数据等操作。Stream API 借助于同样新出现的Lambda表达式,极大的提高编程效率和程序可读性。
下面是使用Stream的常用方法的综合实例。
创建User类作为持久层。
import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;import java.math.BigDecimal;@Data@AllArgsConstructor@NoArgsConstructorpublic class User { int id; String name; String sex; int age; String Department; BigDecimal Salary;}创建UserService.class(用户信息业务逻辑类)。
package com.wsq;import com.wsq.pojo.User;import java.math.BigDecimal;import java.util.ArrayList;import java.util.List;/* * 用户信息业务逻辑类 * @author wsq */public class UserService { /* * 获取用户列表 */ public static List<User> getUserList() { List<User> userList = new ArrayList<User>(); userList.add(new User(1, "wsq的博客_01", "男", 32, "研发部", BigDecimal.valueOf(1600))); userList.add(new User(2, "wsq的博客_02", "男", 30, "财务部", BigDecimal.valueOf(1800))); userList.add(new User(3, "wsq的博客_03", "女", 20, "人事部", BigDecimal.valueOf(1700))); userList.add(new User(4, "wsq的博客_04", "男", 38, "研发部", BigDecimal.valueOf(1500))); userList.add(new User(5, "wsq的博客_05", "女", 25, "财务部", BigDecimal.valueOf(1200))); return userList; }}一、查询方法
1.1 forEach()
使用 forEach() 遍历列表数据。
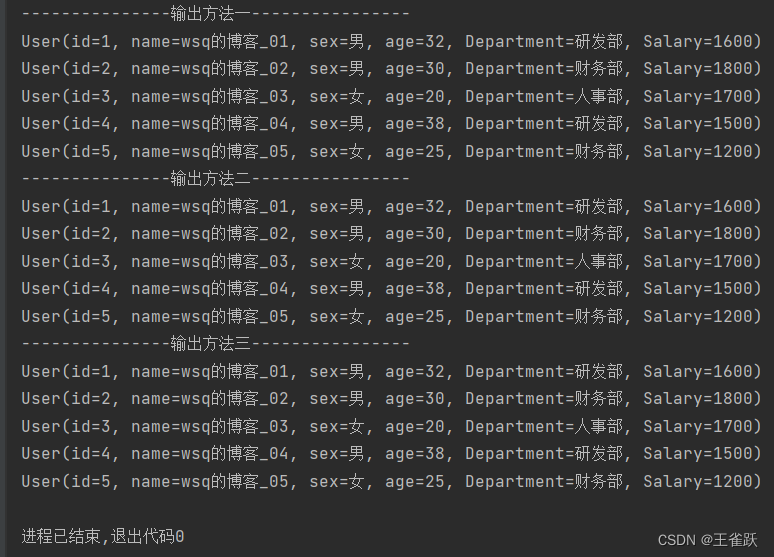
/* * 使用forEach()遍历列表信息 * @author wsq */@Testpublic void forEachTest(){ //获取用户列表 List<User> userList = UserService.getUserList(); //遍历用户列表 System.out.println("---------------输出方法一-----------------"); userList.forEach(user -> {System.out.println(user);}); System.out.println("---------------输出方法二-----------------"); userList.forEach(System.out::println);}控制台输出:
1.2 filter(T -> boolean)
使用 filter() 过滤列表数据。
【示例】获取部门为“研发部”的用户列表。
/* * 使用filter()过滤列表信息 * @author wsq */@Testpublic void filterTest(){ //获取用户列表 List<User> userList = UserService.getUserList(); //获取部门为“研发部”的用户列表 userList = userList.stream().filter(user -> user.getDepartment() == "研发部").collect(Collectors.toList()); //遍历用户列表 userList.forEach(System.out::println);}控制台输出:

1.3 findAny() 和 findFirst()
使用 findAny() 和 findFirst() 获取第一条数据。
【示例】获取用户名称为“wsq的博客_02”的用户信息,如果未找到则返回null。
/* * 使用findAny()获取第一条数据 * @author wsq */@Testpublic void findAnytTest(){ //获取用户列表 List<User> userList = UserService.getUserList(); //获取用户名称为“pan_junbiao的博客_02”的用户信息,如果没有找到则返回null User user = userList.stream().filter(u -> u.getName().equals("wsq的博客_02")).findAny().orElse(null); //打印用户信息 System.out.println(user);}控制台输出:

注意:findFirst() 和 findAny() 都是获取列表中的第一条数据,但是findAny()操作,返回的元素是不确定的,对于同一个列表多次调用findAny()有可能会返回不同的值。使用findAny()是为了更高效的性能。如果是数据较少,串行地情况下,一般会返回第一个结果,如果是并行(parallelStream并行流)的情况,那就不能确保是第一个。
例如:使用parallelStream并行流,findAny() 返回的就不一定是第一条数据。
//parallelStream方法能生成并行流,使用findAny返回的不一定是第一条数据User user = userList.parallelStream().filter(u -> u.getName().startsWith("wsq")).findAny().orElse(null);1.4 map(T -> R) 和 flatMap(T -> Stream)
使用 map() 将流中的每一个元素 T 映射为 R(类似类型转换)。
使用 flatMap() 将流中的每一个元素 T 映射为一个流,再把每一个流连接成为一个流。
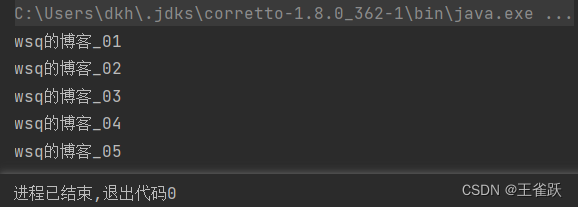
【示例】使用 map() 方法获取用户列表中的名称列。
/* * 使用map()获取列元素 * @author wsq */@Testpublic void mapTest(){ //获取用户列表 List<User> userList = UserService.getUserList(); //获取用户名称列表 List<String> nameList = userList.stream().map(User::getName).collect(Collectors.toList()); //或者:List<String> nameList = userList.stream().map(user -> user.getName()).collect(Collectors.toList()); //遍历名称列表 nameList.forEach(System.out::println);}控制台输出:
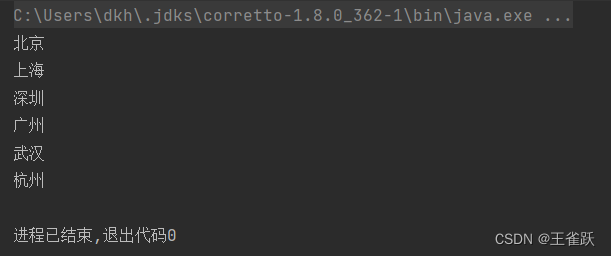
【示例】使用 flatMap() 将流中的每一个元素连接成为一个流。
/* * 使用flatMap()将流中的每一个元素连接成为一个流 * @author wsq */@Testpublic void flatMapTest(){ //创建城市 List<String> cityList = new ArrayList<String>(); cityList.add("北京;上海;深圳;"); cityList.add("广州;武汉;杭州;"); //分隔城市列表,使用 flatMap() 将流中的每一个元素连接成为一个流。 cityList = cityList.stream() .map(city -> city.split(";")) .flatMap(Arrays::stream) .collect(Collectors.toList()); //遍历城市列表 cityList.forEach(System.out::println);}控制台输出:
1.5 distinct()
使用 distinct() 方法可以去除重复的数据。
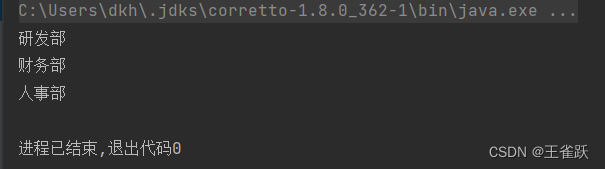
【示例】获取部门列表,并去除重复数据。
/** * 使用distinct()去除重复数据 * @author wsq */@Testpublic void distinctTest(){ //获取用户列表 List<User> userList = UserService.getUserList(); //获取部门列表,并去除重复数据 List<String> departmentList = userList.stream().map(User::getDepartment).distinct().collect(Collectors.toList()); //遍历部门列表 departmentList.forEach(System.out::println);}控制台输出:
1.6 limit(long n) 和 skip(long n)
limit(long n) 方法用于返回前n条数据,skip(long n) 方法用于跳过前n条数据。
【示例】获取用户列表,要求跳过第1条数据后的前3条数据。
/* * limit(long n)方法用于返回前n条数据 * skip(long n)方法用于跳过前n条数据 * @author wsq */@Testpublic void limitAndSkipTest(){ //获取用户列表 List<User> userList = UserService.getUserList(); //获取用户列表,要求跳过第1条数据后的前3条数据 userList = userList.stream() .skip(1) .limit(3) .collect(Collectors.toList()); //遍历用户列表 userList.forEach(System.out::println);}控制台输出:
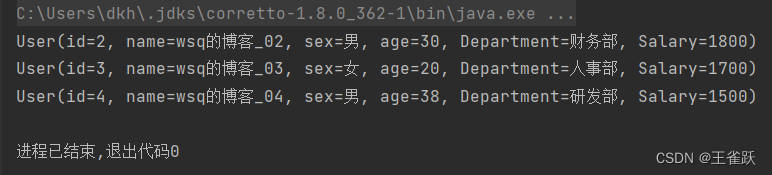
二、判断方法
2.1 anyMatch(T -> boolean)
使用 anyMatch(T -> boolean) 判断流中是否有一个元素匹配给定的 T -> boolean 条件。
2.2 allMatch(T -> boolean)
使用 allMatch(T -> boolean) 判断流中是否所有元素都匹配给定的 T -> boolean 条件。
2.3 noneMatch(T -> boolean)
使用 noneMatch(T -> boolean) 流中是否没有元素匹配给定的 T -> boolean 条件。
【示例】使用 anyMatch()、allMatch()、noneMatch() 进行判断。
/* * 使用 anyMatch()、allMatch()、noneMatch() 进行判断 * @author wsq */@Testpublic void matchTest(){ //获取用户列表 List<User> userList = UserService.getUserList(); //判断用户列表中是否存在名称为“pan_junbiao的博客_01”的数据 boolean result1 = userList.stream().anyMatch(user -> user.getName().equals("pan_junbiao的博客_01")); //判断用户名称是否都包含“pan_junbiao的博客”字段 boolean result2 = userList.stream().allMatch(user -> user.getName().contains("pan_junbiao的博客")); //判断用户名称是否存在不包含“pan_junbiao的博客”字段 boolean result3 = userList.stream().noneMatch(user -> user.getName().contains("pan_junbiao的博客")); //打印结果 System.out.println(result1); System.out.println(result2); System.out.println(result3);}控制台输出:
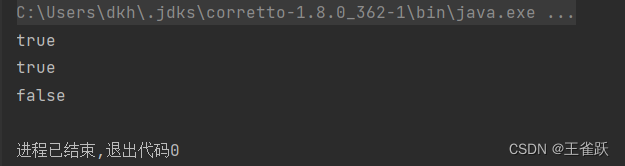
三、统计方法
3.1 reduce((T, T) -> T) 和 reduce(T, (T, T) -> T)
使用 reduce((T, T) -> T) 和 reduce(T, (T, T) -> T) 用于组合流中的元素,如求和,求积,求最大值等。
【示例】使用 reduce() 求用户列表中年龄的最大值、最小值、总和。
/* * 使用 reduce() 方法 * @author wsq */@Testpublic void reduceTest(){ //获取用户列表 List<User> userList = UserService.getUserList(); //用户列表中年龄的最大值、最小值、总和 int maxVal = userList.stream().map(User::getAge).reduce(Integer::max).get(); int minVal = userList.stream().map(User::getAge).reduce(Integer::min).get(); int sumVal = userList.stream().map(User::getAge).reduce(0,Integer::sum); //打印结果 System.out.println("最大年龄:" + maxVal); System.out.println("最小年龄:" + minVal); System.out.println("年龄总和:" + sumVal);}控制台输出:
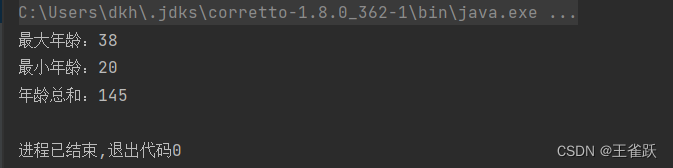
3.2 mapToInt(T -> int) 、mapToDouble(T -> double) 、mapToLong(T -> long)
int sumVal = userList.stream().map(User::getAge).reduce(0,Integer::sum);计算元素总和的方法其中暗含了装箱成本,map(User::getAge) 方法过后流变成了 Stream 类型,而每个 Integer 都要拆箱成一个原始类型再进行 sum 方法求和,这样大大影响了效率。针对这个问题 Java 8 有良心地引入了数值流 IntStream, DoubleStream, LongStream,这种流中的元素都是原始数据类型,分别是 int,double,long。
流转换为数值流:
mapToInt(T -> int) : return IntStreammapToDouble(T -> double) : return DoubleStreammapToLong(T -> long) : return LongStream【示例】使用 mapToInt() 求用户列表中年龄的最大值、最小值、总和、平均值。
/* * 使用 mapToInt() 方法 * @author wsq */@Testpublic void mapToIntTest(){ //获取用户列表 List<User> userList = UserService.getUserList(); //用户列表中年龄的最大值、最小值、总和、平均值 int maxVal = userList.stream().mapToInt(User::getAge).max().getAsInt(); int minVal = userList.stream().mapToInt(User::getAge).min().getAsInt(); int sumVal = userList.stream().mapToInt(User::getAge).sum(); double aveVal = userList.stream().mapToInt(User::getAge).average().getAsDouble(); //打印结果 System.out.println("最大年龄:" + maxVal); System.out.println("最小年龄:" + minVal); System.out.println("年龄总和:" + sumVal); System.out.println("平均年龄:" + aveVal);}控制台输出:
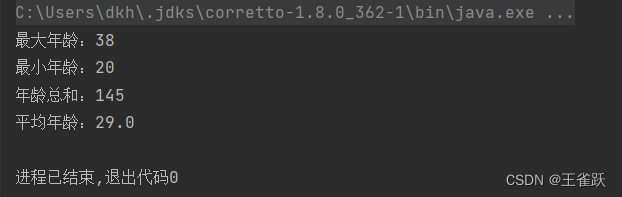
3.3 counting() 和 count()
使用 counting() 和 count() 可以对列表数据进行统计。
【示例】使用 count() 统计用户列表信息。
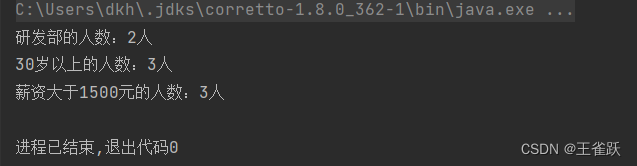
/* * 使用 counting() 或 count() 统计 * @author wsq */@Testpublic void countTest(){ //获取用户列表 List<User> userList = UserService.getUserList(); //统计研发部的人数,使用 counting()方法进行统计 Long departCount = userList.stream().filter(user -> user.getDepartment() == "研发部").collect(Collectors.counting()); //统计30岁以上的人数,使用 count()方法进行统计(推荐) Long ageCount = userList.stream().filter(user -> user.getAge() >= 30).count(); //统计薪资大于1500元的人数 Long salaryCount = userList.stream().filter(user -> user.getSalary().compareTo(BigDecimal.valueOf(1500)) == 1).count(); //打印结果 System.out.println("研发部的人数:" + departCount + "人"); System.out.println("30岁以上的人数:" + ageCount + "人"); System.out.println("薪资大于1500元的人数:" + salaryCount + "人");}控制台输出:
3.4 summingInt()、summingLong()、summingDouble()
用于计算总和,需要一个函数参数。
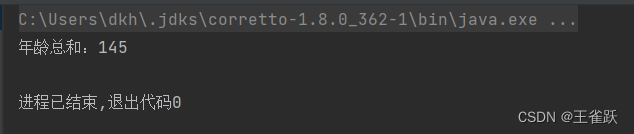
/* * 使用 summingInt()、summingLong()、summingDouble() * @author wsq */@Testpublic void sumTest(){ //获取用户列表 List<User> userList = UserService.getUserList(); //计算年龄总和 int sumAge = userList.stream().collect(Collectors.summingInt(User::getAge)); //打印结果 System.out.println("年龄总和:" + sumAge);}控制台输出:
3.5 averagingInt()、averagingLong()、averagingDouble()
用于计算平均值。
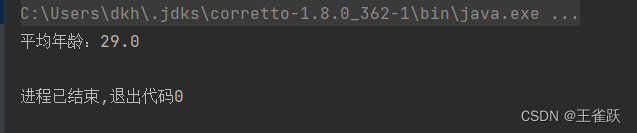
/* * 使用 summingInt()、summingLong()、summingDouble() * @author wsq */@Testpublic void sumTest(){ //获取用户列表 List<User> userList = UserService.getUserList(); //计算平均年龄 double aveAge = userList.stream().collect(Collectors.averagingDouble(User::getAge)); //打印结果 System.out.println("平均年龄:" + aveAge);}控制台输出:
3.6 summarizingInt()、summarizingLong()、summarizingDouble()
这三个方法比较特殊,比如 summarizingInt 会返回 IntSummaryStatistics 类型。
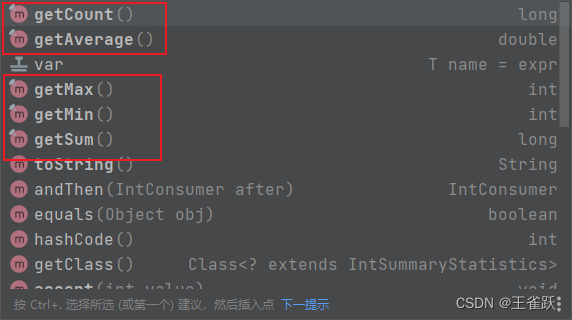
IntSummaryStatistics类提供了用于计算的平均值、总数、最大值、最小值、总和等方法,方法如下图:
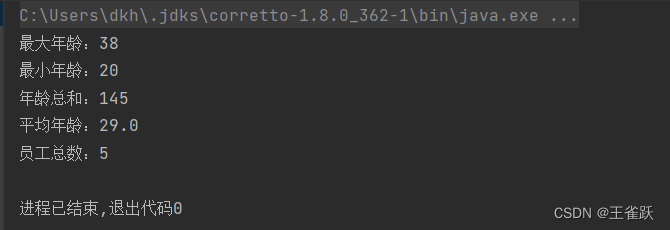
【示例】使用 IntSummaryStatistics 统计:最大值、最小值、总和、平均值、总数。
/* * 使用 summarizingInt 统计 * @author wsq */@Testpublic void summarizingIntTest(){ //获取用户列表 List<User> userList = UserService.getUserList(); //获取IntSummaryStatistics对象 IntSummaryStatistics ageStatistics = userList.stream().collect(Collectors.summarizingInt(User::getAge)); //统计:最大值、最小值、总和、平均值、总数 System.out.println("最大年龄:" + ageStatistics.getMax()); System.out.println("最小年龄:" + ageStatistics.getMin()); System.out.println("年龄总和:" + ageStatistics.getSum()); System.out.println("平均年龄:" + ageStatistics.getAverage()); System.out.println("员工总数:" + ageStatistics.getCount());}控制台输出:
3.7 BigDecimal类型的统计
对于资金相关的字段,通常会使用BigDecimal数据类型。
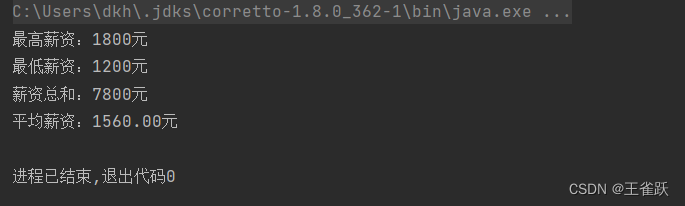
【示例】统计用户薪资信息。
/* * BigDecimal类型的统计 * @author wsq */@Testpublic void BigDecimalTest(){ //获取用户列表 List<User> userList = UserService.getUserList(); //最高薪资 BigDecimal maxSalary = userList.stream().map(User::getSalary).max((x1, x2) -> x1.compareTo(x2)).get(); //最低薪资 BigDecimal minSalary = userList.stream().map(User::getSalary).min((x1, x2) -> x1.compareTo(x2)).get(); //薪资总和 BigDecimal sumSalary = userList.stream().map(User::getSalary).reduce(BigDecimal.ZERO, BigDecimal::add); //平均薪资 BigDecimal avgSalary = userList.stream().map(User::getSalary).reduce(BigDecimal.ZERO, BigDecimal::add).divide(BigDecimal.valueOf(userList.size()), 2, BigDecimal.ROUND_HALF_UP); //打印统计结果 System.out.println("最高薪资:" + maxSalary + "元"); System.out.println("最低薪资:" + minSalary + "元"); System.out.println("薪资总和:" + sumSalary + "元"); System.out.println("平均薪资:" + avgSalary + "元");}控制台输出:
四、排序方法
4.1 sorted() / sorted((T, T) -> int)
如果流中的元素的类实现了 Comparable 接口,即有自己的排序规则,那么可以直接调用 sorted() 方法对元素进行排序,如 Stream。反之, 需要调用 sorted((T, T) -> int) 实现 Comparator 接口。
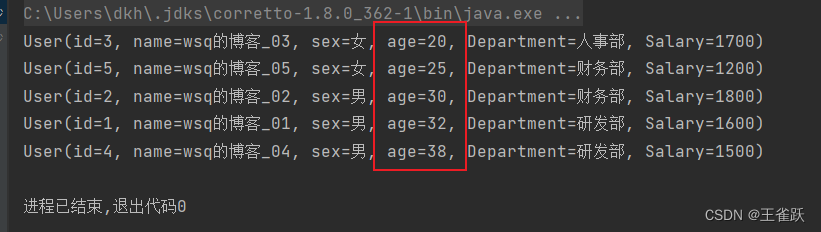
【示例】根据用户年龄进行排序。
/* * 使用 sorted() 排序 * @author wsq */@Testpublic void sortedTest(){ //获取用户列表 List<User> userList = UserService.getUserList(); //根据年龄排序(升序) userList = userList.stream().sorted((u1, u2) -> u1.getAge() - u2.getAge()).collect(Collectors.toList()); //推荐:userList = userList.stream().sorted(Comparator.comparingInt(User::getAge)).collect(Collectors.toList()); //降序:userList = userList.stream().sorted(Comparator.comparingInt(User::getAge).reversed()).collect(Collectors.toList()); //遍历用户列表 userList.forEach(System.out::println);}控制台输出:
五、分组方法
5.1 groupingBy
使用 groupingBy() 将数据进行分组,最终返回一个 Map 类型。
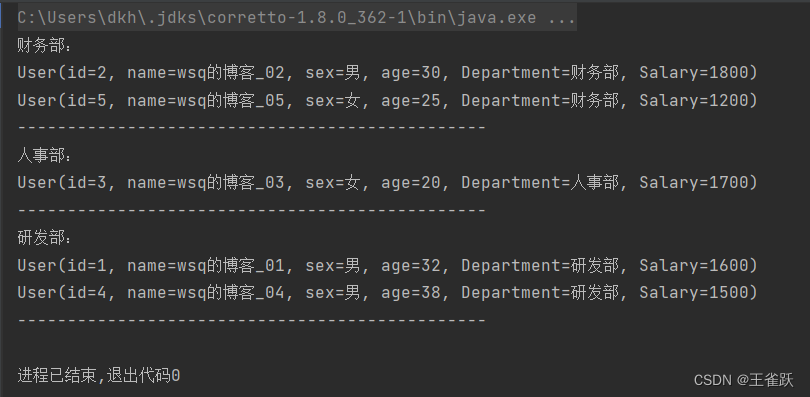
【示例】根据部门对用户列表进行分组。
/* * 使用 groupingBy() 分组 * @author wsq */@Testpublic void groupingByTest(){ //获取用户列表 List<User> userList = UserService.getUserList(); //根据部门对用户列表进行分组 Map<String,List<User>> userMap = userList.stream().collect(Collectors.groupingBy(User::getDepartment)); //遍历分组后的结果 userMap.forEach((key, value) -> { System.out.println(key + ":"); value.forEach(System.out::println); System.out.println("---------------------------------------------"); });}控制台输出:
5.2 多级分组
groupingBy 可以接受一个第二参数实现多级分组。
【示例】根据部门和性别对用户列表进行分组。
/* * 使用 groupingBy() 多级分组 * @author wsq */@Testpublic void multGroupingByTest(){ //获取用户列表 List<User> userList = UserService.getUserList(); //根据部门和性别对用户列表进行分组 Map<String,Map<String,List<User>>> userMap = userList.stream() .collect(Collectors.groupingBy(User::getDepartment,Collectors.groupingBy(User::getSex))); //遍历分组后的结果 userMap.forEach((key1, map) -> { System.out.println(key1 + ":"); map.forEach((key2,user)-> { System.out.println(key2 + ":"); user.forEach(System.out::println); }); System.out.println("-------------------------------------------------------"); });}控制台输出:
5.3 分组汇总
【示例】根据部门进行分组,汇总各个部门用户的平均年龄。
/* * 使用 groupingBy() 分组汇总 * @author wsq */@Testpublic void groupCollectTest(){ //获取用户列表 List<User> userList = UserService.getUserList(); //根据部门进行分组,汇总各个部门用户的平均年龄 Map<String, Double> userMap = userList.stream().collect(Collectors.groupingBy(User::getDepartment, Collectors.averagingInt(User::getAge))); //遍历分组后的结果 userMap.forEach((key, value) -> { System.out.println(key + "的平均年龄:" + value); });}控制台输出: