如果要问最近模型领域什么东西最火,应该非扩散模型莫属,火得我觉得不系统学习一下都不行!
本文是我的学习笔记,只能叫入门文章,因为扩散模型的严谨数学推导公式很多,还没有研究透彻,不敢说一文吃透扩散模型。此文适合对生成模型有一些了解,要整体理解什么是扩散模型、模型原理、应用在什么地方的同学。
1
扩散模型能干啥
扩散模型火起来主要原因是在图像生成领域,多个著名的从文本到图像生成应用都使用了扩散模型,如果你听说过某个著名的应用能又快又好地生成了很逼真的图像,估计就是下面3个中的一个:
OpenAI的DALL·E 2
Google的Imagen
最近搞AI开源影响很大的StabilityAI开发的Stable Diffusion
下面是我在Stable Diffusion中输入“mouse is playing guitar”生成图片的例子,花了25秒,效果不错,关键还是免费的效果。我也尝试了在中文版网站输入中文,但网页没反应,估计系统暂时有问题。

除了计算机视觉领域,扩散模型在NLP、波形信号处理、多模态建模、分子图建模、时间序列建模、对抗性净化等领域都有广泛应用(有兴趣的参见扩散模型综述 https://arxiv.org/abs/2209.00796)。
扩散模型是生成模型的一种,为了有一个全局的视角,我们要回顾一下业界已经成熟的典型的两种生成模型--GAN和VAE,然后再来看扩散模型。
2
生成模型回顾--生成对抗网络GAN
生成模型简单点说就是生成数据的模型,不管生成的是图像、文本、声音还是其他数据。通常情况下我们希望生成的数据的分布能逼近某个场景中真实数据的分布。
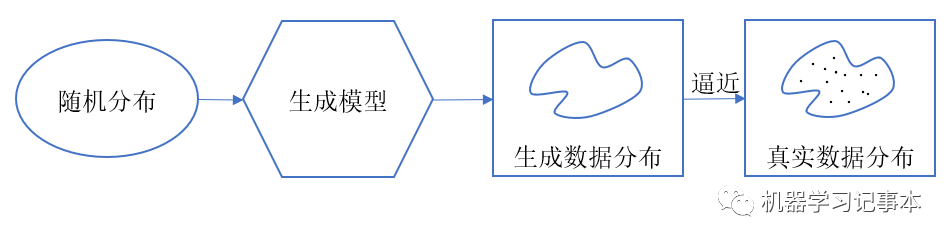
生成对抗网络GAN在生成模型中占有重要一席,我在生成对抗网络GAN系列之一:基本原理和结构细讲一文中有详细讲解,本文只概括描述一下。
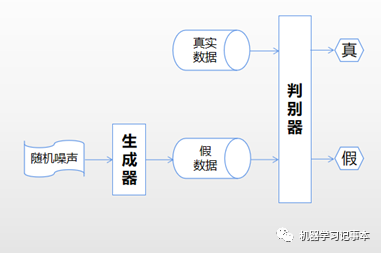
整个网络包含一个生成器和一个判别器。生成器通过输入的随机噪声生成假数据,希望能模仿真实数据。判别器输入有两部分,一是真实数据,二是生成器生成的假数据,判别器的目标就是尽可能分辨出哪些是真数据,哪些是假数据。训练好生成器后,就可以用生成器来生成数据了。
3
生成模型回顾--变分自编码器VAE
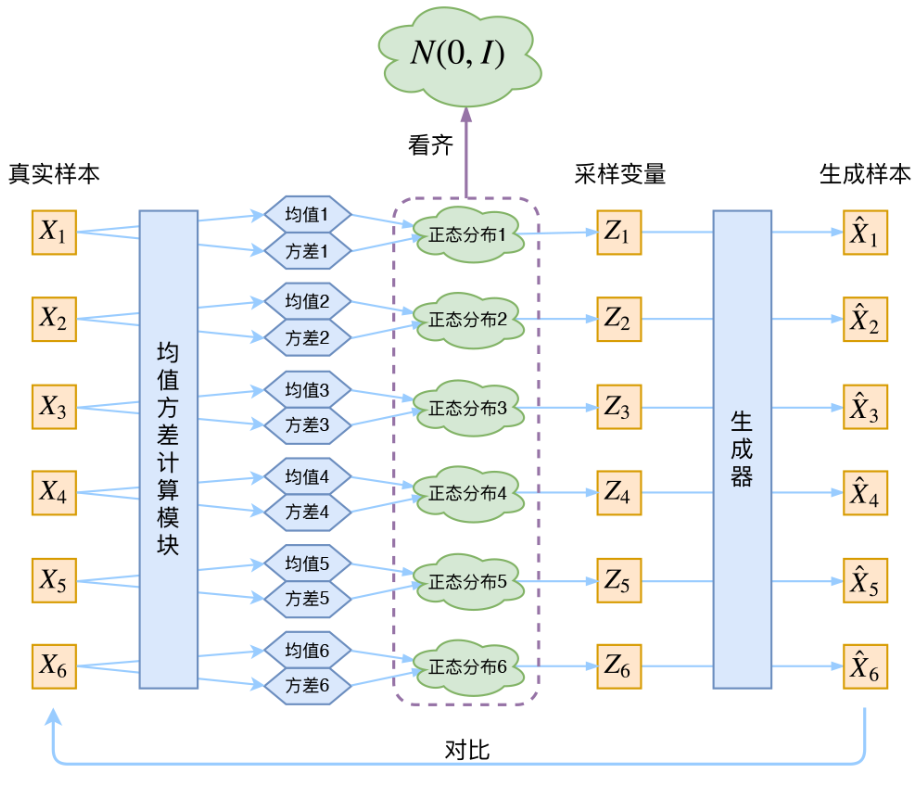
要说生成模型,不得不说变分自编码器VAE,网上大家学习用得最多的还是苏剑林苏神这张图。
简要描述整个训练过程就是:假设真实样本符合正态分布,对真实样本
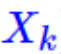
学其分布,就是学习均值和方差,怎么学习呢,神经网络就是一种方法,知道了分布,就可以采样到对应的,再对训练个生成器,输入,生成,让和尽可能接近。要生成数据的时候,根据学习到的分布随机采样,输入生成器即可生成接近真实样本的数据。要进一步学习细节请移步苏神文章。
4
扩散模型原理
上面回顾了GAN和VAE,其实也是为了在其基础上平滑过渡到对扩散模型的理解。
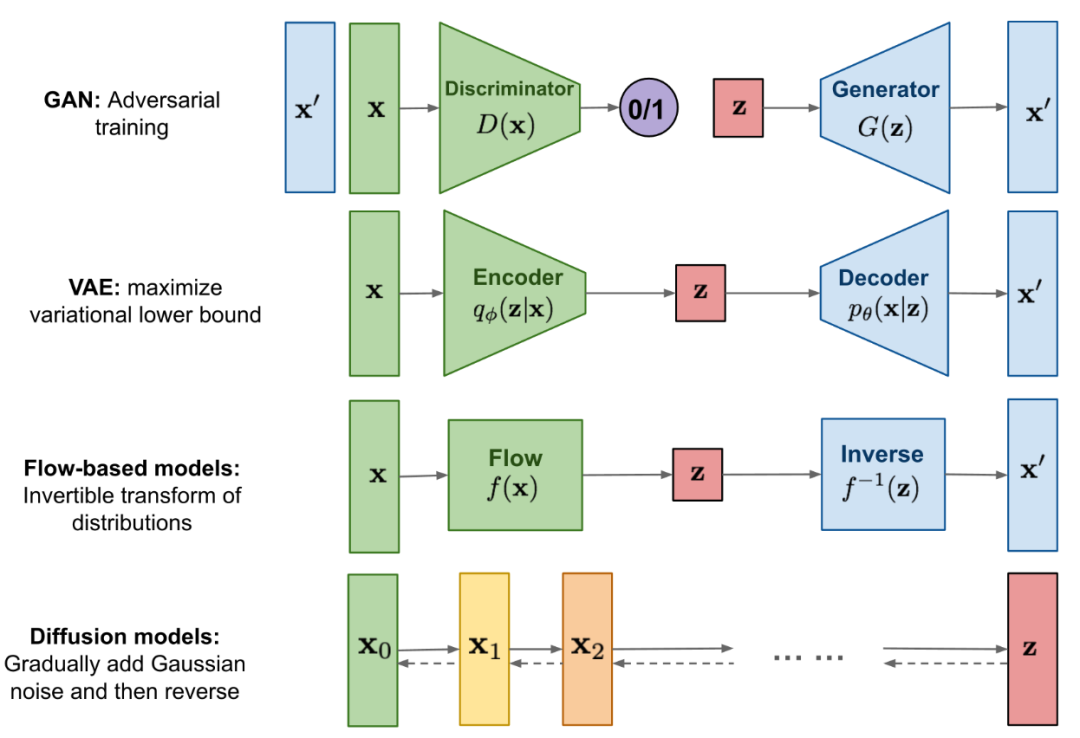
上图是各种资料中常引用来比较GAN、VAE、Flow-based、Diffusion模型的一个经典图,Flow-based模型我没有研究过,直接从GAN、VAE说起,不妨碍我们的理解。
GAN就是粗暴地用神经网络训练生成器和判别器,来学习真实数据的分布,可解释性差,反正就是学出来了,训练时很容易出现不稳定问题。
VAE比起GAN明确要学习数据的分布(Encoder做的),即均值和方差,有了可解释性,然后基于学习到的分布采样到的数据训练生成器(Decoder)。本质上,VAE的Encoder就是对真实数据进行加噪,其一部分学均值,尽量接近0,另一部分学方差,尽量接近1,目的是为了采集到的Z符合标准正态分布N(0,1),方差就描述了加的高斯噪声的强弱。Decoder在加了高斯噪声的数据上解码,相当于去掉噪声恢复真实数据的作用。所以,一句话总结,VAE通过Encoder加噪和Decoder去噪学习来生成数据。
重点来了,开始过渡到扩散模型。VAE已经有很好的理论可解释性了,但有个问题是Encoder一大步就学了的数据分布进行加噪,Decoder又是一大步解码去噪,步子跨得大,就容易扯到蛋,导致学习得不够细腻,那如何能学得细腻点呢?这就是扩散模型干的事:前向一小步一小步地加噪,逆向一小步一小步地去噪。注意,这个逆向指的是逆向还原数据,不要误解成反向梯度计算,所以我特意用逆向,不用反向。
具体的前向和逆向实现最有名的模型是2020年提出的DDPM(Denoising Diffusion Probabilistic Models)。前向T步对真实数据添加高斯噪声,
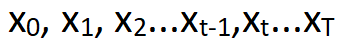
,每个时刻t只和t-1时刻有关,所以可以看着是一个马尔可夫过程。逆向过程也对应T步,大佬们已经从理论上证明逆向过程的每一步也是高斯分布,如果能得到这些分布,那么输入一个高斯噪声,就能通过逆向的T步生成像真实数据的数据了。但是如何得到这T步逆向的分布,很难!很难的东西,我们就用神经网络来学习!
不知道到了这儿,你对扩散模型的基本原理有没有理解,更准确点说,是我有没有讲明白,就是一个增强版的VAE。
5
如何训练和推理
既然本文叫入门文章,我有些犹豫要不要加入数学公式,本来我是不想加的。最近学习扩散模型看了好多知乎大佬的解释,光苏剑林就写了13篇文章漫谈扩散模型,每一篇里都有好多数学公式推理,并不是所有公式都搞懂了,但对DDPM的基本逻辑还是看懂了的。
就算是入门文章,也得说明白模型是如何训练和推理的,要说明这个,无法避免得使用点公式,这篇知乎文章https://zhuanlan.zhihu.com/p/566618077是目前我发现公式使用程度拿捏得最好的,以下对于训练和推理的内容主要参考这篇文章。先说下前向、逆向的具体计算。
前向计算,由t-1时刻计算t时刻值:
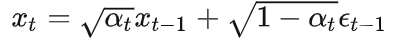
其中
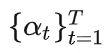
是预先设定好的超参数,是高斯噪声,由t到t-1的不断迭代,可以得到,其中,也是一个随机高斯噪声,于是t时刻的值可以由0时刻初始值计算得到。具体迭代有一堆推导,此处省略。
逆向计算,由t时刻计算t-1时刻值:
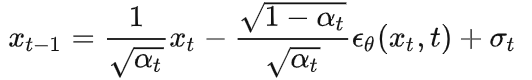
其中
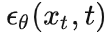
是由和t估计的噪声,是模型超参,是高斯噪声。
好了,前向不断计算加上噪声,逆向不断计算去掉噪声,模型训练的目标就是让每步加的用来搞破环的噪声
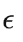
和通过模型学习相近,越相近,去噪越好,得到的数据越像真实数据。具体的损失函数:
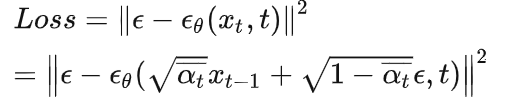
所以原始论文中训练的算法过程描述:

通过模型训练学习到了
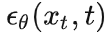
,推理(由噪声生成想要的数据)就简单了,从N(0,1)中随机生成一个噪声,循环T步逐步去噪,就从噪声恢复得到了,算法描述为:

终于可以松一口气,算法描述就这些了。有同学可能会问,随机生成一个噪声得到一个像真实数据的数据
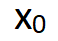
有啥意义呢,这就和GAN里面一样,我们可以加入具体条件要求,比如由文本生成图像,条件要求就是输入的文本。
扩散模型学得更细腻了,需要更多的采样步骤,所以训练时间也增加了,不少研究者都在想办法改进减小训练时间。
6
一个具体例子--Stable Diffusion
理解一种算法,很重要目的是为了落地应用,否则只是飘在空中不踏实,所以我们以Stable Diffusion模型来看看扩散模型究竟是怎么落地实现的。以下内容参考自https://jalammar.github.io/illustrated-stable-diffusion/。
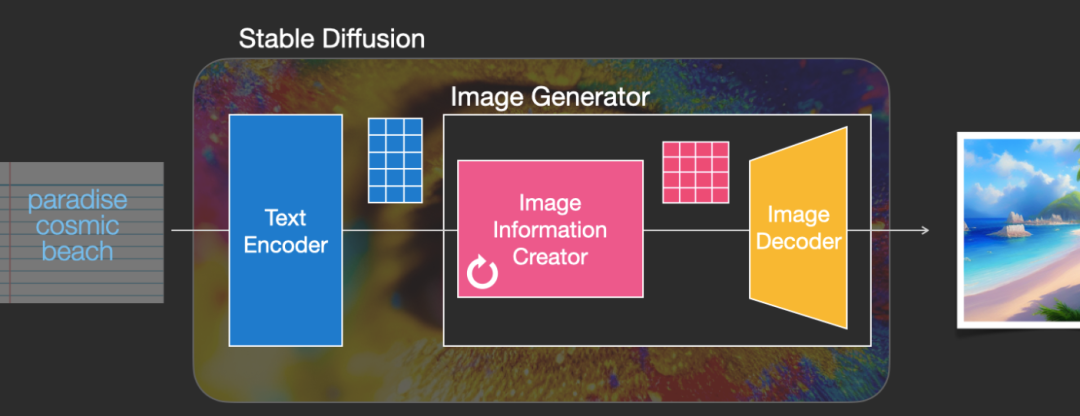
Stable Diffusion的总体结构

总体结构很清晰,输入一段文字,通过Stable Diffusion输出这段文字描述的一张图片,比如上图输入“极乐美丽的沙滩”,输出就是这么一张美丽的沙滩图片。模型由两个组件构成,一是Encoder把文字转换为对应的embedding/representation,这个是NLP文本处理的常规操作,有了文本的embedding,第二个组件Image Generator把这个embedding转换生成图片。论文中说,使用较大的语言模型生成更好的embedding对生成的图像质量的影响大于使用较大的图像生成组件。
再把Image Generator掰开,由两个部分组成,这也是为啥其左变为粉色,右边为黄色。粉色部分为图像信息创建器Image Information Creator,黄色部分图像解码器用于生成图片。
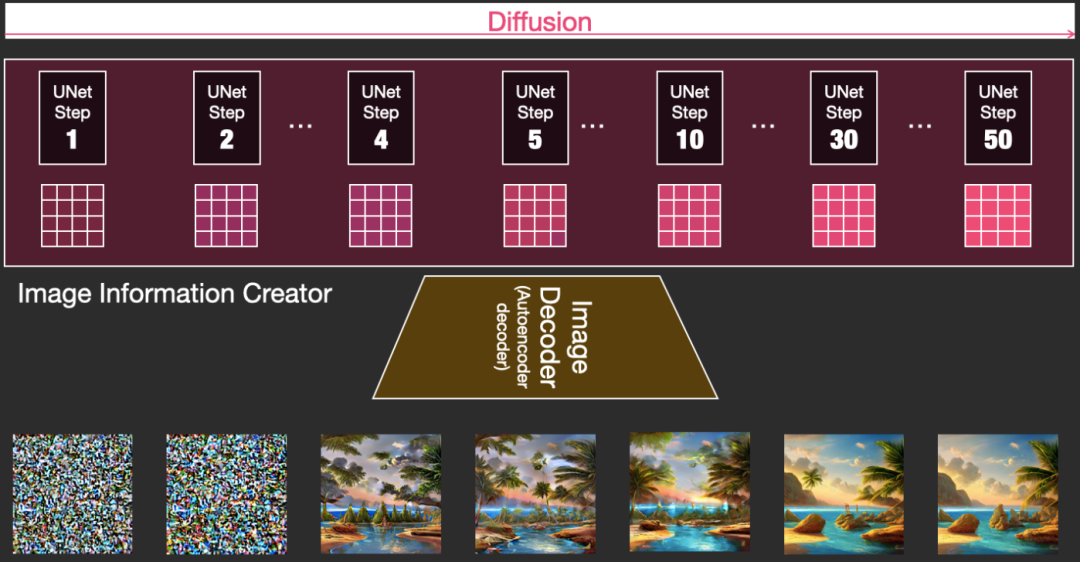
为啥叫Stable Diffusion,重点是Diffusion,其体现在Image Information Creator中,包含了一个扩散过程,神经网络使用了UNet结构。
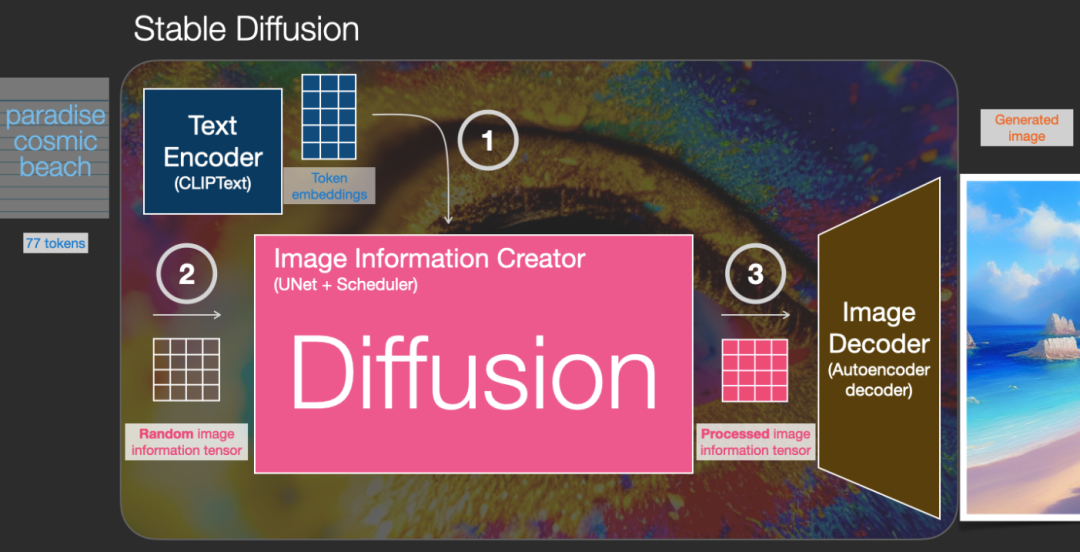
具体扩散过程如下,由50步UNet扩散步骤组成。结合我们本文扩散模型的知识,先随机产生一个噪声数据,加上文本embedding的条件,经过50步的扩散去噪过程,最终就能生成满足文本要求的图片数据。图片数据通过Image Decoder解码器生成图片就不是重点了。

下图是扩散过程50步中逐步去掉噪声生成的图片信息,用图片解码器生成对应图片的直观效果,这个过程和最后生成的效果简直可以用惊艳形容。
7
总结
本文从扩散模型能干啥的直观了解开始,从典型的生成模型GAN、VAE一步一步过渡到扩散模型的基本原理,然后更进一步到其前向、逆向计算,以及如何训练和推理,最后以Stable Diffusion为例看扩散模型如何落地使用。我自己在这个学习过程中有了一个全局的了解,希望你也能有同样的收获。