
欢迎交流学习~~
专栏: Python学习笔记
Python学习系列:
Python | 基础入门篇Part01——注释、数据类型、运算符、字符串
Python | 基础入门篇Part02——判断语句、循环语句、函数初步
Python | 基础入门篇Part03——数据容器
八、数据容器8.1 列表8.2 元组8.3 字符串8.4 序列的切片8.5 集合8.6 字典
八、数据容器
前面我们已经提到过数据元素的两种类型:数字和字符串,接下来我们将引入剩下的:列表、元组、集合和字典。
数据容器:
数据容器是一种可以容纳多份数据的数据类型,容纳的每一份数据称之为一个元素,每一个元素可以是任意类型的数据,如字符串、数字、布尔等。
数据容器的划分:
数据容器根据特点的不同,如:
分为 5类,分别为:
列表list元组 tuple字符串 str集合 set字典 dict 8.1 列表
列表的定义:
列表定义的基本语法为:
"""字面量"""[元素1, 元素2, 元素3, ...]"""定义变量"""变量名称 = [元素1, 元素2, 元素3, ...]"""定义空变量"""变量名称 = []变量名称 = list[][] 为标识列表内的每一个元素之间用逗号隔开 我们用一个例子来说明:
lis = ['name', 18, True, [98, 95, 96]]print(lis)print(type(lis))
我们注意到,在列表中,还存在着一个列表,这叫做 列表的嵌套。
列表的索引:
列表中的元素是有顺序的,从左到右的索引从 0 开始,即第一个元素的索引为 0,之后逐个增加。
列表的索引也可以从右向左取,此时的索引从 -1 开始,即最后一个元素的索引为 -1,之后逐个减少。
如果我们想要取出列表中某个元素进行操作,我们可以利用列表的索引,具体方法是 list[索引]。
我们用一个例子说明:
lis = ['name', 18, True, [98, 95, 96]]print(lis[0])print(lis[1])print(lis[2])print(lis[3])print(lis[-1])print(lis[-2])print(lis[-3])print(lis[-4])
注意到,因为最后一个元素是列表,那我们如何取出其中元素进行操作?只需要再附加一个索引即可,比如:
lis = ['name', 18, True, [98, 95, 96]]print(lis[3][0])print(lis[-1][1])print(lis[-1][-1])
我们还可以利用索引对列表元素进行修改:
lis = ['name', 18, True, [98, 95, 96]]print(lis)lis[1] = 20print(lis)
列表的常用操作方法:
列表除了定义,以及使用索引获取其中的元素,也可以:查找元素索引,插入元素,删除元素,清空列表,修改列表,统计元素个数等等。
这些功能,我们称之为:列表的方法
在前面中我们提到了函数,若函数定义为 Class(类) 的成员,那么函数会称之为 方法。
方法和函数一样,有传入参数,有返回值,只是方法的使用格式不同:
函数的使用:func()
方法的使用:member = Class()member.func()
列表 方法 的用法:
查询元素索引index() 功能:在列表中从前往后找到第一个指定元素的索引,并返回;如果找不到,则报错; 语法:列表.index(元素) lis = ['name', 18, True, [98, 95, 96]]print(lis.index('name'))
insert() 功能:在指定索引位置插入指定元素; 语法:列表.insert(索引,元素) lis = ['name', 18, True, [98, 95, 96]]print(lis)lis.insert(1, 'male')print(lis)
append(),extend() 功能:在列表末尾添加元素,append() 只能添加一个,extend() 能添加多个; 语法:列表.append(元素),列表.extend() lis = ['name', 18, True, [98, 95, 96]]print(lis)lis.append('male')print(lis)lis.extend([1, 2, 3])print(lis)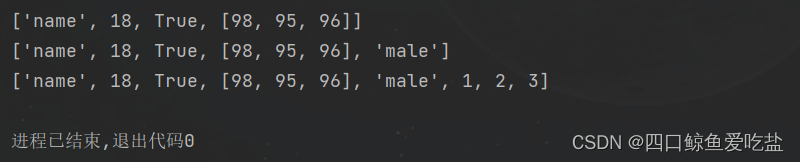
del list[索引] 或 pop(索引) 功能:删除指定索引位置元素,del list[索引] 直接删除,而 pop(索引) 会将删除元素返回; 语法:del 列表[索引],列表.pop(索引),pop() 若不指定索引,默认为 -1 lis = ['name', 18, True, [98, 95, 96]]print(lis)del lis[0]print(lis)d = lis.pop(1)print(lis)print(d)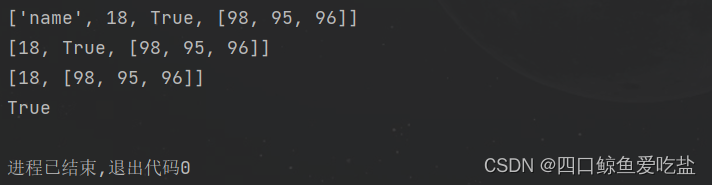
remove() 功能:删除某元素在列表中的第一个匹配项 语法:列表.remove(元素) lis = ['name', 18, True, [98, 95, 96], 18]lis.remove(18)print(lis)
clear() 功能:清空列表中的元素 语法:列表.clear() lis = ['name', 18, True, [98, 95, 96], 18]lis.clear()print(lis)
count() 功能:统计列表中指定元素的个数 语法:列表.count(元素) lis = ['name', 18, True, [98, 95, 96], 18]print(lis.count('name'))print(lis.count(18))
len() 功能:统计列表中元素的个数,并返回 语法:len(列表) lis = ['name', 18, True, [98, 95, 96]]print(len(lis))
列表的遍历:
列表的遍历可以用 while 和 for 循环语句实现:while语句
lis = ['name', 18, True, [98, 95, 96]]index = 0while index < len(lis): print(lis[index]) index += 1
for语句for语句有两种方法实现,一种是利用 range() 函数通过索引遍历,一种是直接遍历。
lis = ['name', 18, True, [98, 95, 96]]for i in range(len(lis)): print(lis[i])lis = ['name', 18, True, [98, 95, 96]]for i in lis: print(i)
8.2 元组
元组同列表一样,都是可以封装多个、不同类型的元素在内,但是,元组一旦完成,就 不能修改。因此我们可以将元组看作 只读 的列表。
所以,当我们封装完数据后,希望其不被更改,就可以用元组。
元组的定义:
元组的定义用 小括号,且使用 逗号 隔开各个元素,数据可以是不同的数据类型:
"""字面量"""(元素1, 元素2, 元素3, ...)"""定义变量"""变量名称 = (元素1, 元素2, 元素3, ...)"""定义空变量"""变量名称 = ()变量名称 = tuple()我们用一个例子说明:
tup = ('name', 18, True, (98, 95, 96))print(tup)print(type(tup))
我们注意到,在元组中,还存在着一个元组,这叫做 元组的嵌套。
元组的操作:
元组的操作和列表的操作类似,除了不可修改,其余操作相同:
index() 功能:在元组中从前往后找到第一个指定元素的索引,并返回;如果找不到,则报错; 语法:元组.index(元素) tup = ('name', 18, True, [98, 95, 96])print(tup.index(18))
count() 功能:统计元组中指定元素的个数 语法:元组.count(元素) tup = ('name', 18, True, [98, 95, 96], True)print(tup.count(18))print(tup.count(True))
len() 功能:统计元组中元素的个数,并返回 语法:len(元组) tup = ('name', 18, True, [98, 95, 96])print(len(tup))
元组的遍历:
元组遍历和列表相同:
tup = ('name', 18, True, (98, 95, 96))index = 0while index < len(tup): print(tup[index]) index += 1tup = ('name', 18, True, (98, 95, 96))for i in range(len(tup)): print(tup[i])tup = ('name', 18, True, (98, 95, 96))for i in tup: print(i)
8.3 字符串
字符串是字符的容器,一个字符可以存放任意数量的字符。
字符串和其他容器一样,有索引,从 0 开始,可以通过索引取出字符串中的字符,比如:
s = 'this is a str'print(s[2])print(s[-1])
字符串的操作:
字符串不能被修改,即不能对原字符串本身直接修改,但是可以操作后返回一个新的字符串。
index() 功能:返回指定字符的第一个匹配项的索引; 用法:字符串.index('指定字符') s = 'this is a str'print(s.index('i'))
replace() 功能:替换字符串的指定子串 用法:字符串.replace(要替换的子串, 替换的内容) s = 'this is a str'new_s = s.replace('is', 'new')print(s)print(new_s)
split() 功能:按照指定的分隔符字符串,将字符串划分为多个字符串,并存入列表中; 用法:字符串.split(分隔字符串) 分隔字符串默认为 ' '空格 s = 'this is a str'lis1 = s.split()lis2 = s.split('s')print(s)print(lis1)print(lis2)
strip() 功能:去除字符串开头和结尾的指定字符; 用法:字符串.strip(指定字符) 指定字符默认为空格 s = ' rt: this is a str 's1 = s.strip()s2 = s.strip(' rt')print(s)print(s1)print(s2)
我们注意到 s2 对应传入的参数是 ' rt',其实,strip() 函数是按照单个字符移除,即 ' ','r','t' 都会移除。
count() 功能:返回字符串中某子串出现的次数; 用法:字符串.count(指定子串) s = ' rt: this is a str 'num = s.count('t')print(num)
len() 功能:返回字符串的长度; 用法:len(字符串) s = ' rt: this is a str 'num = len(s)print(num)
字符串的 遍历和切片 和列表相同,这里不做具体说明。
8.4 序列的切片
我们前面学习了 列表、元组和字符串,这些数据容器都有这样的特点:内容连续、有序且可使用索引,我们称这样的数据容器为 序列。
我们有时需要取出序列中多个元素,这时候就要利用到 切片 操作。
切片: 从一个序列中,取出一个子序列:
序列[起始索引:结束索引:步长]表示从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列 起始索引表示从何处开始,默认为从 0 开始; 结束索引表示到何处结束(但不包括结束索引本身),默认为到结尾 -1; 步长表示依次取元素的间隔,步长 N 表示,每次跳过 N-1 个元素取,步长若为负数则反向取,步长默认为 1; 起始索引也未必要小于结束索引,如果起始索引较大,步长则需为负,可以表示反向取。 我们以实际举例:
lis = ['tom', 18, 98, 95, 96]tup = (1, 2, 3, 4, 5, 6, 7, 8)s = 'this is a string'print(lis[1:-1])print(lis[1:-1:-2])print(tup[2:6:2])print(tup[6:2:-2])print(s[::-1])print(s[::-2])
8.5 集合
前面我们学到的列表、元组和字符串,它们都支持重复元素,而集合则不支持重复元素,因此集合可以用于去重等目的。
集合的定义:
集合的定义与列表基本相同:
"""字面量"""{元素1, 元素2, 元素3, ...}"""定义变量"""变量名称 = {元素1, 元素2, 元素3, ...}"""定义空变量"""变量名称 = set()我们以一个例子说明:
se1 = {1, 2, 3, 4, 2, 1}se2 = set()print(se1)print(se2)print(type(se2))
因为集合是无序的,因此其不存在索引。
但集合允许修改。
集合的操作:
添加新元素add() 功能:在集合中添加新元素 用法:集合.add(新元素) se = {1, 2, 3, 4, 2, 1}print(se)se.add(5)print(se)se.add(4)print(se)
remove() 功能:移除指定元素; 用法:集合.remove(指定元素),集合中没有指定元素会报错 se = {1, 2, 3, 4, 2, 1}print(se)se.remove(1)print(se)
pop() 功能:从集合中随机取出一个元素 结果:会返回取出的元素,同时集合本身也被修改 se = {1, 2, 3, 4, 2, 1}print(se)ele = se.pop()print(ele)print(se)
clear 功能:清空集合 用法:集合.clear() 集合的交 intersection()、并 union()、补 difference 功能:实现集合的运算 用法:集合A.intersection(集合B),集合A.union(集合B),集合A.difference(集合B) se_a = {1, 2, 3, 4, 5, 6}se_b = {4, 5, 6, 7, 8, 9}se_i = se_a.intersection(se_b)se_u = se_a.union(se_b)se_d = se_a.difference(se_b)print(se_a)print(se_b)print(se_i)print(se_u)print(se_d)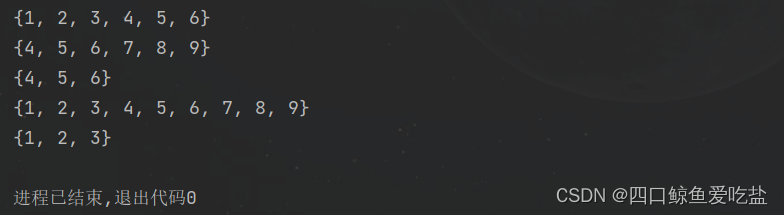
8.6 字典
与集合类似,字典(dictionary)也是由若干无序的数据元素组成,与集合不同的是,字典是一种映射类型,字典中的每一个元素都有一个对应的键(key),即字典中的每个元素都是以 键: 值 对的形式出现。
其中键必须是可哈希的,即不包括列表、集合、字典等,但是值可以为任意类型。
字典的定义:
字典的定义可以用大括号 {}创建,也可以使用 dict() 函数,具体见如下示例代码:
d1 = {'x': 1, 'y': 2, 'z': 3}d2 = {'x': 1, 'y': 2, 'z': 3, 'x': 4}d3 = dict(x=1, y=2, z=3)d4 = dict([('x', 1), ('y', 2), ('z', 3)])d5 = dict()print(d1)print(d2)print(d3)print(d4)print(d5)字典的操作:
插入与修改,可以通过赋值操作直接修改,也可以使用update() 方法 功能:通过键名对字典元素进行修改,若键名不存在则插入新的元素 用法:字典[键]=值,字典.update(键=值) 或 字典1.update(字典2) d1 = {'x': 1, 'y': 2, 'z': 3}print(d1)d1['x'] = 4d1['w'] = 5print(d1)d1.update(y=6)d1.update(v=7)print(d1)d2 = {'q': 100, 'r': 1000}d1.update(d2)print(d1)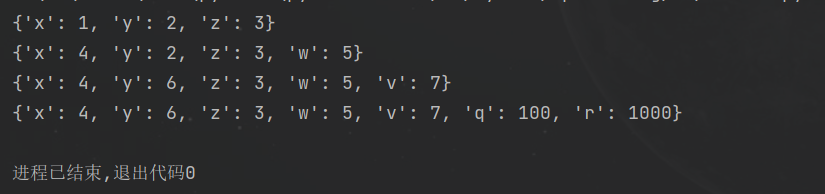
del 功能:删除字典中的指定元素 用法:del 字典[键] d1 = {'x': 1, 'y': 2, 'z': 3}print(d1)del d1['x']print(d1)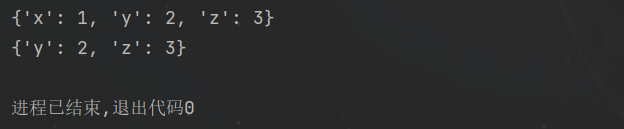
pop() 功能:删除并返回指定元素值 用法:值=字典.pop(键) d1 = {'x': 1, 'y': 2, 'z': 3}print(d1)out = d1.pop('y')print(d1)print(out)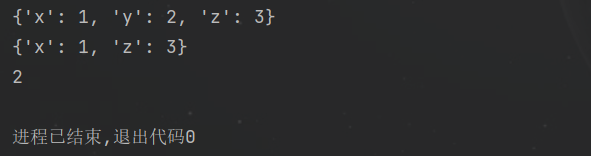
popitem() 功能:删除并返回最后一对键值对 用法: d1 = {'x': 1, 'y': 2, 'z': 3}print(d1)out = d1.popitem()print(d1)print(out)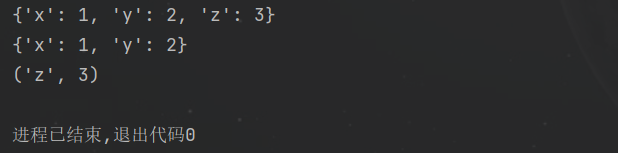
get() 功能:判断字典中是否存在指定的键,若不存在,则返回默认值 用法:字典.get(key, default) d1 = {'x': 1, 'y': 2, 'z': 3}print(d1.get('x', 'No'))print(d1.get('w', 'No'))
items(),或使用 keys() 或 values() 返回字典中所有键或者值 功能:返回键值对,或只返回键或者值 用法:字典.items(),字典.keys(),字典.values() d1 = {'x': 1, 'y': 2, 'z': 3}for k, v in d1.items(): print(f'{k}: {v}')for k in d1.keys(): print(k)for v in d1.values(): print(v)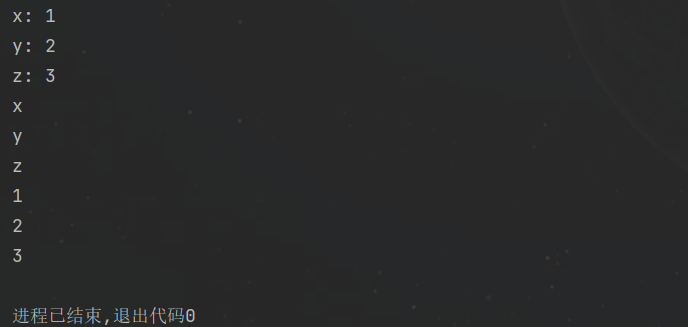
copy() 功能:将一个字典复制一份,赋值给另一个,两个字典的修改不会相互影响 用法:字典2=字典1.copy() d1 = {'x': 1, 'y': 2, 'z': 3}d2 = d1.copy()d2['x'] = 4print(f'd1: {d1}')print(f'd2: {d2}')