文章目录
博主精品专栏导航迁移学习(Transfer Learning)方法一:特征提取(Feature Extraction)方法二:微调(Fine Tuning)(一)实战:基于特征提取的迁移学习(数据集:CIFAR-10)(二)实战:基于微调的迁移学习(数据集:CIFAR-10)(三)实战:基于迁移学习的图像雾霾清除(四)实战:基于迁移学习的102种花分类(先特征提取,后微调)(五)实战:基于迁移学习的102种花分类(自定义Dataset)
博主精品专栏导航
? 【Pytorch项目实战目录】算法详解 + 项目详解 + 数据集 + 完整源码? 【sklearn】线性回归、最小二乘法、岭回归、Lasso回归? 三万字硬核详解:yolov1、yolov2、yolov3、yolov4、yolov5、yolov7? 卷积神经网络CNN的发展史? 卷积神经网络CNN的实战知识? Pytorch基础(全)? Opencv图像处理(全)? Python常用内置函数(全)迁移学习(Transfer Learning)
迁移学习是一种机器学习方法。
具体过程:把任务A预训练模型(网络结构与权重参数),迁移到任务B上。A任务可以是识别图像中的车辆,而B任务可以是识别卡车、汽车、公交车等。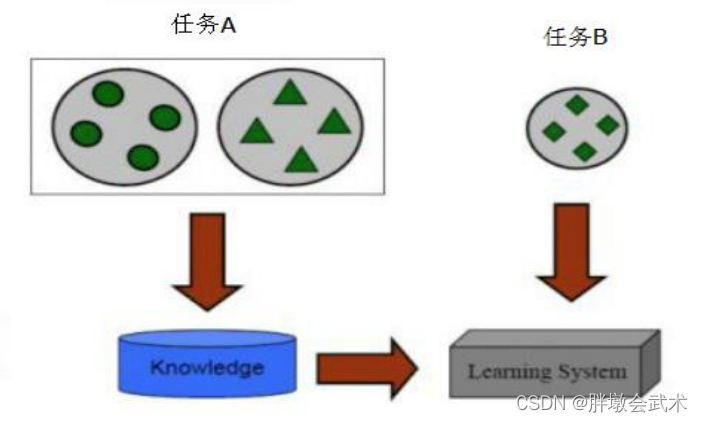 优点:加速训练过程,提升深度模型的性能。应用:常用于大数据,深网络。如:计算机视觉、自然语言处理。主要有三种方法:特征提取、微调、特征提取+微调。
优点:加速训练过程,提升深度模型的性能。应用:常用于大数据,深网络。如:计算机视觉、自然语言处理。主要有三种方法:特征提取、微调、特征提取+微调。 方法一:特征提取(Feature Extraction)
主要步骤:
11、冻结除最后一个全连接层之外的所有网络的权重参数(即取消梯度更新:requires_grad=False);22、依据实际任务修改最后一个全连接层的分类器,随机初始化其参数,然后仅训练该层网络。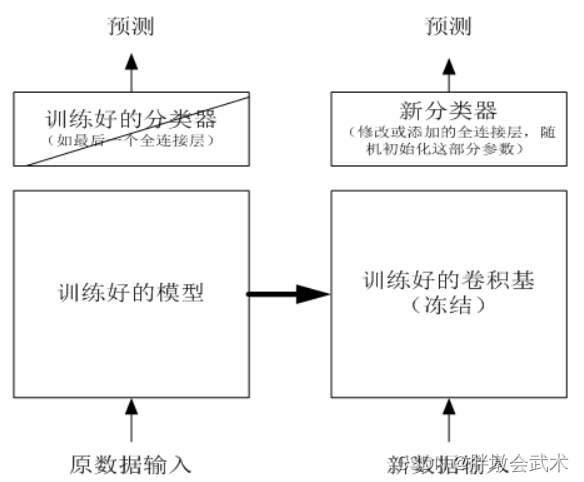
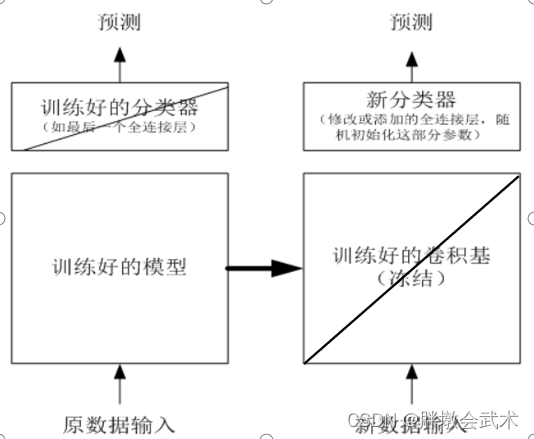
方法二:微调(Fine Tuning)
主要步骤:在预训练模型上,添加新的随机初始化层,且不冻结预训练模型的网络参数,但会使用较小的学习率。优点:(1)虽然训练时间更长但精度更高;
(2)可以减少训练参数的数量,避免过拟合。常用方法:固定底层的参数,调整顶层或具体层的参数。
(一)实战:基于特征提取的迁移学习(数据集:CIFAR-10)
链接:https://pan.baidu.com/s/18Bzu-MU_RS594QCZ8JJQEQ?pwd=efz6
提取码:efz6

import torchimport torchvisionimport torchvision.transforms as transformsfrom datetime import datetimeimport matplotlib.pyplot as pltimport numpy as npimport osos.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # "OMP: Error #15: Initializing libiomp5md.dll"#############################################################def imshow(img): """显示图像""" img = img / 2 + 0.5 # unnormalize npimg = img.numpy() plt.imshow(np.transpose(npimg, (1, 2, 0))) plt.show()def get_acc(output, label): """计算准确度""" total = output.shape[0] _, pred_label = output.max(1) num_correct = (pred_label == label).sum().item() return num_correct / totaldef train(net, train_data, valid_data, num_epochs, optimizer, criterion): """模型训练""" prev_time = datetime.now() for epoch in range(num_epochs): train_loss = 0 train_acc = 0 net = net.train() # 训练模型 for im, label in train_data: im = im.to(device) # (bs, 3, h, w) label = label.to(device) # (bs, h, w) output = net(im) # 前向传播 loss = criterion(output, label) # 损失函数 optimizer.zero_grad() # 梯度清零 loss.backward() # 后向传播 optimizer.step() # 梯度更新 train_loss += loss.item() train_acc += get_acc(output, label) # 打印运行时间 cur_time = datetime.now() h, remainder = divmod((cur_time - prev_time).seconds, 3600) m, s = divmod(remainder, 60) time_str = "Time %02d:%02d:%02d" % (h, m, s) if valid_data is not None: valid_loss = 0 valid_acc = 0 net = net.eval() # 验证模型 for im, label in valid_data: im = im.to(device) # (bs, 3, h, w) label = label.to(device) # (bs, h, w) output = net(im) # 前向传播 loss = criterion(output, label) # 损失函数 valid_loss += loss.item() valid_acc += get_acc(output, label) # 每个Epoch,打印结果。 epoch_str = ("Epoch %d. Train Loss: %f, Train Acc: %f, Valid Loss: %f, Valid Acc: %f, " % (epoch, train_loss / len(train_data), train_acc / len(train_data), valid_loss / len(valid_data), valid_acc / len(valid_data))) else: epoch_str = ("Epoch %d. Train Loss: %f, Train Acc: %f, " % (epoch, train_loss / len(train_data), train_acc / len(train_data))) prev_time = cur_time print(epoch_str + time_str)#############################################################if __name__ == '__main__': # (1)下载数据、数据预处理、迭代器 trans_train = transforms.Compose( [transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])]) trans_valid = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])]) trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=trans_train) trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True, num_workers=2) testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=trans_valid) testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False, num_workers=2) classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') ############################################################# # (2)随机获取部分训练数据 dataiter = iter(trainloader) images, labels = dataiter.next() imshow(torchvision.utils.make_grid(images[:4])) # 显示图像 print(' '.join('%5s' % classes[labels[j]] for j in range(4))) # 打印标签 ############################################################# # (3)冻住模型的所有权重参数 net = torchvision.models.resnet18(pretrained=True) # 使用预训练的模型 for param in net.parameters(): param.requires_grad = False # 冻住该模型的所有权重参数 ############################################################# # (4)替换最后一层全连接层 device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu") # 检测是否有可用的GPU,有则使用,否则使用CPU。 net.fc = torch.nn.Linear(512, 10) # 将最后的全连接层改成十分类 # 查看总参数及(全连接层)训练参数 total_params = sum(p.numel() for p in net.parameters()) print('总参数个数:{}'.format(total_params)) total_trainable_params = sum(p.numel() for p in net.parameters() if p.requires_grad) print('需训练参数个数:{}'.format(total_trainable_params)) ############################################################# # (5)(只)训练全连接层权重参数 net = net.to(device) # 将构建的张量或者模型分配到相应的设备上。 criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失函数 optimizer = torch.optim.SGD(net.fc.parameters(), lr=1e-3, weight_decay=1e-3, momentum=0.9) # 优化器(学习率降低) train(net, trainloader, testloader, 1, optimizer, criterion)(二)实战:基于微调的迁移学习(数据集:CIFAR-10)
链接:https://pan.baidu.com/s/18Bzu-MU_RS594QCZ8JJQEQ?pwd=efz6
提取码:efz6
import torchfrom torch import nnimport torch.nn.functional as Fimport torchvisionimport torchvision.transforms as transformsfrom torchvision import modelsfrom torchvision.datasets import ImageFolderfrom datetime import datetimeimport matplotlib.pyplot as pltimport numpy as npimport osos.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # "OMP: Error #15: Initializing libiomp5md.dll"#############################################################def imshow(img): """显示图像""" img = img / 2 + 0.5 # unnormalize npimg = img.numpy() plt.imshow(np.transpose(npimg, (1, 2, 0))) plt.show()def get_acc(output, label): """计算准确度""" total = output.shape[0] _, pred_label = output.max(1) num_correct = (pred_label == label).sum().item() return num_correct / totaldef train(net, train_data, valid_data, num_epochs, optimizer, criterion): """模型训练""" prev_time = datetime.now() for epoch in range(num_epochs): train_loss = 0 train_acc = 0 net = net.train() # 训练模型 for im, label in train_data: im = im.to(device) # (bs, 3, h, w) label = label.to(device) # (bs, h, w) output = net(im) # 前向传播 loss = criterion(output, label) # 损失函数 optimizer.zero_grad() # 梯度清零 loss.backward() # 后向传播 optimizer.step() # 梯度更新 train_loss += loss.item() train_acc += get_acc(output, label) # 打印运行时间 cur_time = datetime.now() h, remainder = divmod((cur_time - prev_time).seconds, 3600) m, s = divmod(remainder, 60) time_str = "Time %02d:%02d:%02d" % (h, m, s) if valid_data is not None: valid_loss = 0 valid_acc = 0 net = net.eval() # 验证模型 for im, label in valid_data: im = im.to(device) # (bs, 3, h, w) label = label.to(device) # (bs, h, w) output = net(im) # 前向传播 loss = criterion(output, label) # 损失函数 valid_loss += loss.item() valid_acc += get_acc(output, label) # 每个Epoch,打印结果。 epoch_str = ("Epoch %d. Train Loss: %f, Train Acc: %f, Valid Loss: %f, Valid Acc: %f, " % (epoch, train_loss / len(train_data), train_acc / len(train_data), valid_loss / len(valid_data), valid_acc / len(valid_data))) else: epoch_str = ("Epoch %d. Train Loss: %f, Train Acc: %f, " % (epoch, train_loss / len(train_data), train_acc / len(train_data))) prev_time = cur_time print(epoch_str + time_str)#############################################################if __name__ == '__main__': # (1)下载数据、数据预处理、迭代器 trans_train = transforms.Compose( [transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)), transforms.RandomRotation(degrees=15), transforms.ColorJitter(), transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])]) trans_valid = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])]) trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=trans_train) trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True, num_workers=2) testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=trans_valid) testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False, num_workers=2) classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') # (2)随机获取部分训练数据 dataiter = iter(trainloader) images, labels = dataiter.next() imshow(torchvision.utils.make_grid(images)) # 显示图像 print(' '.join('%5s' % classes[labels[j]] for j in range(4))) # 打印标签 # (3)使用预训练的模型,并替换最后一层全连接层 net = models.resnet18(pretrained=True) device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 检测是否有可用的GPU,有则使用,否则使用CPU。 net.fc = nn.Linear(512, 10) # 将最后的全连接层改成十分类 # (4)模型训练 net = net.to(device) # 将构建的张量或者模型分配到相应的设备上。 criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失函数 optimizer = torch.optim.SGD(net.fc.parameters(), lr=1e-3, weight_decay=1e-3, momentum=0.9) # 优化器(学习率降低) train(net, trainloader, testloader, 1, optimizer, criterion)(三)实战:基于迁移学习的图像雾霾清除
链接:https://pan.baidu.com/s/1z1MKgoKc4T-iyJV4mFLHeg?pwd=y58o
提取码:y58o

import torchimport torch.nn as nnimport torchvisionimport torch.backends.cudnn as cudnnimport torch.optimimport numpy as npfrom torchvision import transformsfrom PIL import Imageimport globimport matplotlib.pyplot as pltfrom matplotlib.image import imreadimport osos.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # "OMP: Error #15: Initializing libiomp5md.dll"############################################################## 创建存放目标文件目录(如果文件不存在,则创建)path = 'clean_photo/results'if not os.path.exists(path): os.makedirs(path)class model(nn.Module): """定义神经网络""" def __init__(self): super(model, self).__init__() self.relu = nn.ReLU(inplace=True) self.e_conv1 = nn.Conv2d(3, 3, 1, 1, 0, bias=True) self.e_conv2 = nn.Conv2d(3, 3, 3, 1, 1, bias=True) self.e_conv3 = nn.Conv2d(6, 3, 5, 1, 2, bias=True) self.e_conv4 = nn.Conv2d(6, 3, 7, 1, 3, bias=True) self.e_conv5 = nn.Conv2d(12, 3, 3, 1, 1, bias=True) def forward(self, x): source = [] source.append(x) x1 = self.relu(self.e_conv1(x)) x2 = self.relu(self.e_conv2(x1)) concat1 = torch.cat((x1, x2), 1) x3 = self.relu(self.e_conv3(concat1)) concat2 = torch.cat((x2, x3), 1) x4 = self.relu(self.e_conv4(concat2)) concat3 = torch.cat((x1, x2, x3, x4), 1) x5 = self.relu(self.e_conv5(concat3)) clean_image = self.relu((x5 * x) - x5 + 1) return clean_imagedevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 检测是否有可用的GPU,有则使用,否则使用CPU。net = model().to(device)def cl_image(image_path): data = Image.open(image_path) data = (np.asarray(data) / 255.0) data = torch.from_numpy(data).float() data = data.permute(2, 0, 1) data = data.to(device).unsqueeze(0) ########################################################## # 加载预训练模型的权重参数 net.load_state_dict(torch.load('clean_photo/dehazer.pth', map_location=torch.device('cpu'))) # CPU加载模型 # net.load_state_dict(torch.load('dehazer.pth')) # GPU加载模型 ########################################################## clean_image = net.forward(data) # 前向传播 # 保存图像(自定义保存地址) torchvision.utils.save_image(torch.cat((data, clean_image), 0), "clean_photo/" + image_path.split("/")[-1]) # split("/")[-1]: 获取分隔符最后一个字符串if __name__ == '__main__': test_list = glob.glob(r"clean_photo/test_images\*") for image in test_list: cl_image(image) print(image, "done!") img = imread('./clean_photo/test_images/canyon.png') plt.imshow(img) plt.show() (四)实战:基于迁移学习的102种花分类(先特征提取,后微调)
链接:https://pan.baidu.com/s/1nzV0_PorIupFVXlePoTzsw?pwd=ni9i
提取码:ni9i
PyTorch深度学习模型的保存和加载
CPU与GPU加载模型的区别:torch.load()

花朵数据分训练集和测试集,而每个数据集下有102个文件夹,分别存放102种花,文件夹的名字即对应花朵的标签。
import osimport timeimport copyimport jsonimport matplotlib.pyplot as pltimport numpy as npimport torch# from torch import nn# import torch.optim as optim# import torchvisionfrom torchvision import transforms, models, datasetsos.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # "OMP: Error #15: Initializing libiomp5md.dll"#################################################################################################### 迁移学习:即建立在已经训练好的网络模型(权重参数)基础上,继续训练。# ———— torchvision提供了很多经典网络模型。# 注意1:在已训练好模型基础上,将(最后一层)全连接层的权重参数,根据实际任务需要重新训练。比如:需要将10分类更新为50分类;# 注意2:<11>可以全部重头训练;<22>只训练咱们任务的最后一层,因为前几层都是做特征提取,任务目标是一致的。## 模型训练步骤如下:# (1)【模块1】:提取全连接层之前的网络模型(权重参数),且设置权重参数不更新(即冻住该模型);# (2)【模块2】:根据实际任务需要,自定义全连接层的权重参数;再搭配上【模块1】,进行(全连接层的权重参数)训练。# (3)基于【模块1】、【模块2】构建网络模型,且设置权重参数更新,进行训练。#################################################################################################### 网络模型初始化(下载torchvision已经训练好的网络模型和权重参数)def initialize_model(model_name, classes_num, feature_extract=True, use_pretrained=True):model_ft = models.resnet18(pretrained=use_pretrained)# 模型初始化if feature_extract:# 是否更新模型参数for param in model_ft.parameters():param.requires_grad = False# 提取已经训练好的权重参数(不再更新)num_ftrs = model_ft.fc.in_featuresmodel_ft.fc = torch.nn.Linear(num_ftrs, classes_num) # 全连接网络:设置分类数目(根据实际任务)input_size = 64 # 设置输入图像大小(根据实际任务)return model_ft, input_sizedef train_model(model, dataloaders, optimizer, criterion, num_epochs, filename):since = time.time()# 统计运行时间best_acc = 0# 最优精确度model.to(device)# 加载模型到CPU/GPUval_acc_history = []# 验证集历史精确度train_acc_history = []# 验证集历史精确度train_losses = []# 验证集损失值valid_losses = []# 验证集损失值lr_s = [optimizer.param_groups[0]['lr']]# 学习率best_model_wts = copy.deepcopy(model.state_dict())# 最好的那次模型,后续会变的,先初始化for epoch in range(num_epochs):print('-' * 50)# 切割字符串print('Epoch = {}/{}'.format(epoch, num_epochs - 1))# 打印当前第几轮epoch# 训练模型和验证模型for phase in ['train', 'valid']:if phase == 'train':model.train() # 切换训练模型else:model.eval() # 切换验证模型running_loss = 0.0# 单个epoch的损失running_corrects = 0# 单个epoch的准确率for inputs, labels in dataloaders[phase]:# 遍历(训练集和验证集)inputs = inputs.to(device) # (图像)加载到CPU或GPU中labels = labels.to(device)# (标签)加载到CPU或GPU中optimizer.zero_grad()# 梯度清零outputs = model(inputs)# 前向传播(每个图像输出N个值,对应N分类)loss = criterion(outputs, labels)# 损失函数_, preds = torch.max(outputs, 1)# 预测结果(取最大概率值对应的分类结果)# 梯度更新(仅限训练阶段)if phase == 'train':loss.backward()# 后向传播optimizer.step()# 参数更新# 计算损失running_loss += loss.item() * inputs.size(0) # 累加当前batch的损失值。0表示batch维度running_corrects += torch.sum(preds == labels.data) # 累加当前batch的准确率(预测结果最大值和真实值是否一致)epoch_loss = running_loss / len(dataloaders[phase].dataset) # 计算每个epoch平均损失epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)# 计算每个epoch准确度time_elapsed = time.time() - since # 计算一个epoch计算时间print('Time_elapsed: {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))print('{}_loss: {:.4f} acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))# 验证模型。提取精确度最高的模型(迭代训练,可能会过拟合)if phase == 'valid' and epoch_acc > best_acc:best_acc = epoch_acc# 记录最优精确度best_model_wts = copy.deepcopy(model.state_dict())# 复制当前最好的权重参数# 权重参数(字典结构:key是每个网络层的名字,value是权重参数) + 最优准确度 + 优化器参数(lr)state = {'state_dict': model.state_dict(), 'best_acc': best_acc, 'optimizer': optimizer.state_dict()}torch.save(state, filename)# 保存(当前模型)训练好的权重参数if phase == 'valid':val_acc_history.append(epoch_acc)valid_losses.append(epoch_loss)if phase == 'train':train_acc_history.append(epoch_acc)train_losses.append(epoch_loss)print('learning_rate : {:.7f}'.format(optimizer.param_groups[0]['lr']))lr_s.append(optimizer.param_groups[0]['lr'])# 保存当前epoch的学习率optimizer.step() # 参数更新print('*' * 50)# 切割字符串time_elapsed = time.time() - since# 训练总时间print('Training_total_time {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))print('Best_acc(valid): {:4f}'.format(best_acc))model.load_state_dict(best_model_wts)# 训练完后,提取最优准确度对应的网络模型权重参数。return model, val_acc_history, train_acc_history, valid_losses, train_losses, lr_sdef im_convert(tensor):""" 展示数据 """image = tensor.to("cpu").clone().detach()# 将torch.tensor提取到cpu下image = image.numpy().squeeze()# 并转换为numpy格式,且降维处理image = image.transpose(1, 2, 0)# 维度转换:size * channel(torch中的图像维度:channel * size)image = image * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406))# 预处理操作改变源图像,需还原image = image.clip(0, 1)return image################################################################################################################## (1)指定数据文件的地址data_dir = './flower_data/'train_dir = data_dir + '/train'valid_dir = data_dir + '/valid'# 数据分为训练集和测试集两个文件夹:每个文件夹下有102个子文件夹,每个子文件夹下存放对应类别的图像。################################################################################################################## (2)数据增强data_transforms = {'train': transforms.Compose([transforms.Resize([96, 96]),# Resize的作用是对图像进行缩放。transforms.RandomRotation(45),# RandomRotation的作用是对图像进行随机旋转。transforms.CenterCrop(64),# CenterCrop的作用是从图像的中心位置裁剪指定大小的图像transforms.RandomHorizontalFlip(p=0.5),# RandomHorizontalFlip的作用是以一定的概率对图像进行水平翻转。transforms.RandomVerticalFlip(p=0.5),# RandomVerticalFlip的作用是以一定的概率对图像进行垂直翻转。transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),# ColorJitter的作用是随机修改图片的亮度、对比度和饱和度transforms.RandomGrayscale(p=0.025),# RandomGrayscale的作用是以一定的概率将图像变为灰度图像。transforms.ToTensor(),# 将PIL Image或numpy.ndarray转为pytorch的Tensor,并会将像素值由[0, 255]变为[0, 1]之间。transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),# Normalize的作用是用均值和标准差对Tensor进行归一化处理。'valid': transforms.Compose([transforms.Resize([64, 64]),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}################################################################################################################## (3)数据预处理batch_size = 128# 添加(指定数据)路径 + 数据增强。ImageFolder:提取多个文件夹下的数据(训练集+测试集)DataLoader:批量数据读取image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'valid']}# 字典结构:{'train': x, 'valid': x}dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True) for x in ['train', 'valid']}dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'valid']}class_names = image_datasets['train'].classes################################################################################################################## (4)判断GPU是否可用train_on_gpu = torch.cuda.is_available()if not train_on_gpu:print('CUDA is not available. Training on CPU ...')else:print('CUDA is available! Training on GPU ...')device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")################################################################################################################## (5)加载torchvision.models中已经训练好的网络模型、权重参数。model_name = 'resnet' # 加载网络模型:['resnet', 'alexnet', 'vgg', 'squeezenet', 'densenet', 'inception']feature_extract = True # 提取权重参数classes_num = 102# 设置分类数目(根据实际任务)model_ft, input_size = initialize_model(model_name, classes_num, feature_extract=True, use_pretrained=True)# 模型初始化model_ft = model_ft.to(device)# 模型加载到CPU/GPU中################################################################################################################## (6)迁移学习第一步:模型训练(只训练输出层) ———— 即冻住全连接层之前的权重参数,只更新全连接层的权重参数。params_to_update = model_ft.parameters()# 提取初始化模型的权重参数if feature_extract == True:params_to_update = []# model.named_parameters():返回每一层网络的名称和参数内容(权重和偏置)for name, param in model_ft.named_parameters():if param.requires_grad == True:params_to_update.append(param)# 提取每一层网络的权重参数(已经训练好的权重参数)print("\t", name)else:for name, param in model_ft.named_parameters():if param.requires_grad == True:# 重新训练权重参数print("\t", name)optimizer_ft = torch.optim.Adam(params_to_update, lr=1e-2)# 优化器scheduler = torch.optim.lr_scheduler.StepLR(optimizer_ft, step_size=10, gamma=0.1)# 学习率。每7个epoch,衰减为原来的1/10criterion = torch.nn.CrossEntropyLoss()# 损失函数num_epochs = 1filename = 'checkpoint.pth'# 自定义模型保存后的名字model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, lr_s = train_model(model_ft, dataloaders, optimizer_ft, criterion, num_epochs, filename)################################################################################################################## (7)迁移学习第二步:模型训练(其余网络层+全连接层) ———— 即更新权重参数,最后得到当前网络模型的权重参数。for param in model_ft.parameters():param.requires_grad = True# 将所有的权重参数都设置为True(需要更新)optimizer = torch.optim.Adam(model_ft.parameters(), lr=1e-3)# 优化器(学习率可以小一点)scheduler = torch.optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)# 学习率。每7个epoch,衰减为原来的1/10criterion = torch.nn.CrossEntropyLoss()# 损失函数checkpoint = torch.load(filename)# 加载已经训练好的权重参数best_acc = checkpoint['best_acc']# 提取该模型的最优准确度model_ft.load_state_dict(checkpoint['state_dict'])# 加载该模型的权重参数num_epochs = 1model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, lr_s = train_model(model_ft, dataloaders, optimizer, criterion, num_epochs, filename)################################################################################################################## (8)模型验证dataiter = iter(dataloaders['valid'])# 提取验证集images, labels = dataiter.next()# 提取图像与标签(每次提取数据大小:一个epoch)model_ft.eval()# 模型验证if train_on_gpu:# 提取输出结果(CPU与GPU两种方法)output = model_ft(images.cuda())else:output = model_ft(images)_, preds_tensor = torch.max(output, 1)# 提取预测结果矩阵(取概率最大值)preds = np.squeeze(preds_tensor.numpy()) if not train_on_gpu else np.squeeze(preds_tensor.cpu().numpy())# 格式转换:将tensor转换成numpy,包括CPU与GPU两种转换方法。########################################### (9)画图(局部结果展示)with open('cat_to_name.json', 'r') as f:cat_to_name = json.load(f)# json.load():读取文件句柄fig = plt.figure(figsize=(20, 20))columns = 5# 画图的行数rows = 4# 画图的列数for idx in range(columns * rows):ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[])# 在画布上进行子区域划分。plt.imshow(im_convert(images[idx]))# 画图。图像格式转换(tensor to numpy)并进行计算# 标题展示预测结果:前一个值为label,后一个值为预测值。若预测值为真,则为绿色,否则为红色。ax.set_title("label={} (pred={})" .format(cat_to_name[str(preds[idx])], cat_to_name[str(labels[idx].item())]),color=("green" if cat_to_name[str(preds[idx])] == cat_to_name[str(labels[idx].item())] else "red"))plt.show()(五)实战:基于迁移学习的102种花分类(自定义Dataset)
链接:https://pan.baidu.com/s/1nzV0_PorIupFVXlePoTzsw?pwd=ni9i
提取码:ni9i
train标签格式如下: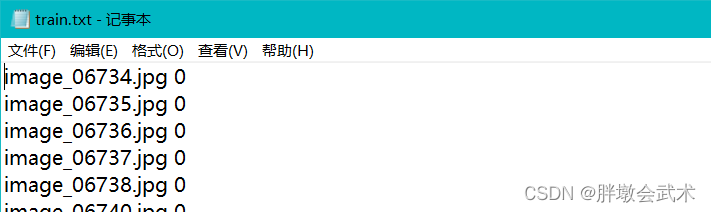
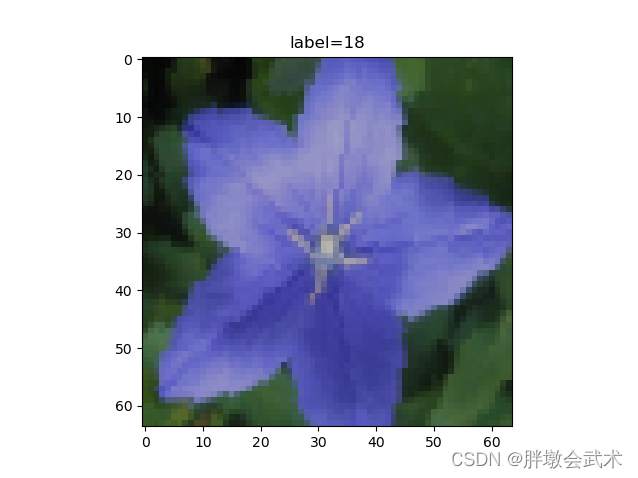
import osimport matplotlib.pyplot as pltimport numpy as npimport torchfrom torchvision import transformsfrom PIL import Imagefrom torch.utils.data import Dataset, DataLoaderos.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # "OMP: Error #15: Initializing libiomp5md.dll"########################################################################### (1)自定义Datasetclass FlowerDataset(Dataset):# 继承torch.utils.data.Dataset def __init__(self, root_dir, ann_file, transform=None): """函数功能:参数初始化""" self.root_dir = root_dir # 获取数据的根目录路径 self.ann_file = ann_file # 获取数据文件(.txt) self.transform = transform # 图像预处理 self.img_label = self.load_annotations() # 加载(.txt)文件,并获得图像名称和对应的标签 self.img = [os.path.join(self.root_dir, img) for img in list(self.img_label.keys())] # (1)将【图像名称】数据转换为list;(2)遍历所有图像名称;(3)通过路径拼接,得到每张图像的存放地址;(4)并将其添加到系统路径中 self.label = [label for label in list(self.img_label.values())] # (1)将【标签】数据转换为list;(2)遍历所有标签; def __len__(self): """函数功能:获取数据集大小""" return len(self.img) def __getitem__(self, idx): # 默认自动打乱数据(idx:表示索引值) """函数功能:获取图像和标签""" image = Image.open(self.img[idx]) # 获取图像索引,并打开其所在路径,得到图像数据。 label = self.label[idx] # 获取图像对应的标签值 if self.transform: # 判断是否需要图像预处理 image = self.transform(image) # 如是,则执行图像预处理 label = torch.from_numpy(np.array(label)) # 格式转换:numpy转换为tensor return image, label def load_annotations(self): """函数功能:读取(.txt)文件,提取数据集""" """文件存放的数据格式:每一行对应一个数据,格式为 = name label""" data_infos = {} # 数据储存。字典结构 = {key=name, value=label} with open(self.ann_file) as f: # (1)逐行读取;(2)并以“ 空格符 ”进行分割;(3)然后保存为列表 samples = [x.strip().split(' ') for x in f.readlines()] for filename, get_label in samples: data_infos[filename] = np.array(get_label, dtype=np.int64) # np.array: 列表转换为ndarray return data_infos ############################################################## # strip():用于移除字符串开头或结尾指定的字符或字符串(默认为空格或换行符)。 # str = "00000003210Runoob01230000000"; # print str.strip( '0' ); # 去除首尾字符 0 ############################################################### (2)图像预处理(图像预处理操作都是在DataLoader中完成的)data_transforms = { 'train': transforms.Compose([ transforms.Resize([96, 96]),# Resize的作用是对图像进行缩放。 transforms.RandomRotation(45),# RandomRotation的作用是对图像进行随机旋转。 transforms.CenterCrop(64),# CenterCrop的作用是从图像的中心位置裁剪指定大小的图像 transforms.RandomHorizontalFlip(p=0.5),# RandomHorizontalFlip的作用是以一定的概率对图像进行水平翻转。 transforms.RandomVerticalFlip(p=0.5),# RandomVerticalFlip的作用是以一定的概率对图像进行垂直翻转。 transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),# ColorJitter的作用是随机修改图片的亮度、对比度和饱和度 transforms.RandomGrayscale(p=0.025),# RandomGrayscale的作用是以一定的概率将图像变为灰度图像。 transforms.ToTensor(),# 将PIL Image或numpy.ndarray转为pytorch的Tensor,并会将像素值由[0, 255]变为[0, 1]之间。 transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),# Normalize的作用是用均值和标准差对Tensor进行归一化处理。 'valid': transforms.Compose([ transforms.Resize([64, 64]), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}# (3)自定义图像数据路径data_dir = './flower_data/'train_dir = data_dir + '/train_filelist'valid_dir = data_dir + '/val_filelist'# (4)实例化dataloadertrain_dataset = FlowerDataset(root_dir=train_dir, ann_file='./flower_data/train.txt', transform=data_transforms['train'])val_dataset = FlowerDataset(root_dir=valid_dir, ann_file='./flower_data/val.txt', transform=data_transforms['valid'])train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)val_loader = DataLoader(val_dataset, batch_size=64, shuffle=True)# (5)模型测试image, label = iter(train_loader).next() # 迭代一个batch数据,然后next获取下一个batch数据(系统定性写法)sample = image[0].squeeze() # 维度压缩:1*3*64*64 -> 3*64*64sample = sample.permute((1, 2, 0)).numpy() # 维度变换:3*64*64 -> 64*64*3sample *= [0.229, 0.224, 0.225] # 还原(标准化)预处理:均值sample += [0.485, 0.456, 0.406] # 还原(标准化)预处理:标准差plt.imshow(sample) # 画图plt.title('label={}'.format(label[0].numpy())) # 标题打印标签plt.show()