1.Introduction
原论文地址:https://arxiv.org/abs/2203.03952
代码地址:https://github.com/hkzhang91/ParC-Net
Introduction部分以翻译原文为主
ViT在许多视觉任务中已经取得了显著的成绩,成为ConvNet的强力替代方案,但作者认为二者都是不可或缺的,给出原因如下:
1)应用方面二者各有优劣:ViT拥有更好的性能但通常计算成本较高,难以训练,ConvNet则在mobile or edge devices的小模型中占据主导地位。
2)信息处理方面,ViT擅长与全局信息的提取,而ConvNet则着重于local relationships的建模(由于inductive bias有很强的先验性)。
因此作者希望根据学习ViT的优点来改进提升ConvNet的性能。简而言之,ParC-Net是作者结合了ViT和ConvNet二者的优点所涉及的一个(模块)网络。
作者总结了ViT和ConvNet的三个主要不同点,也是在后续设计过程中需要对ConvNet进行改进的地方:
1)ViT擅长于全局信息的提取
2)ViT使用了Meta-Former模块
关于Meta-Former,是论文《MetaFormer is Actually What You Need for Vision》对Transformer结构所抽象的一种结构,论文链接:https://arxiv.org/abs/2111.11418v1
3)ViT的信息聚合依靠data driven
2.ParC
ParC:Position aware circular convolution
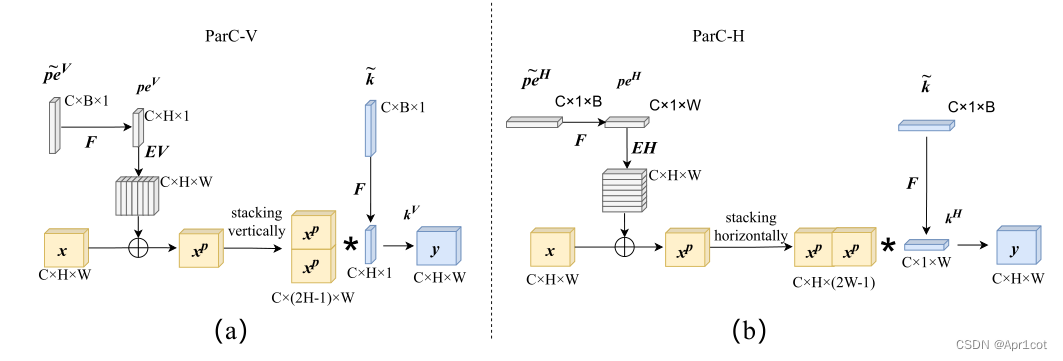 Position aware circular convolution
Position aware circular convolution 针对于全局信息的提取作者提出了Position aware circular convolution(也称作Global Circular Convolution)。图中左右实际是对于该操作水平竖直两方向的对称,理解时只看左边即可。对于维度为C*H*W的输入,作者先将维度为C*B*1的Position Embedding通过双线性插值函数F调整到适合input的维度C*H*1(以适应不同特征大小输入),并且将PE水平复制扩展到C*H*W维度与输入特征相加。这里作者将PE直接设置成为了可学习的参数。
接下来作者将加入PE的特征图竖直方向堆叠,并且同样以插值的方式得到了适应输入维度的C*H*1大小的卷积核,进行卷积操作。对于这一步卷积,作者将之称为循环卷积,并给出了一个卷积示意图。
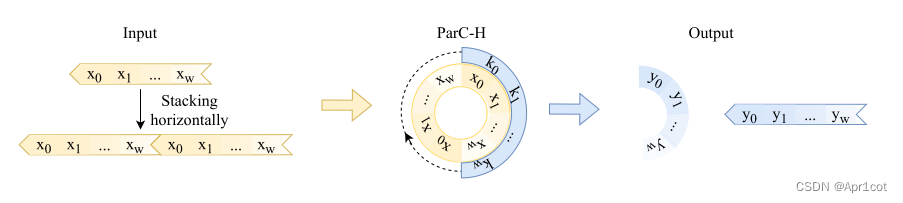 但个人感觉实际上这个示意图只是为了说明为什么叫循环卷积,对于具体的计算细节还是根据公式理解更好。
但个人感觉实际上这个示意图只是为了说明为什么叫循环卷积,对于具体的计算细节还是根据公式理解更好。
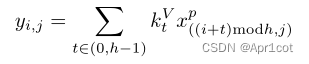
进一步,作者给出了这一步的伪代码来便于读者对这一卷积的理解:y=F.conv2D(torch.cat(xp,xp,dim=2),kV),实际上就是将xp堆叠之后使用了一个“条形(或柱形)”卷积核进行简单的卷积操作。(但这样会导致多一次重复卷积,因此在堆叠示意图中只取了前2*H-1行)
可以看到在示意图中特征维度变化如下:C*(2H-1)*W ---C*H*1--->C*H*W,作者特意带上了通道数,并且并没有出现通道数的改变,那么这里所进行的卷积应该是depth wise卷积,通过对文章后续以及论文源码的阅读可以得知这一步进行的就是DW卷积。(we introduce group convolution and point wise convolution into these modules, which decreases number of parameters without hurting performance.)
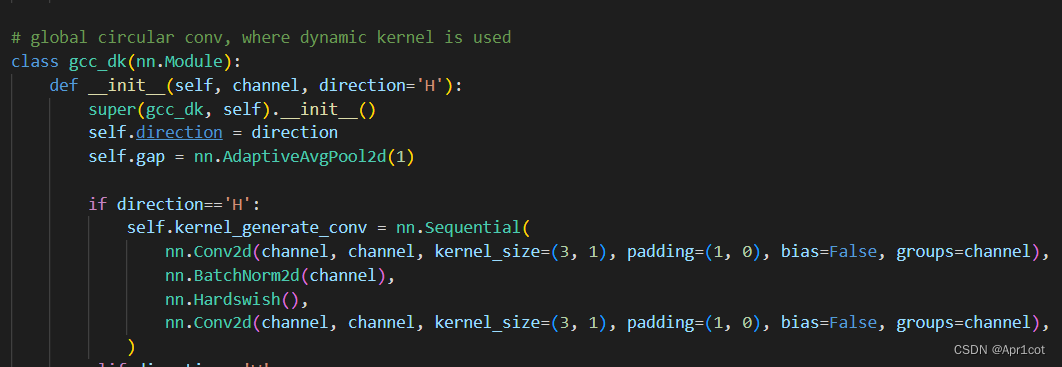 由groups = channel可知使用的是DW卷积
由groups = channel可知使用的是DW卷积 通过上面就完成了一次竖直方向的全局信息交流,同样只要在水平方向进行同样的操作即可做到水平方向的全局信息交流。
3.ParC block
通过ParC成功解决了全局信息提取的问题,接下来就是针对2)3)两点进行改进。首先是Meta-Former模块,Meta-Former由Token Mixer和Channel Mixer构成,ParC首先满足了Token Mixer的全局信息提取的要求,并且相较于Attention在计算成本上更低。
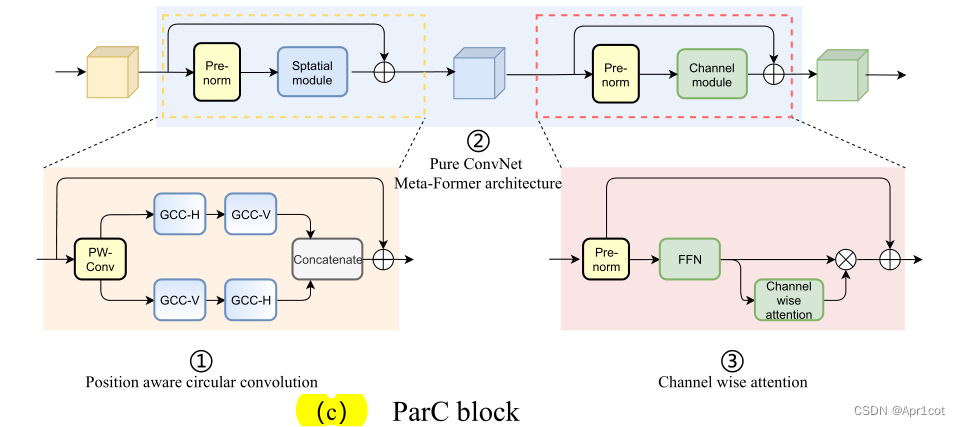
这里①中的PWC即point wise conv,进一步验证了我们前面对于深度可分离卷积的想法,而GCC-H/V即是前面所说的ParC-H/V。
①构建了Meta-Former中的Token mixer模块,那么最后剩下的问题就是3),替换掉Attention模块之后模型不再data driven。为了解决这一点作者给出了一个channel wise attention,先将特征图(x,C*H*W)进行global average(a,C*1*1)并输入一个MLP生成一个channel wise的权重(w,C*1*1),再将权重与特征图在通道方向相乘得到输出(output = wx,C*H*W)。
4.ParC net
对于ParC net 的搭建,作者直接基于MobileViT,采用了分叉结构(c)完成了网络的搭建。

具体而言作者保留了MobileViT中浅层具有局部感受野的MobileNetV2结构,而将网络深层的ViT block替换成了ParC block,使网络变成了一个pure ConvNet。