1.摘要
2020年Transformer在CV领域一炮打响,谷歌提出的Vision Transformer (ViT)(An Image is Worth 16x16 Words,模仿“An Image is Worth a thousand Words”)再次横空出世,只是简单的将图片切成16X16的patch,扔到原封不动的NLP的Transformer中,结果竟然就一骑绝尘,表现超过了一众沉淀了多年的CNN,最神奇的是,它完全不考虑图像的特点, 什么CNN的平移不变性(Translational Invariance)和局部性(Locality) 统统都没有考虑,只要把图像打成patch后,丢到Transformer就成,和NLP的Sequence处理方法完全一样,这也再次诠释了"Attention is all you need!"。在此之后,大量基于Transformer的论文在CV领域出现,比如2021 年中,微软发表了一款基于窗口移动(Shift Window)的Swin Transformer,窗口移动有点CNN的感觉又回来了,窗口移动能够促进相邻patch之间交互,也是个屠榜级的存在。那这样一来,卷积神经网络真的要淡出舞台中央了吗?就在2022年一月份CNN发起了绝地反击,A ConvNet for the 2020s一文提出ConvNeXt,借鉴了 Vision Transformer 和 CNN 的成功经验,构建一个纯卷积网络,其性能超越了高大上(复杂的) 基于Transformer 的先进的模型,荣耀归卷积网络!但仔细看,好像也没又什么大的idea方面的创新,只是一堆Trick,使用现有的结构和方法便达到了ImageNet Top-1的准确率。
论文名称:A ConvNet for the 2020s
论文下载链接:https://arxiv.org/abs/2201.03545
2. ConvNext进化过程
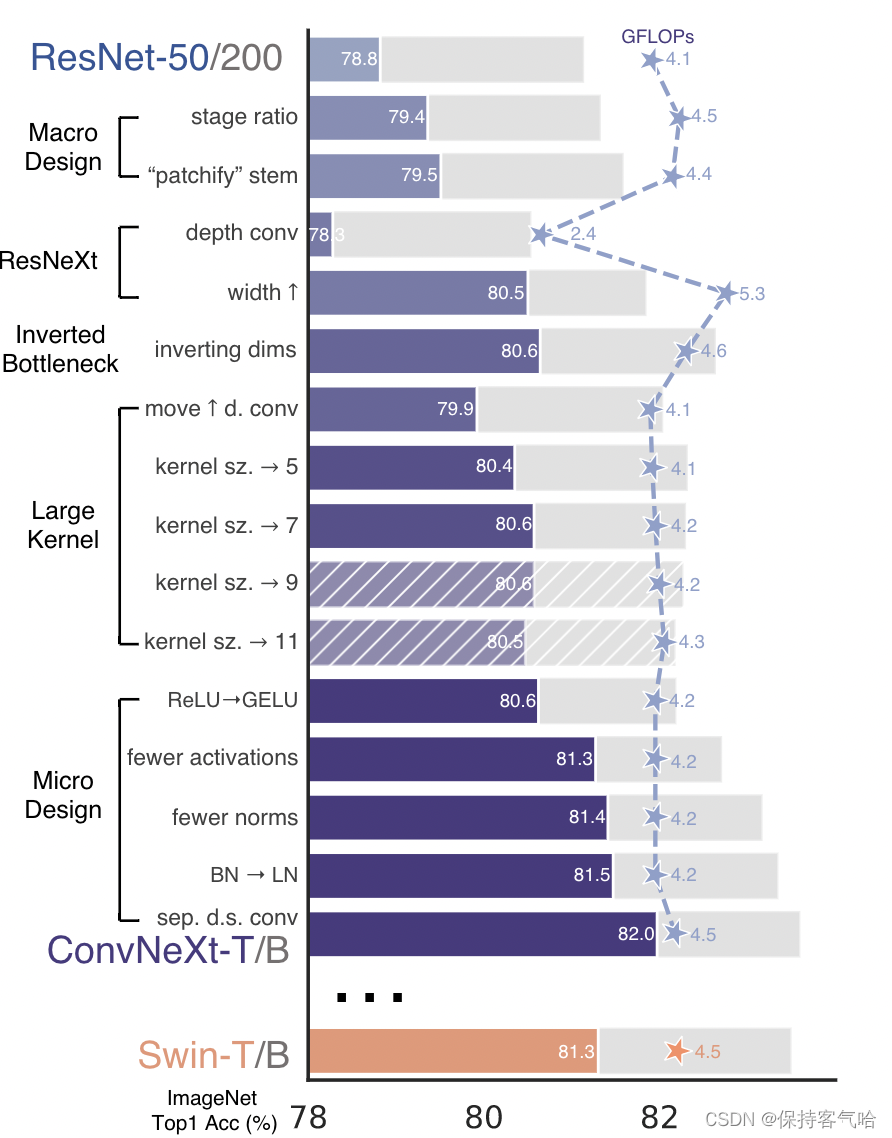
ConvNeXt的出现,证明并不一定需要Transformer那么复杂的结构,只对原有CNN的技术和参数优化也能达到SOTA,ConvNeXt 首先采用标准神经网络 ResNet-50 并对其依据Vit的训练策略进行现代化改造,并以此作为baseline。下图展示了ConvNeXt的所有优化点它从ResNet-50[4]或者ResNet-200出发,依次从宏观设计,深度可分离卷积(ResNeXt[5]),逆瓶颈层(MobileNet v2[6]),大卷积核,细节设计这五个角度依次借鉴Swin Transformer的思想,然后在ImageNet-1K上进行训练和评估,最终得到ConvNeXt的核心结构。
2.1 Tranning Technique(训练技巧)
在ConvNeXt中,它的优化策略借鉴了Swin-Transformer。具体的优化策略包括
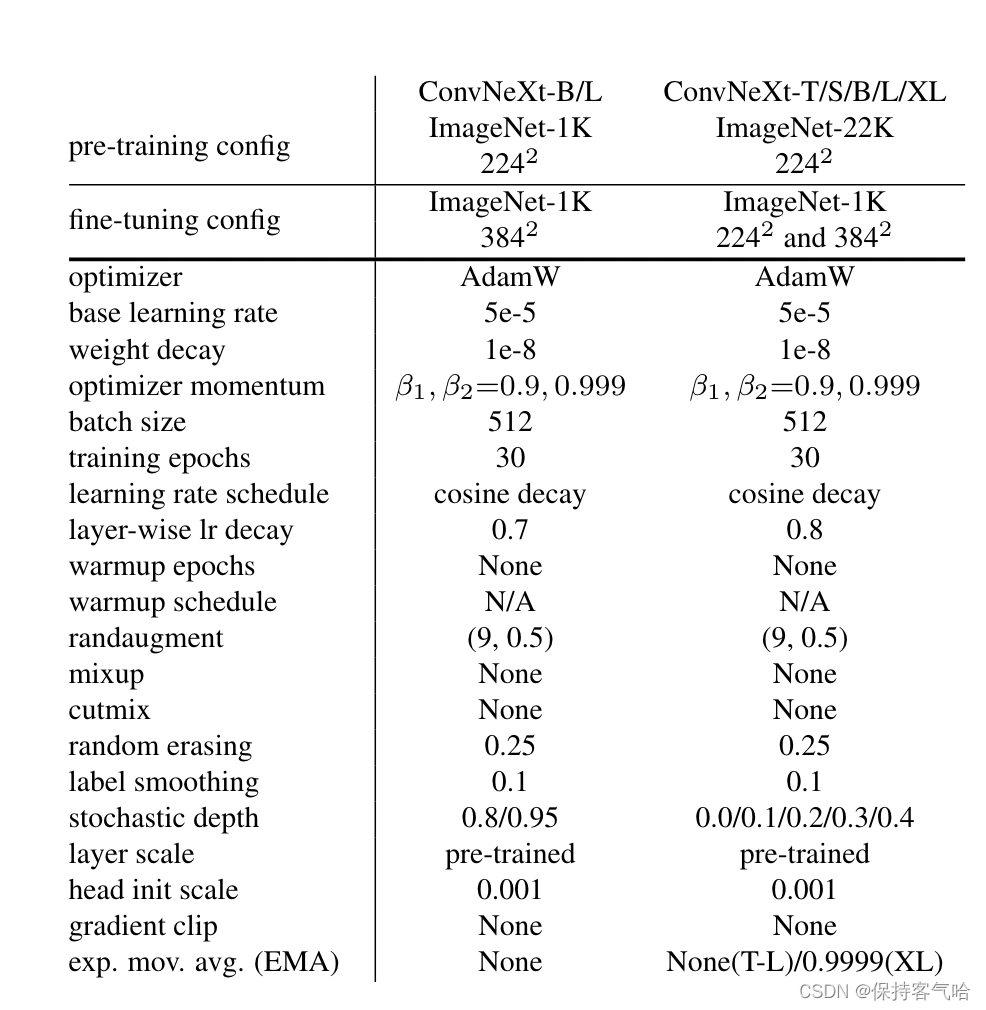
训练的epoch数从90变为了300使用AdamW优化器数据增强技术正则化方案详细参数如下: 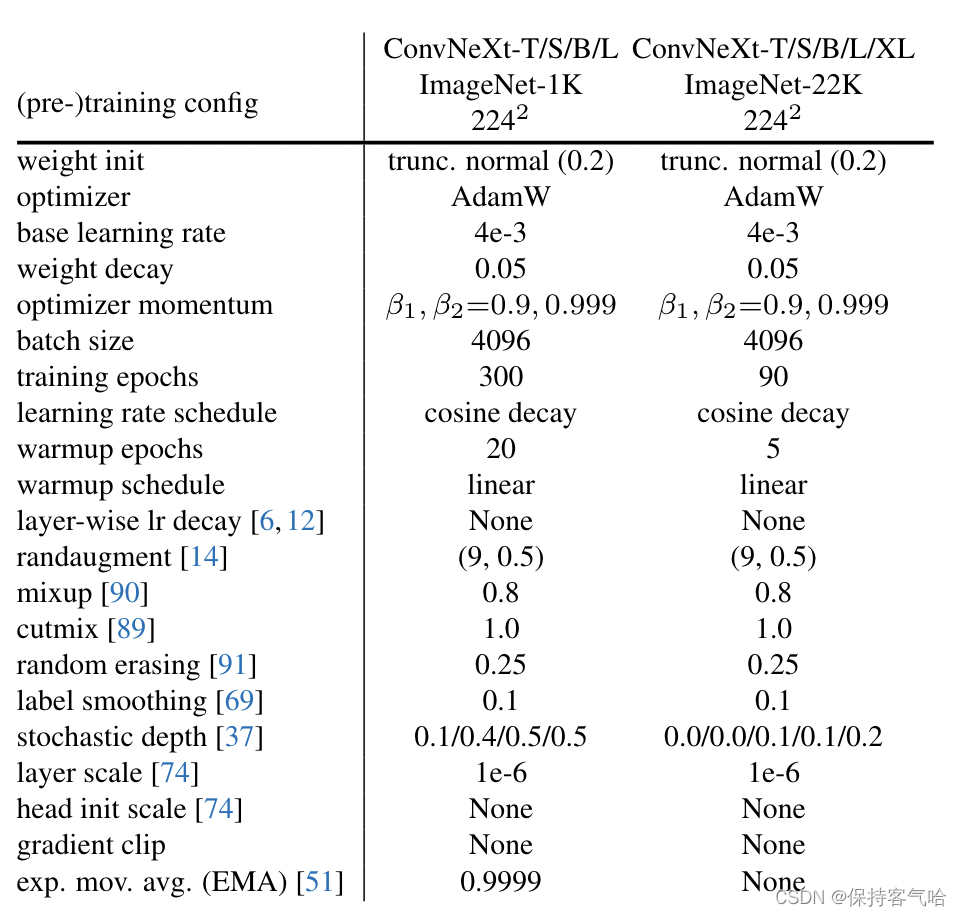
2.2 Macro design(宏观设计)
2.2.1 Changing stage compute ratio
在VGG网络中提出了把网络分成多个网络块结构,每个网络块通过池化操作将feature map下采样到不同的尺寸,在VGG网络中每个网络块的网络层结构数目是相同的,但是在之后的ResNet-50网络结构中,共有四个网络块,每个网络块有不同数量的网络层,在原来的ResNet-50网络中,一般conv4_x(即stage3)堆叠的block的次数是最多的。如下图中的ResNet50中stage1到stage4堆叠block的次数是(3, 4, 6, 3)比例大概是1:1:2:1,但在Swin Transformer中,比如Swin-T的比例是1:1:3:1,Swin-L的比例是1:1:9:1。很明显,在Swin Transformer中,stage3堆叠block的占比更高。所以作者就将ResNet50中的堆叠次数由(3, 4, 6, 3)调整成(3, 3, 9, 3),和Swin-T拥有相似的FLOPs。进行调整后,准确率由78.8%提升到了79.4%。下图是ResNet-50网络结构图: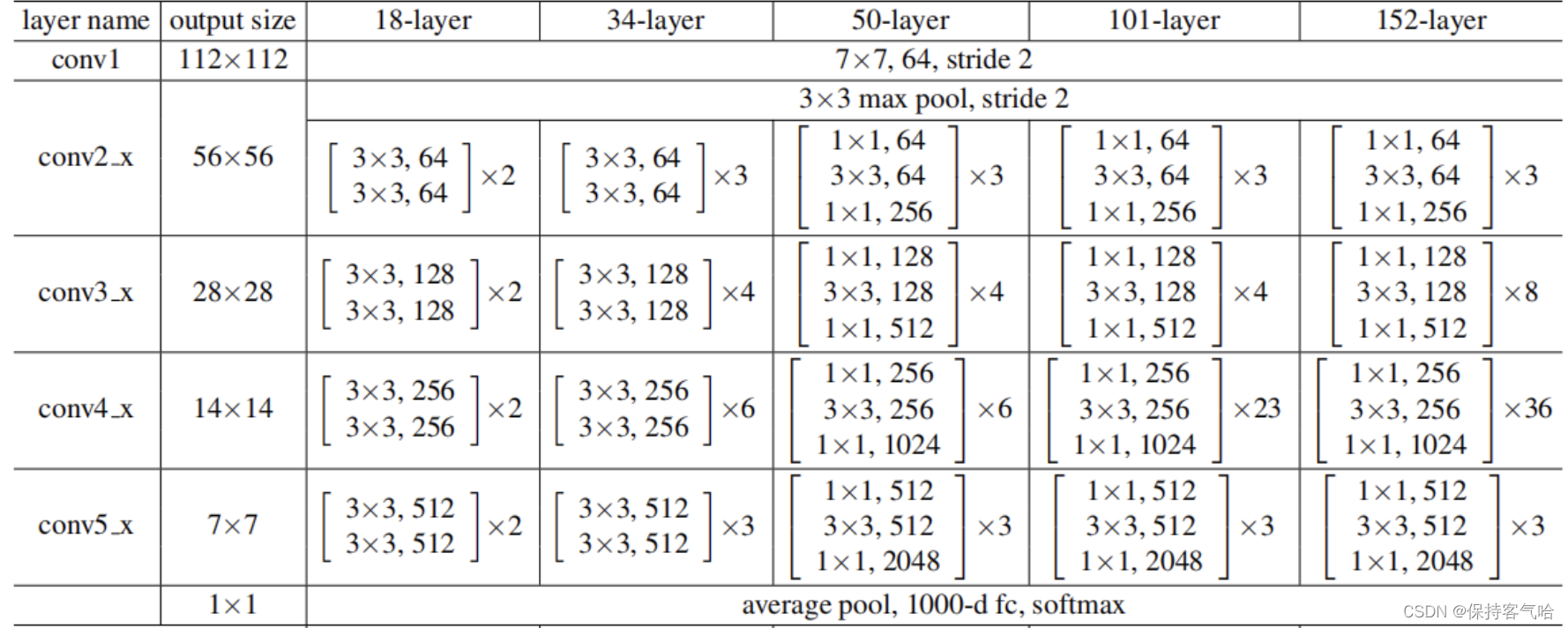
2.2.2 Changing stem to “Patchify”
对于ImageNet数据集,我们通常采用 224×224的输入尺寸,这个尺寸对于ViT等基于Transformer的模型来说是非常大的,它们通常使用一个步长为4,大小也为4的卷积将其尺寸下采样到 56×56。因为这个卷积的步长和大小是完全相同的,所以它又是一个无覆盖的卷积,或者叫Patchify(补丁化)的卷积。这一部分在Swin-Transformer中叫做stem层,它是位于输入之后的一个降采样层。在ConvNeXt中,Stem层也是一个步长为4,大小也为4的卷积操作,这一操作将准确率从79.4%提升至79.5%,GFLOPs从4.5降到4.4%。也有人指出使用覆盖的卷积(例如步长为4,卷积核大小为7的卷积)能够获得更好的表现。
2.3 ResNeXt-ify(ResNeXt化)
由于ResNeXt在FLOPs/accuracy的权衡比ResNet更优秀,于是进行了一些借鉴,主要是使用了分组卷积,它将 3×3 卷积替换成了 3×3的分组卷积,这个操作将GFLOPs从4.4降到了2.4,但是它也将准确率从79.5%降到了78.3%。
ResNeXt的指导准则是“分更多的组,拓宽width”,因此本文直接使用了depthwise conv,即分组数等于输入通道数。这个技术在之前主要是应用在MobileNet这种轻量级网络中,用于降低计算量。但在这里,作者发现dw conv由于每个卷积核单独处理一个通道,这种形式跟self-attention机制很相似,都是在单个通道内做空间信息的混合加权。将bottleneck中的3x3卷积替换成dw conv,为了弥补准确率的下降,它将ResNet-50的基础通道数从64增加至96。这个操作将GFLOPs增加到了5.3,但是准确率提升到了80.5%
2.4 Inverted Bottleneck(反瓶颈)
在标准ResNet中使用的bottleneck是(大维度-小维度-大维度)的形式来减小计算量。后来在MobileNetV2中提出了inverted bottleneck结构,采用(小维度-大维度-小维度)形式,认为这样能让信息在不同维度特征空间之间转换时避免压缩维度带来的信息损失,后来在Transformer的MLP中也使用了类似的结构,即中间粗两头细,中间层全连接层维度数是两端的4倍。
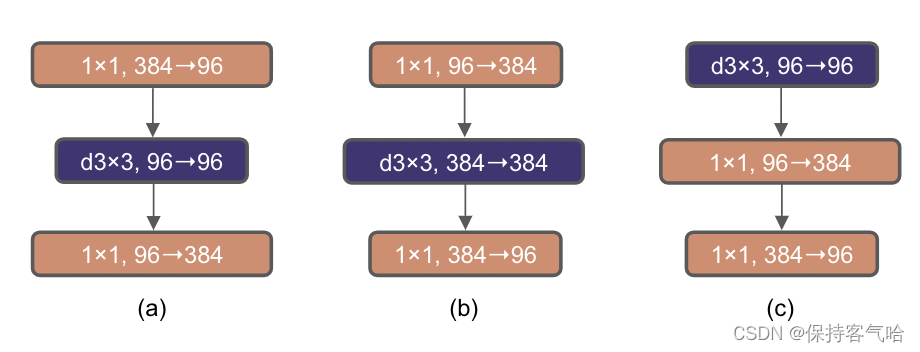
2.5 Large Kernel Sizes(更大的卷积核)
在Swin-T中使用7✖️7大小的卷积核,之前ConvNet上也使用过,但是是用3✖️3去堆加的,这样对GPU加速也好,所以作者采用了大卷积核,这里采用7*7,当然也尝试了其他的尺寸,但是发现取到7的时候就已经饱和了,又由于采用Inverted BottleNeck结构放大了中间卷积层的缘故,直接替换会导致参数量增大,因而作者把DW卷积的位置进行了调整,放到了反瓶颈的开头。最终结果相近,说明在7x7在相同参数量下效果是一致的。
2.6 Micro Design(微观设计)
Replacing ReLU with GELU,在Transformer中激活函数基本用的都是GELU,而在卷积神经网络中最常用的是ReLU,于是作者又将激活函数替换成了GELU,替换后发现准确率没变化,主要是为了对齐比较,因为Transformer中有。Fewer activation functions,使用更少的激活函数。在卷积神经网络中,一般会在每个卷积层或全连接后都接上一个激活函数。但在Transformer中并不是每个模块后都跟有激活函数,比如MLP中只有第一个全连接层后跟了GELU激活函数。接着作者在ConvNeXt Block中也减少激活函数的使用,如下图所示,减少后发现准确率从80.6%增长到81.3%。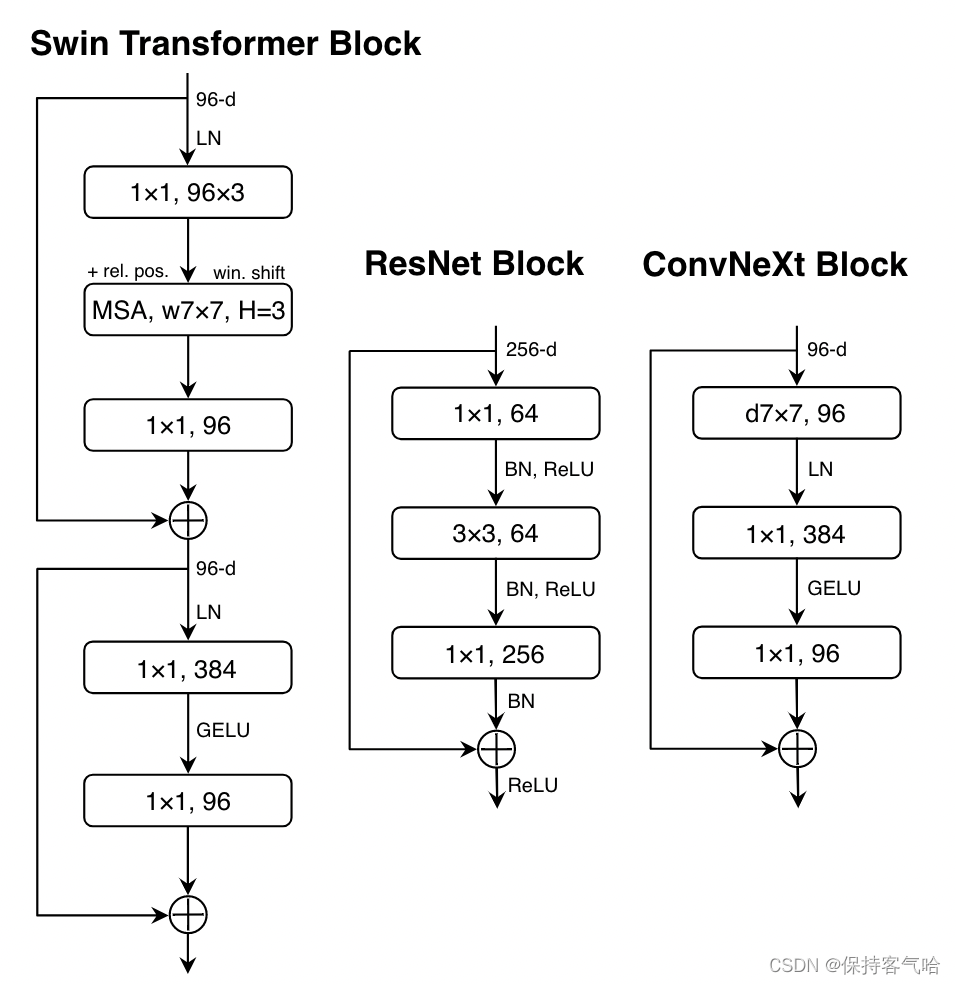
Fewer normalization layers,使用更少的Normalization。同样在Transformer中,Normalization使用的也比较少,接着作者也减少了ConvNeXt Block中的Normalization层,只保留了depthwise conv后的Normalization层。此时准确率已经达到了81.4%,已经超过了Swin-T。Substituting BN with LN,将BN替换成LN。Batch Normalization(BN)在卷积神经网络中是非常常用的操作了,它可以加速网络的收敛并减少过拟合(但用的不好也是个大坑)。但在Transformer中基本都用的Layer Normalization(LN),因为最开始Transformer是应用在NLP领域的,BN又不适用于NLP相关任务。接着作者将BN全部替换成了LN,发现准确率还有小幅提升达到了81.5%。Separate downsampling layers,单独的下采样层。在ResNet网络中stage2-stage4的下采样都是通过将主分支上3x3的卷积层步距设置成2,捷径分支上1x1的卷积层步距设置成2进行下采样的。但在Swin Transformer中是通过一个单独的Patch Merging实现的。接着作者就为ConvNext网络单独使用了一个下采样层,就是通过一个Laryer Normalization加上一个卷积核大小为2步距为2的卷积层构成。更改后准确率就提升到了82.0%。 2.7 ConvNeXt-T 结构图
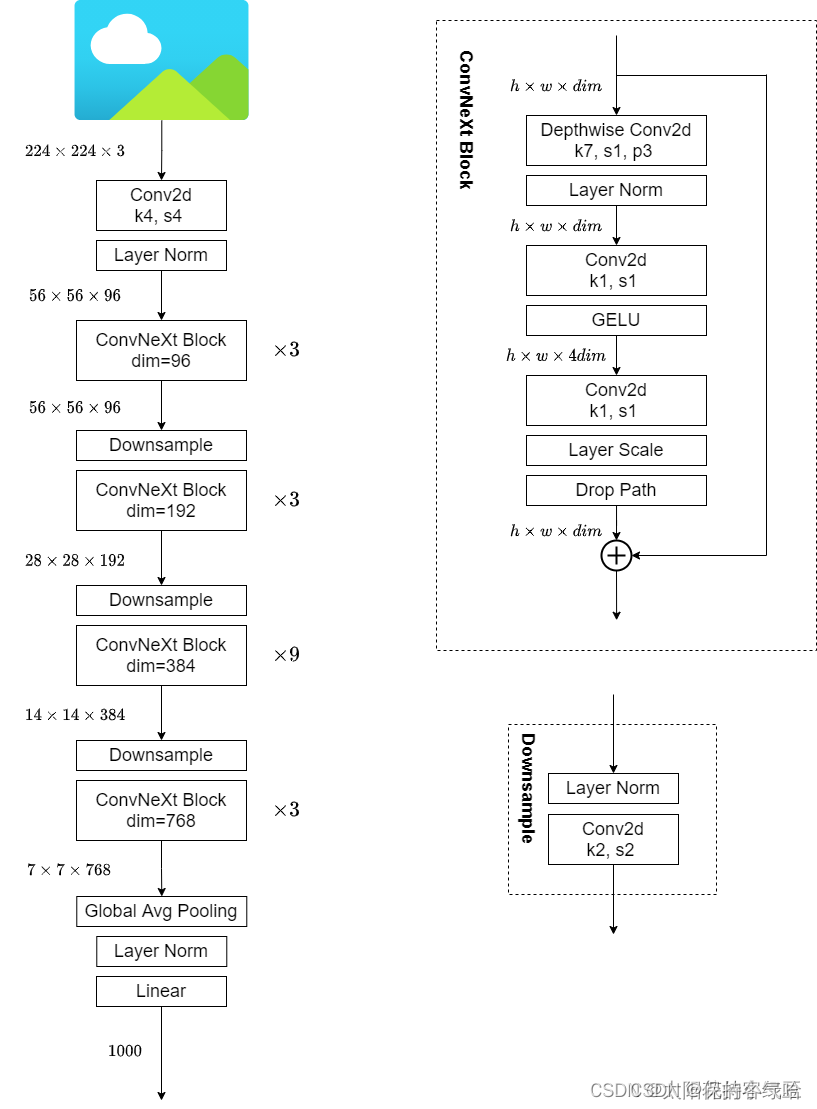
3. 总结
ConvNeXt的出现证明,并不一定需要Transformer那么复杂的结构,只对原有CNN的技术和参数优化也能达到SOTA,未来CV领域,CNN和Transformer谁主沉浮?
参考:太阳花的小绿豆