问题描述
准备使用yolov5训练自己的模型,自己将下载的开源数据集按照自己的要求重新标注了一下,然后现在对其进行划分。
问题分析
划分数据集主要的步骤就是,首先要将数据集打乱顺序,然后按照一定的比例将其分为训练集,验证集和测试集。
这里我定的比例是7:1:2。
步骤流程
1、将数据集打乱顺序
数据集有图片和标注文件,我们需要把两种文件绑定然后将其打乱顺序。
首先读取数据后,将两种文件通过zip函数绑定
each_class_image = [] each_class_label = [] for image in os.listdir(file_path): each_class_image.append(image) for label in os.listdir(xml_path): each_class_label.append(label) data=list(zip(each_class_image,each_class_label))然后打乱顺序,再将两个列表分开
random.shuffle(data) each_class_image,each_class_label=zip(*data)2、按照确定好的比例将两个列表元素分割
分别用三个列表储存一下图片和标注文件的元素
train_images = each_class_image[0:int(train_rate * total)] val_images = each_class_image[int(train_rate * total):int((train_rate + val_rate) * total)] test_images = each_class_image[int((train_rate + val_rate) * total):] train_labels = each_class_label[0:int(train_rate * total)] val_labels = each_class_label[int(train_rate * total):int((train_rate + val_rate) * total)] test_labels = each_class_label[int((train_rate + val_rate) * total):]3、在本地生成文件夹,将划分好的数据集分别保存
这样就保存好了。
for image in train_images: #print(image) old_path = file_path + '/' + image new_path1 = new_file_path + '/' + 'train' + '/' + 'images' if not os.path.exists(new_path1): os.makedirs(new_path1) new_path = new_path1 + '/' + image shutil.copy(old_path, new_path) for label in train_labels: #print(label) old_path = xml_path + '/' + label new_path1 = new_file_path + '/' + 'train' + '/' + 'labels' if not os.path.exists(new_path1): os.makedirs(new_path1) new_path = new_path1 + '/' + label shutil.copy(old_path, new_path) for image in val_images: old_path = file_path + '/' + image new_path1 = new_file_path + '/' + 'val' + '/' + 'images' if not os.path.exists(new_path1): os.makedirs(new_path1) new_path = new_path1 + '/' + image shutil.copy(old_path, new_path) for label in val_labels: old_path = xml_path + '/' + label new_path1 = new_file_path + '/' + 'val' + '/' + 'labels' if not os.path.exists(new_path1): os.makedirs(new_path1) new_path = new_path1 + '/' + label shutil.copy(old_path, new_path) for image in test_images: old_path = file_path + '/' + image new_path1 = new_file_path + '/' + 'test' + '/' + 'images' if not os.path.exists(new_path1): os.makedirs(new_path1) new_path = new_path1 + '/' + image shutil.copy(old_path, new_path) for label in test_labels: old_path = xml_path + '/' + label new_path1 = new_file_path + '/' + 'test' + '/' + 'labels' if not os.path.exists(new_path1): os.makedirs(new_path1) new_path = new_path1 + '/' + label shutil.copy(old_path, new_path)运行结果展示
直接运行单个python文件即可。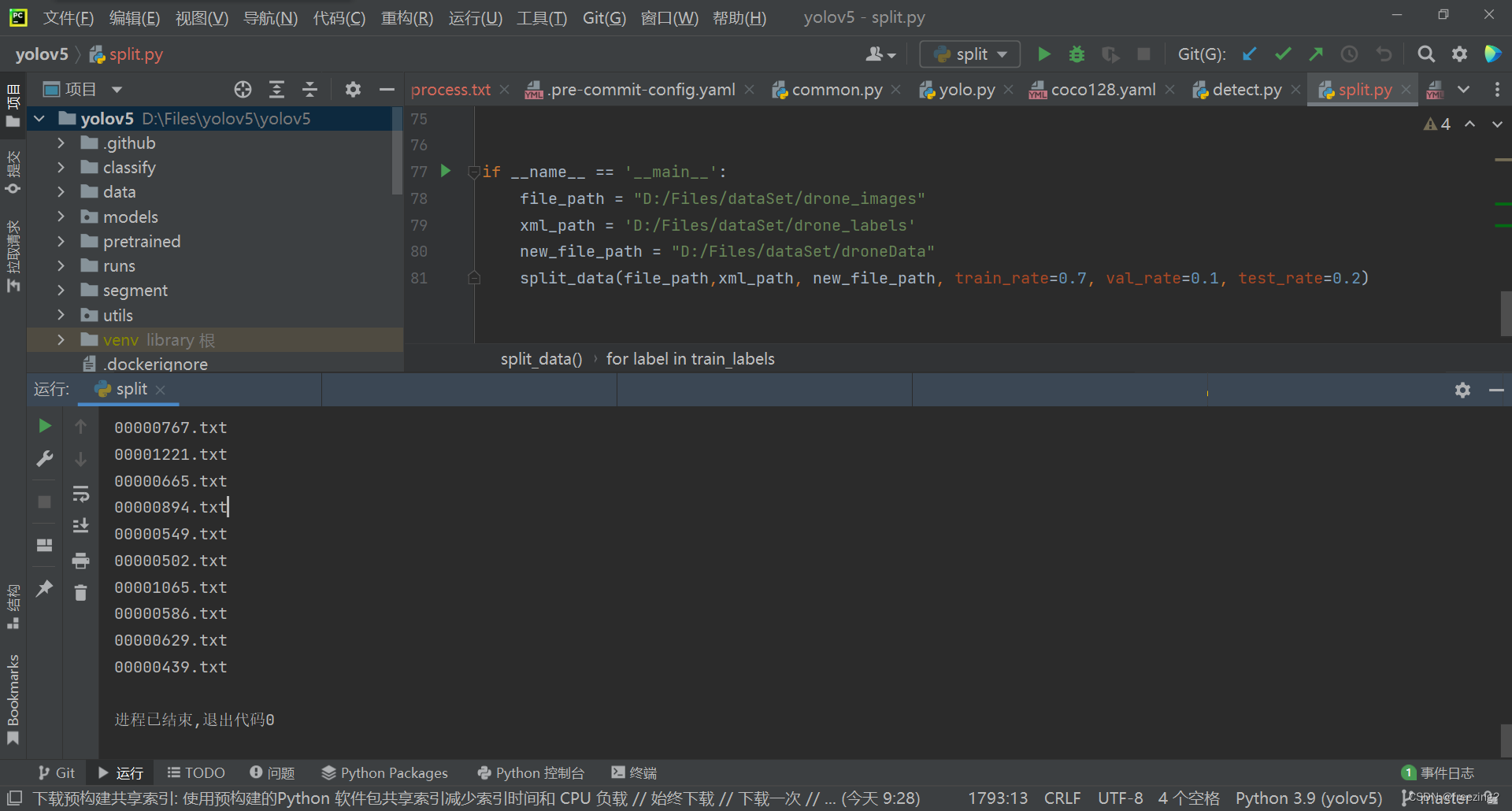
运行完毕
去本地查看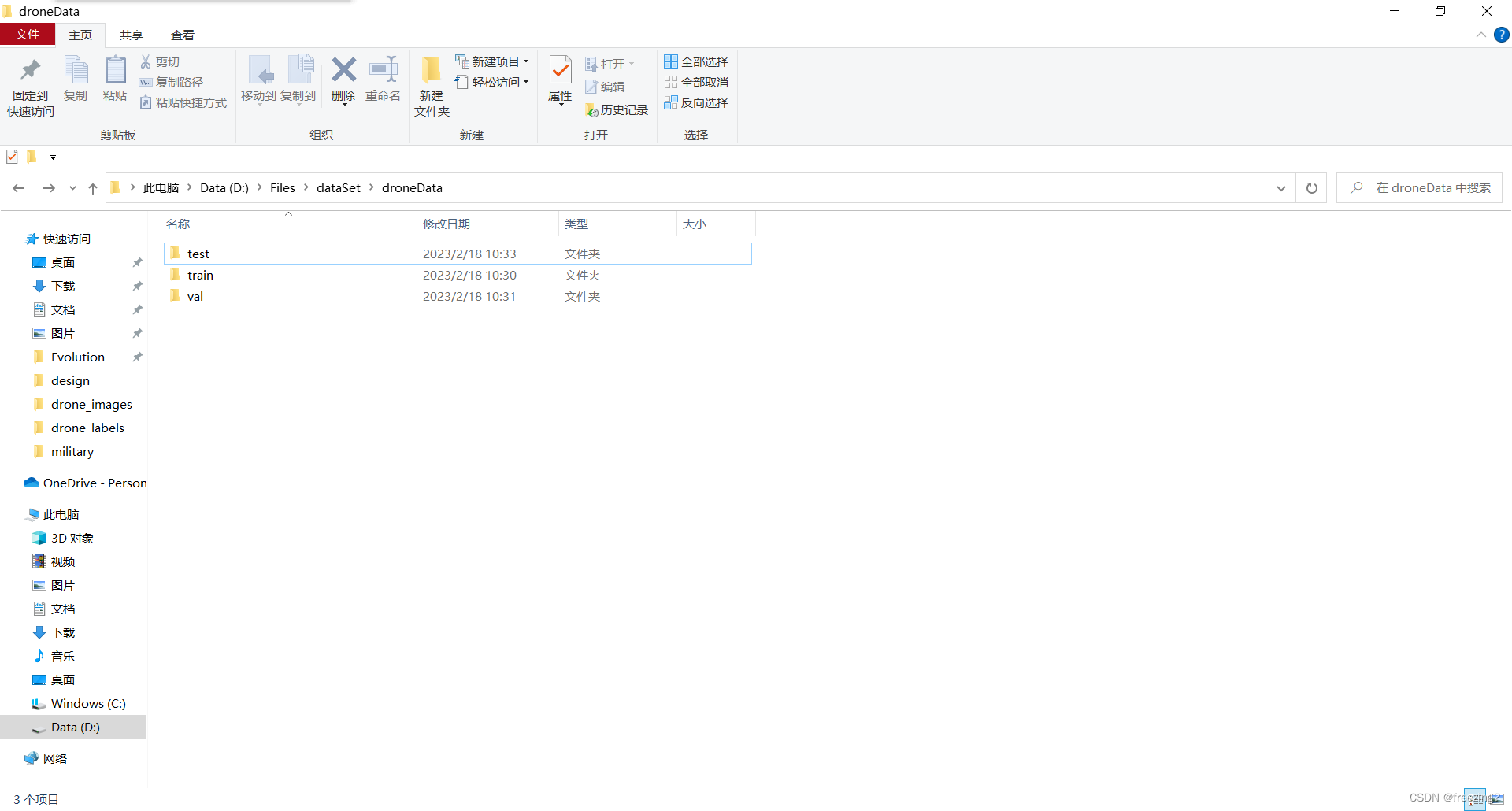
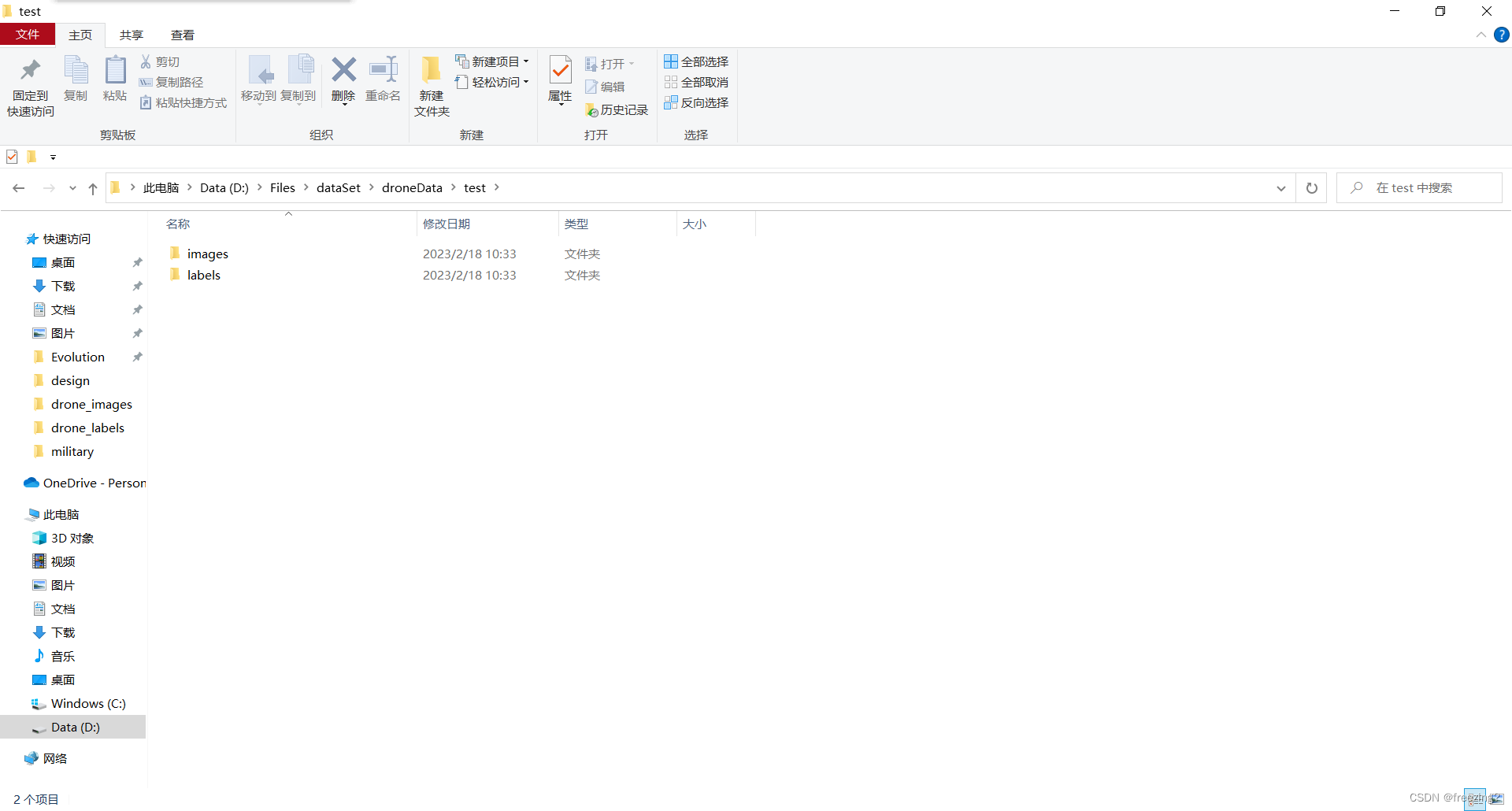
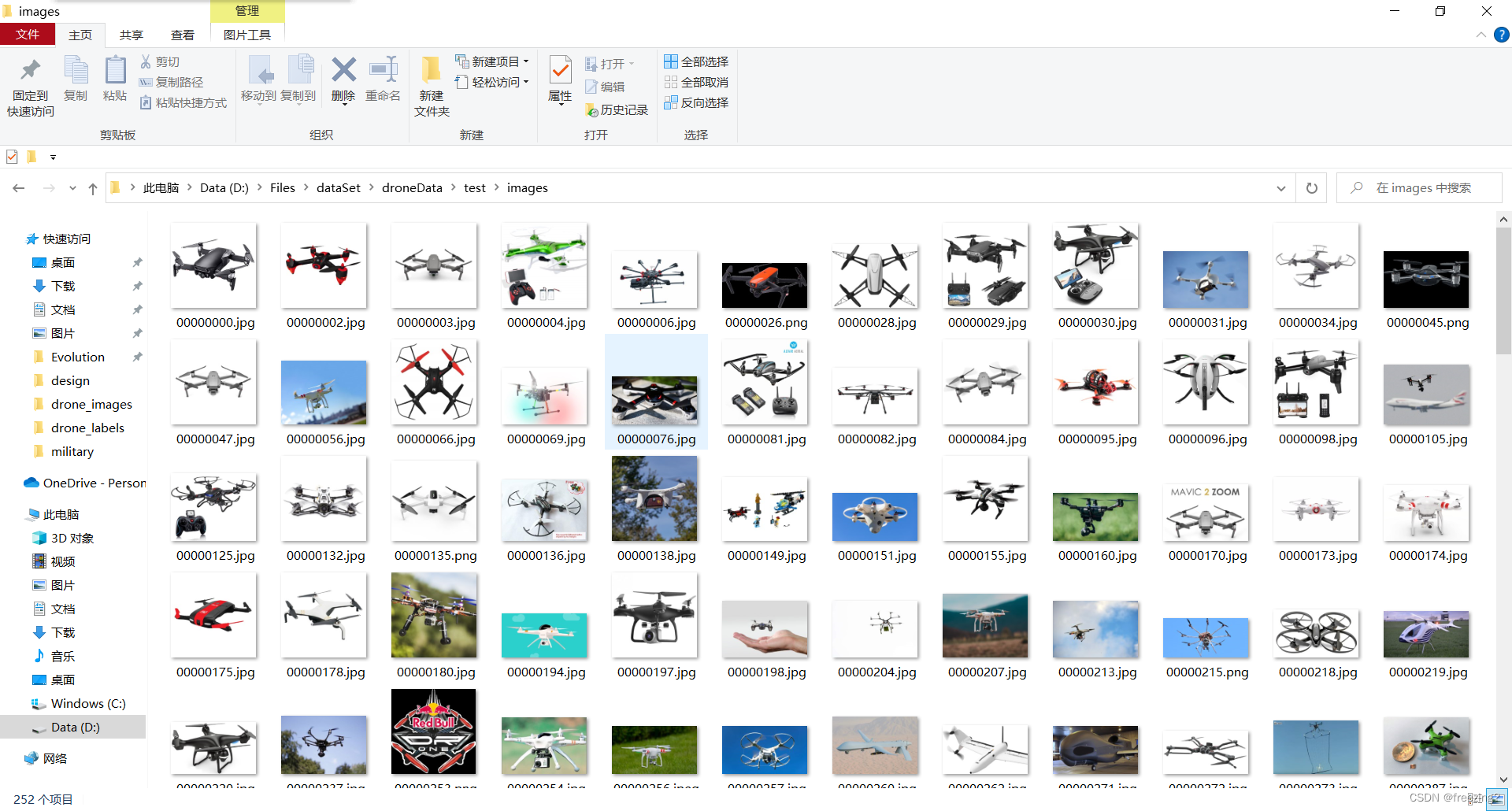
图片和标注文件乱序,且一一对应。
完整代码分享
import osimport shutilimport randomrandom.seed(0)def split_data(file_path,xml_path, new_file_path, train_rate, val_rate, test_rate): each_class_image = [] each_class_label = [] for image in os.listdir(file_path): each_class_image.append(image) for label in os.listdir(xml_path): each_class_label.append(label) data=list(zip(each_class_image,each_class_label)) total = len(each_class_image) random.shuffle(data) each_class_image,each_class_label=zip(*data) train_images = each_class_image[0:int(train_rate * total)] val_images = each_class_image[int(train_rate * total):int((train_rate + val_rate) * total)] test_images = each_class_image[int((train_rate + val_rate) * total):] train_labels = each_class_label[0:int(train_rate * total)] val_labels = each_class_label[int(train_rate * total):int((train_rate + val_rate) * total)] test_labels = each_class_label[int((train_rate + val_rate) * total):] for image in train_images: print(image) old_path = file_path + '/' + image new_path1 = new_file_path + '/' + 'train' + '/' + 'images' if not os.path.exists(new_path1): os.makedirs(new_path1) new_path = new_path1 + '/' + image shutil.copy(old_path, new_path) for label in train_labels: print(label) old_path = xml_path + '/' + label new_path1 = new_file_path + '/' + 'train' + '/' + 'labels' if not os.path.exists(new_path1): os.makedirs(new_path1) new_path = new_path1 + '/' + label shutil.copy(old_path, new_path) for image in val_images: old_path = file_path + '/' + image new_path1 = new_file_path + '/' + 'val' + '/' + 'images' if not os.path.exists(new_path1): os.makedirs(new_path1) new_path = new_path1 + '/' + image shutil.copy(old_path, new_path) for label in val_labels: old_path = xml_path + '/' + label new_path1 = new_file_path + '/' + 'val' + '/' + 'labels' if not os.path.exists(new_path1): os.makedirs(new_path1) new_path = new_path1 + '/' + label shutil.copy(old_path, new_path) for image in test_images: old_path = file_path + '/' + image new_path1 = new_file_path + '/' + 'test' + '/' + 'images' if not os.path.exists(new_path1): os.makedirs(new_path1) new_path = new_path1 + '/' + image shutil.copy(old_path, new_path) for label in test_labels: old_path = xml_path + '/' + label new_path1 = new_file_path + '/' + 'test' + '/' + 'labels' if not os.path.exists(new_path1): os.makedirs(new_path1) new_path = new_path1 + '/' + label shutil.copy(old_path, new_path)if __name__ == '__main__': file_path = "D:/Files/dataSet/drone_images" xml_path = 'D:/Files/dataSet/drone_labels' new_file_path = "D:/Files/dataSet/droneData" split_data(file_path,xml_path, new_file_path, train_rate=0.7, val_rate=0.1, test_rate=0.2)