机器学习:逻辑回归模型算法原理
作者:i阿极
作者简介:Python领域新星作者、多项比赛获奖者:博主个人首页
???如果觉得文章不错或能帮助到你学习,可以点赞?收藏?评论?+关注哦!???
???如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!?
| 订阅专栏案例:机器学习 |
|---|
| 机器学习:基于逻辑回归对某银行客户违约预测分析 |
| 机器学习:学习k-近邻(KNN)模型建立、使用和评价 |
| 机器学习:基于支持向量机(SVM)进行人脸识别预测 |
| 决策树算法分析天气、周末和促销活动对销量的影响 |
| 机器学习:线性回归分析女性身高与体重之间的关系 |
| 机器学习:基于主成分分析(PCA)对数据降维 |
| 机器学习:基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测 |
| 机器学习:学习KMeans算法,了解模型创建、使用模型及模型评价 |
| 机器学习:基于神经网络对用户评论情感分析预测 |
| 机器学习:朴素贝叶斯模型算法原理(含实战案例) |
文章目录
机器学习:逻辑回归模型算法原理1、实验目的2、实验原理3、实验环境4、乳腺癌肿瘤预测案例4.1目标4.2数据集来源4.3导入模块4.4加载数据4.5数据清洗4.6划分训练集和测试集4.7标准化处理4.8建立逻辑回归模型 5、模型评估总结
1、实验目的
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
在这个信息爆炸的时代,如何高效处理数据并利用数据推动决策显得尤为重要,这便是人们通常所说的“数据分析”。与数据分析相伴而生的机器学习(Machine Learning),有些人可能会感到陌生,然而说到战胜了众多人类围棋高手的智能机器人AlphaGo,想必大多数人都有所耳闻。AlphaGo背后的原理支撑就是机器学习,它通过模拟人类的学习行为,不停地分析海量的围棋数据,发现数据背后的规律,从而在已有条件下做出最为理性的决断,这个过程充满了机器美学。
2、实验原理
逻辑回归模型虽然名字中有回归两字,其本质却是分类模型。
分类模型与回归模型的区别在于其预测的变量不是连续的,而是离散的一些类别,以最常见的二分类模型为例,分类模型可以预测一个人是否会违约、客户是否会流失、肿瘤是属于良性肿瘤还是恶性肿瘤等
逻辑回归模型的算法原理中同样涉及了之前线性回归模型中学习到的线性回归方程: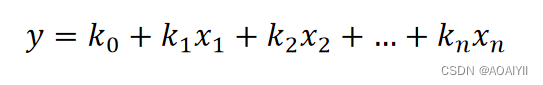
上面这个方程是预测连续变量的,其取值范围属为负无穷到正无穷,而逻辑回归模型是用来预测类别的,比如它预测某物品是属于A类还是B类,它本质预测的是属于A类或者B类的概率,而概率的取值范围是0-1,因此我们不能直接用线性回归方程来预测概率。
需要到用到下图所示的Sigmoid函数,该函数可以将取值为(-∞, +∞)的数转换到(0,1)之间,例如倘若y=3,那个通过Sigmoid函数转换后,f(y)就变成了1/(1+e^-3)=0.95了,这就可以作为一个概率值使用了。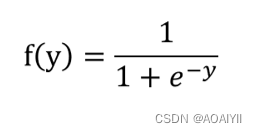
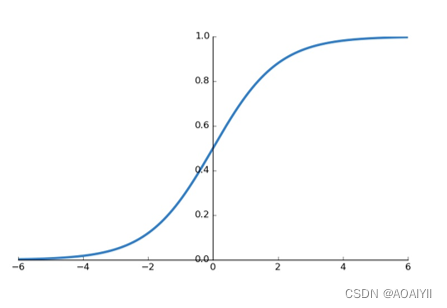
可以通过如下代码绘制Sigmoid函数:
import matplotlib.pyplot as pltimport numpy as npx = np.linspace(-6, 6) y = 1.0 / (1.0 + np.exp(-x)) plt.plot(x,y) plt.show() 通过linspace()函数生成-6到6的等差数列,默认50个数.
Sigmoid函数计算公式,exp()函数表示指数函数

如果对Sigmoid函数还是感到有点困惑,则可以参考下图的一个推导过程,其中y就是之前提到的线性回归方程,其范围是(-∞, +∞),那么指数函数的范围便是(0, +∞),再做一次变换,的范围就变成(0, 1)了,然后分子分母同除以就获得了我们上面提到的Sigmoid函数了。
逻辑回归模型本质就是将线性回归模型通过Sigmoid()函数进行了一个非线性转换得到一个介于0到1之间的概率值,对于二分类问题(分类0和1)而言,其预测分类为1(或者说二分类中数值较大的分类)的概率如下图所示: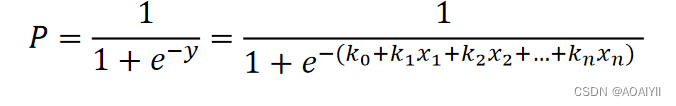
因为概率和为1,则分类为0(或说二分类中数值较小的那个分类)的概率为1-P: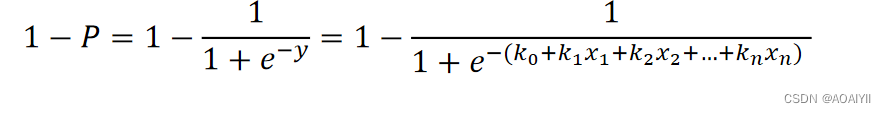
3、实验环境
Python3.9
Anaconda
Jupyter Notebook
4、乳腺癌肿瘤预测案例
4.1目标
根据历史女性乳腺癌患者数据集(医学指标)构建逻辑回归分类模型进行良/恶性乳腺癌肿瘤预测
4.2数据集来源
数据集源于威斯康星州临床科学中心。每个记录代表一个乳腺癌的随访数据样本。这些是DR Wolberg自1984~1995随访搜集连续乳腺癌患者数据,数据仅包括那些具有侵入性的病例乳腺癌并没有远处转移的医学指标数据集。
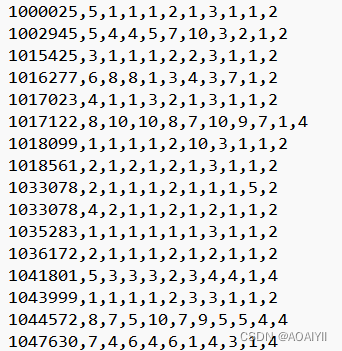
4.3导入模块
import pandas as pdimport numpy as npimport warningswarnings.filterwarnings('ignore')from sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import classification_report4.4加载数据
定义列名并导入数据
column_names = ['样本代码','肿块厚度','均匀细胞大小','均匀细胞形状','边缘粘连','单一上皮细胞大小','裸核', '乏味染色体','正常核','有丝分裂','分类']data = pd.read_csv('/home/kesci/breast-cancer-wisconsin.data',names=column_names)print(data.shape)4.5数据清洗
删除缺失值
data = data.replace('?',np.nan) data = data.dropna(how='any') print(data.shape)
4.6划分训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(data[column_names[1:10]],data[column_names[10]], test_size=0.25)4.7标准化处理
ss = StandardScaler()X_train = ss.fit_transform(X_train)X_test = ss.transform(X_test)4.8建立逻辑回归模型
lr = LogisticRegression(C=1.0,penalty='l1',solver='liblinear')lr.fit(X_train,y_train)y_pred = lr.predict(X_test)5、模型评估
print('预测结果准确性:',lr.score(X_test,y_test))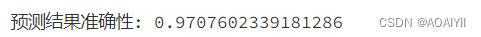
print('预测结果准确性:',classification_report(y_test,y_pred,target_names=['良性', '恶性']),sep='\n')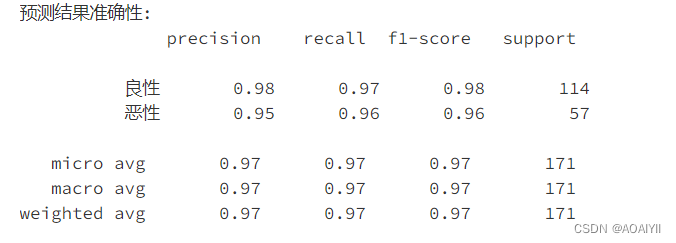
总结
分类模型与回归模型的区别在于其预测的变量不是连续的,而是离散的一些类别,例如,最常见的二分类模型可以预测一个人是否会违约、客户是否会流失、肿瘤是良性还是恶性等。本章要学习的逻辑回归模型虽然名字中有“回归”二字,但其在本质上却是分类模型。
?主页:博主个人首页
?文章下方有交流学习区!一起学习进步!???
?创作不易,你的支持和鼓励是我创作的动力❗❗❗