众数问题(分治方法解决)
众数问题(分治方法解决)
问题描述算法思路与代码实现方法一:排序遍历法代码1:排序遍历法方法二:分治法代码2:分治法 代码测试算法心得和复杂度分析
问题描述
给定含有n个元素的多重集合S,每个元素在S中出现的次数称为该元素的重数。多重集S中最大的元素称为众数。给定一个n个自然数组成的多重集合S,设计算法求其众数和重数。
题目源于:王晓东.《计算机算法设计与分析》.第5版习题2-14
例如:给出 S = [ 1 , 2 , 3 , 4 , 5 , 2 ] S = [1,2,3,4,5,2] S=[1,2,3,4,5,2] 其众数是2,重数是2
算法思路与代码实现
方法一:排序遍历法
将多重集合S中的元素存入一个整型数组当中,对该数组进行排序。排序后,数组相同的元素都会相邻出现。遍历整个数组,记录在遍历过程中记录各个元素及其重数,其中重数最大的元素便是要求得的众数。
具体算法实现思路用以下伪代码说明:
int n; scanf("%d",&n); //记录集合的总元素个数int *arr = scanf(arr); //输入集合元素Quick_Sort(arr,n,0,n-1);//对集合元素进行排序(这里是快速排序)// 遍历数组找众数int z=-1,c=-1;//最终的众数,重数 (假设元素都是正数)int zt=-1,ct=-1;//临时众数和重数 (假设元素都是正数)//遍历数组,用类似打擂台法的方法最大的重数和其对应的众数for(i->1~n){if(arr[i]!=zt){ //发现新元素时记录下来,同时记录他的重数zt = arr[i]; ct = 1;}else if(arr[i]==zt){//排序后相同元素都相邻,如果还是旧元素,增加其记录的重数。ct++;}if(ct>c){ // 如果最大重数的值发生改变,则记录下来。(类似打擂台)c = ct;z = zt;}}printf(z,c);// 输出结果代码1:排序遍历法
#include<stdio.h>#include<stdlib.h> // standard_library//快速排序 int Quick_Sort(int *data,int data_lenth,int low,int high){ if(low<high){ int pkey = data[low],t; int low2 = low,high2 = high; while(low2<high2){ while(low2<high2 && data[high2]>=pkey)high2--; data[low2] = data[high2]; while(low2<high2 && data[low2]<=pkey)low2++; data[high2] = data[low2]; } data[low2] = pkey; int ploc = low2; Quick_Sort(data,data_lenth,low,ploc-1); Quick_Sort(data,data_lenth,ploc+1,high); } return 1; }int main(){ int n; printf("n="); scanf("%d",&n); int *arr = (int*)malloc(sizeof(int)*n); for(int i=0;i<n;i++){ scanf("%d",&arr[i]); } Quick_Sort(arr,n,0,n-1); int z=-1,c=-1;//众数,重数 int zt=-1,ct=-1;//临时众数和重数 , 打擂台法 for(int i=1;i<n;i++){ if(arr[i]!=zt){ zt = arr[i]; ct = 1; }else if(arr[i]==zt){ ct++; } if(ct>c){ c = ct; z = zt; } } printf("---------\n%d\n%d\n",z,c); return 0;}方法二:分治法
同样将多重集合S中的元素存入一个整型数组当中,采用分治的思想,选取一个基准数,将比基准数小的放于左侧,比基准数大的放与右侧(类似于一轮快速排序)。此时比较左部分重数最大的数,右部分重数最大的数,基准数的重数这三个数,其中重数最大的便是整个集合S的众数。这样一来,原问题就得到了分解,可以采用分治法写递归函数求解。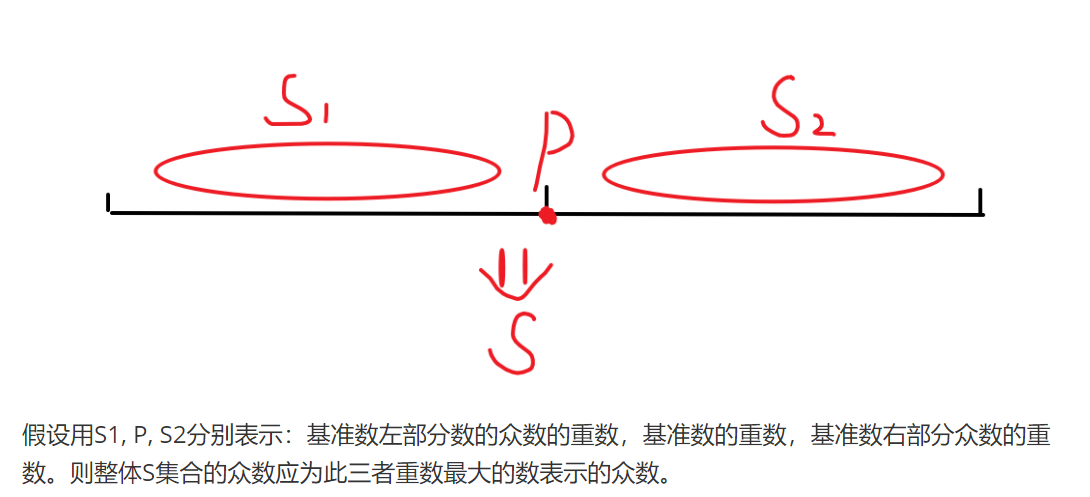 具体算法实现思路用以下伪代码说明:
具体算法实现思路用以下伪代码说明:
int* GetMode(int *data,int data_lenth,int low,int high){//本递归函数由快速排序修改而来,data是输入数据,data_lenth是元素的个数,low是开始寻找的左侧下标,high为开始寻找的右侧下标。//函数返回一个含有两个元素的数组,分别记录众数和重数。int *p = (int*)malloc(sizeof(int)*2); //明确了递归函数的边界条件,当只有一个元素时,元素的众数是他本身,重数是1.p[0] = data[low]; p[1] = 1; //选出基准数,将较小者置于左侧,较大者置于右侧,并统计基准数的重数if(low<high){int pkey = data[low],t;// 基准数默认选取最左侧数,重数默认是1//以下操作将较小者置于左侧,较大者置于右侧,与进行一轮快速排序相同。int low2=low,high2 = high;while(low2<high2){while(low2<high2&&data[high2]>=pkey){if(data[high2]==pkey)p[1]++;//记录重数high2--; }data[low2] = data[high2];while(low2<high2&&data[low2]<=pkey){if(data[low2]==pkey)p[1]++;//记录重数low2++;}data[high2] = data[low2];}data[low2] = pkey; int ploc = low2;//左部分众数 int *p2 = GetMode(data,data_lenth,low,ploc-1); //右部分众数 int *p3 = GetMode(data,data_lenth,ploc+1,high);//在左右部分众数和基准数中,选取重数最大if(p2[1] > p3[1]);else p2 = p3;if(p[1] > p2[1]);else p = p2;}return p;//将结果以指针形式返回 }int main(){int n; scanf("%d",&n); //记录集合的总元素个数int *arr = scanf(arr); //输入集合元素int *p = GetMode(arr,n,0,n-1);// 调用递归函数printf(p[0],p[1]);//输出结果}代码2:分治法
#include<stdio.h>#include<stdlib.h> // standard_libraryint* GetMode(int *data,int data_lenth,int low,int high){ int *p = (int*)malloc(sizeof(int)*2); p[0] = data[low]; p[1] = 1; if(low<high){ int pkey = data[low],t; int low2=low,high2 = high; while(low2<high2){ while(low2<high2&&data[high2]>=pkey){ if(data[high2]==pkey)p[1]++; // 记录基准数的众数 high2--; } data[low2] = data[high2]; while(low2<high2&&data[low2]<=pkey){ if(data[low2]==pkey)p[1]++; // 记录基准数的众数 low2++; } data[high2] = data[low2]; } data[low2] = pkey; int ploc = low2; int *p2 = GetMode(data,data_lenth,low,ploc-1); //左部分众数 int *p3 = GetMode(data,data_lenth,ploc+1,high); //右部分众数 if(p2[1] > p3[1]); else p2 = p3; if(p[1] > p2[1]); else p = p2; } return p; }int main(){ int n; printf("n="); scanf("%d",&n); int *arr = (int*)malloc(sizeof(int)*n); for(int i=0;i<n;i++){ scanf("%d",&arr[i]); } int *p = GetMode(arr,n,0,n-1); printf("------\n%d\n%d\n",p[0],p[1]);return 0;}其实还可以用构建哈希表的方法解决这个问题,复杂度也会降到O(n),具体涉及到用什么哈希算法,就先挖个坑先不写。
代码测试
测试用例2:
11
2
2
2
1
5
3
5
7
5
5
5
算法心得和复杂度分析
复杂度分析:
方法一:排序遍历法
此方法的时间消耗主要来源于排序和寻找众数的遍历。排序的时间消耗取决于所使用的排序算法,这里上文程序中使用的是快速排序,时间复杂度为O(nlogn)。寻找众数的遍历是打擂台方法的一个变形,只需要遍历数组一次,时间复杂度为O(n)。故总体算法时间复杂度为O(nlogn)
方法二:分治法
此算法的递归函数由快速排序修改而来,只是修改了函数返回类型以及记录了基准数的出现个数,故而整体算法的时间复杂度仍然是O(n*logn)
其他心得:
我在写第二种方法的时候,虽有大概的思路,但却纠结老久在取出基准数的相同数的问题。以为基准数左侧与右侧可能出现的与基准数相同的数会影响递归函数的结果,因此一直在想如何将这些与基准数相同的数剔除。但实际上,这些相同数的存在并不会影响最终的结果,因为就算基准数左侧或右侧的部分得到的众数与基准数相同,其重数也绝不会比基准数的重数大,因为中心的基准数不参与计算左右侧的众数计算,导致如果任意一侧的众数与基准数相同时,基准数的重数至少比对应左右侧众数的重数大1。
所以,在设计算法时,有些数据可能在经过某个环节后就没有用了,但其未必会影响算法的正常运行流程,强行取除反而可能导致程序工作量增加。
登录后可发表评论
点击登录