文章目录
一、前言二、什么是进程地址空间三、进程地址空间如何进行管理四、为什么会存在进程地址空间五、进程地址空间区域的严格划分
一、前言
学习Linux系统编程一共要翻越三座大山 – 进程地址空间、文件系统以及多线程,这三部分内容很难但是非常重要;而今天我们将要征服的就是其中的第一座高山 – 进程地址空间。
二、什么是进程地址空间
我们以前在学习 C/C++ 的动态内存管理的时候,通常把地址空间划分为如下几个区域: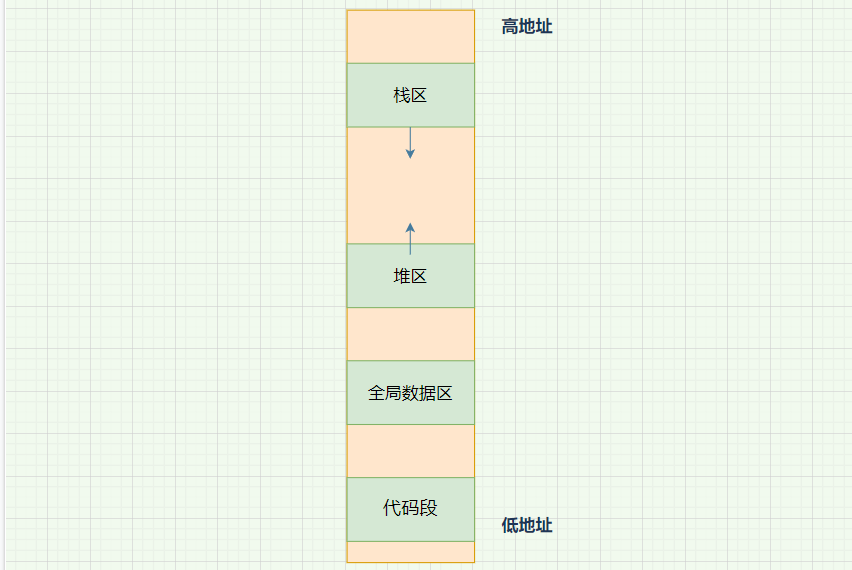
但是我们上面的地址空间是真正的物理空间吗?我们以一个例子来测试:
#include <stdio.h>#include <sys/types.h>#include <unistd.h>int g_val = 100;int main(){ int id = fork(); if(id < 0) { perror("fork fail"); return 1; } else if(id == 0) { int cnt = 0; while(1) { if(cnt == 5) { g_val = 200; printf("子进程已经修改了全局变量...........................\n"); } cnt++; printf("我是子进程,pid:%d, ppid:%d, g_val:%d, &g_val:%p\n", getpid(), getppid(), g_val, &g_val); sleep(1); } } else { while(1) { printf("我是父进程,pid:%d, ppid:%d, g_val:%d, &g_val:%p\n", getpid(), getppid(), g_val, &g_val); sleep(1); } } return 0;}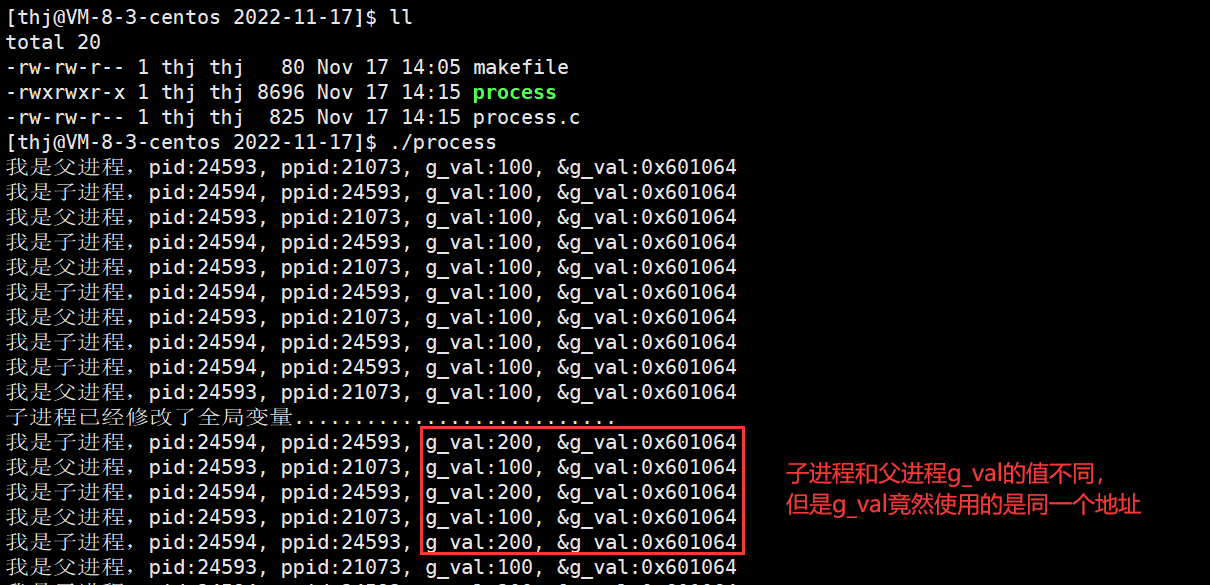
我们可以看到,当子进程修改了全局变量 g_val 的值以后,子进程和父进程的 g_val 不同,这是正常的,因为我们在上一节进程概念中就说过,进程具有独立性,不同进程之间互不影响,包括父子进程;但是这里还发生了一个神奇的现象 – 子进程和父进程 g_val 的地址竟然是一样的!
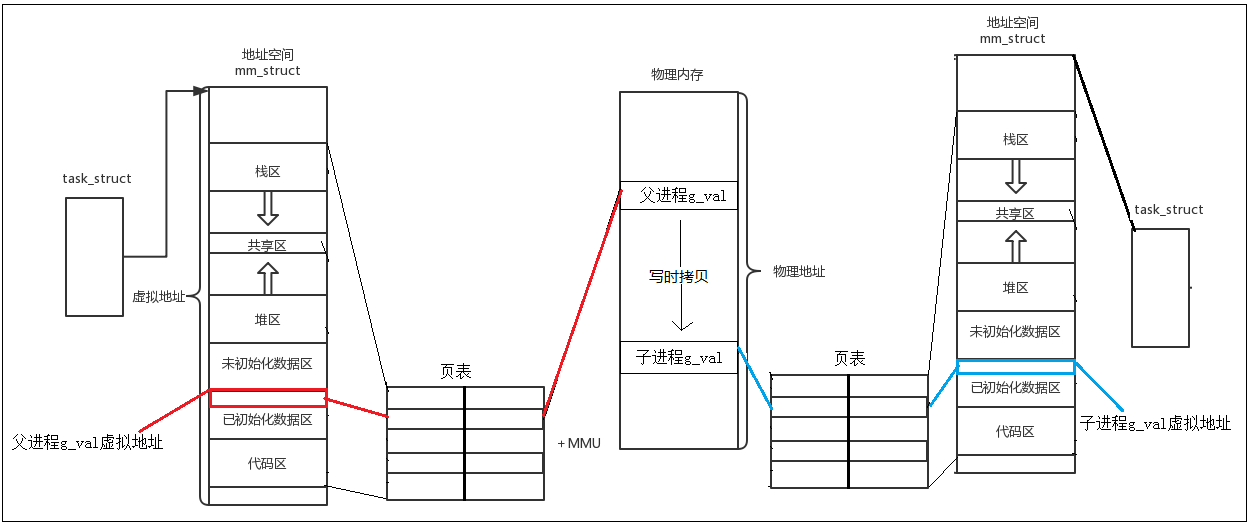
这说明了我们上面得到的 g_val 的地址不是真实的地址 (物理地址) – 因为在同一时间内一个物理地址中只能存储一个进程的数据,不同进程的不同数据不可能同时存在于同一个物理内存中,所以出现上面这种状况的原因只能是我们得到的地址不是物理地址。
实际上操作系统会给每一个进程都创建一个独立的虚拟地址空间,然后通过页表将虚拟地址空间与物理内存一一对应 (映射),我们用户只能得到虚拟地址空间中的虚拟地址,当我们修改虚拟地址中的数据时,操作系统会先通过页表找到对应的物理内存,然后修改物理内存中的数据。
此时,我们就能解释上面的现象了 – 子进程和父进程都拥有自己的单独的进程地址空间,且子进程的地址空间是从父进程那里拷贝来的,所以最开始二者的 g_val 其实指向同一块物理内存;
现在子进程想要修改自己地址空间中 g_val 的值,当操作系统通过页表找到 g_val 的物理内存时,发现 g_val 是被两个进程共同指向的,为了保证进程的独立性,OS 会在物理内存中寻找一块新空间,然后将原空间的数据拷贝到新空间,再修改子进程的页表映射关系,最后再修改新空间中 g_val 的值,上述过程叫做 写时拷贝。
所以虽然子进程和父进程 g_val 的虚拟地址相同,但是它们通过各自的页表映射到的物理地址是不相同的,自然也可以从物理内存中取出不同的数据。
注:在操作系统中,进程地址空间中的地址通常也被称为线性地址,因为它是按比特位从全0到全1依次顺序编址的;磁盘程序内部的地址通常被称为逻辑地址;在其他地方,线性地址、虚拟地址、逻辑地址区分比较严格,但是在Linux中,三者的意思是一样的,都表示虚拟地址,大家不用过于区分。
Tips:OS 为每个进程都创建独立的地址空间就相当于给每个进程都画了一个"大饼",即告诉每个进程:“你享有计算机中的所有资源,整个系统内存都是你的,你快来用吧!” 而实际上,一旦某个进程申请的内存过大时,OS 会直接拒绝进程的请求。
三、进程地址空间如何进行管理
OS 如何管理进程地址空间
OS 会为系统中的每一个进程都创建一个进程地址空间,但是 OS 内部同时存在着许多进程,所以为了保证各个进程正常运行,OS 需要对每个进程的地址空间进行管理。
那么 OS 如何对进程地址空间进行管理呢?在学习了 【Linux】计算机的软硬件体系结构 后,对于这个问题,相信大家已经能够轻松拿捏了 – 管理的本质是对数据进行管理,管理的方法是先描述,再组织。
所以和管理进程一样,操作系统会使用一种内核数据结构来对地址空间进行管理,Linux中用于 管理地址空间的内核数据结构叫做 mm_struct,操作系统会为每个进程创建一个 mm_struct 对象,然后通过管理结构体对象来间接管理进程地址空间。
Linux 中 mm_struct 源码如下: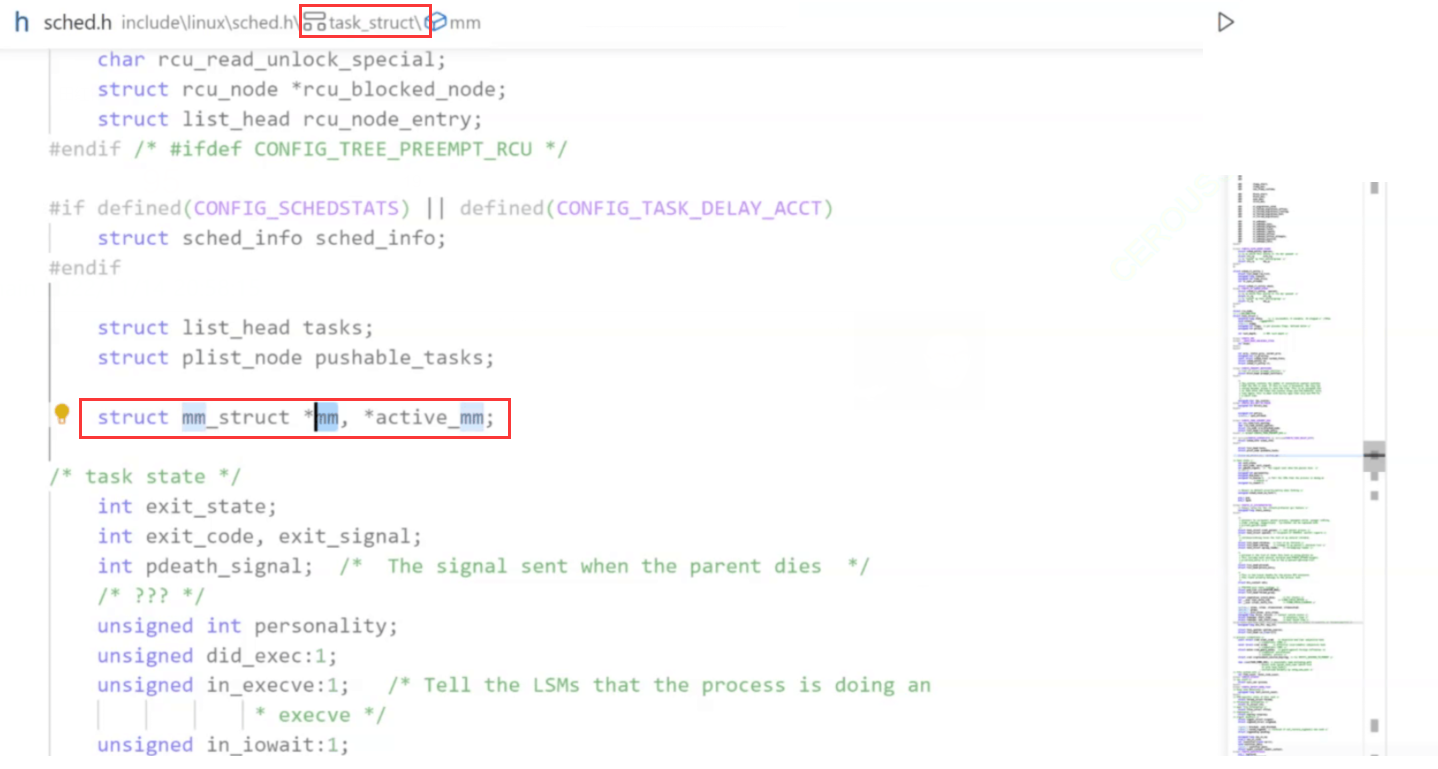
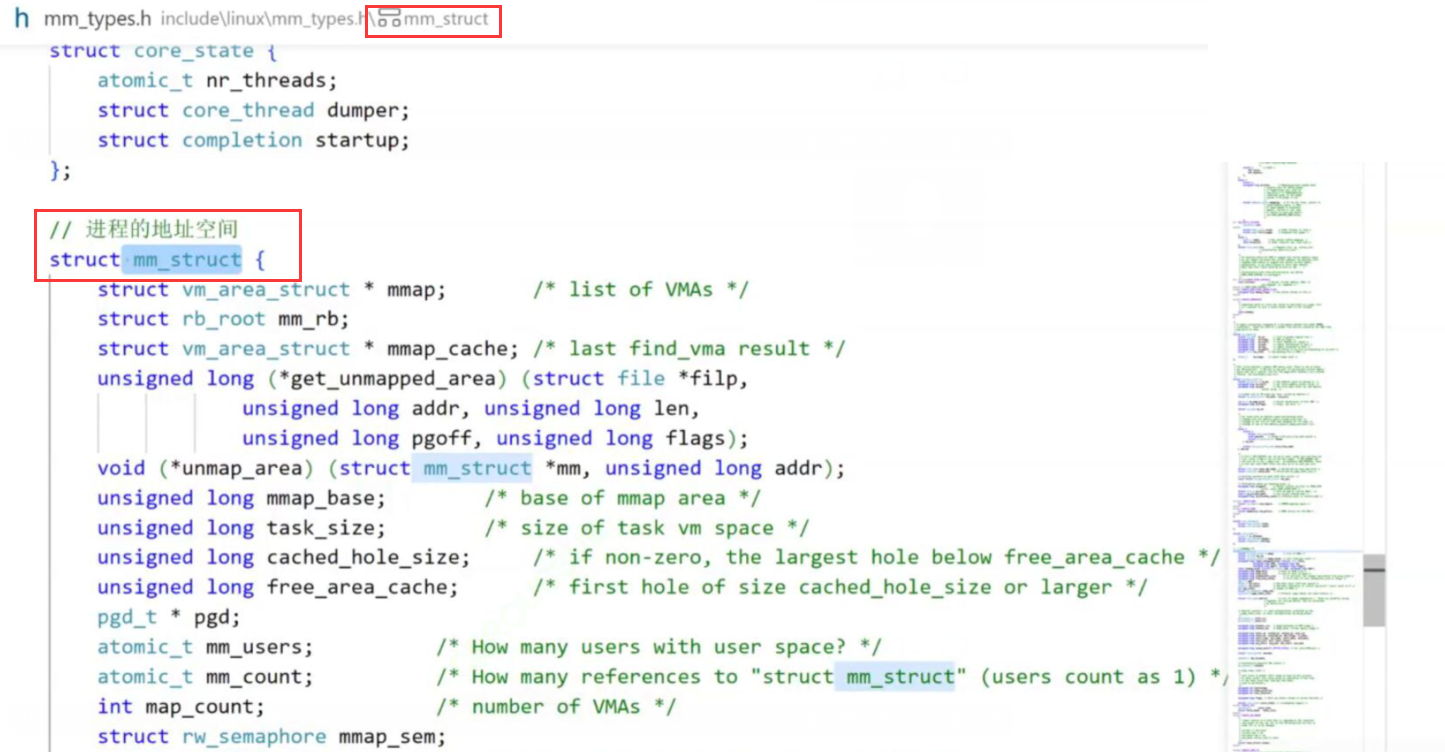
可以看到,进程地址空间其实也是进程属性的一种,我们可以通过进程的 task_struct 来找到/管理进程对应的地址空间。
进程地址空间如何进行区域划分以及区域调整
我们知道进程地址空间被划分为很多个区域,其中我们熟知的有堆区、栈区、已初始化全局数据区、未初始化全局数据区、代码段,那么操作系统如何对这些区域进行划分和管理呢?答案是用通过两个表示区域边界的变量 start、end 来维护一块内存区域,比如:
struct mm_struct { //uint32_t:32位系统下的无符号整型uint32_t code_start, code_end; uint32_t date_start, code_end; uint32_t heap_start, heap_end; unit32_t stack_start, stack_end; ...};Linux mm_struct 中关于区域划分的部分源码如下:
在了解了区域划分的原理之后,地址空间的区域调整就变得很简单了 – 要调整一个区域的大小,调整 mm_struct 中维护此区域 start 和 end 变量即可。
四、为什么会存在进程地址空间
我们上面学习了什么是进程地址空间,以及进程地址空间如何进行管理,那么为什么会存在进程地址空间呢?我们直接将数据存入物理内存不好吗?为什么还要耗费时间和空间创建虚拟地址空间以及页表呢?这时候就需要引入进程地址空间的优势了,进程地址空间主要有如下三方面的优势。
1、进程地址空间保证了数据的安全性。
我们为每一个进程都创建一个进程地址空间,然后通过页表来关联虚拟内存与物理内存,这样当我们用户对某一进程的虚拟内存越界访问或者非法读取与写入时,页表或操作系统可以直接进行拦截,从而保证了内存中数据的安全。
2、进程地址空间可以更方便的进行不同进程间代码和数据的解耦,保证了进程的独立性。
对于互不相关的两个进程来说,它们都拥有自己独立的地址空间以及页表,页表会映射到不同的物理内存上,磁盘代码和数据加载到内存中的位置也不同,一个进程数据的改变不会影响另一个进程;
对于父子进程来说,由于子进程的 mm_struct 和 页表 是通过拷贝父进程得到的,所以二者指向同一块物理内存,共用内存中的同一份代码和数据,但即使是这样,父进程/子进程在修改数据是也会发生写时拷贝,不会影响另一个进程,保证了进程的独立性。
3、进程地址空间让进程以统一的视角来看待磁盘代码以及各个内存区域,使得编译器也能够以相同的视角来进行代码的编译工作。
对于进程来说,各个进程都认为自己的数据被放置在对应的区域,比如代码区、全局数据区,但是物理内存实际上是可以非规律存储的;
对于磁盘中的程序以及编译器来说,编译器也是以进程地址空间的规则来进行编译的,所以磁盘中的可执行程序内部也是有地址的,且此地址也是虚拟地址;所以,当我们的程序被加载到内存变成进程后,不仅程序中的各个数据会被分配物理地址,程序的内部同时也存在虚拟地址,使得CPU在取指令进行运算时,拿到的下一条指令的地址也是虚拟地址,这样CPU也可以以 虚拟地址 -> 页表 -> 物理地址 的方式来统一执行工作。
注:严格来说,磁盘中程序内部的地址叫做逻辑地址,但是在上面我们就说过,对于Linux来说,虚拟地址、线性地址、逻辑地址是一样的,都是虚拟地址。
五、进程地址空间区域的严格划分
我们上面讲的地址空间的区域划分其实是一种粗略的划分,严格的区域划分如下: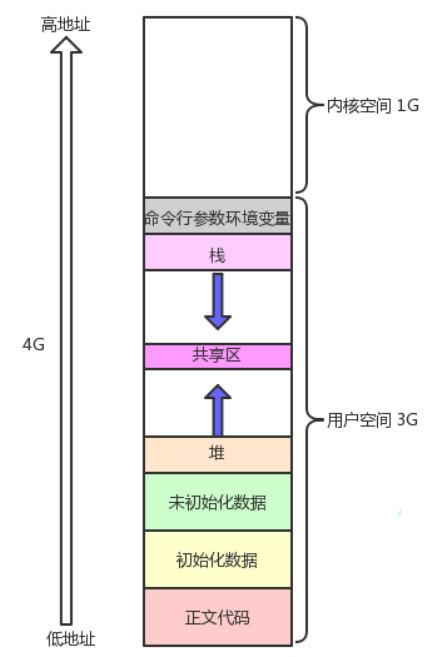
其中,我们之前熟悉的代码段、全局数据区、栈区、堆区、共享区,再加上一个命令行参数将变量被统称为用户空间,在32位操作系统下,这部分空间占总空间的3/4,即3G;剩下的1G属于内核空间。
注:我们今天讲的进程地址空间其实只将了一部分,其中还有很多比较复杂的细节我们没有涉及,比如页表分级、缺页、命中等等,这部分内容我们会在后面学习文件系统以及多线程的时候慢慢补充。