CelebA数据集下载|HTTPSConnectionPool(host=‘drive.google.com‘, port=443)|RuntimeError:Dataset not found
文章标签:
《随便一记》

CeleA是香港中文大学的开放数据,包含10177个名人身份的202599张图片,并且都做好了特征标记,这个数据集对人脸相关的训练来说是非常好用的数据集。
但是它不像其他数据集一样可以自动下载,比如mnist
import torchvision.datasets as dsetimport torchvision.transforms as transformsdataroot = './'imagesize = 64ataset = dset.MNIST(root=dataroot, download=True, transform=transforms.Compose([ transforms.Resize(imagesize), transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,)), ]))在torchvision.datasets.celeba.py文件中,celeba的下载方式有两种:
def download(self) -> None: # 第一种下载方式,手动下载 if self._check_integrity(): print("Files already downloaded and verified") return # 第二种下载方式,从谷歌云盘下载 for (file_id, md5, filename) in self.file_list: download_file_from_google_drive(file_id, os.path.join(self.root, self.base_folder), filename, md5) extract_archive(os.path.join(self.root, self.base_folder, "img_align_celeba.zip"))显然,如果不能手动下载,就要从谷歌云盘下了。但是谷歌云盘需要科学上网,所以还是手动下吧。
谷歌云盘下载的错误信息:requests.exceptions.ConnectionError: HTTPSConnectionPool(host='drive.google.com', port=443): Max retries exceeded with url: /uc?id=0B7EVK8r0v71pblRyaVFSWGxPY0U&export=download (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x000002746E4E7E20>: Failed to establish a new connection: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。'))百度网盘地址:CelebA_免费高速下载|百度网盘-分享无限制 (baidu.com)
那么问题来了,这么多文件,该下哪个呢? 下完之后又放到哪里呢?
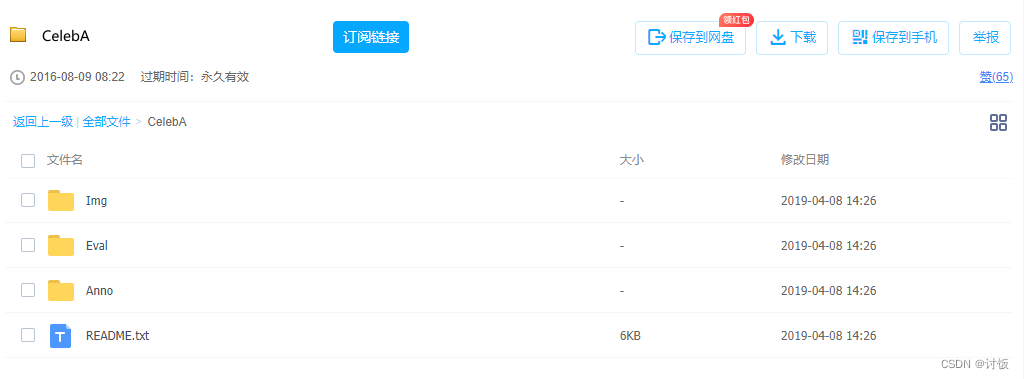
还是在torchvision.datasets.celeba.py文件中,有一个检查完整性的函数_check_integrity(),
def _check_integrity(self) -> bool: for (_, md5, filename) in self.file_list: fpath = os.path.join(self.root, self.base_folder, filename) _, ext = os.path.splitext(filename) # Allow original archive to be deleted (zip and 7z) # Only need the extracted images if ext not in [".zip", ".7z"] and not check_integrity(fpath, md5): return False这个函数会扫描self.file_list中的内容,
base_folder = "celeba"# There currently does not appear to be a easy way to extract 7z in python (without introducing additional# dependencies). The "in-the-wild" (not aligned+cropped) images are only in 7z, so they are not available# right now.file_list = [ # File ID MD5 Hash Filename ("0B7EVK8r0v71pZjFTYXZWM3FlRnM", "00d2c5bc6d35e252742224ab0c1e8fcb", "img_align_celeba.zip"), # ("0B7EVK8r0v71pbWNEUjJKdDQ3dGc","b6cd7e93bc7a96c2dc33f819aa3ac651", "img_align_celeba_png.7z"), # ("0B7EVK8r0v71peklHb0pGdDl6R28", "b6cd7e93bc7a96c2dc33f819aa3ac651", "img_celeba.7z"), ("0B7EVK8r0v71pblRyaVFSWGxPY0U", "75e246fa4810816ffd6ee81facbd244c", "list_attr_celeba.txt"), ("1_ee_0u7vcNLOfNLegJRHmolfH5ICW-XS", "32bd1bd63d3c78cd57e08160ec5ed1e2", "identity_CelebA.txt"), ("0B7EVK8r0v71pbThiMVRxWXZ4dU0", "00566efa6fedff7a56946cd1c10f1c16", "list_bbox_celeba.txt"), ("0B7EVK8r0v71pd0FJY3Blby1HUTQ", "cc24ecafdb5b50baae59b03474781f8c", "list_landmarks_align_celeba.txt"), # ("0B7EVK8r0v71pTzJIdlJWdHczRlU", "063ee6ddb681f96bc9ca28c6febb9d1a", "list_landmarks_celeba.txt"), ("0B7EVK8r0v71pY0NSMzRuSXJEVkk", "d32c9cbf5e040fd4025c592c306e6668", "list_eval_partition.txt"), ]被注释掉了三个,显然,我们只要把没被注释的六个文件下载就好了。
我们需要建一个存放数据的文件夹data,再在data下建一个文件夹celeba,最后把需要下载的文件放到celeba下。
因为
fpath = os.path.join(self.root, self.base_folder, filename)base_folder = "celeba",所以使用的时候只需要写根路径就好,比如:
import torchvision.datasets as dsetimport torchvision.transforms as transformsdataroot = './data'dataset = dset.CelebA(root=dataroot, download=True, transform=transforms.Compose([ transforms.Resize(64), transforms.CenterCrop(64), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]))print(dataset)最终结果:
Files already downloaded and verifiedDataset CelebA Number of datapoints: 162770 Root location: ./data Target type: ['attr'] Split: train StandardTransformTransform: Compose( Resize(size=64, interpolation=bilinear, max_size=None, antialias=None) CenterCrop(size=(64, 64)) ToTensor() Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)) )感觉其他人好像轻轻松松就使用成功了,不知道为啥我就频频踩坑,先是通过程序无法下载,然后去kaggle上下了,结果报错。然后看了pytorch的官方文档,
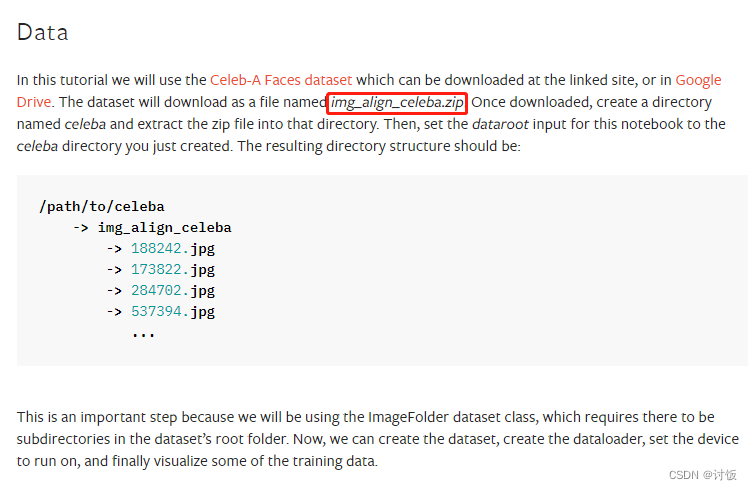
以为只用下一个文件,又花时间下了,结果可想而知。
而csdn上大家都是在介绍这个数据集,这篇文章介绍得还蛮简洁,如果有不知道这个数据集的可以看看这个。
最后附上celeba.py
import csvimport osfrom collections import namedtuplefrom typing import Any, Callable, List, Optional, Union, Tupleimport PILimport torchfrom .utils import download_file_from_google_drive, check_integrity, verify_str_arg, extract_archivefrom .vision import VisionDatasetCSV = namedtuple("CSV", ["header", "index", "data"])class CelebA(VisionDataset): """`Large-scale CelebFaces Attributes (CelebA) Dataset <http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html>`_ Dataset. Args: root (string): Root directory where images are downloaded to. split (string): One of {'train', 'valid', 'test', 'all'}. Accordingly dataset is selected. target_type (string or list, optional): Type of target to use, ``attr``, ``identity``, ``bbox``, or ``landmarks``. Can also be a list to output a tuple with all specified target types. The targets represent: - ``attr`` (np.array shape=(40,) dtype=int): binary (0, 1) labels for attributes - ``identity`` (int): label for each person (data points with the same identity are the same person) - ``bbox`` (np.array shape=(4,) dtype=int): bounding box (x, y, width, height) - ``landmarks`` (np.array shape=(10,) dtype=int): landmark points (lefteye_x, lefteye_y, righteye_x, righteye_y, nose_x, nose_y, leftmouth_x, leftmouth_y, rightmouth_x, rightmouth_y) Defaults to ``attr``. If empty, ``None`` will be returned as target. transform (callable, optional): A function/transform that takes in an PIL image and returns a transformed version. E.g, ``transforms.PILToTensor`` target_transform (callable, optional): A function/transform that takes in the target and transforms it. download (bool, optional): If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again. """ base_folder = "celeba" # There currently does not appear to be a easy way to extract 7z in python (without introducing additional # dependencies). The "in-the-wild" (not aligned+cropped) images are only in 7z, so they are not available # right now. file_list = [ # File ID MD5 Hash Filename ("0B7EVK8r0v71pZjFTYXZWM3FlRnM", "00d2c5bc6d35e252742224ab0c1e8fcb", "img_align_celeba.zip"), # ("0B7EVK8r0v71pbWNEUjJKdDQ3dGc","b6cd7e93bc7a96c2dc33f819aa3ac651", "img_align_celeba_png.7z"), # ("0B7EVK8r0v71peklHb0pGdDl6R28", "b6cd7e93bc7a96c2dc33f819aa3ac651", "img_celeba.7z"), ("0B7EVK8r0v71pblRyaVFSWGxPY0U", "75e246fa4810816ffd6ee81facbd244c", "list_attr_celeba.txt"), ("1_ee_0u7vcNLOfNLegJRHmolfH5ICW-XS", "32bd1bd63d3c78cd57e08160ec5ed1e2", "identity_CelebA.txt"), ("0B7EVK8r0v71pbThiMVRxWXZ4dU0", "00566efa6fedff7a56946cd1c10f1c16", "list_bbox_celeba.txt"), ("0B7EVK8r0v71pd0FJY3Blby1HUTQ", "cc24ecafdb5b50baae59b03474781f8c", "list_landmarks_align_celeba.txt"), # ("0B7EVK8r0v71pTzJIdlJWdHczRlU", "063ee6ddb681f96bc9ca28c6febb9d1a", "list_landmarks_celeba.txt"), ("0B7EVK8r0v71pY0NSMzRuSXJEVkk", "d32c9cbf5e040fd4025c592c306e6668", "list_eval_partition.txt"), ] def __init__( self, root: str, split: str = "train", target_type: Union[List[str], str] = "attr", transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, download: bool = False, ) -> None: super().__init__(root, transform=transform, target_transform=target_transform) self.split = split if isinstance(target_type, list): self.target_type = target_type else: self.target_type = [target_type] if not self.target_type and self.target_transform is not None: raise RuntimeError("target_transform is specified but target_type is empty") if download: self.download() if not self._check_integrity(): raise RuntimeError("Dataset not found or corrupted. You can use download=True to download it") split_map = { "train": 0, "valid": 1, "test": 2, "all": None, } split_ = split_map[verify_str_arg(split.lower(), "split", ("train", "valid", "test", "all"))] splits = self._load_csv("list_eval_partition.txt") identity = self._load_csv("identity_CelebA.txt") bbox = self._load_csv("list_bbox_celeba.txt", header=1) landmarks_align = self._load_csv("list_landmarks_align_celeba.txt", header=1) attr = self._load_csv("list_attr_celeba.txt", header=1) mask = slice(None) if split_ is None else (splits.data == split_).squeeze() if mask == slice(None): # if split == "all" self.filename = splits.index else: self.filename = [splits.index[i] for i in torch.squeeze(torch.nonzero(mask))] self.identity = identity.data[mask] self.bbox = bbox.data[mask] self.landmarks_align = landmarks_align.data[mask] self.attr = attr.data[mask] # map from {-1, 1} to {0, 1} self.attr = torch.div(self.attr + 1, 2, rounding_mode="floor") self.attr_names = attr.header def _load_csv( self, filename: str, header: Optional[int] = None, ) -> CSV: with open(os.path.join(self.root, self.base_folder, filename)) as csv_file: data = list(csv.reader(csv_file, delimiter=" ", skipinitialspace=True)) if header is not None: headers = data[header] data = data[header + 1 :] else: headers = [] indices = [row[0] for row in data] data = [row[1:] for row in data] data_int = [list(map(int, i)) for i in data] return CSV(headers, indices, torch.tensor(data_int)) def _check_integrity(self) -> bool: for (_, md5, filename) in self.file_list: fpath = os.path.join(self.root, self.base_folder, filename) _, ext = os.path.splitext(filename) # Allow original archive to be deleted (zip and 7z) # Only need the extracted images if ext not in [".zip", ".7z"] and not check_integrity(fpath, md5): return False # Should check a hash of the images return os.path.isdir(os.path.join(self.root, self.base_folder, "img_align_celeba")) def download(self) -> None: if self._check_integrity(): print("Files already downloaded and verified") return for (file_id, md5, filename) in self.file_list: download_file_from_google_drive(file_id, os.path.join(self.root, self.base_folder), filename, md5) extract_archive(os.path.join(self.root, self.base_folder, "img_align_celeba.zip")) def __getitem__(self, index: int) -> Tuple[Any, Any]: X = PIL.Image.open(os.path.join(self.root, self.base_folder, "img_align_celeba", self.filename[index])) target: Any = [] for t in self.target_type: if t == "attr": target.append(self.attr[index, :]) elif t == "identity": target.append(self.identity[index, 0]) elif t == "bbox": target.append(self.bbox[index, :]) elif t == "landmarks": target.append(self.landmarks_align[index, :]) else: # TODO: refactor with utils.verify_str_arg raise ValueError(f'Target type "{t}" is not recognized.') if self.transform is not None: X = self.transform(X) if target: target = tuple(target) if len(target) > 1 else target[0] if self.target_transform is not None: target = self.target_transform(target) else: target = None return X, target def __len__(self) -> int: return len(self.attr) def extra_repr(self) -> str: lines = ["Target type: {target_type}", "Split: {split}"] return "\n".join(lines).format(**self.__dict__)check_integrity函数在torchvision.datasets.utils.py中,
def check_integrity(fpath: str, md5: Optional[str] = None) -> bool: if not os.path.isfile(fpath): return False if md5 is None: return True return check_md5(fpath, md5)
登录后可发表评论
点击登录