目录
前言
布隆过滤器
什么是布隆过滤器
布隆过滤器的作用
布隆过滤器原理
怎么设计布隆过滤器
布隆过滤器使用案例
安装布隆过滤器
添加依赖
添加配置
添加工具类
添加测试代码
简单测试
特别提醒
结语
前言
前面三篇,已经把消息队列和其所包含的Kafka和RabbitMQ做了说明,并用案例演示了如何使用,今天这一篇,我们要讲解的内容是布隆过滤器,布隆过滤器不同于过滤器Filter,想知道布隆过滤器是什么,和怎样使用布隆过滤器吗?今天这篇博客,将带你了解这些,学完这篇,你将能独立使用布隆过滤器,了解其工作原理。下面,就让我们一起来学习吧。
布隆过滤器
说起过滤器,我们总是想起两种:一种是Filter过滤器,一种是布隆过滤器。Filter过滤器用于在全局捕捉请求,并在请求前后做一些事情,比如:统一编码,URL级别的权限访问控制,过滤敏感词汇,压缩请求信息等。那么布隆过滤器是做什么的呢?这里先卖个关子,我们继续往下看。
什么是布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
布隆过滤器不保存元素,之判断是否存在,不保存,所以也无法取出元素。
布隆过滤器的作用
布隆过滤器主要应用于网页URL的去重,垃圾邮件的判别,集合重复元素的判别,查询加速(比如基于key-value的存储系统)、数据库防止查询击穿, 使用BloomFilter来减少不存在的行或列的磁盘查找。
在Java开发 - Redis初体验一文中,我们曾提到过布隆过滤器,在缓存击穿的预防上面它是很好的效果的。刚好,学完此篇,你就可以在Redis项目中尝试添加布隆过滤器来防止缓存击穿,因为在当时写那篇博客时,我们采用的方法是给null值,在文中也提到,这是不合适的,因为当时还没有讲解布隆过滤器,学完此篇,大家可以去做个尝试。
布隆过滤器原理
常规检查元素是否存在我们会怎么做?一般是遍历集合,判断元素是否相等,但这种查询的方式在数据量庞大的情况下效率太低,想要实现快速的查找,前面学过的Java开发 - 树(二叉树,二叉排序树,红黑树)中曾经讲解过的数据结构或许会有一些帮助,其Hash散列或类似算法可以保证高效判断元素是否存在,但也存在消耗内存较多的问题,布隆过滤器的存在,正好解决了这个问题。
当要向布隆过滤器中添加一个元素时,该元素会经过N个哈希函数的计算并最终产生k个哈希值,布隆过滤器是个位数组,假设每一位是0,这些值就会根据计算出来的下标放入这个数组中,为1。在查询时,会判断这几个哈希值所在的位置,只要有一个为0就不存在于布隆过滤器中。
下面,我们通过几张图来说明布隆过滤器查询的原理:
假设这是一个空的布隆过滤器:
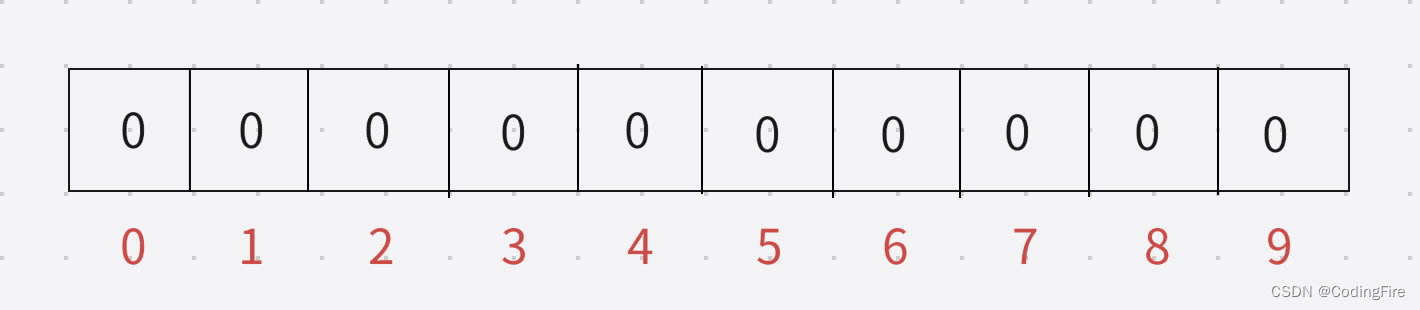
现在添加了coding单词在布隆过滤器中的状态:
coding算法1加密:1
coding算法2加密:3
coding算法3加密:5
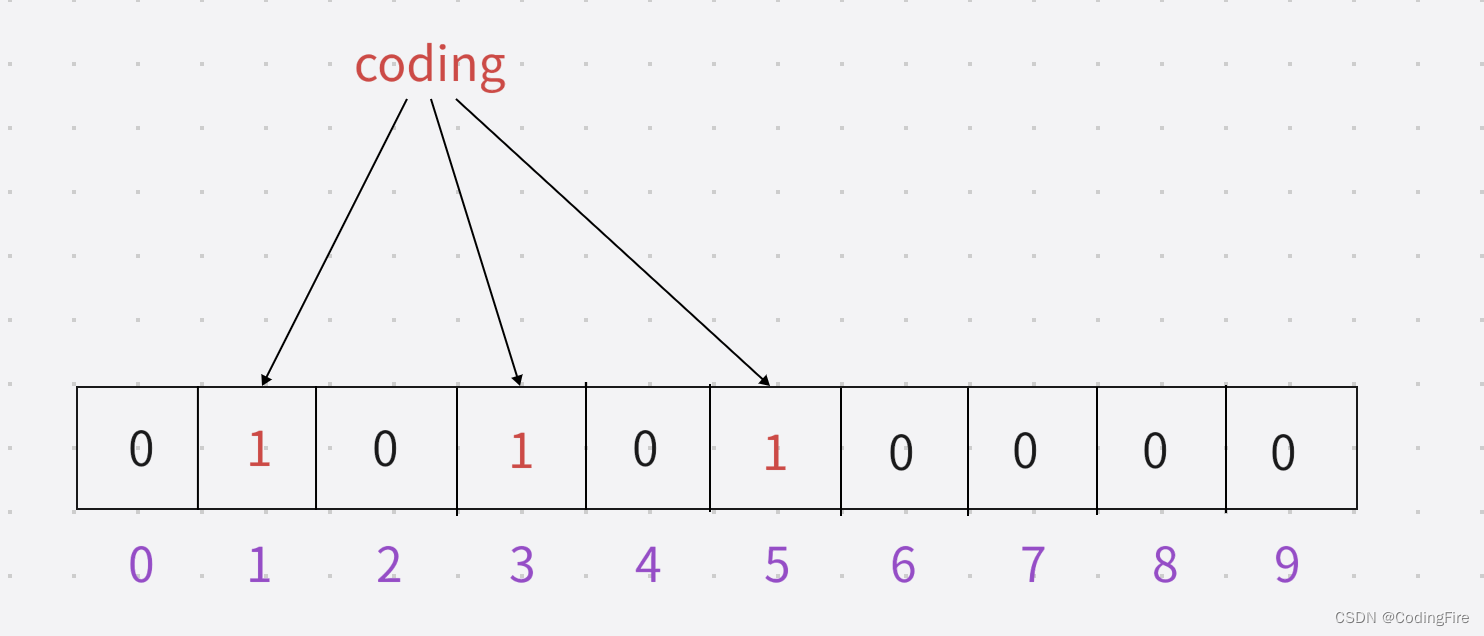
现在添加了fire单词在布隆过滤器中的状态:
fire算法1加密:2
fire算法2加密:4
fire算法3加密:6
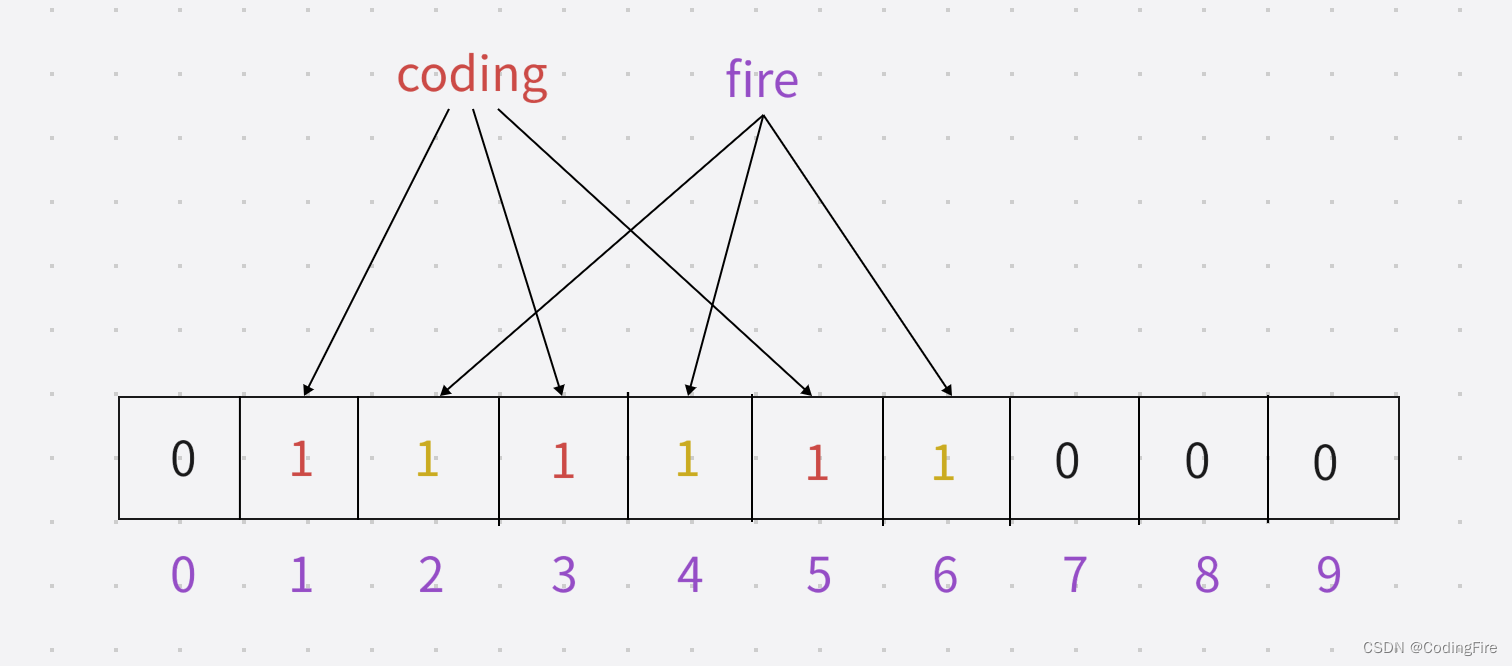
现在添加了codingfire单词在布隆过滤器中的状态:
codingfire算法1加密:1
codingfire算法2加密:4
codingfire算法3加密:6
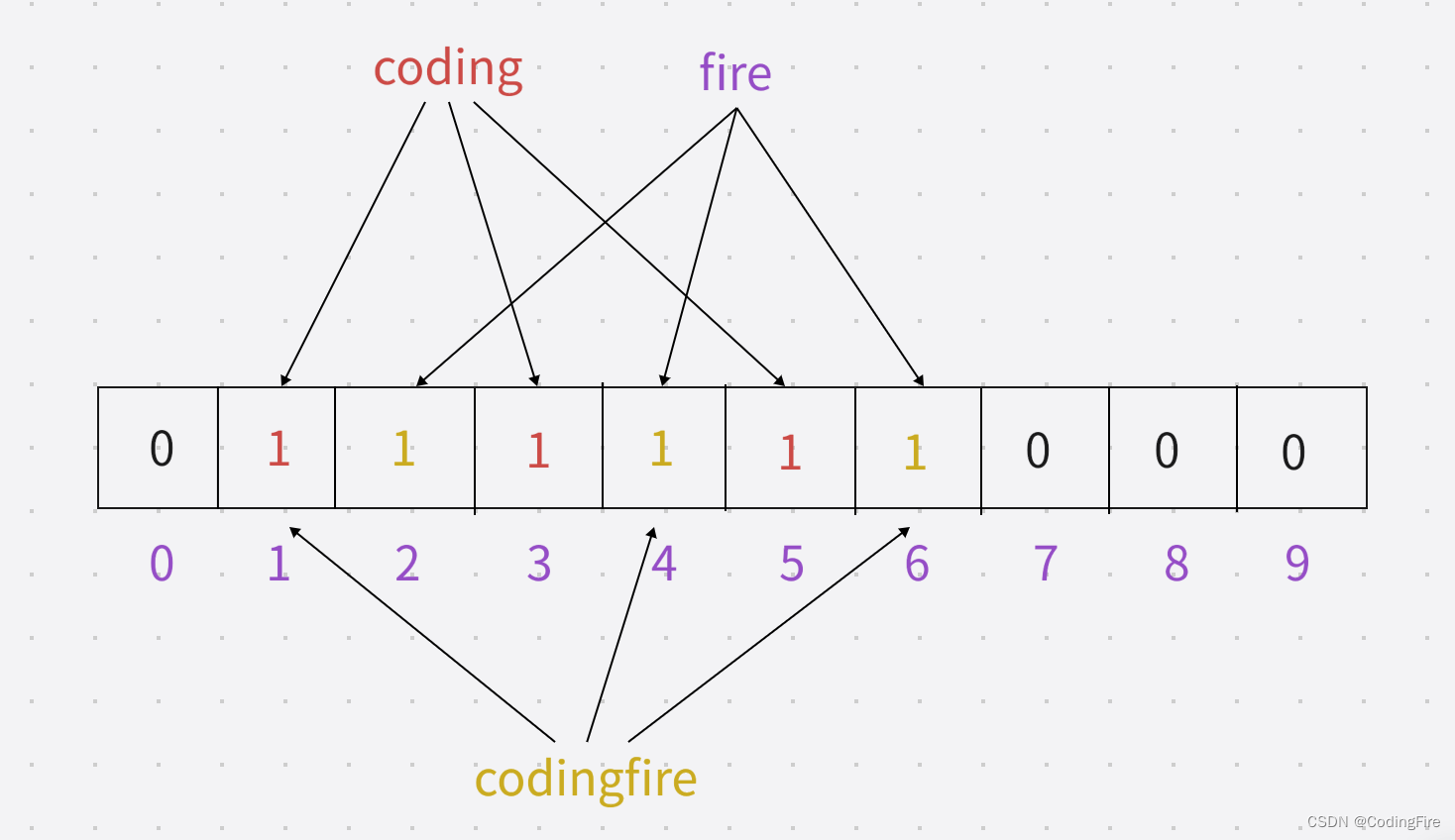
问题来了,我还没添加呢,1,4,6的位置已经有东西了,这时候,布隆过滤器就会误判,认为codingfire已存在于布隆过滤器中。
布隆过滤器误判特点:
布隆过滤器判断不存在的元素,一定不在集合中布隆过滤器判断存在的元素,有可能不存在集合中这是因为我们做测试时布隆过滤器太短了,假设就10格,会导致每个位置值都是1,我们就不用存东西了,误判会很严重,啥都存在,那这就是个失败的布隆过滤器。所以,合适的大小对布隆过滤器非常重要。
怎么设计布隆过滤器
布隆过滤器在启动时需要分配合适的内存大小,这直接决定了它是否准确。设置的大小要满足这几个条件:
可接受范围的大小既节省内存,又不会有很高的误判率关于这两个条件,有一个公式用于计算误判率:
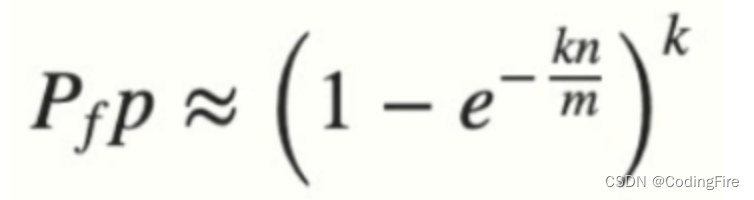
这是根据误判率计算布隆过滤器长度的公式:
n :是已经添加元素的数量;
k :哈希的次数;
m :布隆过滤器的长度(位数的大小)
最终结果结果就是误判率。
反着来也是可以的,知道误判率,反推布隆过滤器长度:
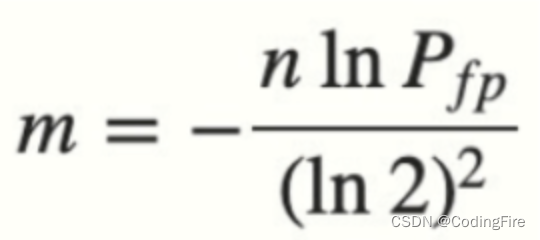
推荐一个在线计算布隆过滤器大小的网站,可以正推,也可以反推:Bloom filter calculator
布隆过滤器使用案例
安装布隆过滤器
布隆过滤器安装推荐这篇博客:Redis 布隆过滤器命令的使用详解
不过,它里面提到的布隆过滤器我个人不推荐,因为官方也推出了一个结合了Redis和布隆过滤器的软件工具:redis/redis-stack
网址在:Docker
安装方法和推荐博客里是一样的,由于比较简单,博主就不带大家一步步安装了,安装完请回到这里,我们继续。
安装完记得启动:
由于我们是教程,所以密码不设置,端口采用默认,实际可是要改的。 我们在上一篇RabbitMQ所在的子工程stock中继续集成,做一个简单的测试。
添加依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId></dependency>
添加配置
spring: redis: host: localhost port: 6379 password:
添加工具类
在stock包下建utils包,包下新建一个类,代码如下:
package com.codingfire.cloud.stock.utils;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.redis.core.StringRedisTemplate;import org.springframework.data.redis.core.script.DefaultRedisScript;import org.springframework.data.redis.core.script.RedisScript;import org.springframework.stereotype.Component;import java.util.Arrays;import java.util.List;@Componentpublic class RedisBloomUtils { @Autowired private StringRedisTemplate redisTemplate; private static RedisScript<Boolean> bfreserveScript = new DefaultRedisScript<>("return redis.call('bf.reserve', KEYS[1], ARGV[1], ARGV[2])", Boolean.class); private static RedisScript<Boolean> bfaddScript = new DefaultRedisScript<>("return redis.call('bf.add', KEYS[1], ARGV[1])", Boolean.class); private static RedisScript<Boolean> bfexistsScript = new DefaultRedisScript<>("return redis.call('bf.exists', KEYS[1], ARGV[1])", Boolean.class); private static String bfmaddScript = "return redis.call('bf.madd', KEYS[1], %s)"; private static String bfmexistsScript = "return redis.call('bf.mexists', KEYS[1], %s)"; public Boolean hasBloomFilter(String key){ return redisTemplate.hasKey(key); } /** * 设置错误率和大小(需要在添加元素前调用,若已存在元素,则会报错) * 错误率越低,需要的空间越大 * @param key * @param errorRate 错误率,默认0.01 * @param initialSize 默认100,预计放入的元素数量,当实际数量超出这个数值时,误判率会上升,尽量估计一个准确数值再加上一定的冗余空间 * @return */ public Boolean bfreserve(String key, double errorRate, int initialSize){ return redisTemplate.execute(bfreserveScript, Arrays.asList(key), String.valueOf(errorRate), String.valueOf(initialSize)); } /** * 添加元素 * @param key * @param value * @return true表示添加成功,false表示添加失败(存在时会返回false) */ public Boolean bfadd(String key, String value){ return redisTemplate.execute(bfaddScript, Arrays.asList(key), value); } /** * 查看元素是否存在(判断为存在时有可能是误判,不存在是一定不存在) * @param key * @param value * @return true表示存在,false表示不存在 */ public Boolean bfexists(String key, String value){ return redisTemplate.execute(bfexistsScript, Arrays.asList(key), value); } /** * 批量添加元素 * @param key * @param values * @return 按序 1表示添加成功,0表示添加失败 */ public List<Integer> bfmadd(String key, String... values){ return (List<Integer>)redisTemplate.execute(this.generateScript(bfmaddScript, values), Arrays.asList(key), values); } /** * 批量检查元素是否存在(判断为存在时有可能是误判,不存在是一定不存在) * @param key * @param values * @return 按序 1表示存在,0表示不存在 */ public List<Integer> bfmexists(String key, String... values){ return (List<Integer>)redisTemplate.execute(this.generateScript(bfmexistsScript, values), Arrays.asList(key), values); } private RedisScript<List> generateScript(String script, String[] values) { StringBuilder sb = new StringBuilder(); for(int i = 1; i <= values.length; i ++){ if(i != 1){ sb.append(","); } sb.append("ARGV[").append(i).append("]"); } return new DefaultRedisScript<>(String.format(script, sb.toString()), List.class); }}代码都是模版,使用时直接添加此类即可。
添加测试代码
我们quartz包下有个QuartzJob类,我们曾在里面测试Quartz功能和RabbitMQ,现在,我们来添加布隆过滤器的测试代码:
package com.codingfire.cloud.stock.quartz;import com.codingfire.cloud.stock.utils.RedisBloomUtils;import org.quartz.Job;import org.quartz.JobExecutionContext;import org.quartz.JobExecutionException;import org.springframework.amqp.rabbit.core.RabbitTemplate;import org.springframework.beans.factory.annotation.Autowired;import java.time.LocalDateTime;public class QuartzJob implements Job { // RabbitTemplate就是amqp框架提供的发送消息的对象 @Autowired private RabbitTemplate rabbitTemplate; @Autowired private RedisBloomUtils redisBloomUtils; @Override public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException { //输出当前时间 System.out.println("--------------"+ LocalDateTime.now() +"---------------"); // 先简单的发送一串文字// rabbitTemplate.convertAndSend(RabbitMQConfig.STOCK_EX,RabbitMQConfig.STOCK_ROUT,"黄河之水天上来,奔流到海不复还。"); // 首先确定要向布隆过滤器中保存的元素 String[] numbers={"zero","one","two","three","four","five","six","seven","eight","nine","ten"}; // 使用RedisBloomUtils类将上面的数组元素保存在Redis(布隆过滤器)中 redisBloomUtils.bfmadd("numberBloom",numbers); // 下面就可以判断一个元素是否在这个布隆过滤器中了 String elm="six"; System.out.println("布隆过滤器判断"+elm+"是否存在:"+ redisBloomUtils.bfexists("numberBloom",elm)); }}大阿甲不用纠结代码为什么写在这个类里,随便你写在哪里,写在测试类中也行,只要你项目能运行我们写的测试方法,随便你写在哪。
简单测试
下面我们来简单测试下布隆过滤器的使用,看情况启动服务,如果十一路学习过来,和博主用的是相同工程的同学,请启动nacos,seata,mysql,还有最重要的redisbloom,可能还要启动RabbitMQ,否则会报错,启动后,运行项目,查看控制台输出:
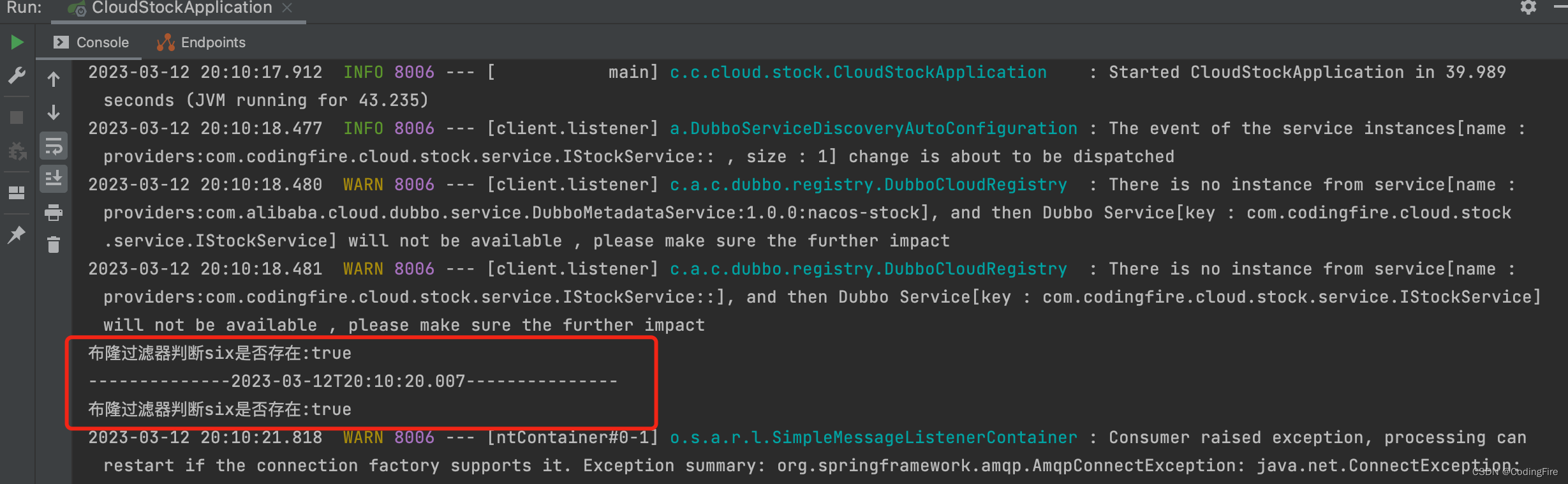
能输出图中内容的就是测试成功了。
特别提醒
设置错误率和大小在使用前记得调用,不设置默认0.01,自己看哈。
QuartzJob中布隆过滤器虽然进行了测试,但我们要知道QuartzJob的工作驱动,还有一个类叫QuartzConfig,这里面的代码相当于是注册+触发条件。我这么说,大家懂吗?不懂得可以去看看驱动QuartzJob运行的触发器的设置:Java开发 - Quartz初体验。
结语
简单来说,布隆过滤器就是用来判断某个元素是否存在于某一个集中的东西,而且,其判断效率非常高,是一个在大数据情况下常用的工具,但它本身代码量并不大,但要注意布隆过滤器存在误判率,所以使用起来,在设置重要参数时还是要注意些的。今天的布隆过滤器介绍到此结束, 不知道大家对最近的博客还满意吗?欢迎留言沟通交流。