早点睡兄弟,别一天到晚就熬夜。
文章目录
一、通过list迭代器来感受类和对象以及类封装的思想1.迭代器的特征和本质是什么?(两大特征:类的内嵌类型,行为像指针。本质:内置类型定义的变量或自定义类型实例化的对象)2.迭代器的价值是什么?(封装、类、对象的思想 && C++语法的不可替代性:引用、运算符重载等)3.我们为什么要将list迭代器进行类封装?(原生指针无法满足要求,只能通过类封装和运算符重载让对象能够像指针一样使用) 二、list的模拟实现1.迭代器对象作为参数的insert和erase的实现2.list的拷贝构造、赋值重载、析构函数 三、const迭代器的实现1.const迭代器的错误实现(const修饰了迭代器本身而不是迭代器指向的内容)2.重新构建一个__list_const_iterator的类(菜鸟的做法)3.增加模板参数,根据类模板参数的不同,实例化出不同的类(大佬的做法)4.类名和类型的区别 四、实现迭代器 + →的访问方式(像结构体指针 + →一样的行为)1.迭代器指向对象为结构体时,编译器对→的特殊处理(省略一个箭头,提升代码可读性)2.实现const链表对象的迭代器在→解引用时,返回值不可被修改(增加模板参数,实例化出不同的类)3.重新理解迭代器的本质(行为像指针一样,可用于所有底层数据结构不同的容器) 五、反思迭代器类的设计,回顾类和对象的知识六、对比vector和list,总结三个容器的迭代器失效
一、通过list迭代器来感受类和对象以及类封装的思想
1.迭代器的特征和本质是什么?(两大特征:类的内嵌类型,行为像指针。本质:内置类型定义的变量或自定义类型实例化的对象)
1.
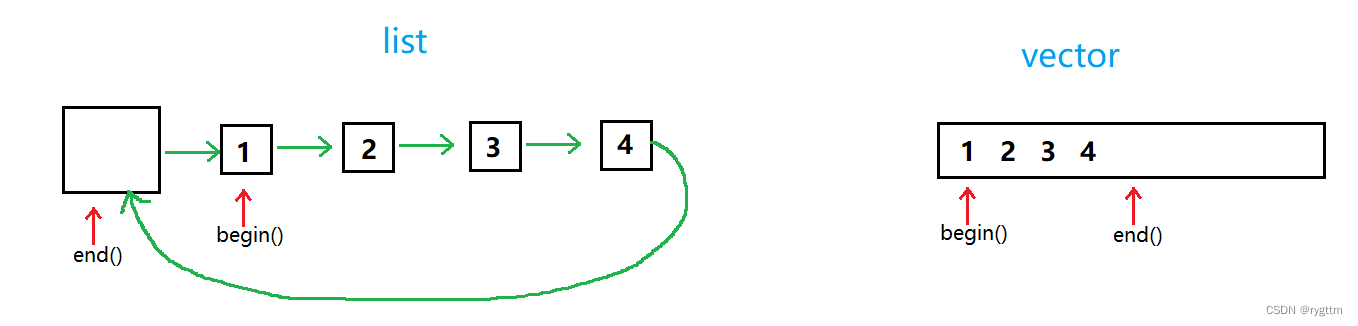
从迭代器的上层角度来看,vector和list的迭代器的使用没有差别,迭代器的begin和end返回的是左闭右开的区间位置[ begin(),end() )。
2.
迭代器的一大特征就是类的内嵌类型,在使用时要指定迭代器属于的类域,是哪个容器的迭代器就属于哪个容器的类域。在类里面定义内嵌类型一般有两种方式,一种是typedef,另一种就是内部类,C++不太喜欢用内部类这种方式,可能是因为代码的维护性较低,所以弃用了内部类这样的方式。
内嵌类型迭代器基本都是在类里面typedef出来的,C++喜欢这样内嵌类型的定义方式。
迭代器的另一大特征就是像指针一样的东西,对于使用者来讲不必关心底层实现细节,将迭代器当作指针一样使用即可。
list迭代器遍历时,while循环的判断条件只能是!=,不能是<,因为他的底层是一个个的结点,结点的地址之间并不具有相关性。
3.
list的迭代器我们用的是类模板定义出来的,也就是自定义类型的迭代器。vector的迭代器我们用的是原生指针定义出来的,也就是内置类型的迭代器。
但vector的迭代器不一定是内置类型,虽然我们当时实现的是原生指针版本的迭代器,但那时因为我们模拟实现的是SGI版本的STL,比如PJ版本呢?他的vector迭代器就一定是原生指针内置类型实现的吗?这可不一定。

4.
在前面的文章我们谈vector迭代器失效问题的时候,可以看到vs和g++对于erase之后迭代器是否失效有着不同的做法,vs认为他就是失效了,g++却不这么认为,其本质就是因为两个编译器底层调用的STL库的版本是不同的,前者调用PJ版本的STL库,后者调用SGI版本的STL库,SGI版本下vector的迭代器就是用原生指针实现的,但PJ版本下vector的迭代器并不是原生指针实现的,而是经过类(自定义类型)的封装实现的,在类里面用运算符重载等实现迭代器的基本操作,这些类成员函数里面会有assert的断言检查,所以在erase之后vs同一认为迭代器失效,因为他的库底层PJ版本的STL源码就是这么规定的。
从下面源码可以看到,vector的迭代器被封装为一个类,[]和下标,++或 - -,反正随机迭代器的各种操作,PJ版本都是用类的运算符重载来实现的。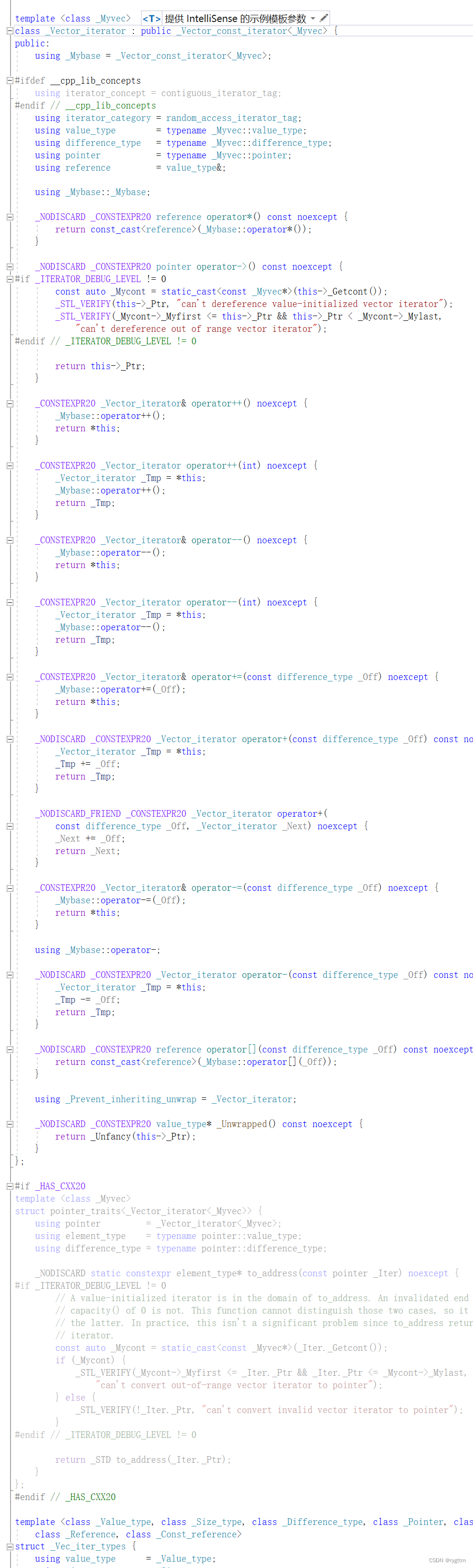
下面是SGI版本的list迭代器的源码实现,利用的就是类封装,将迭代器的使用细节全部封装在__list_iterator这个类里面,类成员变量就是结构体指针node *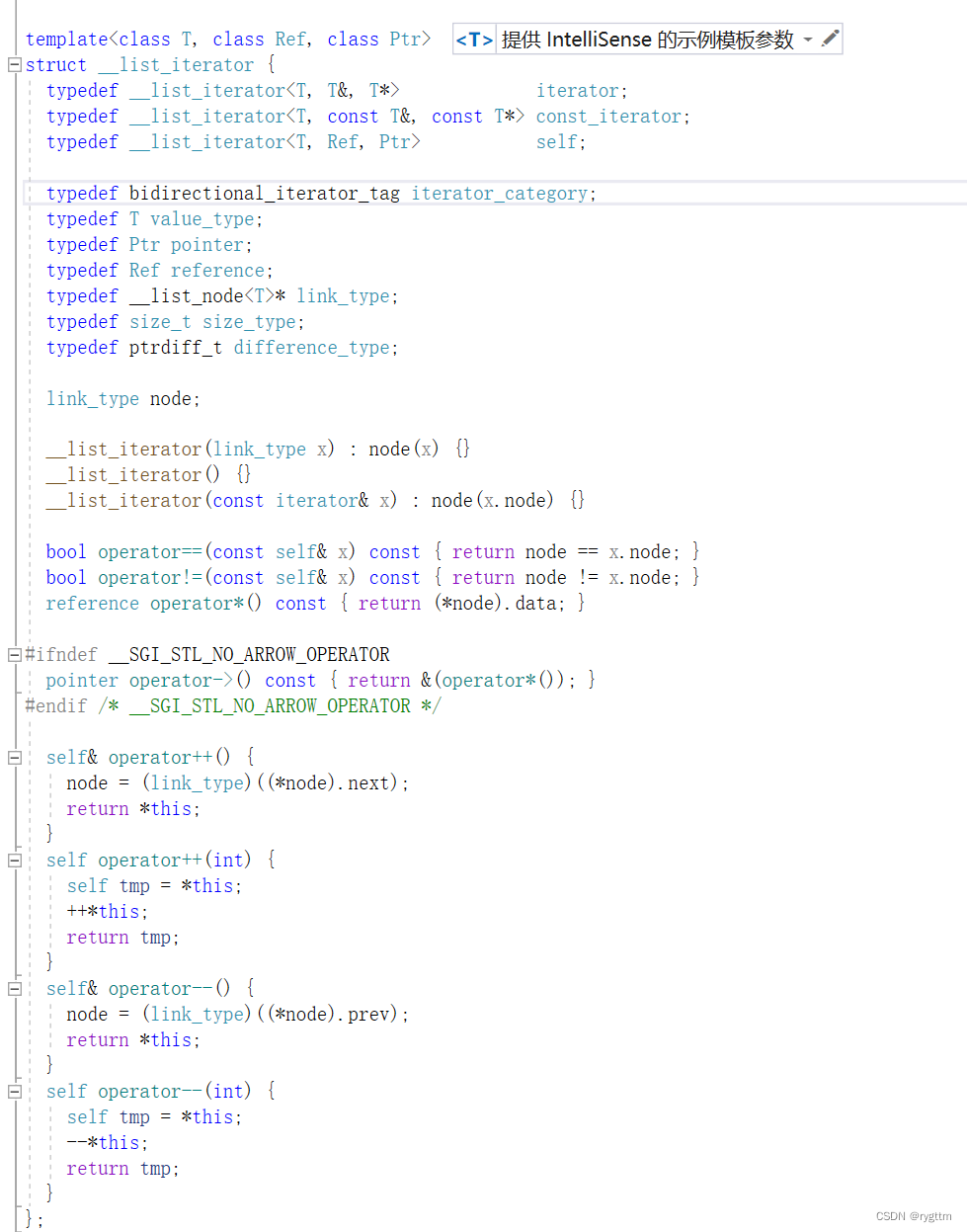
5.
SGI版本下,list迭代器是自定义类型,vector迭代器是内置类型,所以vector迭代器的解引用就是原生指针的解引用,而list迭代器的解引用是类里面operator*运算符重载的函数调用,如果不重载解引用则解引用返回的是结点,他们的底层是有很大的区别的,对于内置类型和自定义类型分别实现的迭代器。
2.迭代器的价值是什么?(封装、类、对象的思想 && C++语法的不可替代性:引用、运算符重载等)
1.
即使我们没学过容器set,但我们依旧可以用迭代器来遍历set,打印容器set的所有元素。假设没有迭代器,我们自己去写遍历vector和list的接口,我们需要暴露底层实现的细节,告诉使用者该如何如何遍历我们的容器,按照我们所写接口的方式进行遍历。并且不同容器的遍历方式不一样,这又导致了使用者在使用我们所写容器的遍历方式时,要去看源码,要去看接口,看完之后才能知道该如何使用,对使用者来讲成本太高了。
2.
a.迭代器对底层的实现进行封装,不暴露底层实现的细节。
b.提供统一的访问方式,降低使用者的使用成本。
无论你的结构是数组、链表、还是树,迭代器都提供了统一的访问方式,降低使用成本。
遍历一棵树不容易,但是如果我们用迭代器封装了树的遍历,那遍历起来不久轻轻松松了吗?我们直接用封装好的迭代器进行遍历即可
3.
每个容器的底层结构都形态各异,对于数组来说,迭代器就用原生指针来实现就可以完成迭代器的功能,你不用原生指针,用类去封装一下原生指针也可以,PJ版本就是这样实现的。
但是链表和树的底层结构又和vector不一样了,那我该如何提供统一的访问方式呢?这个时候就能体现出C++类的独特价值所在,内置类型解引用确实可以直接拿到数据,但自定义类型却不能通过解引用拿到数据,但是我们有类啊!类里面的运算符重载的实现不就是我们说了算吗?我们可以重载解引用运算符,让他返回特定的数据。并且引用也是C++的价值之处,只要我们返回引用,那通过重载函数的返回值就可以修改对应的结点数据,因为引用就是别名,我们操纵这个引用返回值,就可以修改链表对应结点里面的_data的数据。

4.
迭代器默默帮使用者承受了底层实现的复杂细节,使用者在上层用起来很舒服,本质是因为诸多实现的复杂细节被迭代器封装起来了,这才得以让所有的容器都有统一的访问方式,无论你底层是多么多么复杂的结构,你使用者不要担心,在STL库里面已经将迭代器的各种操作封装起来,无论你是++还是 - -,又或是解引用,又或是->的成员选择,你都不用担心,在STL源码里面这些操作都会被实现,迭代器将所有负责的操作都封装起来,默默替你承受着一切。
5.
前面是站在上层使用和底层实现的角度看待迭代器,再以物理角度(内存中实际存储所占的空间大小)看待一下迭代器吧,vector的迭代器是4个字节,因为他是原生指针直接指向变量_data,解引用获得_data的数据内容。
list的迭代器也是4个字节,因为自定义类型迭代器实例化出来的对象的成员变量只有一个结构体指针,结构体指针大小也是4个字节,所以it对象和vector的迭代器大小相同均为4字节。

void test_set1(){set<int> s;s.insert(3);s.insert(2);s.insert(1);s.insert(5);set<int>::iterator it = s.begin();while (it != s.end()){cout << *it << " ";it++;}cout << endl;}//迭代器的价值是什么?//1.封装底层的实现,不暴露底层的实现细节//2.提供统一的访问方式,降低使用的成本。(不需要关心set底层的二叉搜索树结构)// 遍历一棵树不容易,但如果封装了迭代器进行访问那就容易很多了,这就足以降低使用的成本。// 底层结构形态各异,但访问方式达到了统一3.我们为什么要将list迭代器进行类封装?(原生指针无法满足要求,只能通过类封装和运算符重载让对象能够像指针一样使用)
1.
前面我们都在谈论迭代器的实现底层和迭代器的特征本质价值等等话题,但我们反过来可以想一下为什么要对list的迭代器进行类封装呢?实际这个答案藏在迭代器的特征里面。
2.
我们谈到过迭代器的特征是类的内嵌类型和行为像指针一样的东西,所以如果我们不进行类封装,直接用原生指针来实现list的迭代器,那这个迭代器势必就不像指针一样使用了,他此时就不满足迭代器的特征了,因为解引用或++ - - 等行为无法像指针一样,那我们就没有办法继续使用原生指针来当作我们的迭代器。
3.
所以这个时候就要用类将结构体指针进行封装,迭代器就不再是原生指针类型定义出来的变量了,而是自定义类型实例化出来的对象,我们借用自定义类型和运算符重载,让实例化出来的对象能够像指针一样,类似原生指针类型定义出来的变量那样进行使用,这就是为什么我们用类封装的原因。
二、list的模拟实现
1.迭代器对象作为参数的insert和erase的实现
1.
实现insert时可以看到所传参数是迭代器,实际就是链表结点的地址,也是一个结构体指针,只不过我们对这个结构体指针进行了封装,这个迭代器就变成了一个对象,在实现上和数据结构初阶实现的带头双向循环链表没什么区别,仅仅是多了一个类的封装。
实现erase时返回删除位置的下一个位置的迭代器,以便于使用者刷新erase之后的迭代器,防止产生迭代器失效问题。
void push_back(const T& x){//node* newnode = new node(x);//会调用类Node的构造函数//node* tail = _head->_prev;//tail->_next = newnode;//newnode->_prev = tail;//newnode->_next = _head;//_head->_prev = newnode;insert(end(), x);}void push_front(const T& x){insert(begin(), x);}void pop_front(){erase(begin());}void pop_back(){erase(--end());//调用迭代器对象的operator--运算符重载}iterator insert(iterator pos, const T& x){node* newnode = new node(x);//调用node类的带参构造node* cur = pos._pnode;//通过迭代器对象pos拿到当前结点的结构体指针,pos所属类是struct,则成员是公有node* prev = cur->_prev;//拿到前一个和当前位置的node指针//prev newnode curprev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;++_size;return iterator(newnode);//返回插入结点的迭代器对象}iterator erase(iterator pos){//assert(pos != _head);//一个是指针,一个是迭代器类型,这里类型不匹配,选择用end()来进行比较assert(pos != iterator(_head));//迭代器位置不能是哨兵卫结点//assert(pos != end());//上下两种assert方式都可以//拿到当前位置的前一个和后一个位置的结构体指针node* prev = pos._pnode->_prev;node* next = pos._pnode->_next;prev->_next = next;next->_prev = prev;delete pos._pnode;--_size;return iterator(next);//返回删除位置的下一个位置的迭代器,这个迭代器现在是一个对象。vector那里是原生指针。}2.list的拷贝构造、赋值重载、析构函数
1.
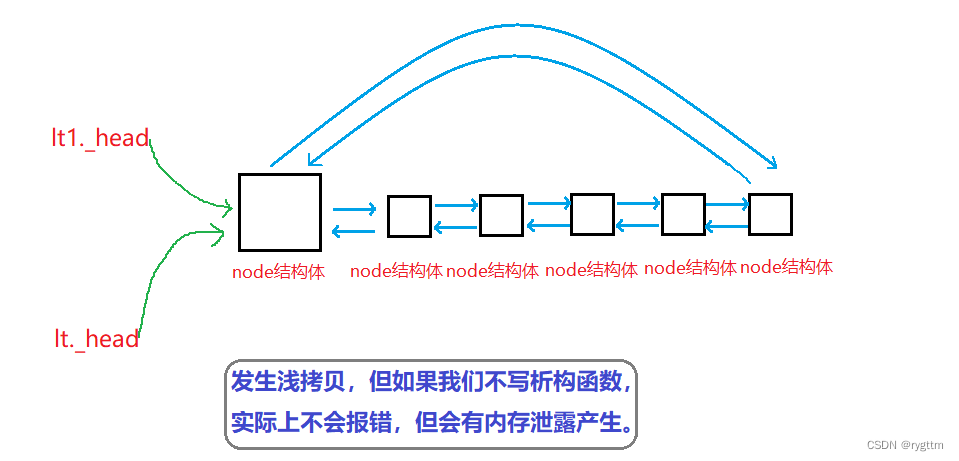
如果我们不写拷贝构造,那么链表就会发生浅拷贝,但如果此时我们没写析构函数,则程序运行起来是不会报错的,但实际程序已经有问题了,因为发生了内存泄露。
首先链表浅拷贝时,会直接将哨兵卫结点的地址拷贝给新链表的哨兵卫结点地址_head,此时两个链表头结点指针指向的是同一块儿空间,不写析构函数,编译器默认生成的析构函数对内置类型不会处理,所以堆上开辟的空间就不会处理,这就产生了内存泄露,只能等待进程结束,操作系统回收对应进程资源后,堆上申请的空间才会被释放掉。
2.
这也从另一方面体现了内存泄露的危害所在,因为一旦程序产生了内存泄露,编译器是不会报错的,所以你以为你的程序好好的跑起来了,感觉没有什么bug产生,但你的程序其实已经产生了问题,那就是内存泄露。
3.
只要写了正确的析构函数,浅拷贝就肯定会出现问题了,因为同一块空间被析构两次,第二次就会变成野指针的越界访问,这个时候程序就会报错。
4.
clear()用于释放除哨兵卫结点之外的其他所有结点资源,析构函数用于释放链表所有的结点资源,包括哨兵卫结点。
clear再实现时有两种写法,一种就是定义两个结构体指针,一个指向头结点,一个指向下一个位置的结点,然后依次向后遍历释放结点资源。
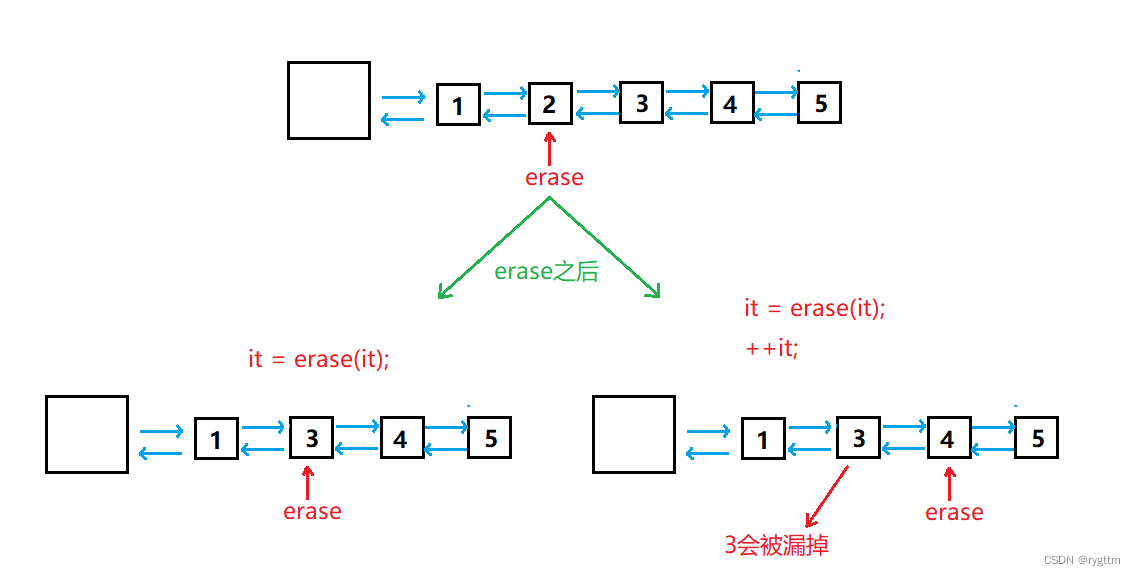
另一种写法就是利用迭代器和erase,进行代码复用,遍历迭代器直到开区间end()就结束迭代器的遍历,然后依次调用erase释放结点,erase之后迭代器会失效,所以我们要用erase的返回值来更新迭代器,但需要注意的是erase更新迭代器之后,迭代器不用++了,否则会出现部分结点未释放的问题,又是内存泄露,因为erase的返回值就已经更新了,你再++就相当于更新两次,则释放时会漏掉一个结点。
析构函数实现时,我们代码复用clear将除哨兵卫结点之外的其他结点释放,最后再释放哨兵卫结点即可。
5.
拷贝构造的传统写法就是自己先初始化好哨兵卫结点,然后用迭代器或范围for(本质就是迭代器)遍历链表,将遍历到的每一个结点的数据都尾插到链表里面去,范围for就是将遍历到的迭代器进行解引用然后拷贝构造给auto推导的变量,值得注意的是,在auto变量这里,推荐使用auto的引用,因为数据类型是泛型,内置类型用个拷贝构造还好说,但如果是自定义类型,则拷贝构造的代价太大,所以推荐auto用引用。
现代写法还是找打工人,对于拷贝构造来说,打工人还是迭代器为参数的构造函数,所以除无参的构造函数外,我们再多实现一个参数为迭代器区间的构造函数,让这个构造函数给我们打工,构造出一个临时list对象,最后再调用swap交换这个临时list对象和被拷贝构造对象即可,等到离开函数栈帧tmp对象就会被销毁。
6.
赋值重载的传统写法依旧是用范围for遍历list的数据,然后将遍历到的数据都尾插到被赋值链表里面,但是尾插数据之前需要clear一下,将链表里面原有数据对应的结点释放掉,然后再进行遍历到的元素的push_back,另外为了防止自己给自己赋值我们还调用了一下最最不常用的取地址重载函数,保证两个链表对象是不相同的。
现代写法也是找打工人,对于赋值重载来说,打工人就是拷贝构造,我们利用传值拷贝的形参临时对象和被赋值对象直接进行swap,道理相同形参临时对象在函数栈帧销毁时会跟着一起被析构掉。
7.
swap的实现也比较简单,直接交换两个链表头结点指针即可。
size()接口返回链表结点的个数,如果遍历链表计数结点个数来实现size()的话,在size()频繁调用的情况下,效率就会降下来,所以我们用空间换时间,牺牲空间来换取效率的提升,增加一个list成员变量_size,表示链表当前节点个数,插入结点就++_size,删除结点就–_size,调用size()接口时,直接返回成员变量_size的大小即可。
list(){empty_initialize();}template <class InputIterator>list(InputIterator first, InputIterator last)//迭代器区间为参数的默认构造{empty_initialize();//如果不调用初始化接口,则被拷贝对象的_head是一个野指针,交换后析构会出问题。while (first != last){push_back(*first);++first;}}void swap(list<T>& lt){std::swap(_head, lt._head);std::swap(_size, lt._size);}// lt2(lt1)//list(const list<T>& lt)//传统写法//{//empty_initialize();//初始化被拷贝链表,先搞一个头结点出来。////下面的范围for会傻瓜式的替换为const迭代器//for (auto& e : lt)//如果T是自定义类型,则会调用该类的拷贝构造,代价会很大,为了提高效率,这里用引用。////范围for本质就是取容器里面的每一个迭代器,然后解引用迭代器赋值给元素e,如果T是string类型拷贝的字节会很多//{////如果已知auto的类型是int,char等,可以不用引用,但如果是泛型或自定义类型,就应该用引用减少拷贝的消耗//push_back(e);//e是数据不是结点,解引用迭代器拿到的是数据,然后将数据尾插到链表里//}//}list(const list<T>& lt)//拷贝构造的现代写法//:_head(nullptr)//不能用空指针初始化_head,否则在析构时,进入到clear里面,begin()会访问空指针,造成越界访问{empty_initialize();list<T> tmp(lt.begin(), lt.end());//交换两个指向头结点的结构体指针,就完成了链表的交换swap(tmp);}list<T>& operator=(list<T> lt)//现代写法{swap(lt);return *this;//返回list<T>类的对象}// lt1=lt2//list<T>& operator=(const list<T>& lt)//传统写法//{//if (this != <)//对象的取地址运算符重载//{////将this对象的数据先清掉,但不要清掉哨兵卫的头结点,就算你清了,等会儿还得empty_initialize//clear();//for (auto& e : lt)//这里也用auto引用//{//push_back(e);//}//return *this;//}//}void clear()//clear不清除头结点{//C语言实现的方式:定义下一个节点的地址cur,删除cur->prev,++cur,cur->prev!=end();//C++可以直接利用迭代器和erase进行删除。迭代器是真牛啊iterator it = begin();while (it != end()){it = erase(it);//不更新it,会出现迭代器失效的问题。//++it;//再++it的位置就不对了,clear无法完全删除除头之外的节点,erase会自动返回删除位置的下一个位置的迭代器}}size_t size()const//提供const版本,这样const对象和非const对象都可以调用{//如果搞一个迭代器循环,计数器记录到底有多少个结点,然后返回计数器大小。//但如果频繁调用size()的话,则效率就会降下来。所以可以想到以空间换时间,多在list里面加一个成员变量return _size;}bool empty()const{return _size == 0;//两个条件都可以//return _head == _head->_next;}~list()//析构函数清除头结点{//如果显示写了析构函数会存在野指针访问的问题,没写则依靠不处理内置类型的默认析构来析构对象。//如果内置类型涉及堆空间的资源申请,则调用编译器的默认析构会导致内存泄露的问题,但内存泄露又不会报错,//这真是令人害怕的事情!clear();delete _head;_head = nullptr;}三、const迭代器的实现
1.const迭代器的错误实现(const修饰了迭代器本身而不是迭代器指向的内容)
1.
在迭代器前面加个const并没有完成const迭代器的实现,因为我们所说的const迭代器指的是解引用迭代器之后的内容不能被修改,但迭代器本身也可以理解为指针本身是可以被修改的,因为迭代器需要++或 - -来移动自己的位置,就像指针一样能够++或 - -来移动自己的位置。所以你在迭代器前面加个const表示的是迭代器本身不能被修改,而不是解引用迭代器后的内容不能被修改。
// const T* p1;// T* const p2;//正确的const迭代器类似于p1的行为,解引用迭代器后的内容不能被修改,但迭代器本身可以被修改,因为无论是const还是非const迭代器都要++或--void print_list(const list<int>& lt){//普通迭代器前面加个const肯定是不行的,这不符合const迭代器的意义。const list<int>::iterator cit = lt.begin();//这样写的话,const修饰的是迭代器本身,迭代器不能++或--了,我们要的是const修饰迭代器指向的内容list<int>::const_iterator it = lt.begin();while (it != lt.end()){//(*it) += 2;//实现const迭代器之后,这里就不能写了cout << *it << " ";++it;}cout << endl;}2.
重载一个const版本的解引用运算符重载函数,这样的确可以被const迭代器对象调用,并且返回的数据的值是常引用,表示返回的值不能被修改,这些的确都没有毛病。
但是当const迭代器对象调用++或 - -的运算符重载函数就出问题了,因为迭代器对象是const修饰的,所以迭代器对象的成员变量就不允许被修改,那就是结构体指针不能被修改,而++或 - -的运算符重载函数肯定是要对结构体指针进行修改的,这就出大问题了,const对象能够用迭代器,但是他的迭代器不能满足++或 - -这样的操作,所以这样是不行的。
3.
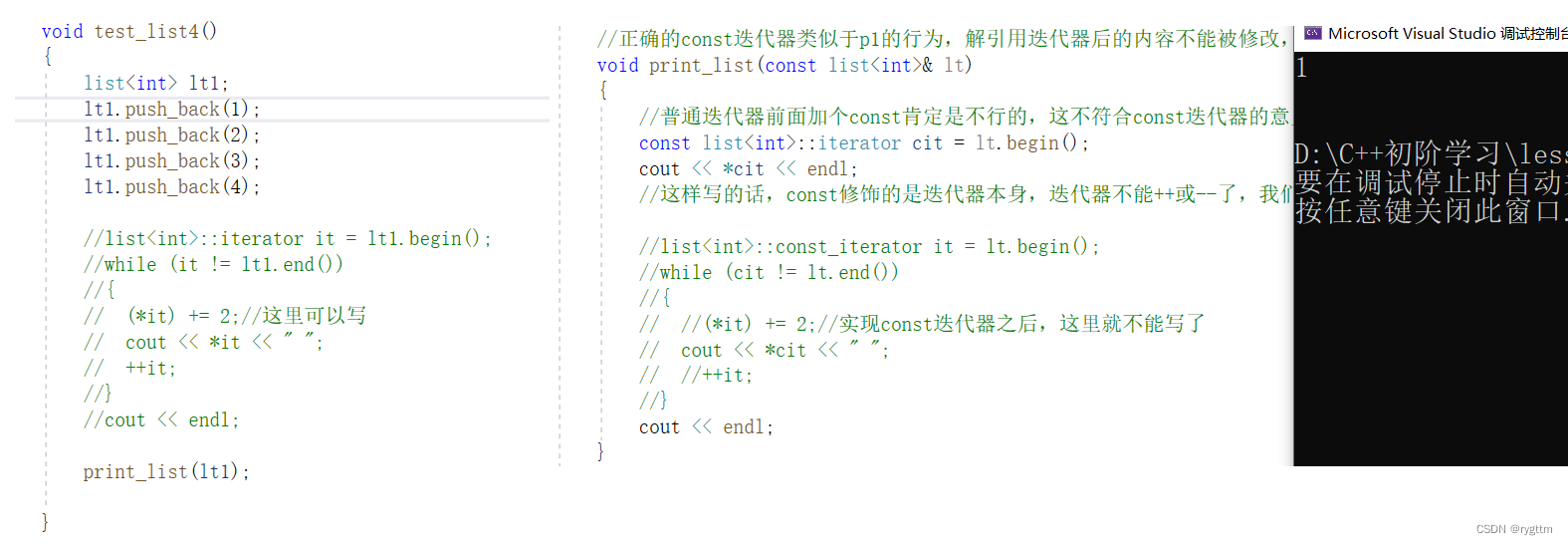
下面的const修饰的cit确实能够调用const版本的解引用重载函数,但是有个屁用啊,你的cit都是const修饰的了,只能解引用,不能++或 - - 这不废物吗?所以上下这两个问题实际就是一个问题,都是围绕const修饰指针本身这个错误的问题展开的。
我们只能打印出一个值,因为迭代器被const修饰了,相当于指针别const修饰了,迭代器不能++或 - -,所以我们只能解引用当前位置的迭代器,非常的有病。
T& operator*(){return _pnode->_data;//返回变量_data的引用,表示数据可以被读或修改,_data的类型是T}//const iterator cit;//*cit;//++it;这样的话,可以解引用,但是不能++const T& operator*()const{return _pnode->_data;}__list_iterator<T>& operator++()//++改变的就是成员变量_pnode,所以不能用const修饰此函数{_pnode = _pnode->_next;return *this;}__list_iterator<T>& operator--(){_pnode = _pnode->_prev;return *this;}2.重新构建一个__list_const_iterator的类(菜鸟的做法)
1.
实现const迭代器的一种方式就是重新构建一个类,类里面原有成员函数都不变,仅仅是将类名做出修改,然后我们把解引用函数的返回值修改成常引用,在使用const_iterator迭代器类型的时候,如果你解引用迭代器则直接调用__list_const_iterator类里面的返回常引用的重载函数。
这样就可以实现解引用const_iterator后的内容不可被修改了,因为我们重新构建了一个类,将类里面解引用函数的返回值重新修改为常引用。
2.
可能会有人有疑问,为什么我们不能在原来的那个类里面重载一个返回值为常引用的解引用函数呢?答案是不可以,因为返回值不同无法构成重载函数,所以这两个不同返回值的函数不能在同一个类里面出现,这也是为什么我们重建了一个类,专门搞了一个返回值为常引用的解引用函数。
template<class T>struct __list_const_iterator//将迭代器进行了封装,以便于解引用,++,--等运算符依旧对迭代器适用{//迭代器的封装完美体现了面向对象封装的思想,以及类和对象强大的力量。一个成员变量仅仅是结构体指针的迭代器对象//可以通过运算符重载和类封装的思想,将迭代器的功能实现的滴水不漏,隐藏底层实现的机制。typedef list_node<T> node;node* _pnode;__list_const_iterator(node* p):_pnode(p){}const T& operator*(){return _pnode->_data;//返回变量_data的引用,表示数据可以被读或修改,_data的类型是T}__list_const_iterator<T>& operator++()//++改变的就是成员变量_pnode,所以不能用const修饰此函数{_pnode = _pnode->_next;return *this;}__list_const_iterator<T>& operator--(){_pnode = _pnode->_prev;return *this;}bool operator!=(const __list_const_iterator<T>& it)const//比较两个迭代器是否相等,实际比较的是list_node的地址是否相等{return _pnode != it._pnode;}};template<class T>class list{typedef list_node<T> node;public:typedef __list_iterator<T> iterator;//iterator是类模板的typedef,模板也是类型,只不过还没有实例化typedef __list_const_iterator<T> const_iterator;const_iterator begin()const//const修饰*this,代表list对象的成员变量不可被修改,用于const的list对象调用。{return const_iterator(_head->_next);}const_iterator end()const{return const_iterator(_head);}iterator begin(){return iterator(_head->_next);}iterator end(){return iterator(_head);}……………………省略}3.增加模板参数,根据类模板参数的不同,实例化出不同的类(大佬的做法)
1.
上面重建一个类,这样代码冗余的做法大佬是要被笑话的,尤其STL还是开源的代码,大佬其实是通过增加模板参数,在传参数时,根据参数类型的不同实例化出不同的类。
2.
例如下面代码,用const_iterator时,就是用第二个模板参数为const T&的类模板,等T类型确定时,就会实例化出具体的类,当用iterator时,我们就用第二个模板参数为T&的类模板,等T类型确定时,又会实例化出另一个不同的类。
3.
下面是SGI版本源码,可以看到iterator和const_iterator对应的类模板的第二个参数的不同,一个是普通引用,一个是常引用。第三个模板参数T*在下面的部分会讲。
// typedef __list_iterator<T, T&> iterator;// typedef __list_iterator<T, const T&> const_iterator;template<class T, class Ref>struct __list_iterator{typedef list_node<T> node;typedef __list_iterator<T, Ref> Self;node* _pnode;__list_iterator(node* p):_pnode(p){}Ref operator*(){return _pnode->_data;//返回的是数据类型,所以用Ref}Self& operator++(){_pnode = _pnode->_next;return *this;//返回的是迭代器对象,所以用该迭代器对应的类的类型,实际就是__list_iterator<T,Ref>//只是将__list_iterator<T,Ref> typedef为 Self}Self& operator--(){_pnode = _pnode->_prev;return *this;}bool operator!=(const Self& it){return _pnode != it._pnode;}};template<class T>class list{typedef list_node<T> node;public:typedef __list_iterator<T, T&> iterator;//typedef __list_const_iterator<T> const_iterator;typedef __list_iterator<T, const T&> const_iterator;const_iterator begin() const{return const_iterator(_head->_next);}const_iterator end() const{return const_iterator(_head);}……………………省略}4.类名和类型的区别
1.
list是类型,list是类名。
构造函数的函数名和类名相同。
在类外面不能用类名代表类型,在类里面可以用类名代表类型,这算C++的一个坑,但非常不建议这么用,如果在类里面用类名代表类型,这很容易把自己搞晕。

2.
但我们还是用最标准的写法,无论是在类里面还是在类外面,将类名和类型严格区分开来。
四、实现迭代器 + →的访问方式(像结构体指针 + →一样的行为)
1.迭代器指向对象为结构体时,编译器对→的特殊处理(省略一个箭头,提升代码可读性)
1.
当list存的是结构体类型Pos时,直接打印解引用迭代器后的值就会出现问题,因为解引用迭代器后拿到的是Pos类的对象,所以如果想要打印对象的值,我们可以重载Pos类的流插入运算符来实现,如果Pos类的成员变量是私有的,我们也可以用友元函数来解决。
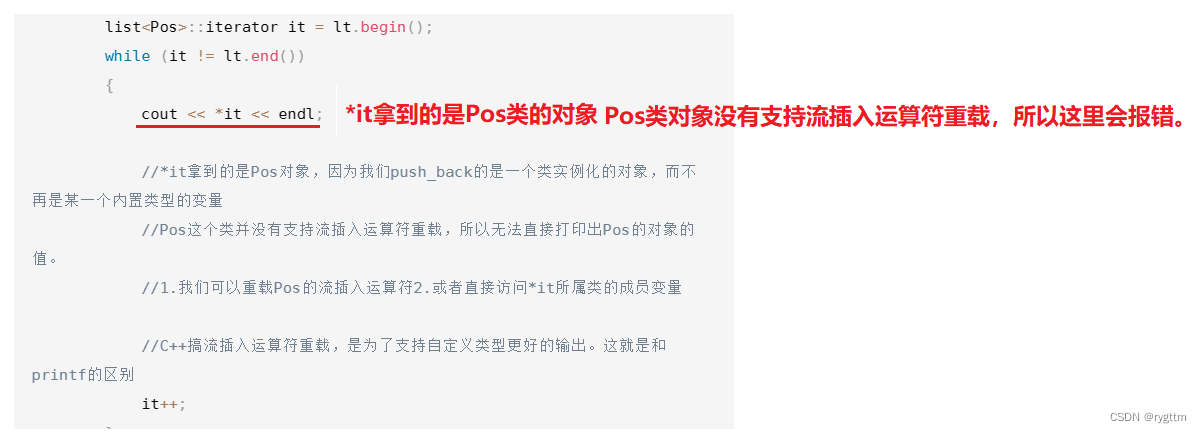
2.
如果不想用流插入,而是就想直接用解引用,那我们需要像下面这样去使用,利用对象.的运算符来进行成员选择。但下面这样的使用方式不怎么舒服,一般情况下如果有结构体指针,而不是结构体对象时,我们喜欢用结构体指针 + →的方式来访问结构体成员。
cout << (*it)._row << ":" << (*it)._col << endl;3.
如果是普通指针我们一般就用解引用,如果是结构指针,我们喜欢用→的访问方式。当迭代器指向的数据是一个结构体对象时,我们更偏向于用→来访问,当迭代器指向的数据是单个数据时,我们更偏向于用*来访问。
4.
所以下面这样的使用方式更舒服一些,因为迭代器it所指向的内容是Pos结构体的对象。但it不是一个结构体指针,不能用→这样的访问方式,这该如何解决呢?不用担心,it是一个对象,我们可以利用运算符重载来解决。
cout << it->_row << ":" << it->_col << endl;5.
→的运算符重载返回的是迭代器所指向的结构体对象的地址,那返回的就是结构体指针,所以最标准的写法应该是下面第一行代码,但是编译器为了代码可读性,做了特殊处理,省略掉一个→。
第二行代码会被编译器处理为第三行代码的样子,从底层角度来讲,第三行代码更好理解,但从语法角度来看,第二行代码的可读性更高一点。
cout << it->->_row << ":" << it->->_col << endl;//严格来说应该是这样写的cout << it->_row << ":" << it->_col << endl;//但编译器为了代码可读性,做了特殊处理,省略掉一个->cout << it.operator->()->_row << ":" << it.operator->()->_col << endl;6.
有人会说,那我能不能像下面这样写呢?当然可以,但是这不符合大多数人的习惯,因为迭代器所指向内容是一个结构体,我们更喜欢用结构体指针+→这样的访问方式来访问,当然如果你非要用对象+ . 这样的方式来访问那也可以,只不过看起来不舒服而已,因为我们一般用*it都是在迭代器所指向内容是数据的情况下才用解引用,如果迭代器所指向内容是结构体,那我们还是习惯用→的方式来访问,也就是迭代器+→的方式。
cout << (*it)._row << ':' << (*it)._col << endl;7.反过头来讲,我们利用类封装和运算符重载的本意就是
//typedef __list_iterator<T,T&,T*> iterator//typedef __list_iterator<T,const T&,const T*> const_iterator;template<class T,class Ref,class Ptr>struct __list_iterator//将迭代器进行了封装,以便于解引用,++,--等运算符依旧对迭代器适用{//迭代器的封装完美体现了面向对象封装的思想,以及类和对象强大的力量。一个成员变量仅仅是结构体指针的迭代器对象//可以通过运算符重载和类封装的思想,将迭代器的功能实现的滴水不漏,隐藏底层实现的机制。typedef list_node<T> node;typedef __list_iterator<T, Ref, Ptr> Self;//Self代表整个类模板实例化的类型,这就是typedef的价值。node* _pnode;__list_iterator(node*p):_pnode(p){}//T* operator->()//{//return &_pnode->_data;//返回list_node的_data的地址,这个地址是对象的地址,可以用于对象的成员选择。//}Ptr operator->(){return &_pnode->_data;//返回list_node的_data的地址,这个地址是对象的地址,可以用于对象的成员选择。}}struct Pos{//friend ostream& operator<<(ostream& out, Pos& p);实际这里不用用友元,因为struct默认是publicPos(int row = 0, int col = 0)//全缺省的构造既能当默认构造用,又能当传具体参数的构造用。:_row(row), _col(col){}int _row;int _col;};ostream& operator<<(ostream& out, Pos& p){out << p._row << ":" << p._col;return out;}void test_list5(){list<Pos> lt;Pos p1(1, 1);lt.push_back(p1);lt.push_back(p1);lt.push_back(p1);lt.push_back(Pos(2, 2));//用匿名对象来push_back,省下自己初始化创建一个对象了。lt.push_back(Pos(3, 3));// int* p -> *p// pos* p -> p->// 解引用的三种方式:1.数组的[] 2.普通指针的解引用 3.结构体指针的成员选择,分为.和->两种成员选择的方式//list<Pos>::iterator it = lt.begin();while (it != lt.end()){//cout << *it << endl;//cout << (&(*it))->_row << ':' << (&(*(&(*it))))->_col << endl;//堪称迂腐。cout << it->_row << ":" << it->_col << endl;//这里编译器省略了一个箭头,对于老手很喜欢//编译器会把上面这行代码转换成下面这行代码//cout << it.operator->()->_row << ":" << it.operator->()->_col << endl;//也还可以,比较照顾新手。//':'":"一个是字符串,一个是字符,打印出来的结果看起来一样是因为\0是标识字符不显示。//operator->()返回Pos对象的地址,因为_data是push_back到list的对象。//应该再加一层->才能正常得到结构体Pos里面的成员变量的值。//所以本来的面貌是cout << it->->_row << it->->_col << endl;//编译器为了可读性,做了特殊处理,省略了一个->//但使用时不可以多加一个->,因为这会干扰编译器的识别。//*it拿到的是Pos对象,因为我们push_back的是一个类实例化的对象,而不再是某一个内置类型的变量//Pos这个类并没有支持流插入运算符重载,所以无法直接打印出Pos的对象的值。//1.我们可以重载Pos的流插入运算符2.或者直接访问*it所属类的成员变量//C++搞流插入运算符重载,是为了支持自定义类型更好的输出。这就是和printf的区别it++;}//map<string, string>dict;//这个数据结构的迭代器很常用->,我们上面的list迭代器一般还是*解引用用的比较多。cout << endl;print_list(lt);}2.实现const链表对象的迭代器在→解引用时,返回值不可被修改(增加模板参数,实例化出不同的类)
1.
只要我们再增加一个模板参数,就可以在实例化类时给const_iterator第三个参数传一个const T *,表示→成员函数的返回值为结构体指针,但是指针所指向内容不可被修改,这就完成了const对象的迭代器所指向内容为结构体时,保证结构体中的内容不可被修改的工作。
库里面也是三个模板参数。
template<class T,class Ref,class Ptr>struct __list_iterator//将迭代器进行了封装,以便于解引用,++,--等运算符依旧对迭代器适用{//迭代器的封装完美体现了面向对象封装的思想,以及类和对象强大的力量。一个成员变量仅仅是结构体指针的迭代器对象//可以通过运算符重载和类封装的思想,将迭代器的功能实现的滴水不漏,隐藏底层实现的机制。typedef list_node<T> node;typedef __list_iterator<T, Ref, Ptr> Self;//Self代表整个类模板实例化的类型,这就是typedef的价值。node* _pnode;__list_iterator(node*p):_pnode(p){}Ptr operator->()//当迭代器指向内容是结构体时,我们倾向于这样的访问方式。{return &_pnode->_data;//返回迭代器所指向的结构体的地址。}}template<class T>class list{typedef list_node<T> node;public:typedef __list_iterator<T,T&,T*> iterator;//iterator是类模板的typedef,模板也是类型,只不过还没有实例化//typedef __list_const_iterator<T> const_iterator;typedef __list_iterator<T,const T&,const T*> const_iterator;………………省略}3.重新理解迭代器的本质(行为像指针一样,可用于所有底层数据结构不同的容器)
1.
当我们实现迭代器的解引用和箭头这样的访问方式的函数重载后,我们不妨再来理解一下,迭代器到底是一个什么样的东西,如果不理解透彻迭代器的本质,那对于迭代器的理解就永远都浮在表面,无法发生质的改变。
2.
实际上在理解时我们就可以将迭代器看作指针,因为迭代器始终都是围绕指针展开的,我们说过迭代器的特征之一就是像指针一样的行为,在指针所指向内容是数据时,指针可以解引用,当指针所指向内容是结构体时,可以用箭头进行成员选择。
但是不同的数据结构底层都不一样,如果仅仅将迭代器就设定为一个原生指针,他是无法满足所有数据结构的要求的,这时候我们就用类封装和运算符重载的知识来对迭代器进行行为的包装,让迭代器在使用时的行为就像指针一样,实现迭代器的目的就是让所有底层数据结构都不同的容器在使用时,都能用一个 “指针” 来读写容器的所有数据,这个广义上的指针就是我们所说的迭代器,我们通过类和对象以及类封装的思想,让迭代器的行为达到像指针一样,这就是迭代器的本质。
五、反思迭代器类的设计,回顾类和对象的知识
1.
如果没有写析构函数,则编译器默认生成的析构函数对内置类型不会处理,对自定义类型会调用他的析构函数。如果没有写构造函数,则编译器默认生成的构造函数对内置类型不会处理,对自定义类型会调用他的构造函数。
2.
在栈实现队列那道题中,如果我们自己写了无参的默认构造,则成员变量也会在初始化列表进行初始化,在初始化列表处,对于自定义类型,初始化列表会调用他的默认构造。如果此时自定义类型没有默认构造,则会报错。对于内置类型,初始化列表不会处理,但如果你在初始化列表显示写了,那就用显示写的进行初始化,如果没有写,在成员变量声明处有缺省值就用缺省值,没有就用编译器不处理内置类型的随机值。
3.
构造的行为和析构的行为类似,所以对于MyQueue类来说,如果不写他的析构函数,编译器的默认析构会调用自定义类型成员变量的默认析构,如果是内置类型则不会处理。


4.
迭代器类我们没有写析构函数,则会调用编译器默认生成的析构函数,而默认的析构不会处理内置类型为结构体指针的成员变量,所以结点的空间就不会被释放。不释放当然是正确的,因为结点是属于链表的,释放结点的工作应该交给链表类而不是迭代器类。
所以当内置类型涉及资源申请时,也并不一定就要写析构函数,还需要视情况而定。就比如迭代器类,你敢不敢写析构函数把结点空间释放掉,你当然不敢,因为迭代器类只是借助类封装和运算符重载去访问一下结点里面的数据,而不是要对结点进行资源清理,资源清理的工作是list类的。
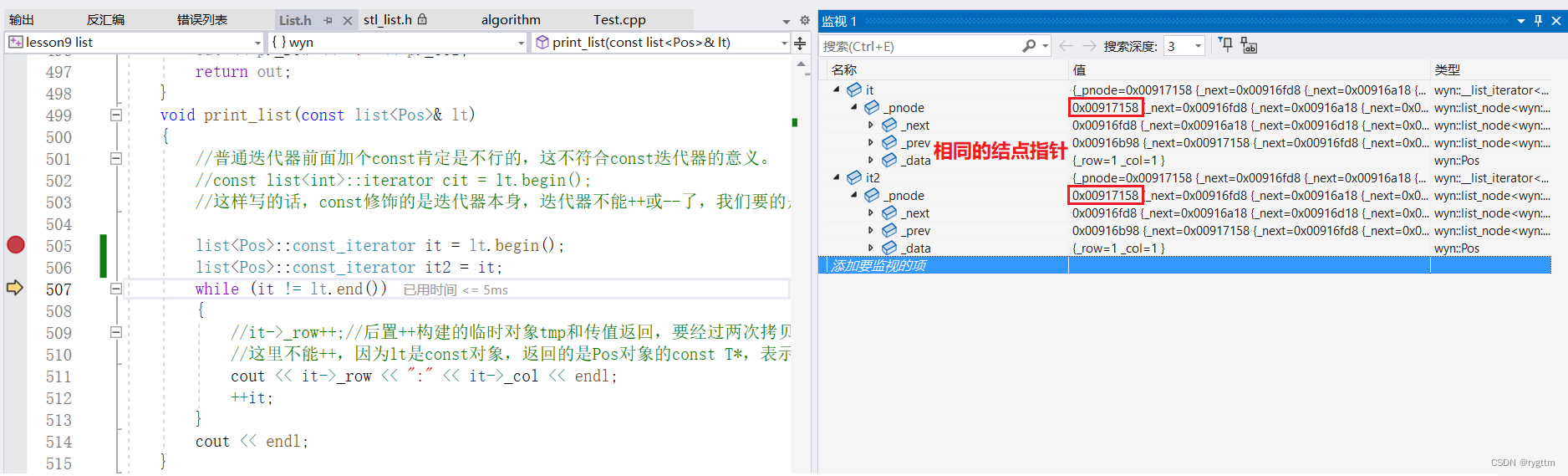
5.
迭代器类我们也没有写拷贝构造和赋值重载,但我们有用到迭代器的拷贝构造和赋值,所以用到拷贝构造和赋值的地方就都是浅拷贝。但是浅拷贝满足了我们的要求,迭代器it和it2里面的结点指针是一模一样的,因为发生了浅拷贝,所以两个迭代器里面的结点指针都指向了同一块空间,但并没有出错,其实就是因为迭代器类没有写析构函数,编译器的默认析构不会处理这两个迭代器里面相同结点指针所指向的一块儿空间,因为默认析构不会对内置类型处理,结点指针也是内置类型。
所以当内置类型涉及资源申请时,也并不一定需要写深拷贝,还需要视情况而定
6.
所以一个类如果不需要显示写析构函数,那就不需要写拷贝构造和赋值。
需要显示写析构函数,那就要去写拷贝构造和赋值,否则会由于浅拷贝导致程序出现问题。
六、对比vector和list,总结三个容器的迭代器失效
vector的优点:
a.支持下标的随机访问
b.尾插尾删效率高
c.CPU高速缓存命中率高(局部性原理)
vector的缺点:
a.前面部分插入删除数据效率低(插入和删除需要挪动数据)
b.扩容有消耗,还存在一定空间浪费(2倍扩容是比较合适的,开大了浪费,开小了需要频繁扩容)
list的优点:
a.按需申请释放空间,无需扩容
b.任意位置插入删除的时间复杂度是O(1),不考虑find查找位置,只单论erase和insert。
list的缺点:
a.不支持下标的随机访问
b.CPU高速缓存命中率低(局部性原理)
1.
vector和list是互补配合的关系,就像我们的左手和右手,如果只用一只手,无论哪个手都不会方便,而配合起来就会方便很多。
2.
vector的insert和erase之后迭代器都会失效,list在insert之后迭代器不会失效,erase之后迭代器会失效。
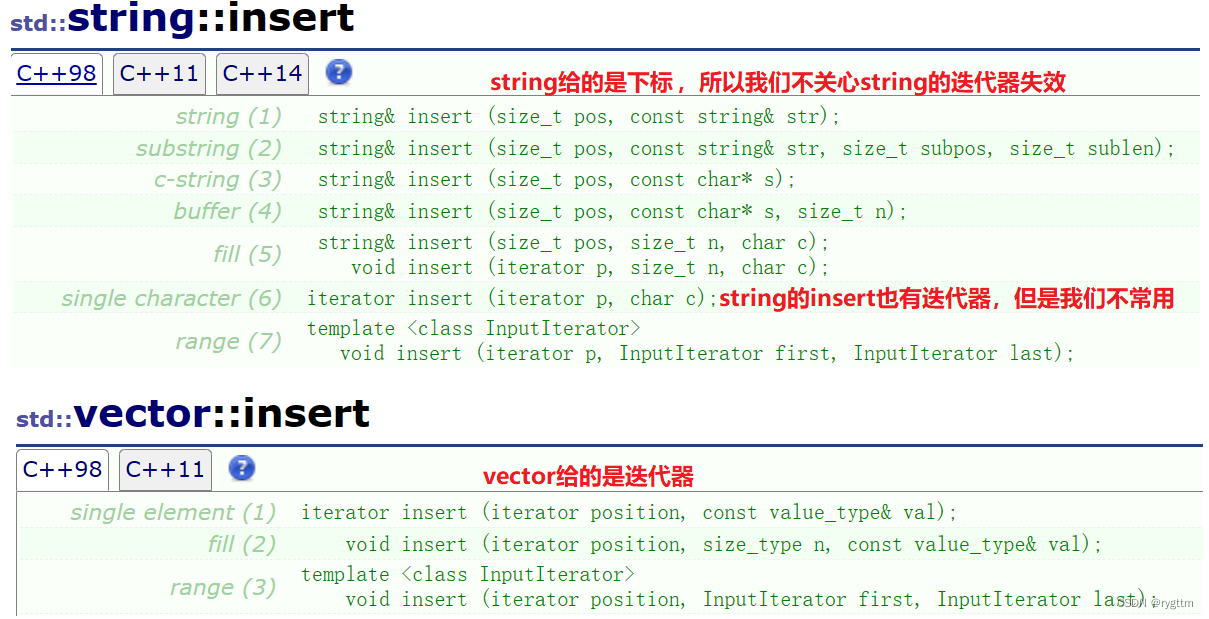
3.
string的迭代器会不会失效呢?前面我们没有谈过string的迭代器失效问题,只谈了vector和list的迭代器失效问题。但其实string的迭代器在insert和erase之后也会失效,和vector是类似的。
但是我们一般不关注string的迭代器失效,因为string的insert和erase接口函数都是下标支持的,迭代器支持的用的很少。