参考链接
YOLOv5训练结果分析:一个毕设笔记,其中对于每次yolov5 训练运行后的结果解释的不错。本文内容
yolov5 的数据格式 介绍 yolov5 模型中 train,py 的相关参数 介绍输出展示的内容都是什么含义一、yolov5 的数据格式
1.1 数据格式:label_index,cx, cy,w,h
label_index :为标签名称在标签数组中的索引,下标从 0 开始。cx:标记框中心点的 x 坐标,数值是原始中心点 x 坐标除以 图宽 后的结果。cy:标记框中心点的 y 坐标,数值是原始中心点 y 坐标除以 图高 后的结果。w:标记框的 宽,数值为 原始标记框的 宽 除以 图宽 后的结果。h:标记框的 高,数值为 原始标记框的 高 除以 图高 后的结果。
注:其中的实例即为标记框。
1.2 样例

1.3 数据集的存储格式

1.4 yolov5 创建图片名称列表的程序
# -*- coding:utf-8 -*-import osdef create_data_list(root_path, is_val='val'): txt_path = './yolov5_face_'+str(is_val)+'.txt' img_root_path = os.path.join( os.path.join(root_path, 'images', is_val) ) with open(txt_path, 'w') as f: for file_name in os.listdir(img_root_path): if file_name.split('.')[-1]!= 'jpg': print('文件名称有误 {}'.format(file_name)) img_path = os.path.join(img_root_path, file_name) line = '{}\n'.format(img_path) f.writelines(line)### 图片和标签文件存储的根路径root_path = ''create_data_list(root_path, 'train')create_data_list(root_path, 'val')二、 train.py 中相关参数
自己尝试修改过的参数
–weigths: 指的是训练好的网络模型,用来初始化网络权重。为空时从头开始训练–cfg:网络结构配置文件。其中 nc 表示标签数据中有多少类别。–data:数据路径。数据集存储路径结构参考 1.3 部分。 指向数据存储的根路径,例如训练集:root_path / images / train / ,此路径下存储所有训练数据的图片。 指向存储图片路径的 txt 文件,txt 文件每一行内容为一张图片的绝对路径。例如:…/ coco / train2017.txt 。 无论采用两种方式中的哪一种,此配置文件中都指定了 【标签数量】、【标签名称】。 –epochs:训练迭代次数–batch-size:每次喂给神经网络的图片数量,一般设置为 2 的 n 次幂。–imgsz:训练图片尺寸。第一个参数为训练集图片的输入尺寸,第二个参数为测试集图片的输入尺寸,需要设置为 32 的倍数(网络进行过程中会进行 32 倍下采样)。–nosave: 只保留最终网络模型。 default = True ,只保留最后一次的训练结果,中间过程的权重文件(.pt)不进行保存。 default = False , 训练过程中产生的权重文件,进行可选择性的保存。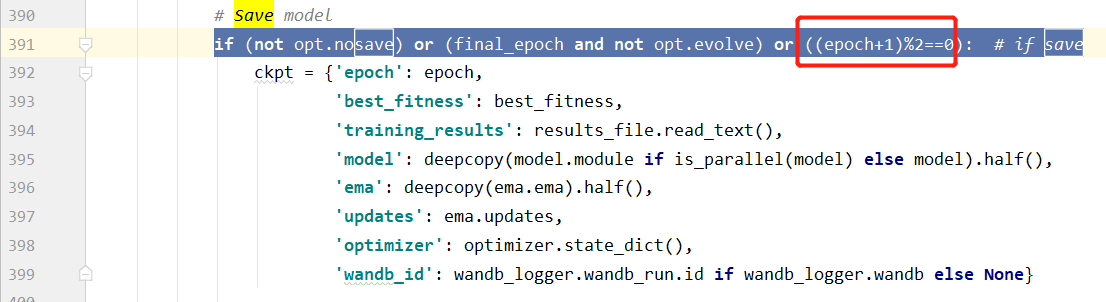 –notest :是否只在训练完成后,对验证集进行测试。 default = True ,只在训练完成后,进行一次测试。default = False ,每一个 epoch 完成后都对验证集进行测试。
–notest :是否只在训练完成后,对验证集进行测试。 default = True ,只在训练完成后,进行一次测试。default = False ,每一个 epoch 完成后都对验证集进行测试。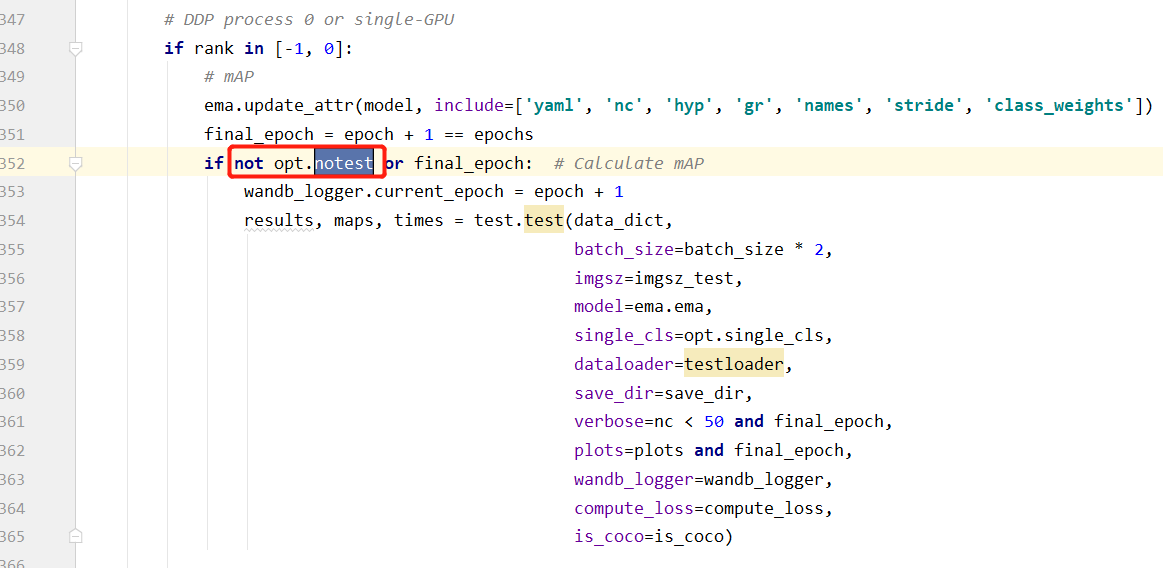 –device:训练网络的设备cpu还是gpu–project:训练结果保存路径。即输出结果 results.txt 、权重文件,存储的根路径。默认名称为 runs。–name: 训练结果保存文件名。在project 对应的文件夹中,默认问 exp (看到一篇文章中说,超过10个之后,会循环覆盖)。–save-period:训练多少次保存一次网络模型。(应该综合 --nosave 同时考虑)–noautoanchor:是否采用锚点检查。 在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。
–device:训练网络的设备cpu还是gpu–project:训练结果保存路径。即输出结果 results.txt 、权重文件,存储的根路径。默认名称为 runs。–name: 训练结果保存文件名。在project 对应的文件夹中,默认问 exp (看到一篇文章中说,超过10个之后,会循环覆盖)。–save-period:训练多少次保存一次网络模型。(应该综合 --nosave 同时考虑)–noautoanchor:是否采用锚点检查。 在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数。
因此初始锚框也是比较重要的一部分,比如Yolov5在Coco数据集上初始设定的锚框:
 但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。当然,如果觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭。
但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。当然,如果觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭。 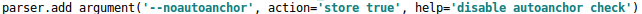 控制的代码即train.py中上面一行代码,设置成False,每次训练时,不会自动计算。
控制的代码即train.py中上面一行代码,设置成False,每次训练时,不会自动计算。 以下参数还未尝试修改。
参考链接:https://blog.csdn.net/weixin_42638415/article/details/120799608
–hyp: 训练网络的一些超参数设置
–rect: 是否采用矩形训练
–resume: 指定你之前训练的网络模型,是否从最近的上一个模型开始训练。
–evolve:是否寻找最优参数
–bucket:gsutil bucket
–cache:是否对图片进行缓存,加快训练
–image-weights:测试过程中,图像的那些测试地方不太好,对这些不太好的地方加权重
–multi-scale:图片尺度变换
–single-cls:训练数据集是单类别还是多类别
–adam:是否采用adam
–sync-bn:分布式训练
–local_rank:DDP参数,请勿修改。
–workers: 多线程训练,设置最多多少个线程同时进行分布式的训练。个人理解,线程之间的交互也会耗时。
–entity :W&B entity
–exist-ok: 覆盖掉上一次的结果,不新建训练结果文件
–quad:在dataloader时采用什么样的方式读取我们的数据
–linear-lr:按照线性的方式去调整学习率
–label-smoothing: 对标签平滑,防止过拟合
–upload_dataset:Upload dataset as W&B artifact table
–bbox_interval:Set bounding-box image logging interval for W&B
三、输出结果分析
3.1 训练时,屏幕中的输出结果

3.2 log文件,results.txt 文件中的内容分析
参考链接:https://blog.csdn.net/thy0000/article/details/125281995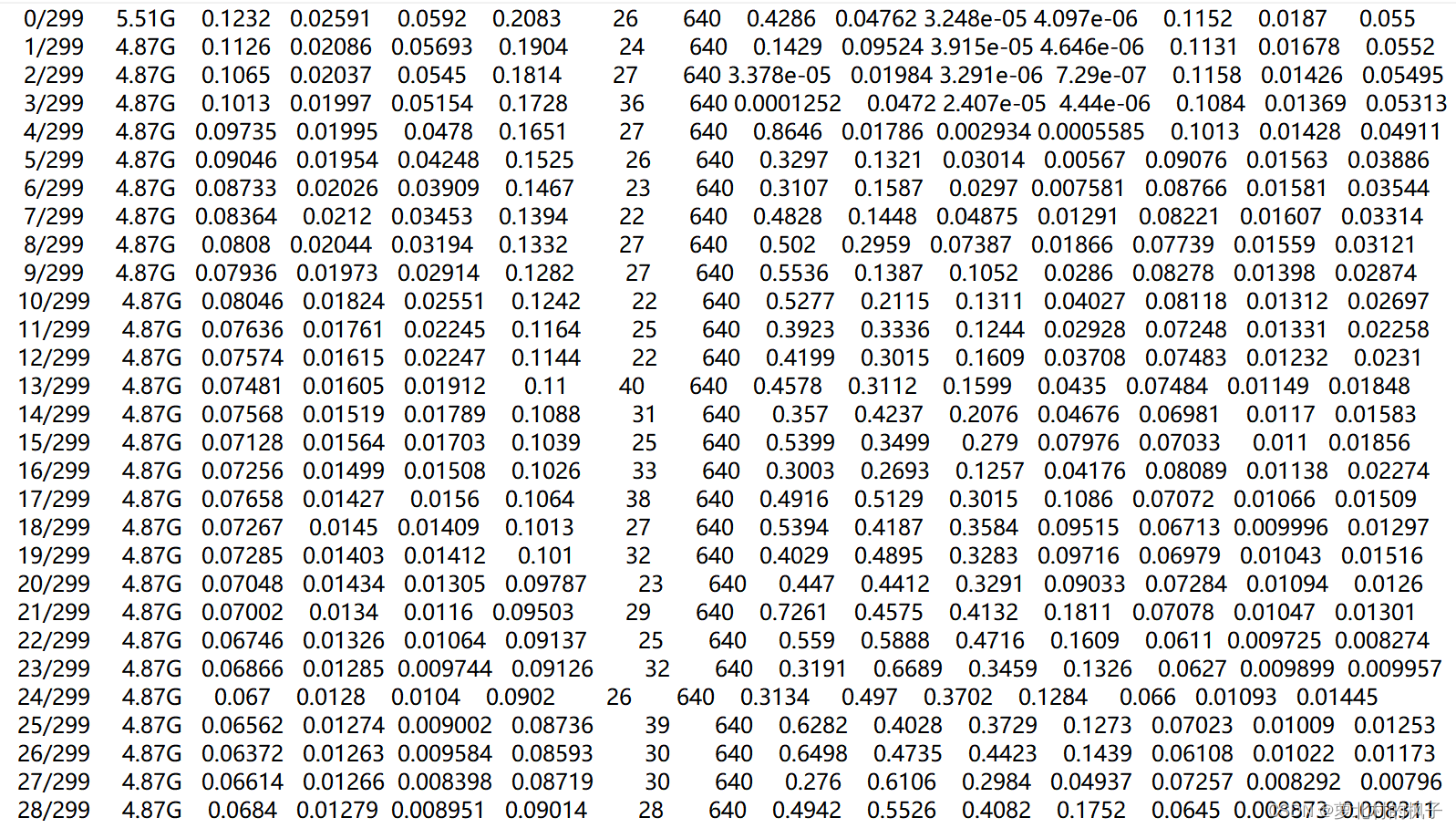
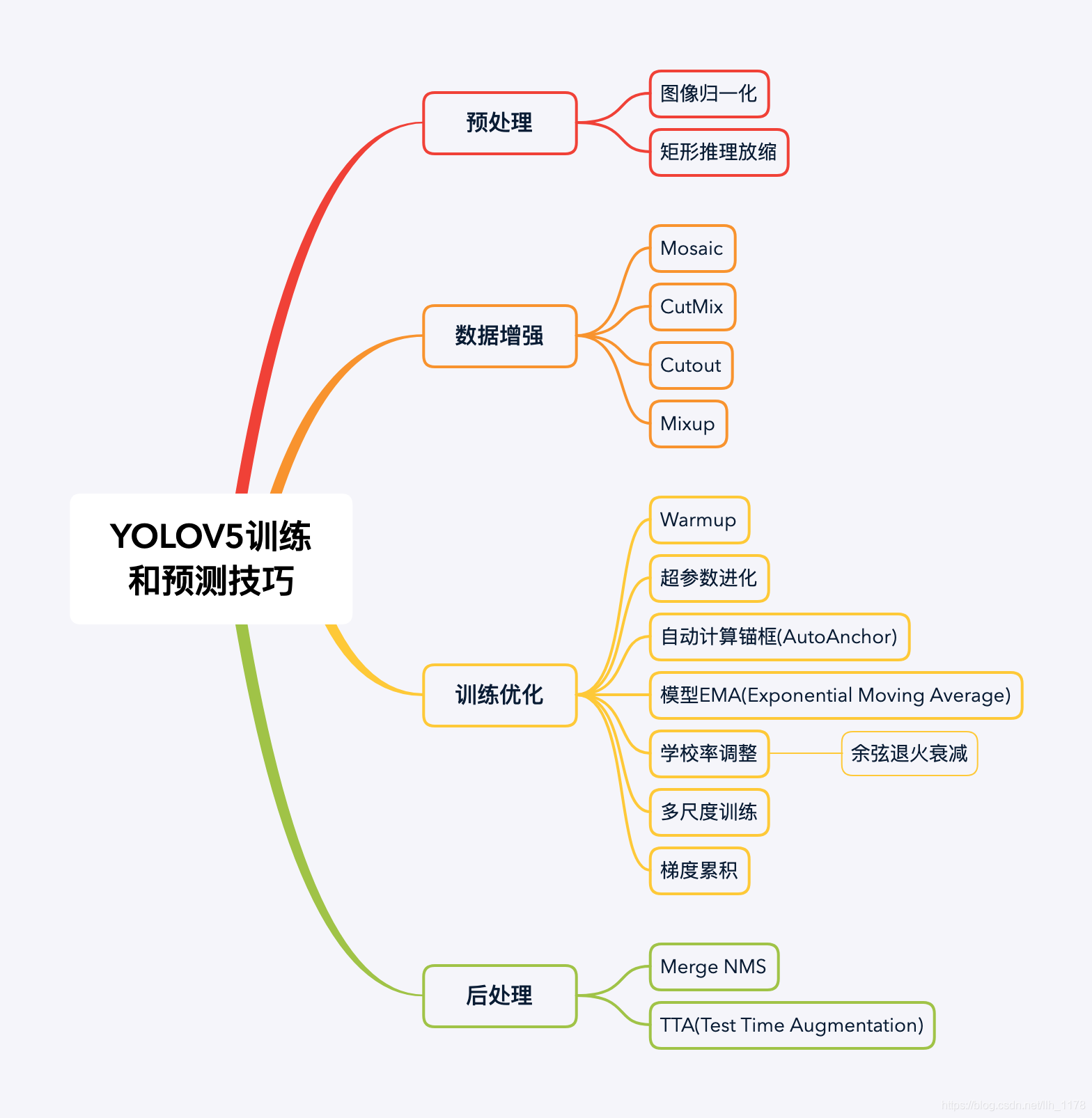
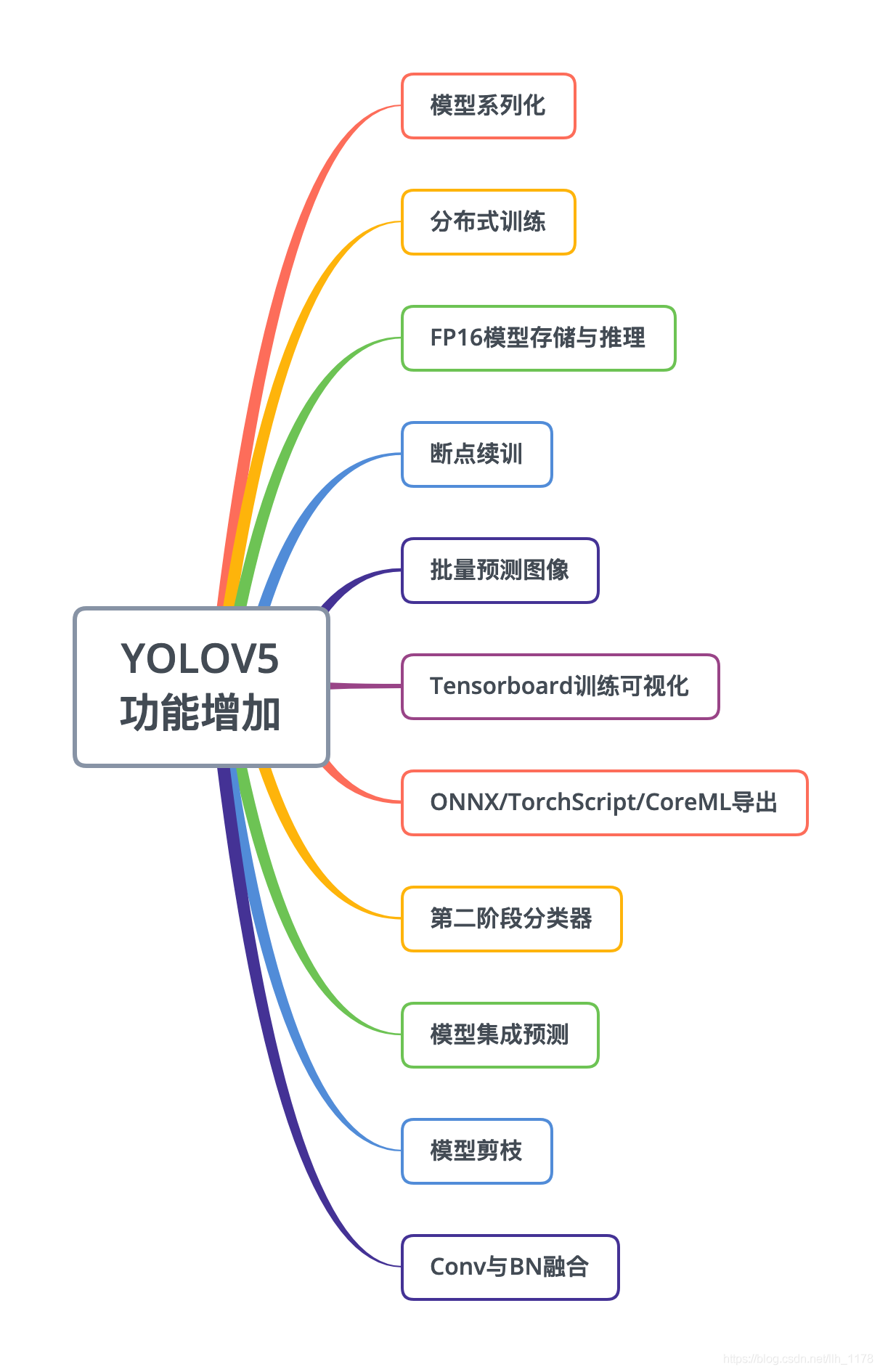
四、其他较好的图解