目录
1. 模板
2. 函数模板
2.1 函数模板概念
2.2 函数模板格式
2.3 函数模板原理
2.4 函数模板的实例化
2.5 模板参数的匹配原则
2.6 声明定义分离
3. 类模板
3.1 类模板格式
3.2 类模板的实例化
3.3 类模板中函数放在类外进行定义时
4. 模板分离编译
4.1 什么是分离编译
4.2 模板的分离编译
5. 缺省值,返回值
6. 总结
C语言总结在这常见八大排序在这
作者和朋友建立的社区:非科班转码社区-CSDN社区云???
期待hxd的支持哈? ? ?
最后是打鸡血环节:你只管努力,剩下的交给天意? ? ?
1. 模板
首先模板分为函数模板和类模板 想到模板,就会联想到泛型编程 泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础。 网图: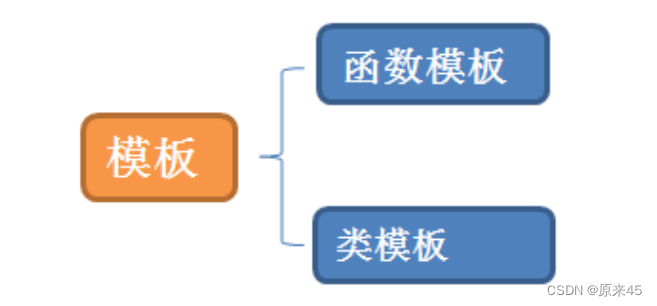 在之前,我们已经知道了函数重载 还是那一个例子 Swap函数交换 int double char 哪怕是函数重载,我们也要写三个,但是如果有了模板,我们只需要:
在之前,我们已经知道了函数重载 还是那一个例子 Swap函数交换 int double char 哪怕是函数重载,我们也要写三个,但是如果有了模板,我们只需要: 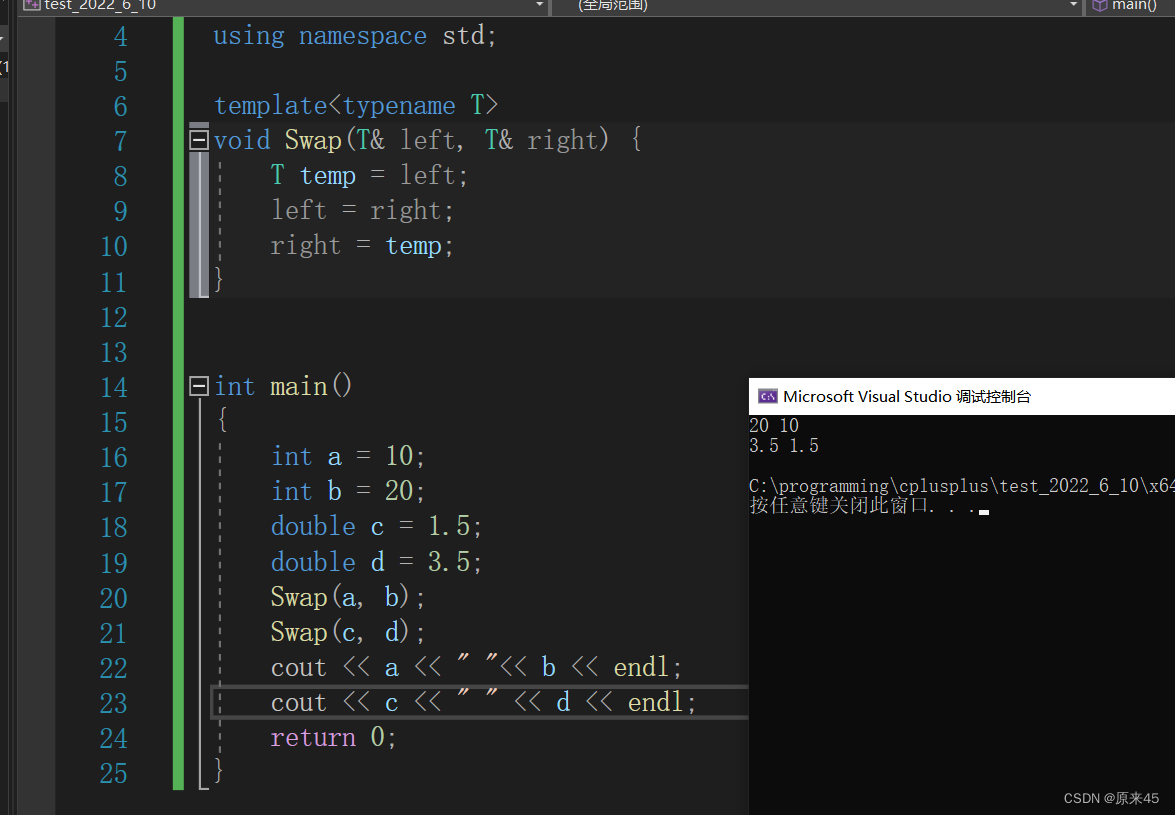 告诉编译器一个模板,让编译器根据不同的类型利用该模板来生成代码
告诉编译器一个模板,让编译器根据不同的类型利用该模板来生成代码 2. 函数模板
2.1 函数模板概念
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生 函数的特定类型版本。(上面的图就是一个函数模板的例子)2.2 函数模板格式
template<typename T1, typename T2,......,typename Tn> 返回值类型 函数名 ( 参数列表 ){}template<typename T>void Swap( T& left, T& right) { T temp = left; left = right; right = temp; }2.3 函数模板原理
函数模板是一个蓝图,它本身并不是函数,是编译器用使用方式产生特定具体类型函数的模具。 所以其实模板就是将本来应该我们做的重复的事情交给了编译器。简单说就是本来我们应该多去写的Swap的重复工作去给编译器做了 网图:
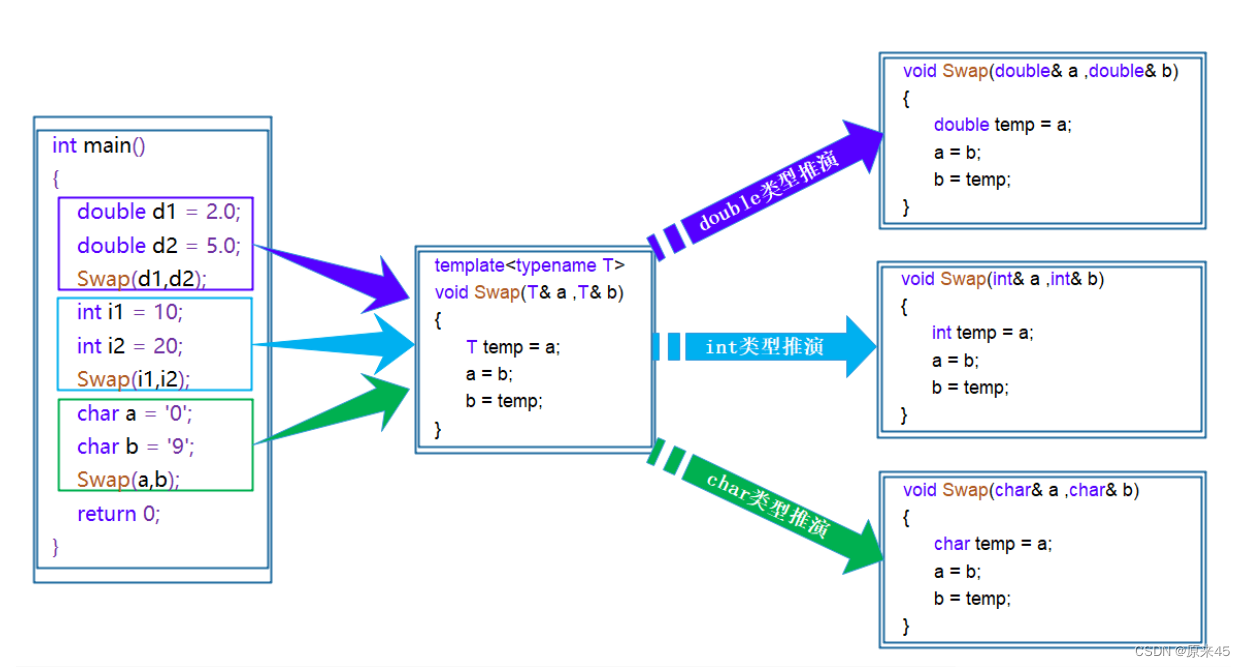 在编译器编译阶段 ,对于模板函数的使用, 编译器需要根据传入的实参类型来推演生成对应类型 的函数 以供调用。比如: 当用 double 类型使用函数模板时,编译器通过对实参类型的推演,将 T 确定为 double 类型,然后产生一份专门处理 double 类型的代码 ,对于字符类型也是如此。
在编译器编译阶段 ,对于模板函数的使用, 编译器需要根据传入的实参类型来推演生成对应类型 的函数 以供调用。比如: 当用 double 类型使用函数模板时,编译器通过对实参类型的推演,将 T 确定为 double 类型,然后产生一份专门处理 double 类型的代码 ,对于字符类型也是如此。 2.4 函数模板的实例化
用不同类型的参数使用函数模板时 ,称为函数模板的 实例化 。模板参数实例化分为: 隐式实例化 和显式实例化 。 1. 隐式实例化:让编译器根据实参推演模板参数的实际类型 2. 显式实例化:在函数名后的 <> 中指定模板参数的实际类型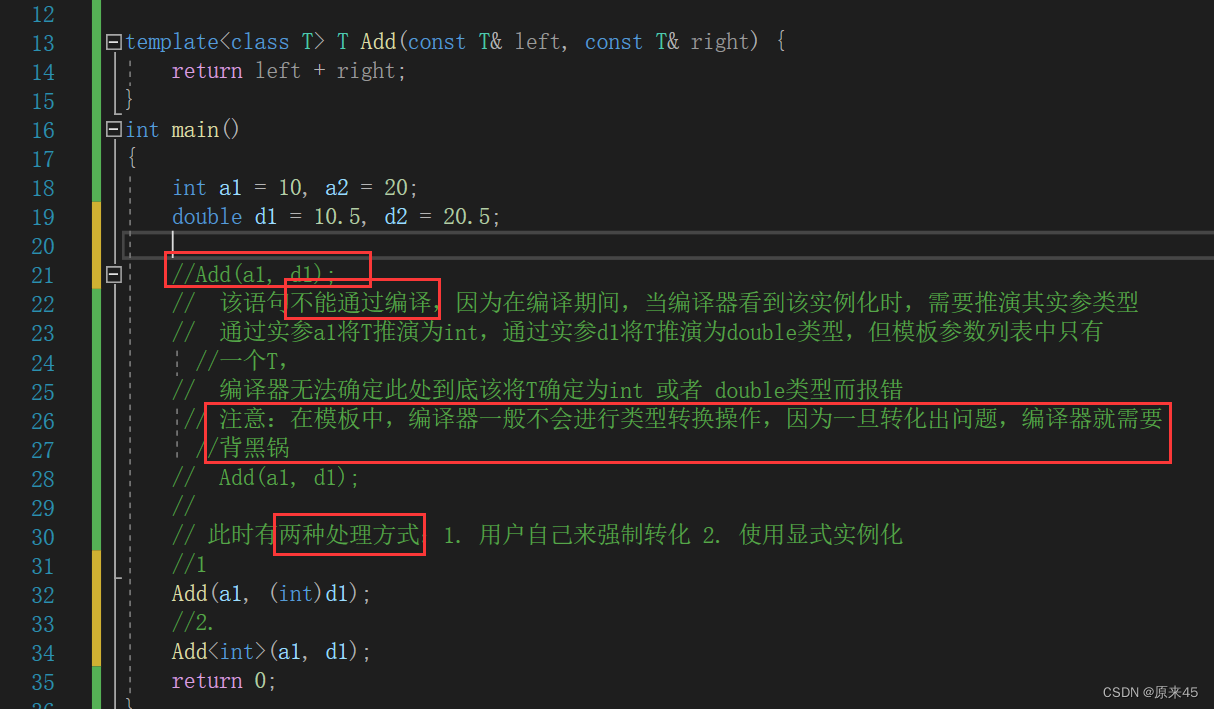
2.5 模板参数的匹配原则
1. 一个非模板函数可以和一个同名的函数模板同时存在,而且该函数模板还可以被实例化为这 个非模板函数 就比如一个模板的Add和一个自己实现的Add可以一起存在 然后: void Test () { Add ( 1 , 2 ); // 与非模板函数匹配,编译器不需要特化 Add < int > ( 1 , 2 ); // 调用编译器特化的 Add 版本 } 2. 对于非模板函数和同名函数模板,如果其他条件都相同,在调动时会优先调用非模板函数而 不会从该模板产生出一个实例。如果模板可以产生一个具有更好匹配的函数, 那么将选择模 板。 简单说会先找自己实现的有没有,没有就去看模板能不能实例化一个。
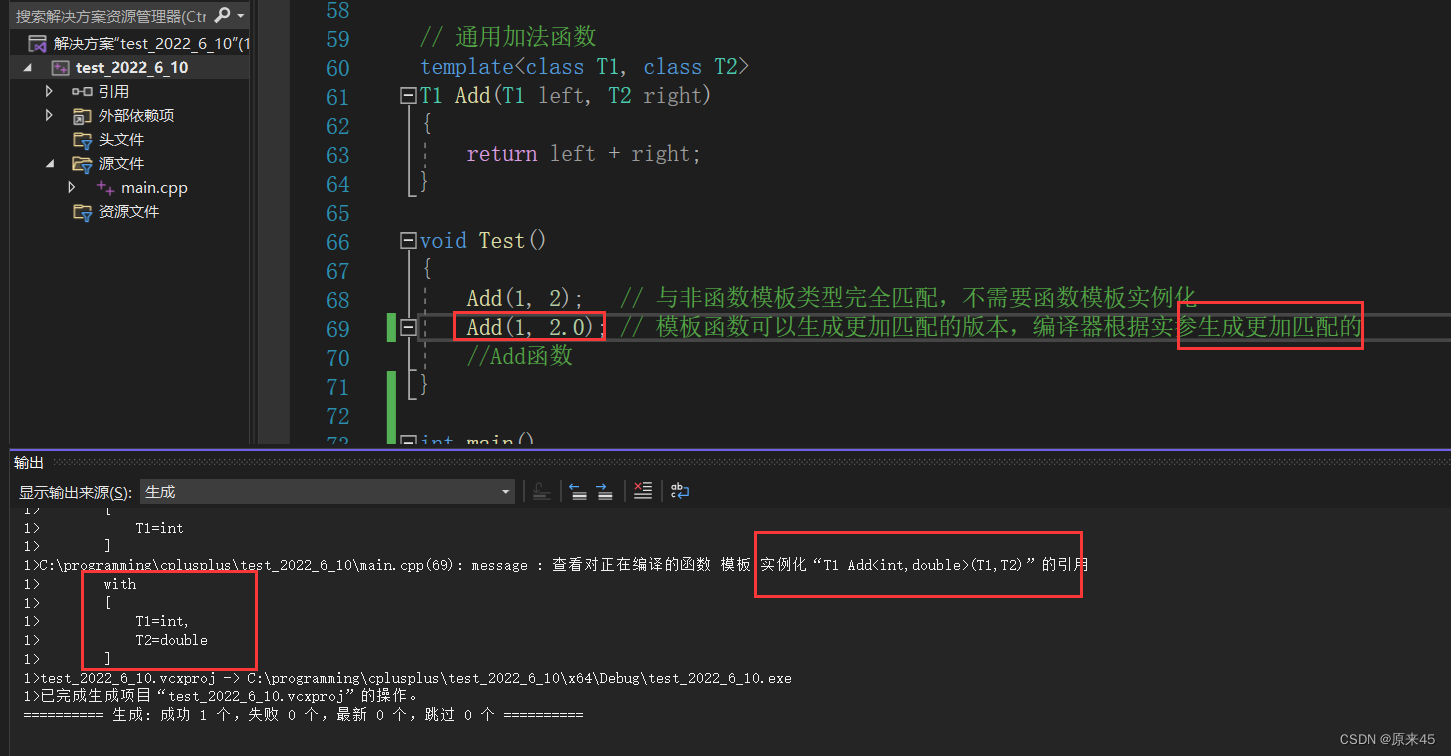
3. 模板函数不允许自动类型转换,但普通函数可以进行自动类型转换
2.6 声明定义分离
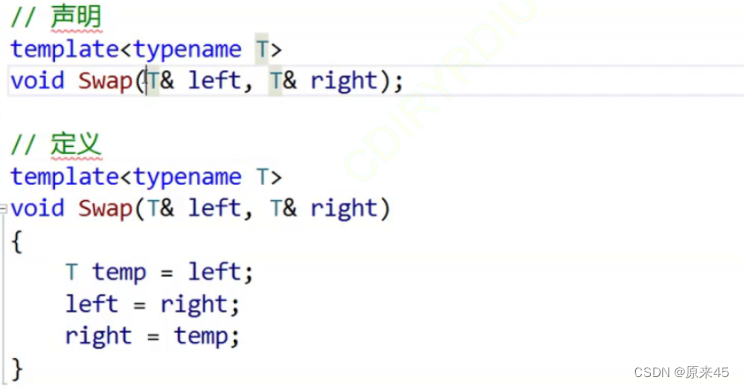
也可以声明定义分离
不同的是模板参数声明定义都要给
3. 类模板
3.1 类模板格式
template<class T1, class T2, ..., class Tn>class 类模板名{ // 类内成员定义};这里就习惯用上class,上面的函数模板是typename
3.2 类模板的实例化
类模板实例化与函数模板实例化不同, 类模板实例化需要在类模板名字后跟 <> ,然后将实例化的 类型放在 <> 中即可,类模板名字不是真正的类,而实例化的结果才是真正的类 。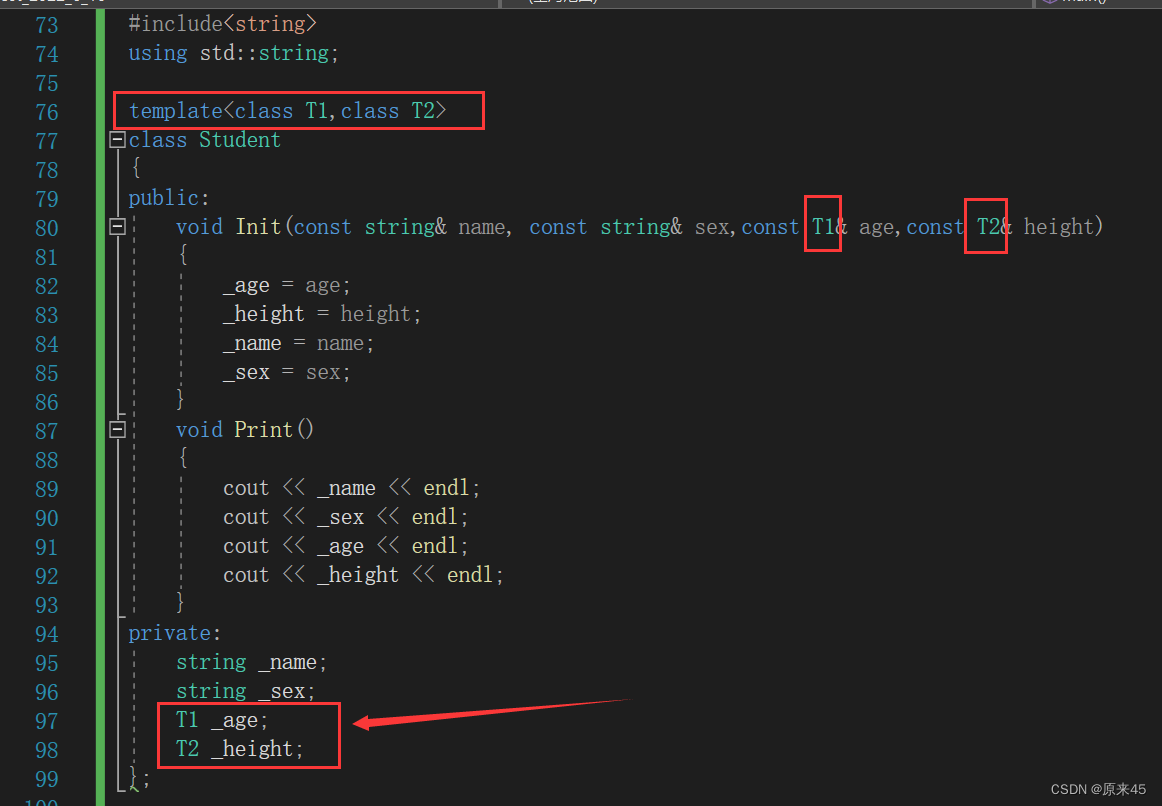
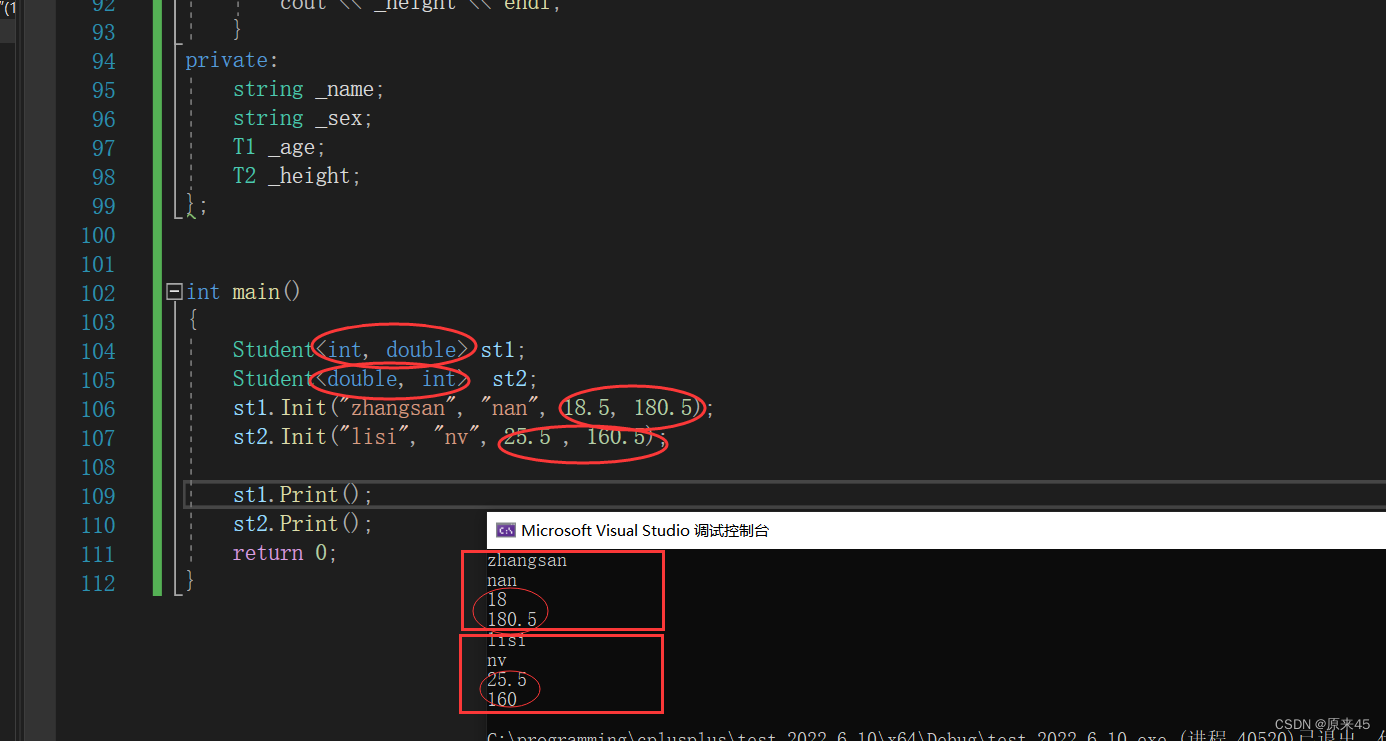 虽然有警告,但是为了测试,问题不大。 我们可以发现这里是创建了两个对象的,因为他们在各自的年龄和身高打印都是有所区别的(有无小数)
虽然有警告,但是为了测试,问题不大。 我们可以发现这里是创建了两个对象的,因为他们在各自的年龄和身高打印都是有所区别的(有无小数)
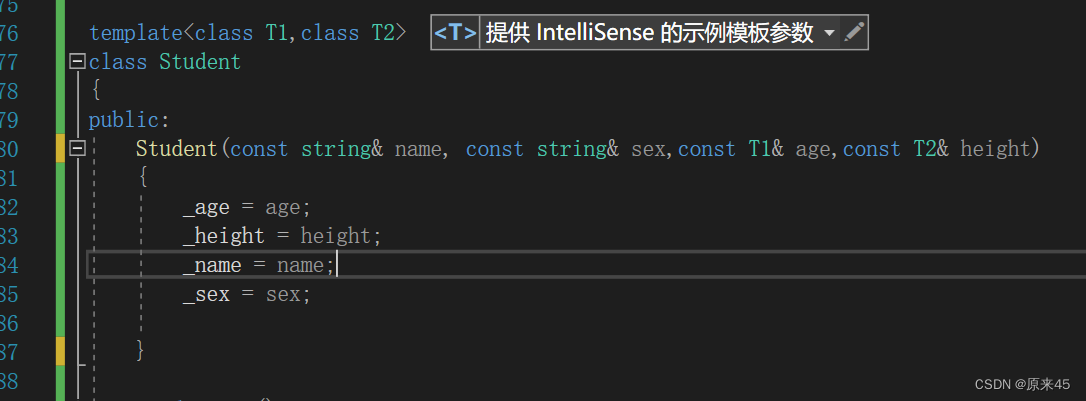
在这里 Student 这个类是一个模板,我们用这个模板创建了两个对象 分别是张三和李四
注意:Student 不是具体的类,是编译器根据被实例化的类型生成具体类的模具PS:上面是用的Init,习惯还没改过来,大家还是用构造函数比较好

3.3 类模板中函数放在类外进行定义时
需要加模板参数列表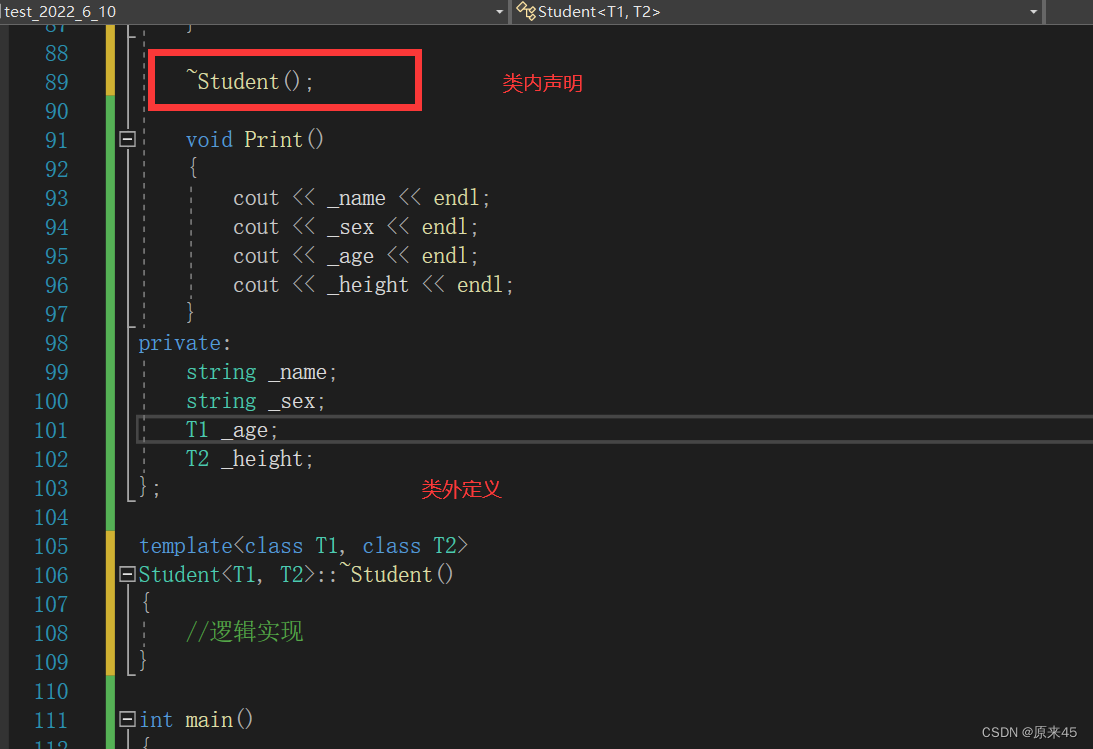
4. 模板分离编译
4.1 什么是分离编译
一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程称为分离编译模式。4.2 模板的分离编译
假如有以下场景,模板的声明与定义分离开,在头文件中进行声明,源文件中完成定义:// a.htemplate<class T> T Add(const T& left, const T& right);// a.cpptemplate<class T> T Add(const T& left, const T& right) { return left + right; }// main.cpp#include"a.h"int main(){ Add(1, 2); Add(1.0, 2.0); return 0; }我们开始运行
问题:会出现链接错误。
原因:首先程序运行是要预处理,编译汇编和链接。对于头文件的内容,a.cpp .i .s .o模板都是空的,因为编译器下不了手,不知道T是啥。(模板是在编译阶段处理,不是预处理)
main.cpp 里面因为只有声明,所以call是不知道地址的
然后链接的时候,因为a.cpp是没有生成对应的函数的(因为之前T不知道),所以链接的时候会发生链接错误。
简单说就是编译的时候经过模板的定义了但是因为T不知道所以不会生成对应的汇编代码,导致最后main.cpp里面要调用的时候并没有生成对应的函数所以会出现链接错误。

解决:
放在一个名为 .hpp 的文件,也是就是这个文件是.h和.cpp的合体,寓意更好。直接.h也可以哈。(推荐)对于上面的原因对症下药,因为只有声明没有生成对应的定义,所以我们直接在 a.cpp 文件 显示实例化指定 在定义的下面加上:templateint Add<int>(int& left, int& right);templatedouble Add<double>(double& left, double& right);为什么:
但是为什么放在一起就没有链接错误了?
因为声明和定义放在一起,调用函数的时候直接实例化call地址去了,所以不报错并不是因为链接能找到,而是根本没有去找,直接call地址了。
5. 缺省值,返回值
也可以有缺省值(半/全),但是必须是从右往左缺省(类比函数),因为传参是从左往右传的

也可以模板做返回值
6. 总结
优点: 1. 模板复用了代码,节省资源,更快的迭代开发, C++ 的标准模板库 (STL) 因此而产生 2. 增强了代码的灵活性 缺陷: 1. 模板会导致代码膨胀问题,也会导致编译时间变长 2. 出现模板编译错误时,错误信息非常凌乱,不易定位错误最后的最后,创作不易,希望读者三连支持?
赠人玫瑰,手有余香?