目录
一、概述
二、头结点的介绍及作用
三、不带头结点单链表实现
?3.1 C语言定义链表结点
?3.2 无头结点单链表初始化
?3.3 无头结点单链表插入数据
?3.4 无头结点单链表删除数据
?3.5 无头结点单链表查找数据
?3.6 无头结点单链表的销毁
四、无头结点单链表完整代码
五、有头结点单链表完整代码

一、概述
上一篇文章 线性表详解 讲了线性表的基本概念,并且一步一步地用C语言实现了 带头结点的单链表,今天就一直在想 带头结点 和 不带头结点 的单链表究竟有什么不同?这篇文章就总结一下,这两者的差异,且一步一步地实现(不带头结点)的单链表,最后给出这两种链表的C语言实现代码。

二、头结点的介绍及作用
头结点:为了方便操作链表,在第一个结点前增加的一个结点,其数据域可以不存储任何信息,指针域存储第一个结点地址。有了头结点,第一个元素的插入和删除操作就和其他元素一样了。头结点不是必须的。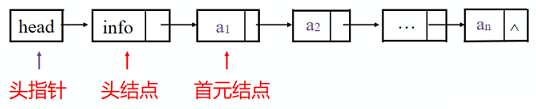
头结点的作用:从头结点的定义来看,头结点的作用是为了使第一个元素的插入和删除操作与其他元素一样。
有头结点的情况下:
1、头指针只会指向头结点;
2、第一个结点的插入操作只会改变头结点的next指针的值,将其指向新结点。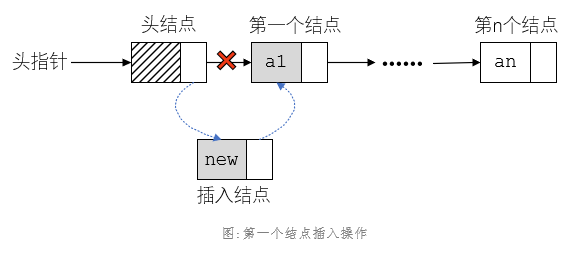
3、第一个结点的删除操作只会改变头结点的next指针的值,将其指向第二个结点。
无头结点的情况下:
1、头指针会指向第一个结点,第一个结点改变则头指针的值会变,空链表时指向NULL;
2、第一个结点的插入操作会改变头指针值,将其指向新结点。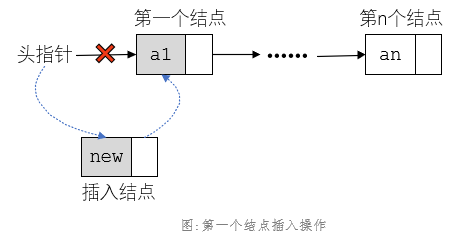
3、第一个结点的删除操作会改变头指针值,将其指向第二个结点。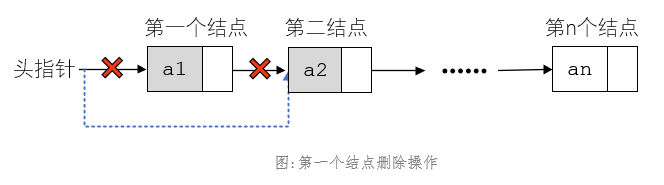

三、不带头结点单链表实现
从前面可以看到 带头结点 和 无头结点 的单链表的一些区别,这一小节就一步步地实现一个不带头结点的单链表。为了可以和上篇文章带头结点单链表形成对比,数据结构和函数尽量都上一篇文章的保持一致。
?3.1 C语言定义链表结点
typedef int ElemType;typedef struct Node{ElemType data;struct Node *next;// 指向结点的指针}Node;// 定义链表结点:包含数据域,指针域typedef struct Node *LinkList;// 定义链表头指针,是指向结点的指针?3.2 无头结点单链表初始化
因为没有头结点,所以初始化时,头指针就指向NULL,表示空链表。而想要在函数里修改头指针,就需要传入头指针的地址LinkList*。
无头结点单链表初始化算法思路如下:
1、如果传入的头指针地址无效,返回失败;2、否则,修改头指针指向NULL,*pList = NULL;C语言实现代码如下:
int ListInit(LinkList *pList){if(pList==NULL) // 判断参数有效性return -1;*pList = NULL;return 0;}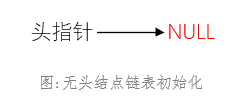
?3.3 无头结点单链表插入数据
无头结点单链表插入数据,如果插入位置是第一个结点时需要改变头指针的值;*pList = new;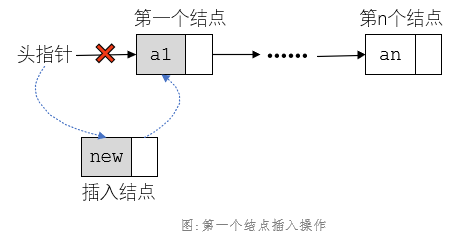
插入其他位置数据时,也是按照 新结点先连接下个结点、前个结点再连接新结点 顺序:new->next = cur->next;、cur->next = new;;
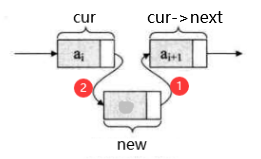
注意:如果这两个顺序反了,先执行cur->next = new;,会导致cur后面的数据全部都丢了,因为cur->next原本是保存着后继元素的地址的,现在直接被覆盖后,就无法继续查找后继元素了。
无头结点单链表在第n个位置插入数据的算法思路:
1、定义一个结点指针cur指向头结点,用来遍历链表;2、定义一个变量cur_i,用来表示当前结点的序号,初始化为1(头指针指向的就是第一结点);3、如果插入第一个位置3.1、分配内存空间给新结点,然后填好数值域;3.2、将头指针指向的位置cur赋值給新结点,new->next = cur;3.3、改变头指针的值,指向新结点,*pList = new;,返回成功。4、插入其他位置,将cur指针后移,直到插入位置n的前一个位置,即当cur_i==(n-1)跳出循环;5、若结束循环后,cur为无效结点,说明循环到最后一个结点时,链表长度不够;6、否则,说明当前结点cur的下个位置就是插入位置n,分配存储空间给新结点new;7、把值填进新节点的数据域,用新结点指向当前节点的下个节点;8、将当前节点指向新节点,完成插入操作。C语言实现代码如下,因为需要修改头指针的值,这里传入头指针的地址LinkList*:
int ListInsert(LinkList *pList, int data, int n)// 将node插入到第n位,n从1开始{if(pList==NULL || n<1) // 判断参数有效性return -1;ListNode* cur = *pList;// cur指向当前结点,初始化指向第一个结点int cur_i=1;// i表示当前结点的序号if(n==1)// 插入到第一位置,需要改变头指针指向新结点{ListNode* new = (ListNode*)malloc(sizeof(ListNode));new->data = data;new->next = cur;*pList = new;return 0;}while(cur && cur_i<(n-1))// 当前结点有效,且不是插入位置的前一个结点,就后移一个{cur = cur->next;cur_i++;}if(!cur)// 当前结点无效,说明已经移动到最后{printf("[%s %d]error din't have No.%d\n", __FUNCTION__,__LINE__, n);return -1;// 链表没有 n 那么长}ListNode* new = (ListNode*)malloc(sizeof(ListNode));new->data = data;new->next = cur->next;cur->next = new;return 0;}?3.4 无头结点单链表删除数据
无头结点单链表删除数据,如果删除位置是第一个结点时需要改变头指针的值,指向第二个结点,也就是list->next;
如果删除其他位置,也是“把当前结点的指针指向下个结点的下一个结点”,因为需要修改头指针的值,这里传入头指针的地址LinkList*。;
单链表删除第n个数据的算法思路:
1、定义一个结点指针cur指向头结点,用来遍历链表;2、定义一个变量cur_i,表示当前结点的序号,初始化为1(头指针指向的就是第一结点);3、如果删除第一个位置3.1、如果当前是空链表,返回失败;3.2、将头指针指向第二个结点(list->next),前面用*pList给cur赋值了,第二个结点为cur->next;3.3、释放第一个结点的内存空间,free(cur);4、删除其他位置,若当下个结点有效,就后移到删除位置n的前个位置,即cur_i==(n-1)时跳出循环;5、若结束循环后,下个结点(cur->next)为无效结点,说明循环到最后一个结点了,链表长度不够;5、否则,说明下个结点(cur->next)就是删除位置n的结点delete,赋值delete = cur->next;6、将当前结点的指针域指向delete的下个结点,cur->next=delete->next;7、最后释放delete结点的内存,完成删除操作。C语言实现代码如下,删除结点更关注的是下个结点(cur->next)的有效性:
// 删除第n个结点,且将删除的值通过data传出int ListDelete(LinkList *pList, int *data, int n){if(pList==NULL || data==NULL || n<1)return -1;ListNode* cur = *pList;// cur指向当前结点,初始化指向第一个结点int cur_i=1;// i表示当前结点的序号if(n==1)// 删除第一结点,需要改变头指针指向下个结点{if(cur == NULL){printf("[%s %d]error din't have No.%d\n", __FUNCTION__,__LINE__, n);return -1;}*pList = cur->next;free(cur);return 0;}while(cur->next && cur_i<(n-1)){// 下个结点有效,且当前位置不是删除位置的前一个,就后移一个cur = cur->next;cur_i++;}if(!cur->next)// 下个结点无效,说明已经移动到最后{printf("[%s %d]error din't have No.%d\n", __FUNCTION__,__LINE__, n);return -1;// 链表没有 n 那么长}ListNode *delete = cur->next;cur->next = delete->next;free(delete);return 0;}?3.5 无头结点单链表查找数据
无头结点单链表查找和 带头结点单链表查找的实现思路基本是一样的,都是从第一个结点不断往后找。因为不需要修改头指针的值,这里传入头指针LinkList。
无头结点单链表查找第n个数据的算法思路:
1、定义一个结点指针cur指向第一个结点,用来遍历链表;2、定义一个变量cur_i,用来表示当前结点的序号,初始化为1(第一步指向的就是第一个结点);3、当前个结点(cur)有效,且当前位置不是查找位置n,就继续后移,直到无效或i==n跳出循环;4、若结束循环后,当前结点(cur)为无效结点,说明循环到最后一个结点了,链表长度不够;5、否则,说明当前结点(cur)就是查找位置n的结点;返回结点数据*data = cur->data。C语言实现代码如下:
int ListFind(LinkList list, int *data, int n){if(list==NULL || data==NULL || n<1)return -1;ListNode* cur = list;// 指向第一个节点int cur_i=1;// i表示当前结点的序号while(cur && cur_i<n)// 当前结点有效,且当前位置不是查找位置n,就往后移动一个{cur = cur->next;cur_i++;}if(!cur)// 当前结点无效,说明已经移动到最后{printf("[%s %d]error din't have No.%d\n", __FUNCTION__,__LINE__, n);return -1;// 链表没有 n 那么长}*data = cur->data;printf("[%s %d]find No.%d = %d\n", __FUNCTION__,__LINE__, n,*data);return 0;}?3.6 无头结点单链表的销毁
无头结点单链表销毁和 带头结点单链表销毁的实现思路基本是一样的,都是从第一个结点不断往后删除。因为不需要修改头指针的值,这里传入头指针LinkList。
单链表销毁的算法思路:
1、定义一个结点指针cur指向第一个结点,用来遍历链表;2、定义一个结点指针next,保存下个结点地址;3、当前个结点(cur)有效,进入循环:3.1、先保存下个结点地址,因为下个结点本来保存在cur->next,直接free(cur)会丢掉下个结点;3.2、删除当前结点,释放内存3.3、将当前指针指向前面保存好的下个结点。4、结束循环后,已经删除完所有节点,此时需要将头指针指向NULL,表示空链表。C语言实现代码如下:
void ListDestroy(LinkList *pList){ListNode* cur = *pList;// 指向第一个节点ListNode* next = NULL;// 用于保存下个结点地址while(cur)// 当前结点有效,就往后移动{next = cur->next;// 保存下个结点地址//printf("[%s %d]delete %d\n", __FUNCTION__,__LINE__, cur->data);free(cur);// 删除当前结点、并释放内存cur = next;// 将当前结点指针指向下个结点}*pList = NULL;}
四、 无头结点单链表完整代码
下面是无头结点的单链表完整代码,已经在Ubuntu下编译通过,并使用了,复制代码保存为LinkListNoHeadNode.c,然后再Ubuntu命令行执行gcc LinkListNoHeadNode.c -o LinkListNoHeadNode去编译。
#include <stdio.h>#include <stdlib.h>typedef struct _ListNode{int data;struct _ListNode *next;}ListNode;typedef ListNode* LinkList;int ListInit(LinkList *pList){if(pList==NULL) // 判断参数有效性return -1;*pList = NULL;return 0;}int ListInsert(LinkList *pList, int data, int n)// 将node插入到第n位,n从1开始{if(pList==NULL || n<1) // 判断参数有效性return -1;ListNode* cur = *pList;// cur指向当前结点,初始化指向第一个结点int cur_i=1;// i表示当前结点的序号if(n==1)// 插入到第一位置,需要改变头指针指向新结点{ListNode* new = (ListNode*)malloc(sizeof(ListNode));new->data = data;new->next = cur;*pList = new;return 0;}while(cur && cur_i<(n-1))// 当前结点有效,且不是插入位置的前一个结点,就后移一个{cur = cur->next;cur_i++;}if(!cur)// 当前结点无效,说明已经移动到最后{printf("[%s %d]error din't have No.%d\n", __FUNCTION__,__LINE__, n);return -1;// 链表没有 n 那么长}ListNode* new = (ListNode*)malloc(sizeof(ListNode));new->data = data;new->next = cur->next;cur->next = new;return 0;}// 删除第n个结点,且将删除的值通过data传出int ListDelete(LinkList *pList, int *data, int n){if(pList==NULL || data==NULL || n<1)return -1;ListNode* cur = *pList;// cur指向当前结点,初始化指向第一个结点int cur_i=1;// i表示当前结点的序号if(n==1)// 删除第一结点,需要改变头指针指向下个结点{if(cur == NULL){printf("[%s %d]error din't have No.%d\n", __FUNCTION__,__LINE__, n);return -1;}*pList = cur->next;free(cur);return 0;}while(cur->next && cur_i<(n-1)){// 下个结点有效,且当前位置不是删除位置的前一个,就后移一个cur = cur->next;cur_i++;}if(!cur->next)// 下个结点无效,说明已经移动到最后{printf("[%s %d]error din't have No.%d\n", __FUNCTION__,__LINE__, n);return -1;// 链表没有 n 那么长}ListNode *delete = cur->next;cur->next = delete->next;free(delete);return 0;}int ListFind(LinkList list, int *data, int n){if(list==NULL || data==NULL || n<1)return -1;ListNode* cur = list;// 指向第一个节点int cur_i=1;// i表示当前结点的序号while(cur && cur_i<n)// 当前结点有效,且当前位置不是查找位置n,就往后移动一个{cur = cur->next;cur_i++;}if(!cur)// 当前结点无效,说明已经移动到最后{printf("[%s %d]error din't have No.%d\n", __FUNCTION__,__LINE__, n);return -1;// 链表没有 n 那么长}*data = cur->data;printf("[%s %d]find No.%d = %d\n", __FUNCTION__,__LINE__, n,*data);return 0;}void ListDestroy(LinkList *pList){ListNode* cur = *pList;// 指向第一个节点ListNode* next = NULL;// 用于保存下个结点地址while(cur)// 当前结点有效,就往后移动{next = cur->next;// 保存下个结点地址//printf("[%s %d]delete %d\n", __FUNCTION__,__LINE__, cur->data);free(cur);// 删除当前结点、并释放内存cur = next;// 将当前结点指针指向下个结点}*pList = NULL;}void ListPrintf(LinkList list){ListNode* cur = list;// 指向第一个节点printf("list:[");while(cur){printf("%d,",cur->data);cur = cur->next;}printf("]\n");}int main(){LinkList list;ListInit(&list);int data=0;printf("Linklist is empty !!! \n");ListInsert(&list, 2, 2);// 空链表时,验证插入ListDelete(&list, &data, 1);// 空链表时,验证删除ListFind(list, &data, 1);// 空链表时,验证查询ListDestroy(&list);// 空链表时,验证销毁printf("\ninsert 3 data\n");// 正常插入3个数据ListInsert(&list, 1, 1);ListInsert(&list, 2, 2);ListInsert(&list, 3, 3);ListPrintf(list);printf("\n验证错误值\n");ListInsert(&list, 5, 5);// 验证插入ListDelete(&list, &data, 4);// 验证删除ListFind(list, &data, 4);// 验证查询printf("\n正常操作\n");// 正常操作ListFind(list, &data, 2);printf("delete 2,now\n");ListDelete(&list, &data, 2);ListPrintf(list);printf("Insert 4 to 2,now\n");ListInsert(&list, 4, 2);ListPrintf(list);printf("Destroy ,now\n");ListDestroy(&list);ListPrintf(list);return 0;}
五、 有头结点单链表完整代码
下面是带头结点的单链表完整代码,已经在Ubuntu下编译通过,并使用了,复制代码保存为LinkListHaveHeadNode.c,然后再Ubuntu命令行执行gcc LinkListHaveHeadNode.c -o LinkListHaveHeadNode去编译。
#include <stdio.h>#include <stdlib.h>typedef struct _ListNode{int data;struct _ListNode *next;}ListNode;typedef ListNode* LinkList;LinkList ListInit(){LinkList list = (LinkList)malloc(sizeof(ListNode));list->next = NULL;list->data = -1;return list;}int ListInsert(LinkList list, int data, int n)// 将node插入到第n位,n从1开始{if(list==NULL || n<1) // 判断参数有效性return -1;ListNode* cur = list;// cur指向当前结点,初始化指向头结点int cur_i=0;// i表示当前结点的序号,0-头结点while(cur && cur_i<(n-1))// 当前结点有效,且不是插入位置的前一个结点,就后移一个{cur = cur->next;cur_i++;}if(!cur)// 当前结点无效,说明已经移动到最后{printf("[%s %d]error din't have No.%d\n", __FUNCTION__,__LINE__, n);return -1;// 链表没有 n 那么长}ListNode* new = (ListNode*)malloc(sizeof(ListNode));new->data = data;new->next = cur->next;cur->next = new;return 0;}// 删除第n个结点,且将删除的值通过data传出int ListDelete(LinkList list, int *data, int n){if(list==NULL || data==NULL || n<1)return -1;ListNode* cur = list;// cur指向当前结点,初始化指向头结点int cur_i=0;// i表示当前结点的序号,0-头结点while(cur->next && cur_i<(n-1)){// 下个结点有效,且当前位置不是删除位置的前一个,就后移一个cur = cur->next;cur_i++;}if(!cur->next)// 下个结点无效,说明已经移动到最后{printf("[%s %d]error din't have No.%d\n", __FUNCTION__,__LINE__, n);return -1;// 链表没有 n 那么长}ListNode *delete = cur->next;cur->next = delete->next;free(delete);return 0;}int ListFind(LinkList list, int *data, int n){if(list==NULL || data==NULL || n<1)return -1;ListNode* cur = list->next;// 指向第一个节点int cur_i=1;// i表示当前结点的序号while(cur && cur_i<n)// 当前结点有效,且当前位置不是查找位置n,就往后移动一个{cur = cur->next;cur_i++;}if(!cur)// 当前结点无效,说明已经移动到最后{printf("[%s %d]error din't have No.%d\n", __FUNCTION__,__LINE__, n);return -1;// 链表没有 n 那么长}*data = cur->data;printf("[%s %d]find No.%d = %d\n", __FUNCTION__,__LINE__, n,*data);return 0;}void ListDestroy(LinkList list){ListNode* cur = list->next;// 指向第一个节点ListNode* next = NULL;// 用于保存下个结点地址while(cur)// 当前结点有效,就往后移动{next = cur->next;// 保存下个结点地址//printf("[%s %d]delete %d\n", __FUNCTION__,__LINE__, cur->data);free(cur);// 删除当前结点、并释放内存cur = next;// 将当前结点指针指向下个结点}list->next = NULL;}void ListPrintf(LinkList list){ListNode* cur = list->next;// 指向第一个节点printf("list:[");while(cur){printf("%d,",cur->data);cur = cur->next;}printf("]\n");}int main(){LinkList list=ListInit();int data=0;printf("Linklist is empty !!! \n");ListInsert(list, 2, 2);// 空链表时,验证插入ListDelete(list, &data, 1);// 空链表时,验证删除ListFind(list, &data, 1);// 空链表时,验证查询ListDestroy(list);// 空链表时,验证销毁printf("\ninsert 3 data\n");// 正常插入3个数据ListInsert(list, 1, 1);ListInsert(list, 2, 2);ListInsert(list, 3, 3);ListPrintf(list);printf("\n验证错误值\n");ListInsert(list, 5, 5);// 验证插入ListDelete(list, &data, 4);// 验证删除ListFind(list, &data, 4);// 验证查询printf("\n正常操作\n");// 正常操作ListFind(list, &data, 2);printf("delete 2,now\n");ListDelete(list, &data, 2);ListPrintf(list);printf("Insert 4 to 2,now\n");ListInsert(list, 4, 2);ListPrintf(list);printf("Destroy ,now\n");ListDestroy(list);ListPrintf(list);return 0;}总结:
文章先介绍 “头结点” 在链表的作用,以及 “有头结点” 和 “无头结点” 的区别,然后再详细介绍了“无头结点链表” 的实现步骤,最后给出了 “无头结点单链表” 的C语言实现代码,同时也给出了 “有头结点单链表” 的C语言实现代码。读者可以对比这两份代码,将会对单链表的“头结点”有非常深刻的理解。
如果文章有用的话,麻烦点赞?、收藏⭐一波!!! ???