

文章目录
一、前言二、宏的优缺点分析1、概念回顾2、宏的缺点3、宏的优点 三、inline内联函数1、概念2、特性①:空间换时间?趣味杂谈:庞大的游戏更新包3、特性②:inline实现机制4、特性③:inline的声明与定义反汇编观察函数调用的流程内联函数的生成机制【⭐】 四、总结与提炼
一、前言
本文我们聊一聊一下宏和内联函数之间的关系。
在预处理章节,我们重点介绍了什么是宏,以及宏和函数之间的区别,还记得下面这张图吗,我们对宏和函数之间做了一个很细致的分析?那在本文中,我们来说的就不是普通的函数了,它叫做【内联函数】,是C++里面独有的,由inline关键字进行修饰,具体怎样,敬请看下去吧? 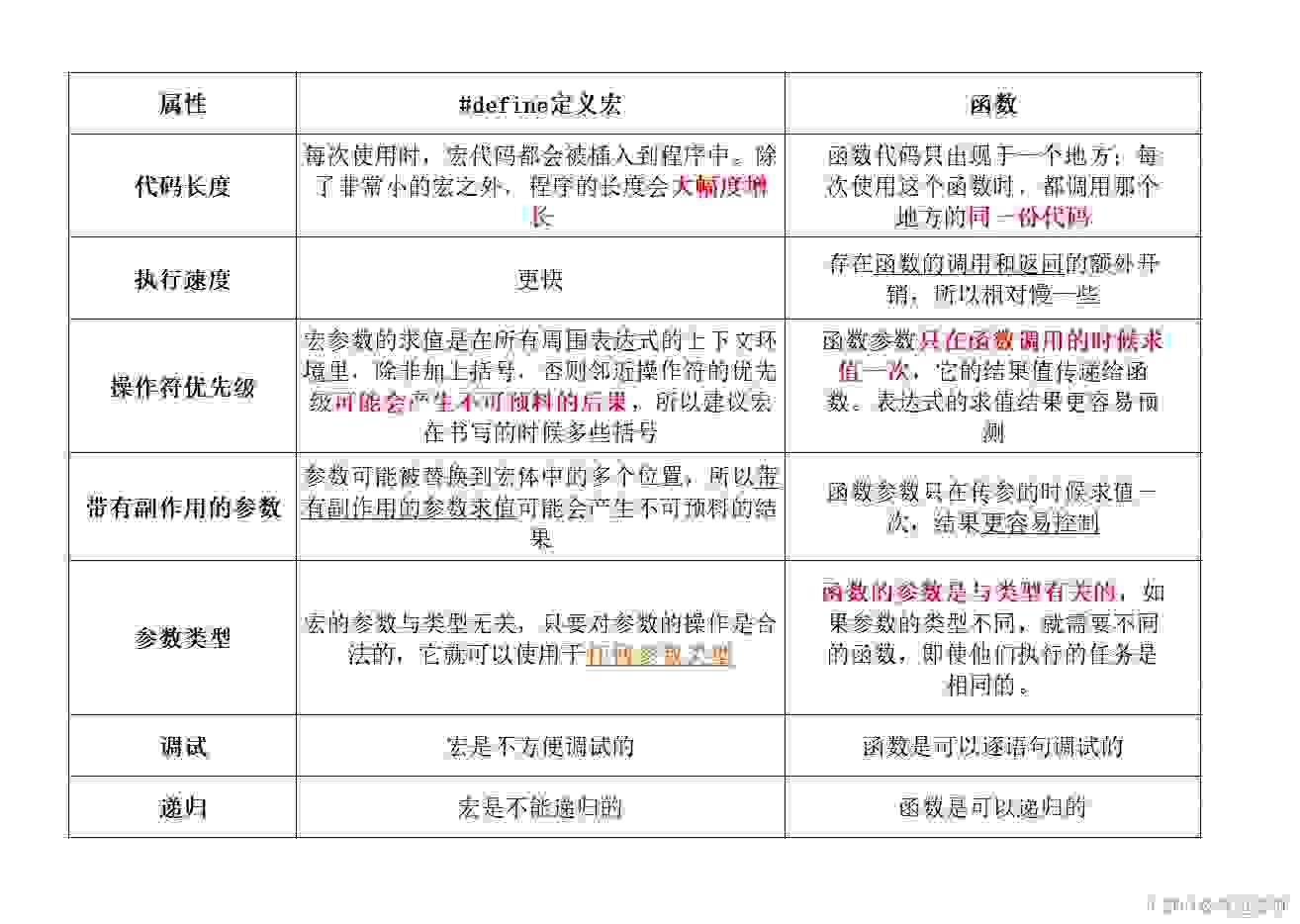
二、宏的优缺点分析
在将内联函数之间前,我们再来聊聊有关宏的一些内容
1、概念回顾
下面是宏的申明方式:
#define name( parament-list ) stuff//其中的 parament-list 是一个由逗号隔开的符号表,它们可能出现在stuff中注:① 参数列表的左括号必须与name紧邻,如果两者之间有任何空白存在,参数列表就会被解释为stuff的一部分。
在学习了C语言后,如果我不带你去回顾这一些,那你是否能立马写出一个宏来呢,例如:写一个用于求和的宏函数那我相信对于很多同学来说都会措手不及,答案会像是下面这样千奇百怪?//1.#define Add(int x, int y)return x + y;//2.#define ADD(x, y) x + y//3.#define ADD(x, y) (x + y)//4.#define ADD(x, y) ((x) + (y));//5.#define ADD(x, y) ((x) + (y))后面四个的主要区别就在于后面的stuff,我们一一来分析一下
int ret = ADD(1, 2);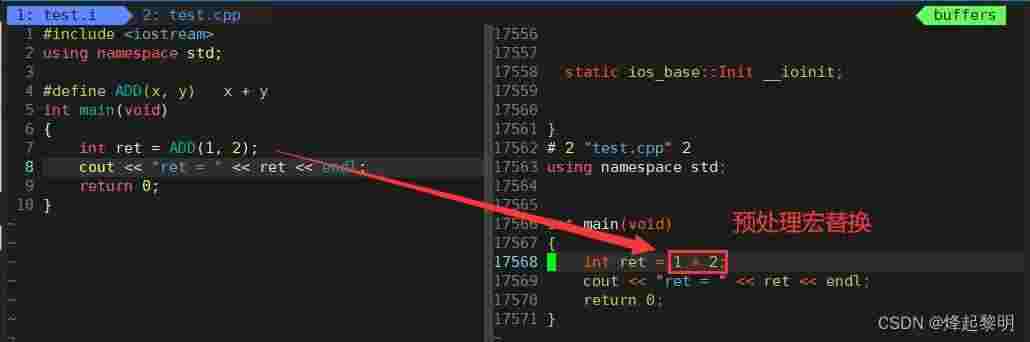
int ret = ADD(1, 2) * 3;*的优先级来得高,所以2会和后面的3先进行一个运算,这也就造成了最后结果的不同 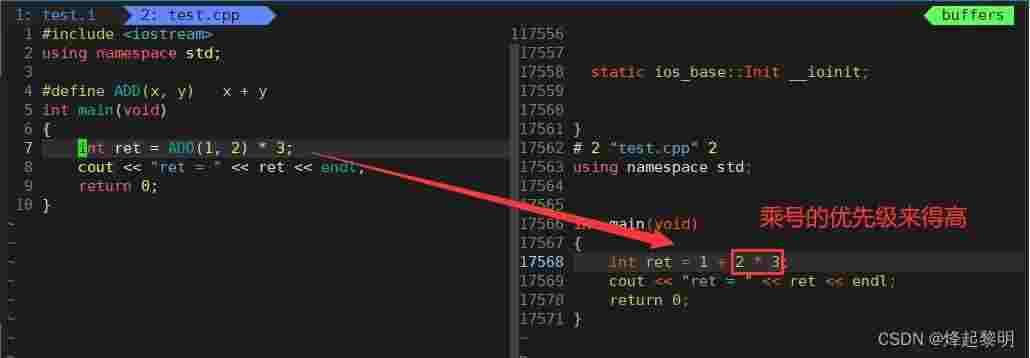
所以我们应该要像下面这样,在外层加上一个大括号,防止出现优先级的问题
#define ADD(x, y) (x + y)int a = 10; int b = 20;int ret = ADD(a | b, a & b);+号来说,它的优先级高于&按位与和|按位或的,如果不清楚优先的话可以看看操作符汇总大全所以中间的【b】和【a】会先进行结合,然后再去算&和| 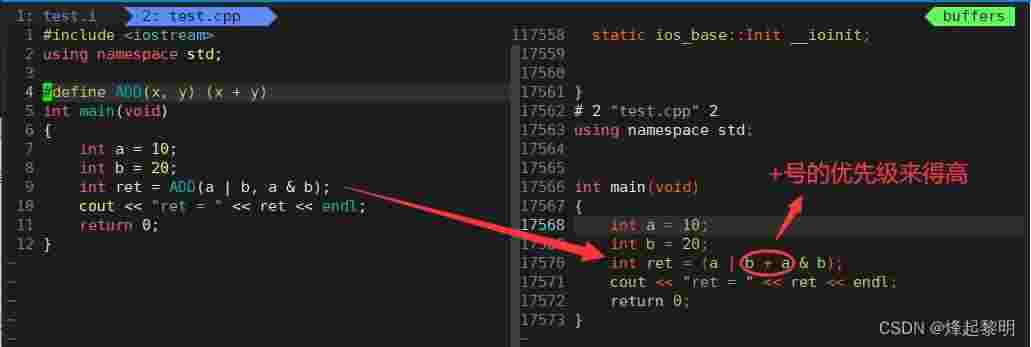
(),这样就不会出现问题了 #define ADD(x, y) ((x) + (y));;号,对于分号来说是我们在写代码的时候作为一条语句结束的标志,但是对于宏来说也可以写分号吗?将原先的传参继续替换成下面这样来试试 int ret = ADD(1, 2) * 3;;号,但是分号后面还有3要乘,这个时候其实就不对了,所以宏定义后是不可以加分号的 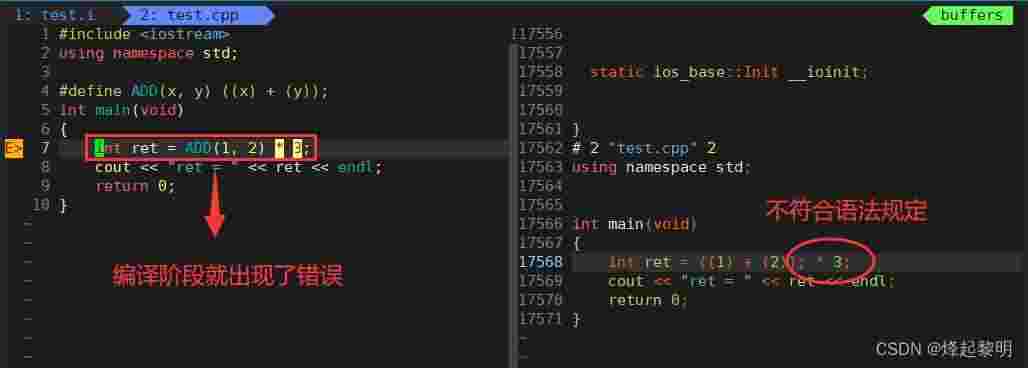
#define ADD(x, y) ((x) + (y))//✔2、宏的缺点
看了上面有关【宏】概念的一些回顾,我们来聊聊它的缺点所在
① 宏可能会带来运算符优先级的问题,导致程容易出现错。【加括号太麻烦了!!!】
这一点相信你在看了上一小节的叙述之后一定是感同身受,只是完成一个两数相加的功能,就需要加上这么多括号了,若是再复杂一些的功能,那岂不是要加很多了?② 宏是不能调试的【这点比较致命?】
可以观察到,无论是在哪个平台下,对于宏来说都是无法调试的Windows环境下VS
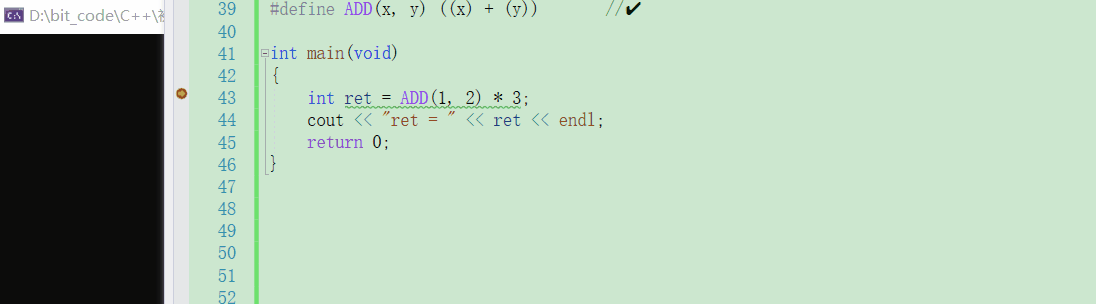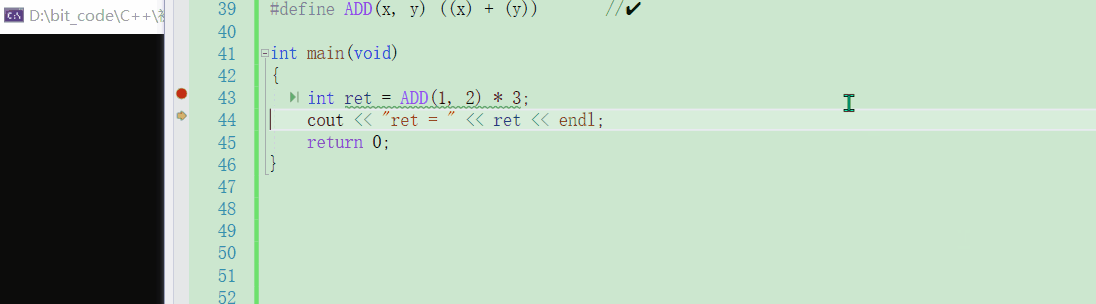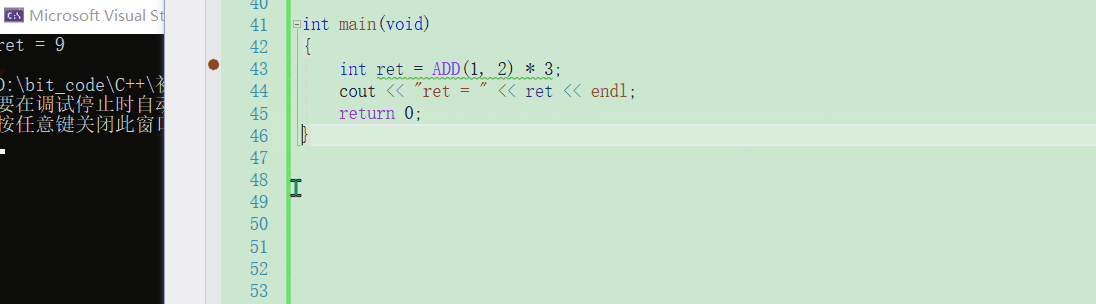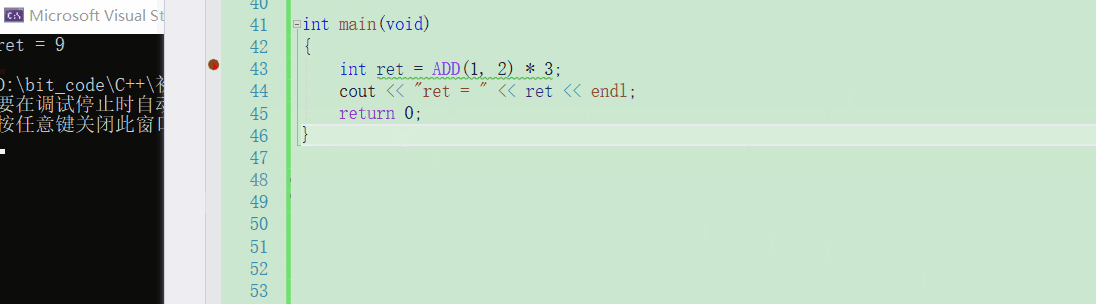
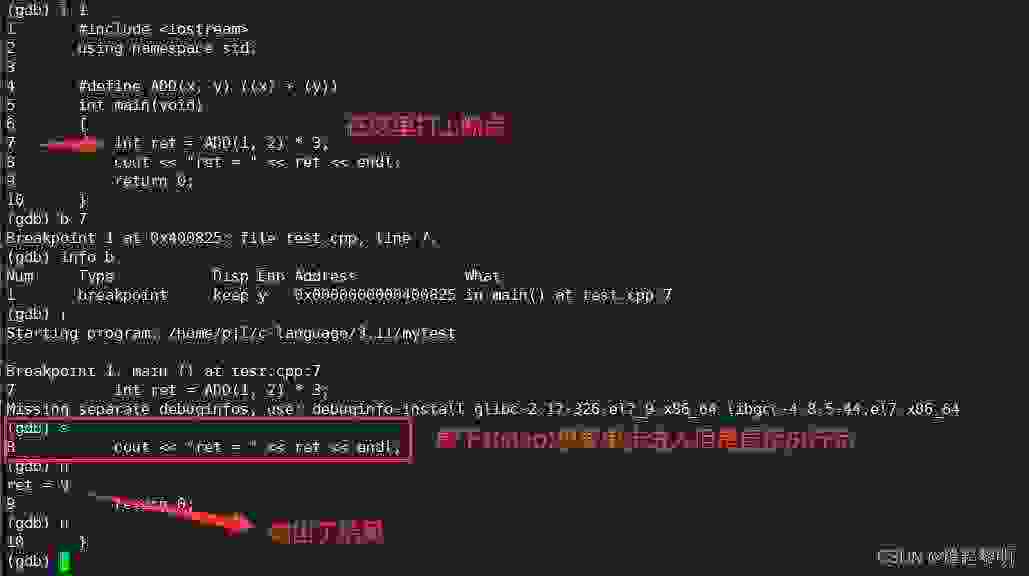
Linux环境下gdb
③ 没有类型安全的检查【直接替换】
可以看到,无论我传入何种类型的参数,都不会出现问题。这点其实说明了宏对于类型的检查是不严谨的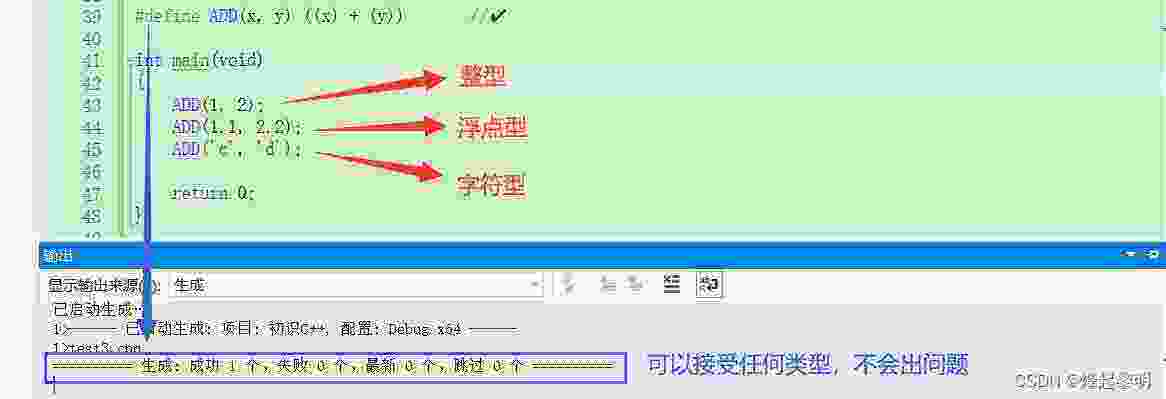
④ 有些场景下非常复杂,容易出错,不容易掌握
之前我有写过一篇文章叫做使用宏将一个整数的二进制位的奇数位和偶数位交换。为了实现这个功能我写了一个这样的宏函数#define SWAP(n) num = (((n & 0xaaaaaaaa) >> 1) | ((n & 0x55555555) << 1))3、宏的优点
了解了宏的缺点之后,我们再来瞧瞧它的优点,既然在一些场景被广泛使用,那一定也具有它的优点?
① 宏常量提高复用性和可维护性
#define n 500② 宏函数类型不固定,int、double、float都可以用
③ 宏函数不用建立栈帧,因此不会产生消耗
好,以上就是本文所要讲的有关【宏】相关的所有内容,希望能唤起读者对这个知识点的回忆
三、inline内联函数
接下去我们就正式来讲讲C++中的独有的【内联函数】
1、概念
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数提升程序运行的效率
inline int Add(int x, int y){int z = x + y;return z;}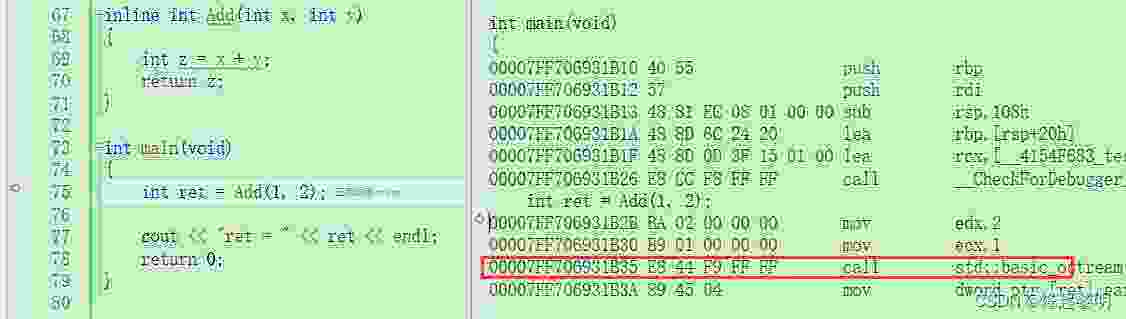
call指令吗,哪来的不调用一说呢?因为我们还需要去做一些配置? 
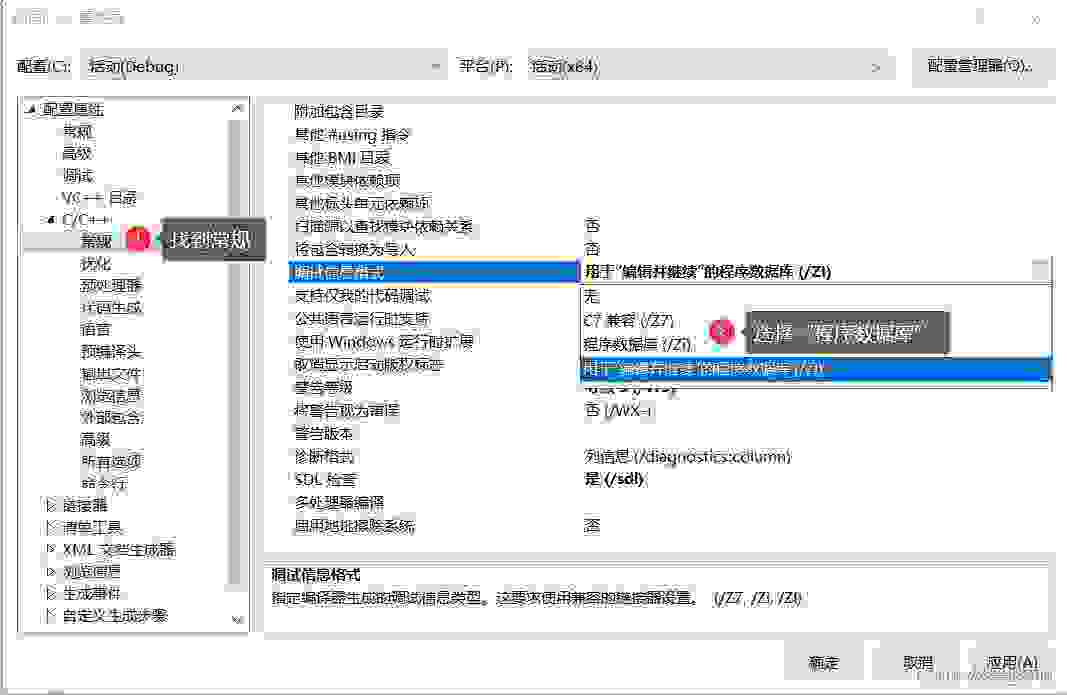
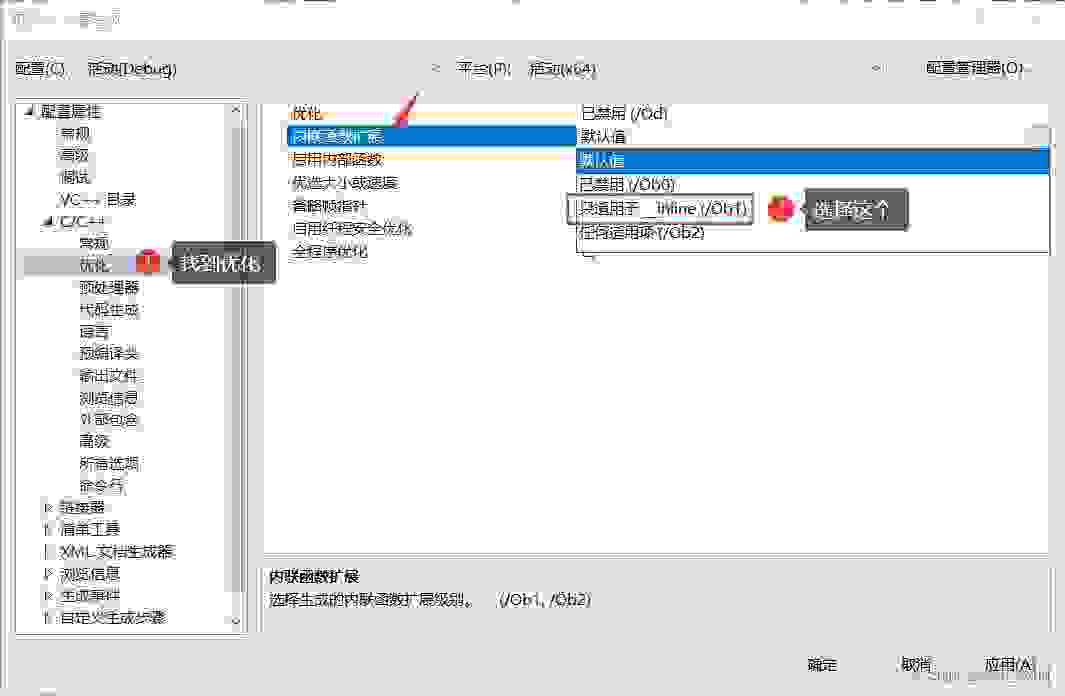
call指令了,编译器直接将内敛函数Add做了展开 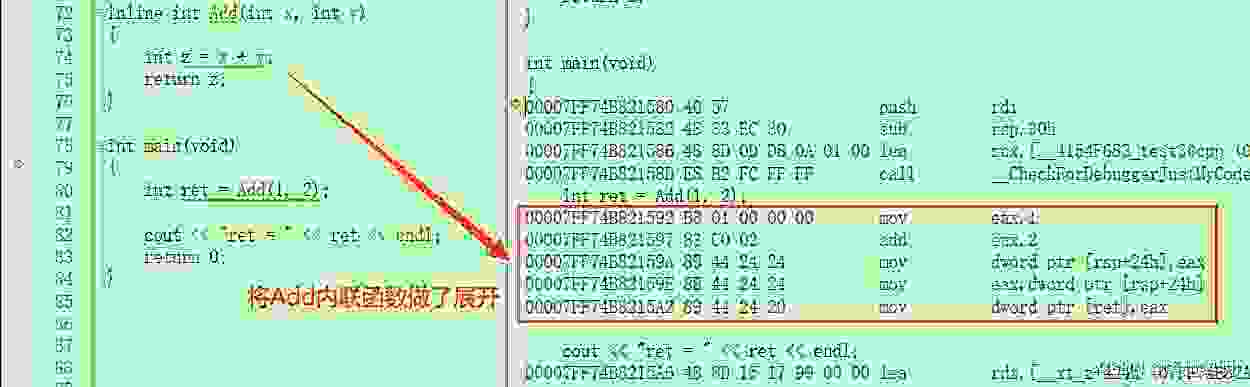
inline关键字,就可以起到这种效果。非但如此,它还可以调试? 接下去我们再来介绍一下有关内敛函数的一些特性
2、特性①:空间换时间
有同学可能不是很理解空间换时间是什么意思,可以看看时空复杂度章节。不过要说明的一点是这里的空间不是内存,是编译后的程序,而【空间换时间】就会使得编译出来的可执行程序会变大
对于这种空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用 【缺陷】:可能会使目标文件变大;【优势】:少了调用开销,提高程序运行效率; 可以通过下面这幅图来看看:此时程序中有一个swap()函数,内部有10行代码。在程序的1000个地方都会对其进行调用,那请问此时去使用内联函数和不使用内联函数的区别是什么? 当不使用内联函数时,就是将这个swap()函数当做普通的函数的话,我们知道在底层会进行一个call指令再通过jump指令跳转到这个函数所在地址然后执行这个函数,那每一个调用的地方都要跳转的话,就会跳转1000次,所以swap + 调用swap指令,合计是1000 + 10条指令当使用内联函数时,通过上面的学习可以知道,它不会去进行一个函数的调用,而是直接将相关的指令拷贝到程序中调用这个swap()函数的每一块地方,所以swap + 调用swap指令,合计是1000 * 10条指令 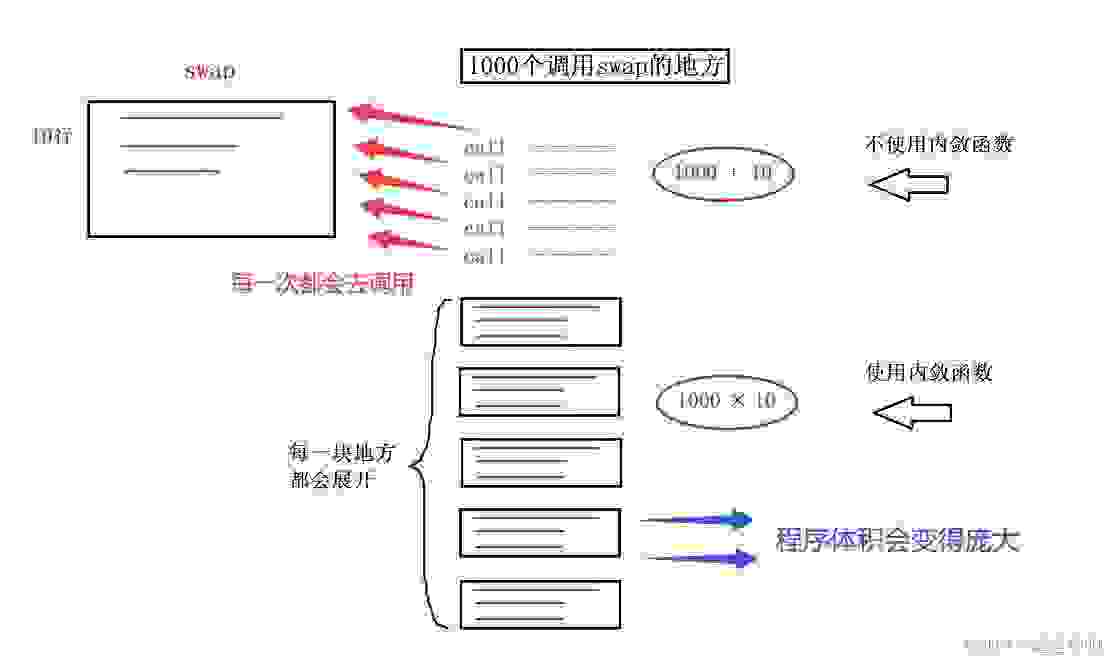
?趣味杂谈:庞大的游戏更新包
在理解了一个函数设不设置内联函数的区别的时候,顺带来谈一谈这个目标文件体积变大的缘故
要知道,干我们这一行基本一年到头都是在公司,也有逢年过节才能回家一趟,而且平常工作忙得也没有时间玩游戏,那此刻当你过年回家的时候,就看到家里的一些弟弟妹妹拿着手机?在打《王者荣耀》,这相信是最正常不过了那此时呢,你也心里痒痒,打开了你尘封已久的王者荣耀,然后看到要更新,而且一看就是4、5个G,突然之间就不想玩了?更新的过程中只能眼巴巴地看着别人玩,不过呢,你有个同事,也是很久都没有玩过游戏了,也是一样进去更新,但是呢她却3、5分钟更新好了,因为更新包只有3、500M。这是为什么呢?原来她是苹果手机,系统是IOS系统,其实对于更新的这些内容都是指令,只是你们的指令数目不同而已。那我们都知道【苹果】这家公司系统是自己设计的,而且对于像芯片、硬件、软件各方面都领先于同行所以说这个性能不一样就会手机系统上使用的软件也存在差异。别人这个性能好,在优化各种方面都齐全,所以就不会导致这个更新包越变越大,相反对比我们平常使用的几千元的安卓手机,却越用越卡,这也是很多人选择使用苹果手机的原因? 
3、特性②:inline实现机制
好,小插曲,我们回归正题,继续来讲讲内联函数的第二大特性 —— 【inline实现机制】
inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同一般建议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性《C++prime》第五版关于inline的建议:

我们可以到VS中来观察一下
call指令,而不是将其函数中的内容直接拷贝到程序调用处,即使是加了这个inline关键字,似乎还是起不到内联函数的作用,这是为什么呢? 因为编译器在对于这个内联请求的时候发觉不对劲,所以选择忽略了这个请求,而不是像宏那样无论怎样都会傻傻地进行替换 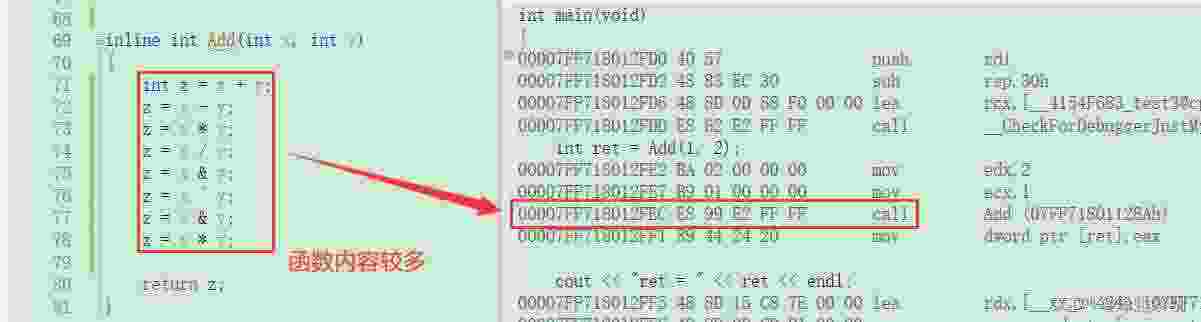
1000 + 1000条指令如果采用内联将其展开的话消耗的就是1000 * 1000条指令,这就很恐怖了? 那上面这个还是个普通的大一点的函数,但你再想如果是**··**呢?层层地往下调用再一层层地返回来,那需要调用的指令就更多了,如果全部站开的话,就会造成一个灾难性的后果⚠ 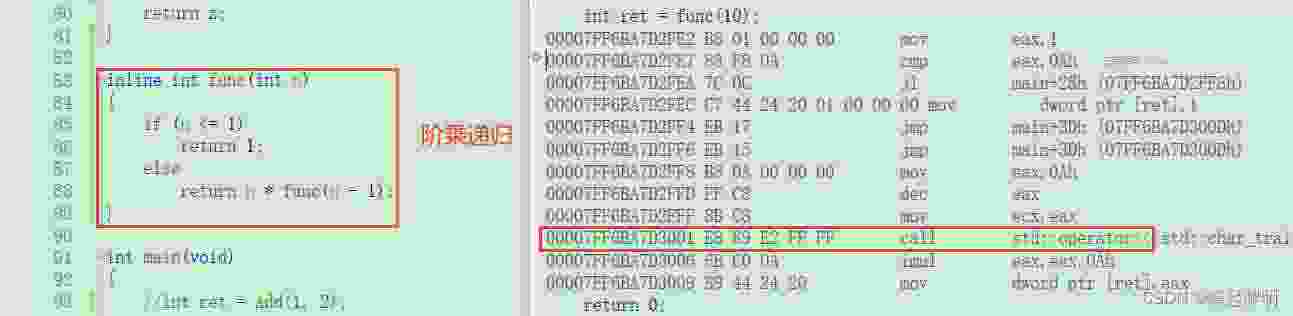
所以呢,加不加内敛是你的事,最终要不要把它真的展开变成内敛编译器说了算,所以我们在使用的时候一般是比较短小、调用频繁的函数(10几行以内)加上内联,其他就不加了
4、特性③:inline的声明与定义
inline内联函数的第三个特性,就是我们要注意内联函数的定义和声明不可以分开,导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到
// F.h#include <iostream>using namespace std;inline void f(int i);//--------------------------// F.cpp#include "F.h"void f(int i){cout << i << endl;}//--------------------------// main.cpp#include "F.h"int main(){f(10);return 0;}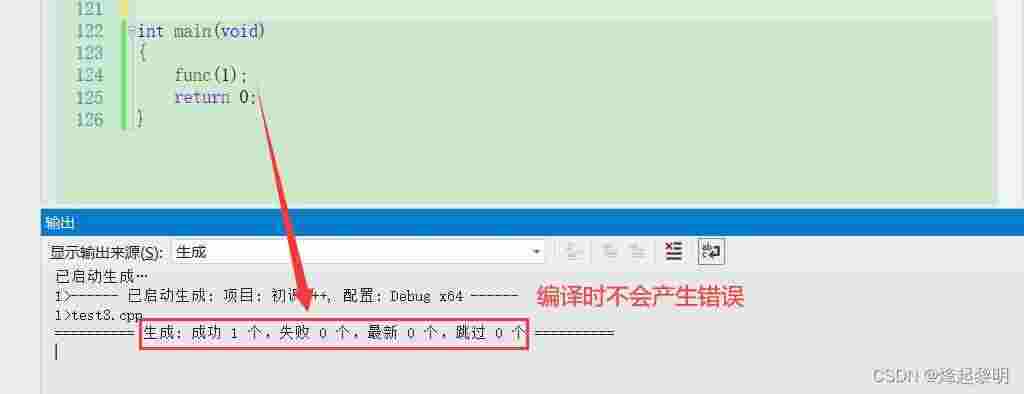
? 这种错误一般都是最后链接目标文件的时候除了问题,不是很清楚的可以看看程序的编译和链接
? 对于这些很复杂的符号func@@YAXH@Z,是C++中的函数名修饰,可以看看探究函数重载的原理:函数名修饰
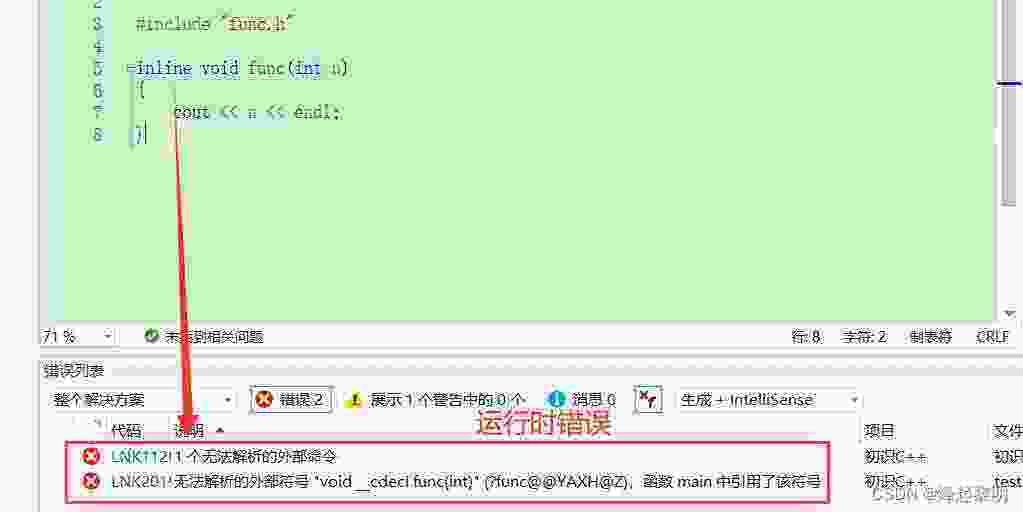
那我们现在就要去思考,为什么会出现这种【运行时错误】呢?
反汇编观察函数调用的流程
对于内联函数来说是这样,但是普通函数来说是怎么一步步地进行调用的呢?我们可以通过汇编来看看?
对于函数的地址来说,在指针章节我们有说过,它值得就是【函数指针】,但是从汇编角度来看,它call的到底是谁的地址呢? 
F11跳转到了一条叫做【jmp】的指令,此时你去观察这个地址,其实就是这条【jmp】的地址,在英语中jump是跳的意思,那你可以将这条指令理解为一个中转站,call指令会暂时跳到这条指令所在的地址,然后再通过这条指令去找需要调用函数的地址 
F10的话就会通过这个函数的地址找到这个函数,此时就开始执行函数内部的逻辑, 
call指令的下一条指令,这就算是一次函数调用的过程 
可以将它们放到一起来观察,就可以发现它们之间的逻辑非常紧密
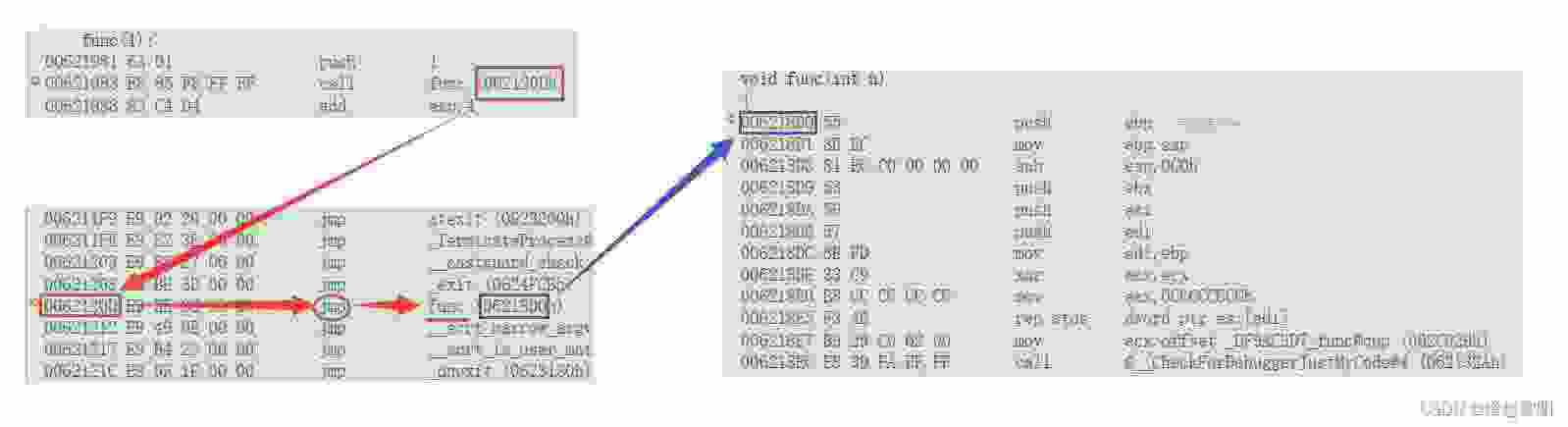
如果对上面过程还是不太理解的可以看看反汇编深挖【函数栈帧】的创建和销毁
内联函数的生成机制【⭐】
上面是对于普通函数的调用机制,那对于内联函数呢?也是这么去跳转吗?
一定要注意!内联内联,那么这个函数的内容就直接放到调用的地方 它便说:也就是我不需要你再通过这么繁琐的步骤一步步地跳转过来了,我会将内部的东西做一些优化,直接放到你那里,你执行这些指令即可可是呢,为什么会出现链接错误❌
因为在【预编译】的时候就要展开func.h这个头文件,但是在主调用接口中包含的头文件中只有函数的声明没有实现,此时只能在【链接】的时候展开了,但是在链接的时候因为只有声明所以只得到了函数名修饰后的地址。编译器便需要通过这个地址找到函数所在的位置,对于普通函数而言在这个时候就可以通过call找过去了,但是对于内联函数而言,却无法做到,因为它并没有【call】和【jmp】这些指令,因此就造成了链接错误的现象 那要如何去解决呢?
若是这个函数要定义成内联函数的话,就不要将定义和声明分开了,在头文件中定义出来后就直接对其进行声明,便不会造成这样的问题了// F.h#include <iostream>using namespace std;inline void f(int i){cout << i << endl;}//--------------------------// main.cpp#include "F.h"int main(){f(10);return 0;}四、总结与提炼
好,最后来总结一下本文所学习的内容?
首先我们回顾来一下C语言中所学习的【宏】,经过了对宏的优缺点分析以及一些同学的错误案例对照,在面试的时候让你写一个宏,可不要写错了哦!接下去,我们就正式地开始介绍内联函数,对于内联函数来说,它不仅保留了宏的优点,没有函数调用建立栈帧的开销,而且还修复了宏的缺点,将其做成一个函数的形式,简洁直观,而且便于调试观察,提升程序运行的效率但是对于内联函数来说,也是存在要注意的地方,因为它也是会和宏一样在调用的地方展开,不过会进行一定程度的优化,可这种空间换时间的思想只适用于小型的函数,对于大型的函数不建议定义成【内联函数】,会造成程序的过多臃肿但是在看了内联函数的生成机制后,其实我们也不用担心在误用内联函数后使得程序变大,它会有一个自动判断的机制,若是你程序的行数过多的话,编译器就会忽略你的这请求,对于我们要将一个函数声明为内联函数其实是在向编译器发起一个申请,它可以选择接收也可以选择拒绝?以上就是本文要介绍的所有内容,感谢您的阅读?
