目录
前言
一、准备工作
1、下载
1.下载yolov5源代码存放到桌面
2.下载anaconda用于配置环境
3.熟悉命令窗口简单指令
2、配置环境
3、测试环境是否正确配置
二、训练模型
1、标注图片
2、检查标签
3、更改运行文件
1.修改coco128.yaml
2.修改yolov5s.yaml
4、修改train.py
5、开始训练,运行mytrain.py
三、使用模型
1、调用摄像头
2、识别本地图片或者视频
3、识别网络摄像头或者流媒体
四、总结
五、找到我
前言
本人学的是机电自动化专业,但因为一些原因自学了yolov5。在半知半解的情况下,摸索着学习。
此文是我个人在学习yolov5的一些学习总结,可能有一些地方我还没有弄懂,所以本文如有错误,还请谅解,可以私信或者在评论里指出,万分感谢。
这是我学yolov5的看过的一些教程,也在此特别感谢各位大佬经验分享,没有你们的无偿分享,就没有今天的这份学习总结。
【一天搞定系列】垃圾分类设计!学不会up给你跪下!收藏不亏!_哔哩哔哩_bilibili
【Yolov5】1.认真总结6000字Yolov5保姆级教程_若oo尘的博客-CSDN博客_yolov5流程图
手把手教你使用YOLOV5训练自己的目标检测模型-口罩检测-视频教程_肆十二的博客-CSDN博客
YOLOv5训练自己的数据集(超详细完整版)_深度学习菜鸟的博客-CSDN博客_yolov5训练数据集
YOLOv5学习笔记_「已注销」的博客-CSDN博客
【深度学习】【YoloV5】单机多卡训练 多机多卡训练_XD742971636的博客-CSDN博客_yolov5 多卡训练
一、准备工作
1、下载
1.下载yolov5源代码存放到桌面
下载地址:GitHub - ultralytics/yolov5: YOLOv5 ? in PyTorch > ONNX > CoreML > TFLite
如果出现网络错误,使用 Steam++ 快速访问 Github_小飞飞¹²³的博客-CSDN博客
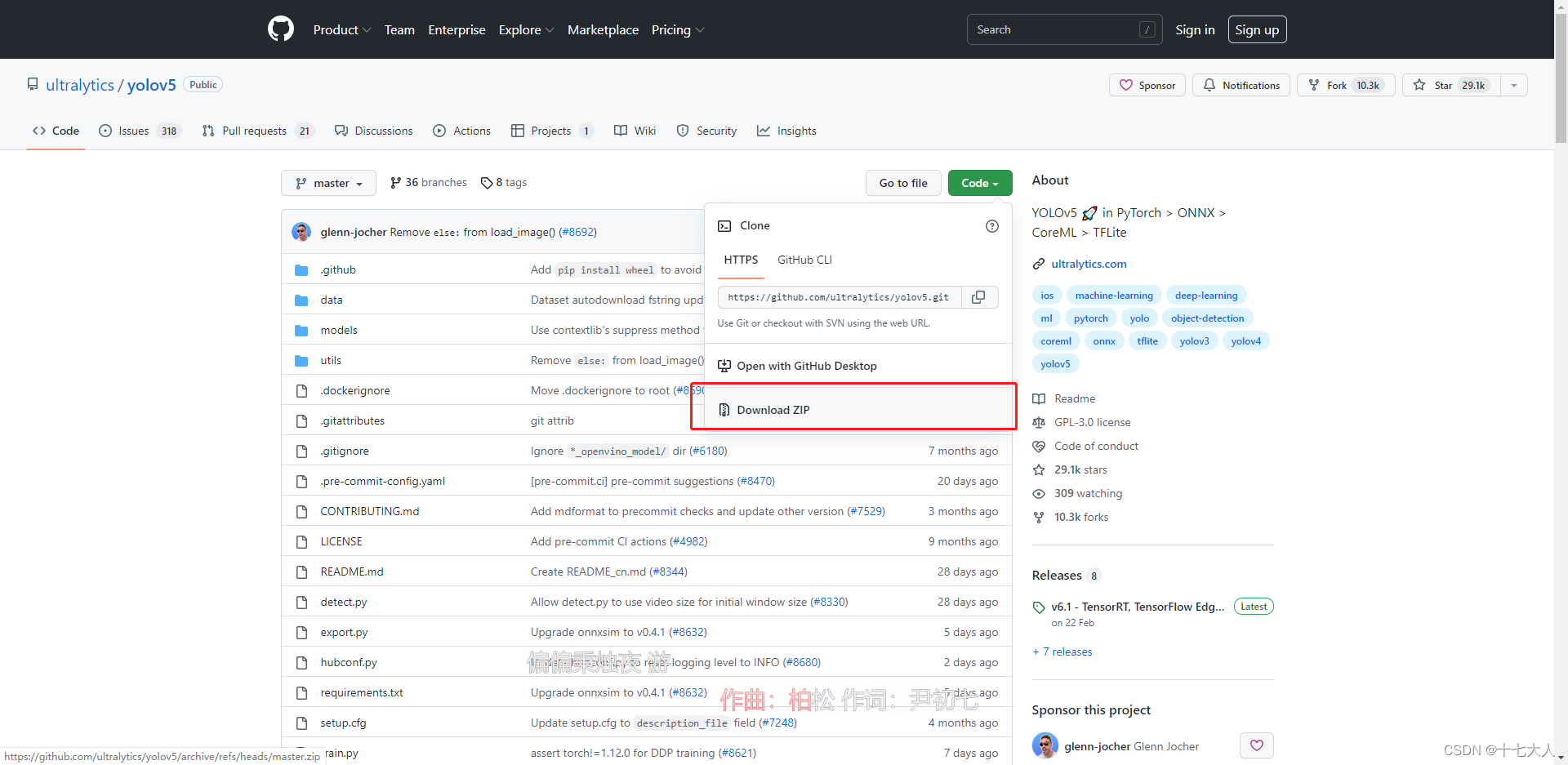
点击code-Download ZIP下载并解压,文件夹重命名为yolov5
存放路径你可以自己设定也可以参照我的,我存放在C盘里
C:\Users\Administrator\

2.下载anaconda用于配置环境
下载地址Anaconda | Anaconda Distribution
推荐使用清华镜像下载Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
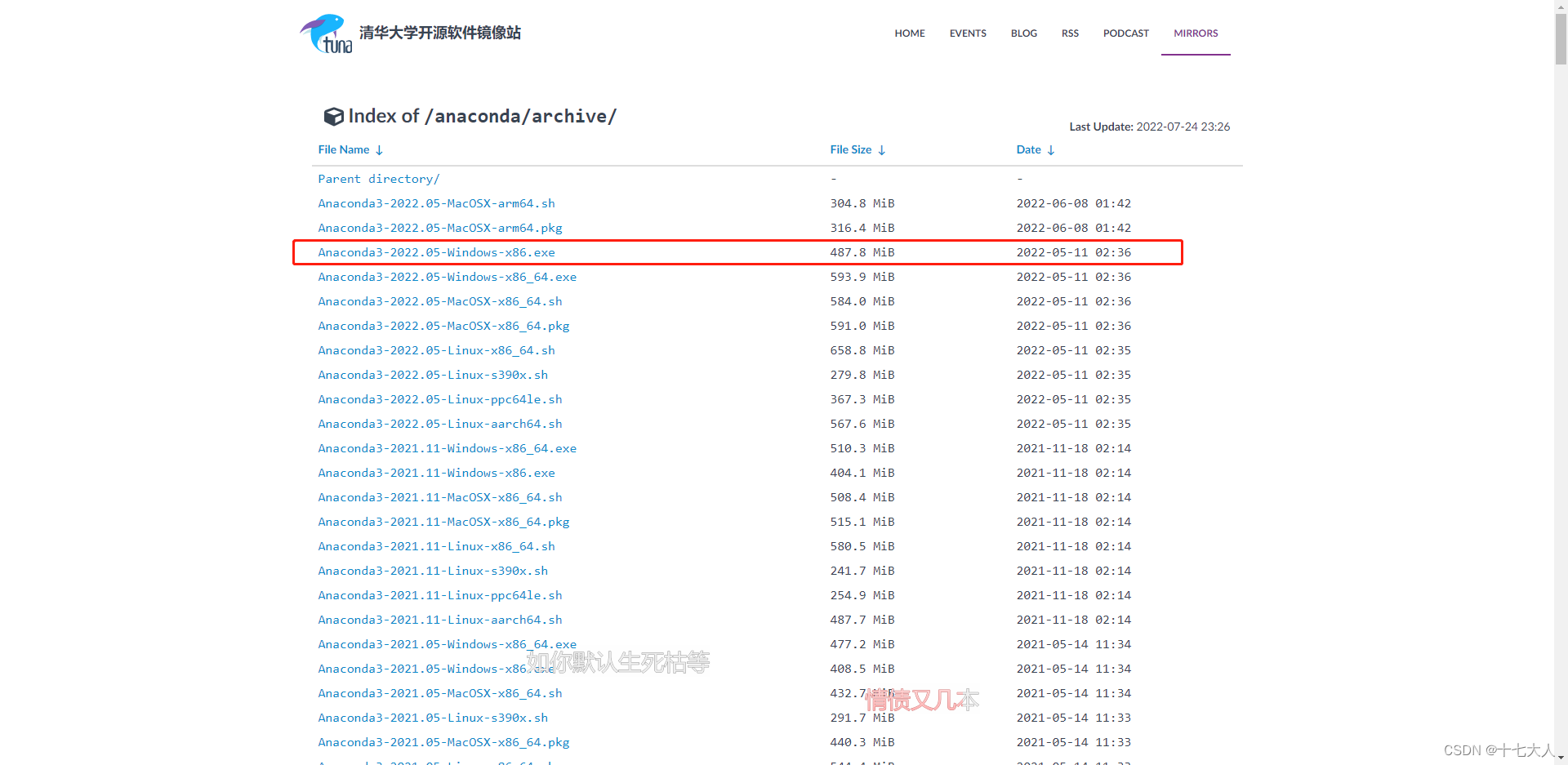
安装
最新Anaconda3的安装配置及使用教程(详细过程)_HowieXue的博客-CSDN博客_anaconda3
注意,大部分Anaconda教程安装后会让你更改conda源或者pip源,这个与实际使用环境有关,个人使用官方源速度2m/s,反而使用清华源500k/s。所以换不换源取决你自己的网络环境。
建议先不用换源
Anaconda之conda换国内源_你的大数据学长的博客-CSDN博客_conda换源
pip 及 conda换源_uu_189340的博客-CSDN博客_conda pip换源
这里的pip以及conda是指下载器,换源是指在墙的情况下,改为从国内访问速度更快的网站下载软件包
3.熟悉命令窗口简单指令
conda简单指令conda --version #查看conda版本,验证是否安装conda env list #查看所有环境conda create -n env_name package_name #创建名为env_name的新环境,并在该环境下安装名为package_name 的包,可以指定新环境的版本号例如:conda create -n python2 python=python2.7 numpy pandas,创建了python2环境,python版本为2.7,同时还安装了numpy pandas包conda activate env_name #进入env_name环境conda deactivate #退出环境conda create --name new_env_name --clone old_env_name #复制old_env_name为new_env_nameconda remove --name env_name –all #删除环境conda list #查看所有已经安装的包conda install package_name #在当前环境中安装包conda install --name env_name package_name #在指定环境中安装包conda remove – name env_name package #删除指定环境中的包conda remove package #删除当前环境中的包win命令窗口简单指令dir #显示当前文件夹中的所有文件cd #文件夹名或者文件夹路径 #跳转到文件夹cd .. #移动到上一个文件夹2、配置环境
在win开始目录里找到Anaconda3文件,打开Anaconda prompt
输入
conda create -n yolo python==3.8.5 #创建一个名字叫yolo的环境,使用python3.8.5#下图环境的名称是yolo5,这是因为我已经有yolo的环境了,所以用yolo5的名称来做演示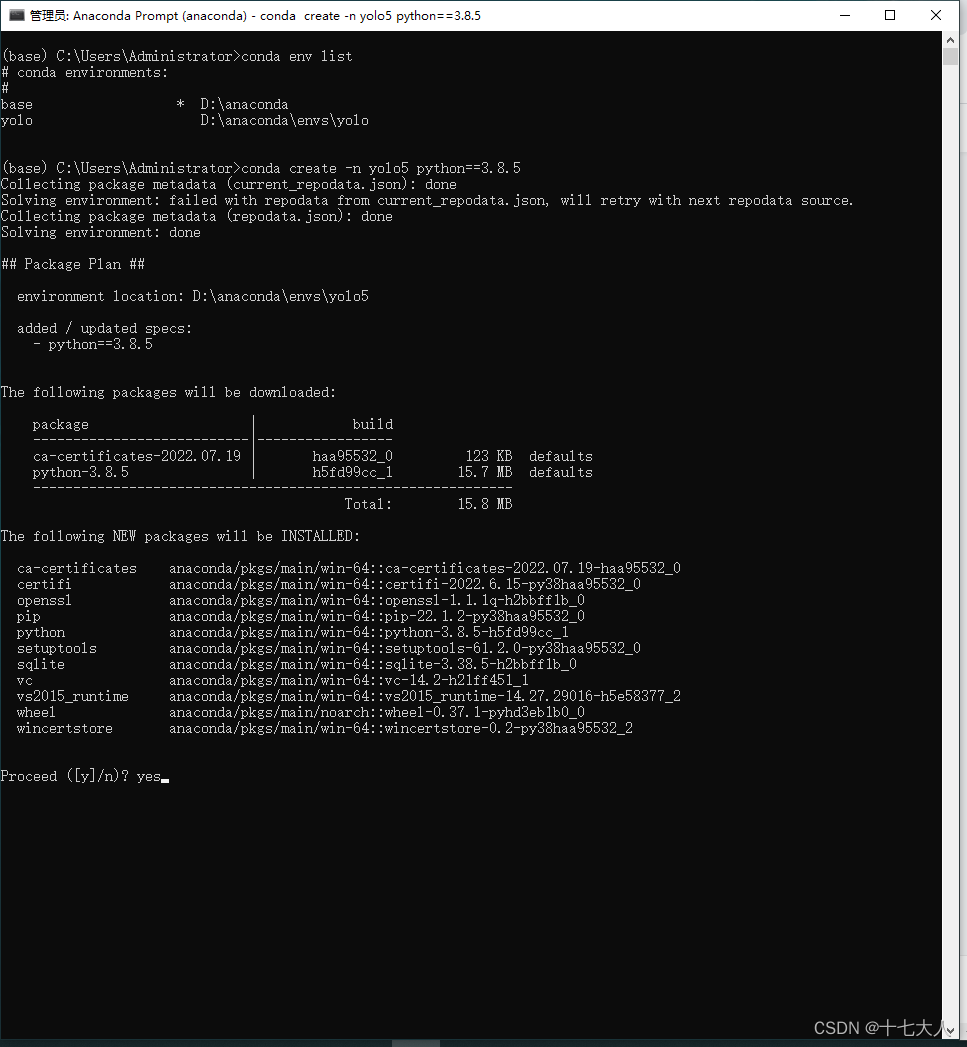
输入yes
耐心等待下载安装完成,半小时左右
conda activate yolo
可以看到环境从base变成yolo了
除了环境空间,我们还需要安装软件包
打开pytorch官网PyTorch
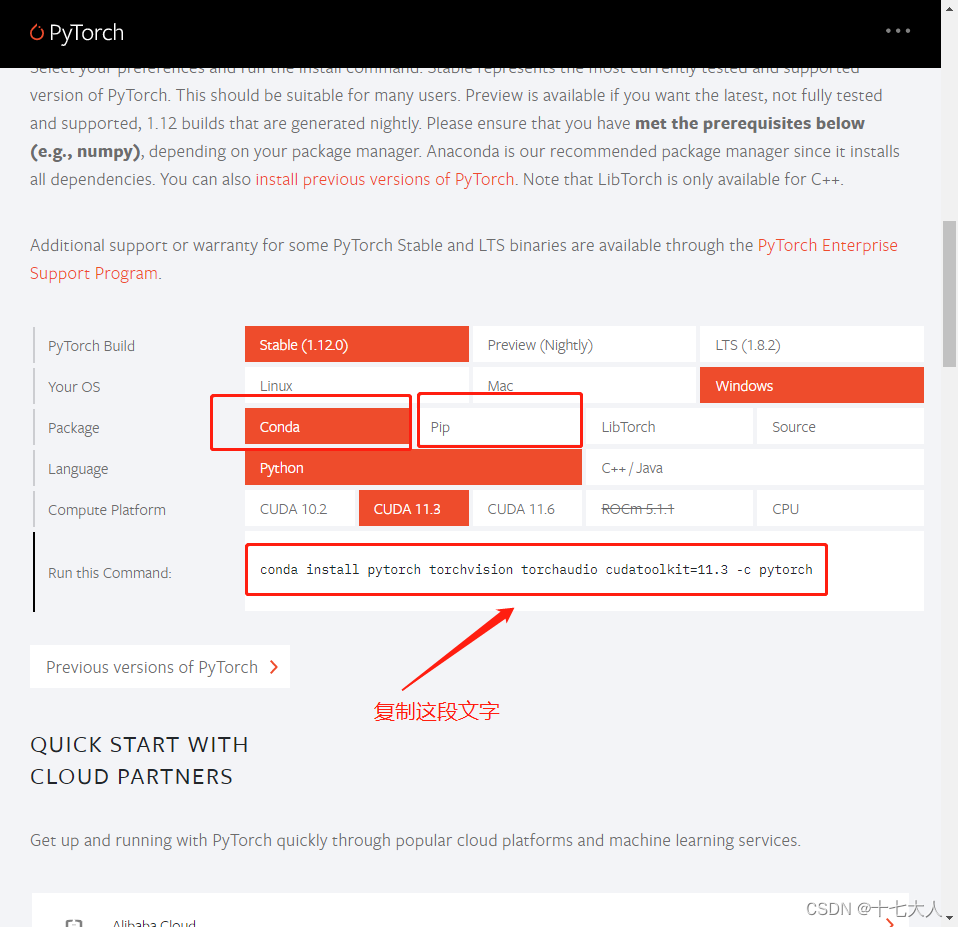
选择与电脑对于的版本与安装方式,我上面写的conda安装,也可以选择pip安装
如果你用的是独立显卡,你可以选cuda11.3或者cuda11.6,如果只用cpu那选择选cpu
显卡驱动务必更新到最新,具体安装参考
PyTorch 最新安装教程(2021-07-27)_ZSYL的博客-CSDN博客_pytorch安装教程
然后复制下方的安装代码,在yolo的环境下复制回车
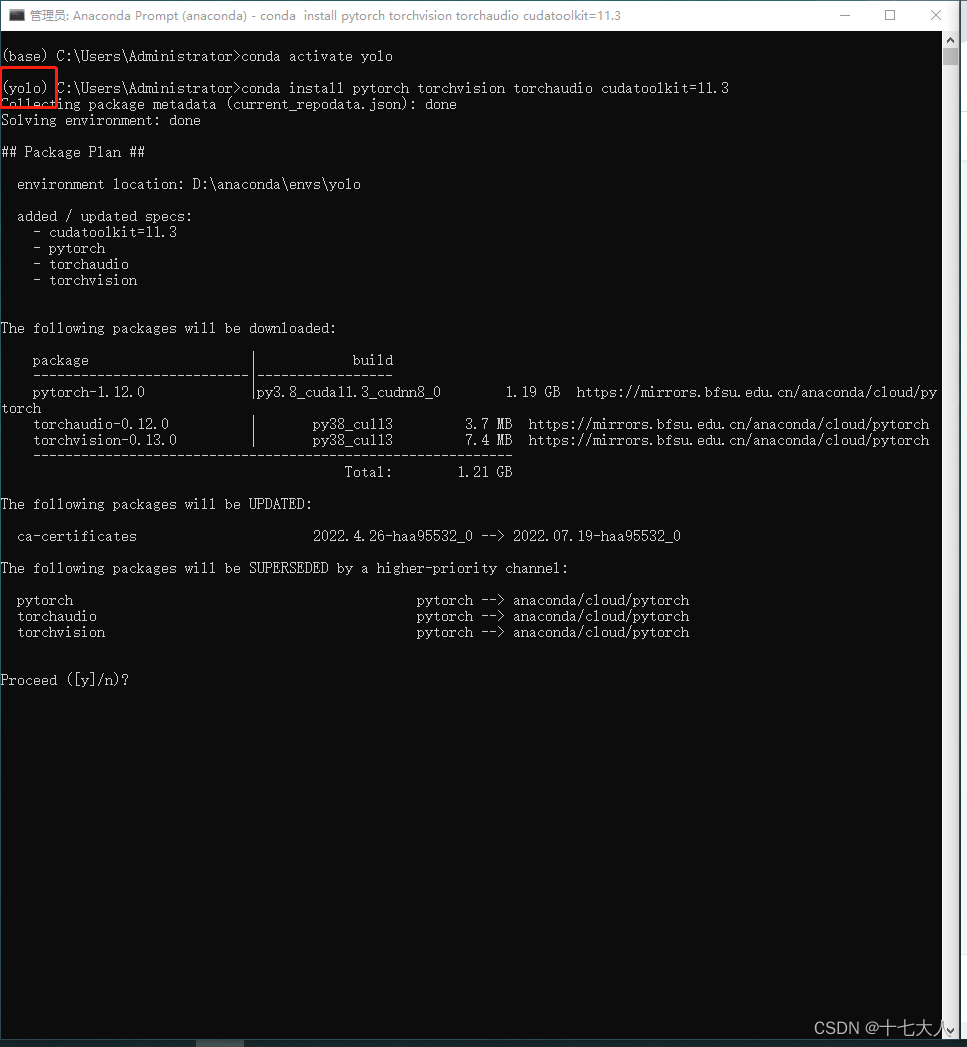
注意一定要先切换到yolo环境,在yolo的环境下安装
输入yes
安装完成后进入py环境,输入指令验证
pythonimport torch print(torch.__version__) # pytorch版本print(torch.version.cuda) # cuda版本print(torch.cuda.is_available()) # 查看cuda是否可用#crtl+z 回车 退出python环境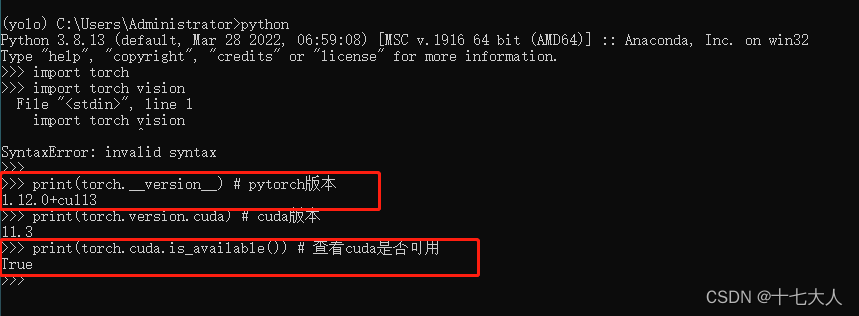
得到pytorch版本1.12.0+cu113,这个cu113表示是使用gpu的版本是正确的
注意,如果出现1.12.0+cpu 说明你安装错了,这是cpu版本,要卸载cpu版,重新安装gpu版的
后面的查看cuda是否可用是指,是否可以调用gpu,只有为ture才能调用gpu
conda uninstall pytorch #conda卸载pip uninstall torch #pip卸载#你用那个指令安装的就用那个指令卸载具体看pytorch安装及卸载_翟羽嚄的博客-CSDN博客_卸载pytorch
然后是其他软件包的安装
先移动到yolov5源代码的位置
cd \Users\Administrator\yolov5 #你放在哪里就cd到你放的那个路径在显示文件夹里的文件
dir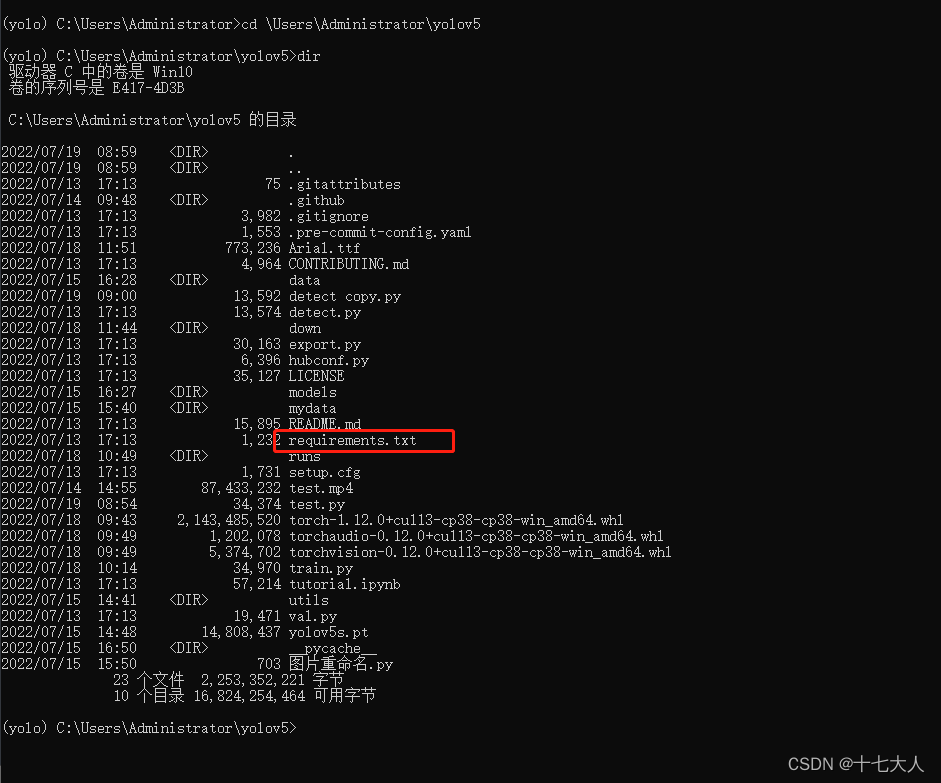
可以看到有个叫requirements.txt的文件,里面放的是yolov5要安装的软件包和版本
我们在文件管理器中打开requirements.txt
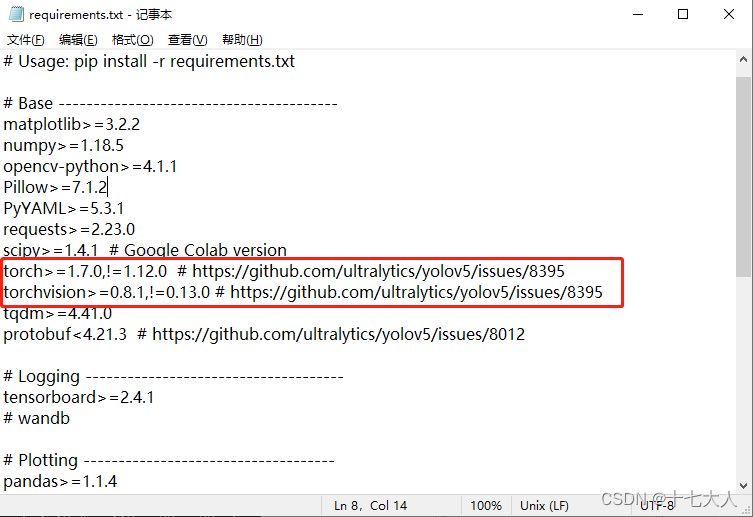
找到这两行,在前面加#号注释掉或者直接删掉这两行
注意!!这两行其实就是pytorch的安装指令,但是这条指令执行后会默认安装cpu版本的pytorch,覆盖掉我们之前安装的gpu版本,这也是为什么大部分人装了半天gpu版本,最后一查是cpu版本的原因。
使用pip下载requirements.txt里所有软件包
pip install -r requirements.txt安装labelme,用于标注图片
pip install labelimg安装VScode,用于编辑python程序
VSCode安装教程(超详细)_牛哄哄的柯南的博客-CSDN博客_vscode安装
3、测试环境是否正确配置
打开VScode,找到yolov5文件目录,选择detect.py文件,在右下角选择编译器为yolo
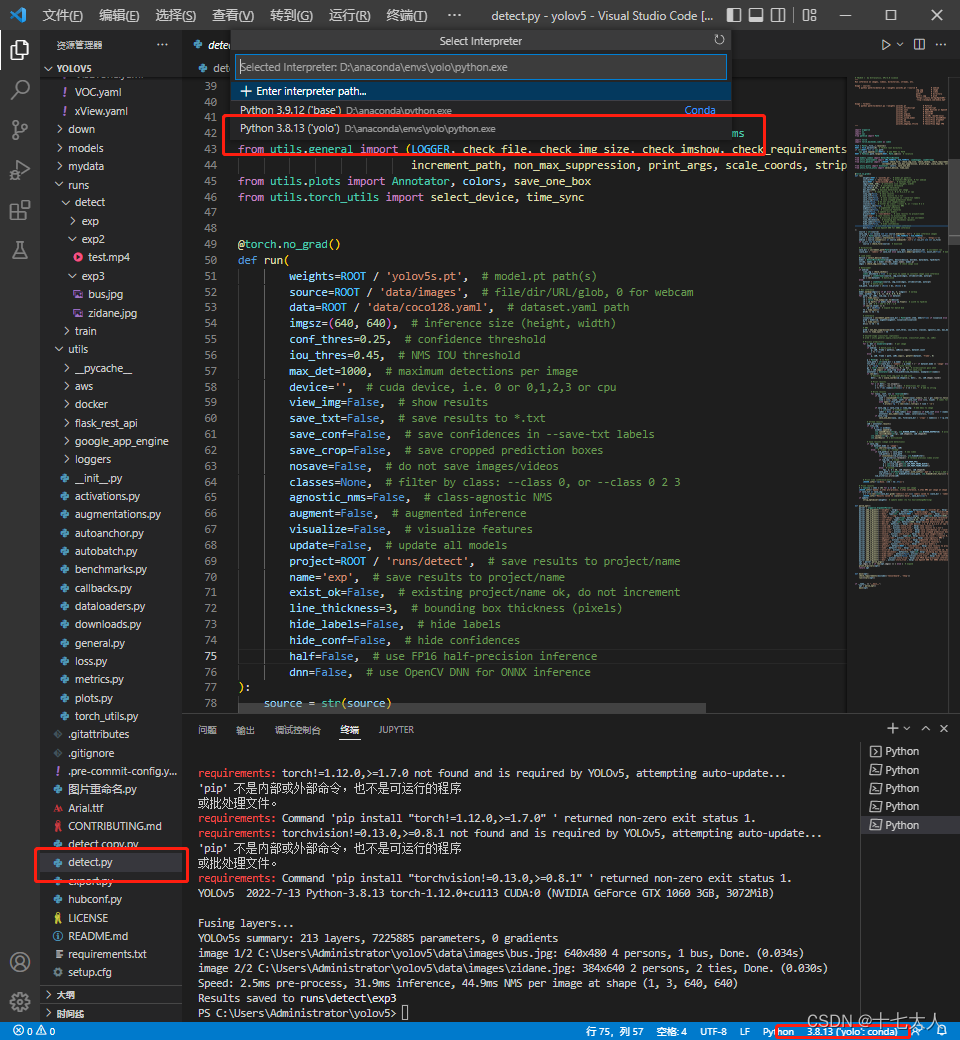
点击右上角运行
正常情况下运行后会在runs\detect文件下出现一个以exp为前缀的新文件夹,找到最新的那个,打开可以看到两张被标注好的照片
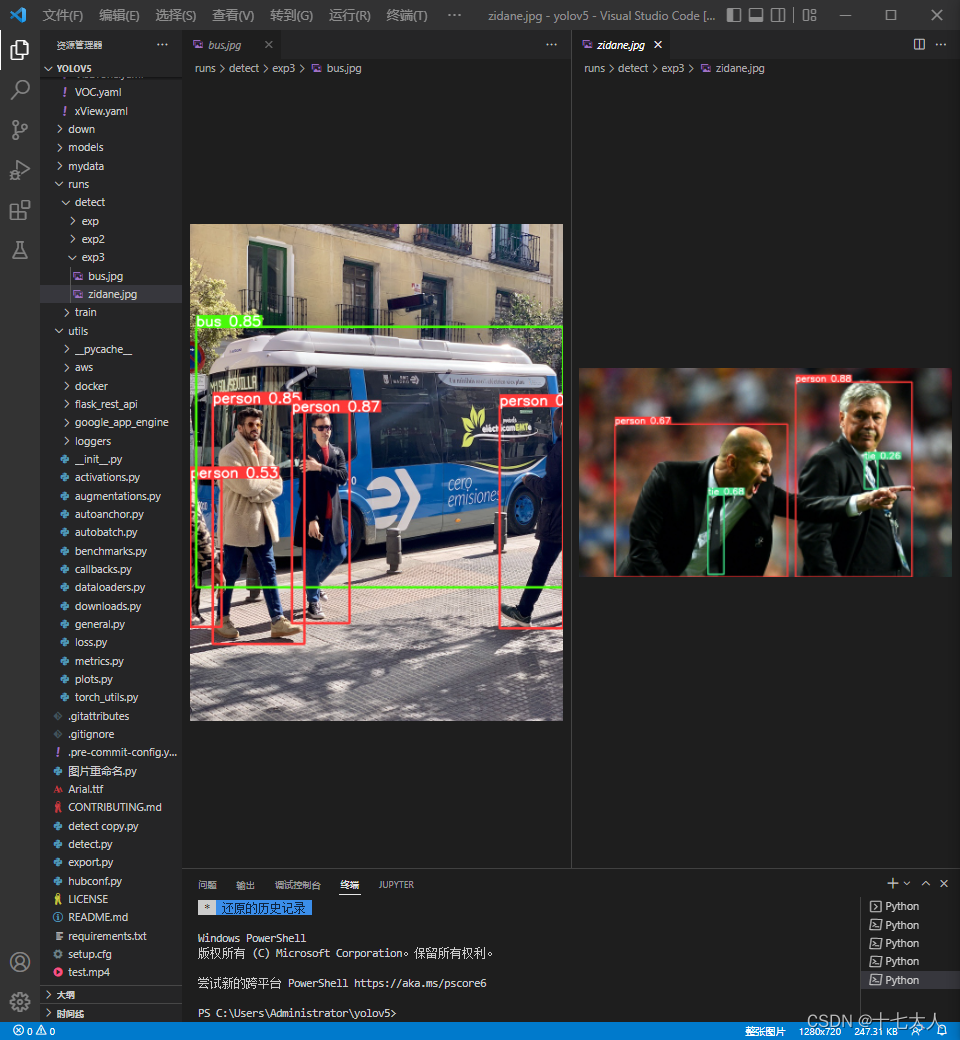
但直接运行成功的情况太少了,大部分人的情况是遇到
ModuleNotFoundError: No module named requestsUnknown or unsupported command installModuleNotFoundError: No module named ‘tqdm‘ModuleNotFoundError: No module named ‘seaborn‘环境变量有中文导致的软件不能使用的问题关于VS Code中“相对路径”异常的解决办法(windows系统)ModuleNotFoundError: No module named ‘pandas’WARNING:Ignore distutils configs in setup.cfg due to encoding errors解决:python:ModuleNotFoundError: No module named requests与Unknown or unsupported command install报错_Aloeox的博客-CSDN博客
ModuleNotFoundError: No module named ‘tqdm‘_长沙有肥鱼的博客-CSDN博客
ModuleNotFoundError: No module named ‘seaborn‘(缺少seaborn包)_Mr.小蔡的博客-CSDN博客
环境变量有中文导致的软件不能使用的问题_一抹烟霞的博客-CSDN博客
关于VS Code中“相对路径”异常的解决办法(windows系统)_恒木mh的博客-CSDN博客_vscode相对路径用不了
Jupyter Notebook报错 ModuleNotFoundError: No module named ‘pandas’_StefanJ的博客-CSDN博客【WARNING:Ignore distutils configs in setup.cfg due to encoding errors】完美解决_Youcai Zhang的博客-CSDN博客
这些是我遇到的问题,所有你们大概率也会遇到,你们可以关注我,在我的收藏夹里可以看到深度学习的收藏夹,里面的内容你们可能用得到。
当解决完所有问题,runs\detect出现被标注好的照片后,即代表环境已经配置好了,接下来我们进行下一步训练模型
二、训练模型
1、标注图片
首先,对着要识别的物体拍一大堆照片
然后按照下图顺序新建文件夹
mydata
├─ images
│ ├─ test # 下面放测试集图片
│ ├─ train # 下面放训练集图片
│ └─ val # 下面放验证集图片
└─ labels
├─ test # 下面放测试集标签
├─ train # 下面放训练集标签
├─ val # 下面放验证集标签
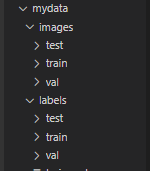
如图,mydata 文件夹的位置可以随意放置,记住路径即可,但mydata的内部文件夹的名称与位置要与上面图片一致。
我这里存放在C:\Users\Administrator\yolov5\
将开始拍摄好的照片放在mydata/images/train下
注意,图片数量至少50张起步,越多越好,没有上限
注意,如果文件名字太乱可以用以下方法更改,不过不改也没有太大问题Python批量改变图片名字_怪&的博客-CSDN博客_python修改图片名称
回到Anaconda prompt 进入yolo环境
输入
labelimg
可以看到弹出了一个界面
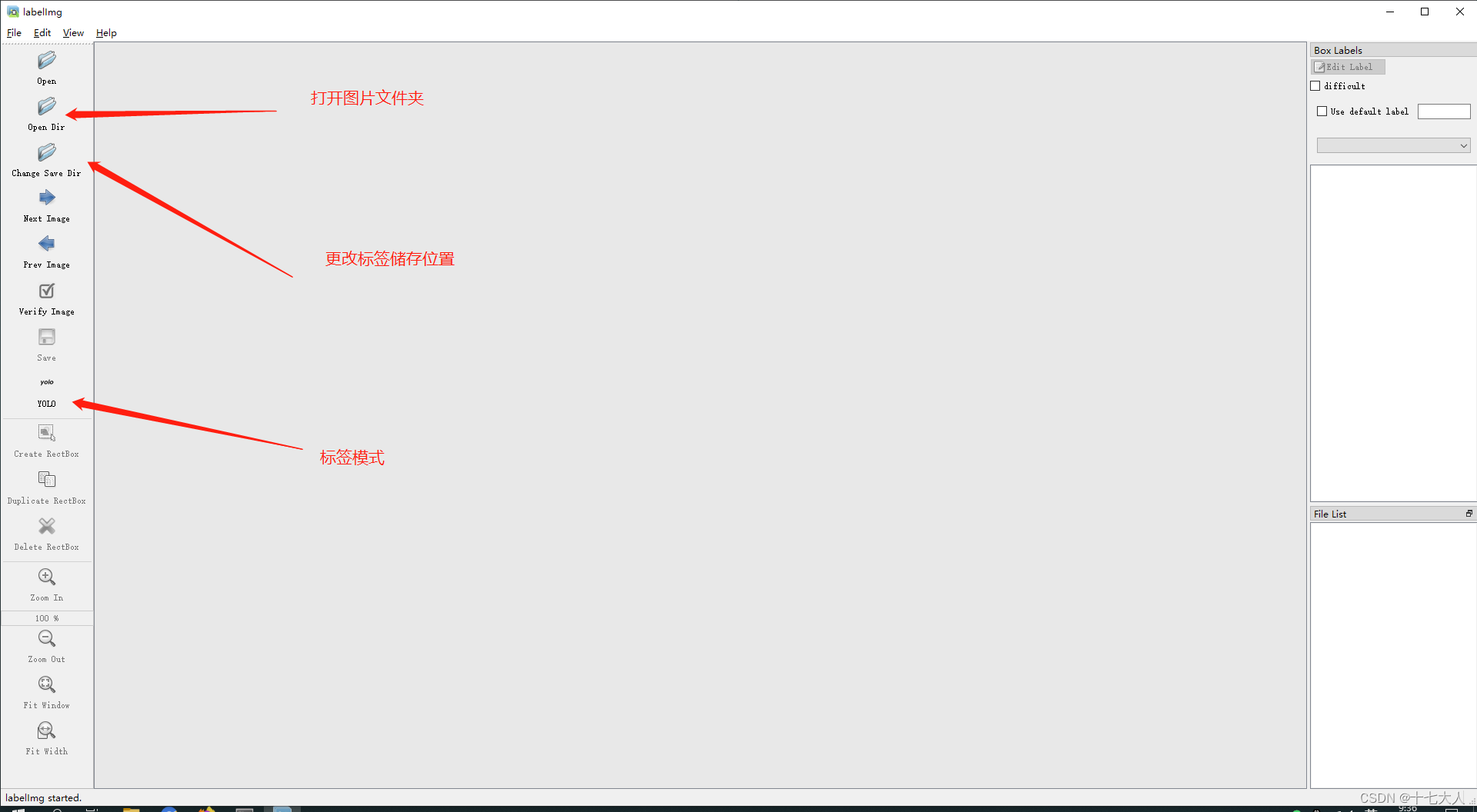
先打开 ,文件位置选择你存放图片的地方mydata\images\train,我这里是C:\Users\Administrator\yolov5\mydata\images\train
,文件位置选择你存放图片的地方mydata\images\train,我这里是C:\Users\Administrator\yolov5\mydata\images\train
在打开 ,文件位置选择在你要保存标注文件的地方mydata\labels\train,我这里是
,文件位置选择在你要保存标注文件的地方mydata\labels\train,我这里是
C:\Users\Administrator\yolov5\mydata\labels\train
注意,图片文件必须保存在mydata\images\train下,标注文件必须保存在mydata\labels\train文件下,必须在同一个mydata文件下,不然程序可能找不到
点击save按键下方的 切换标注模式为yolo
切换标注模式为yolo
在view中设置auto save mode自动保存
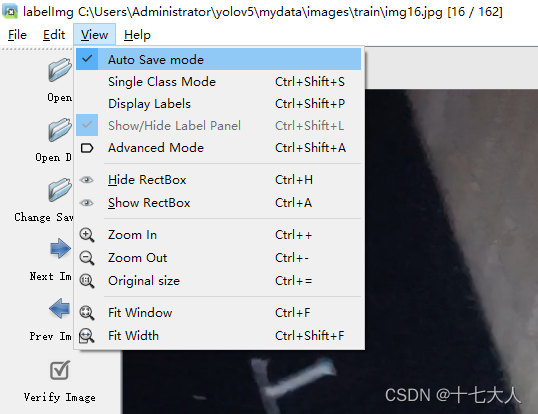
labelimg的快捷键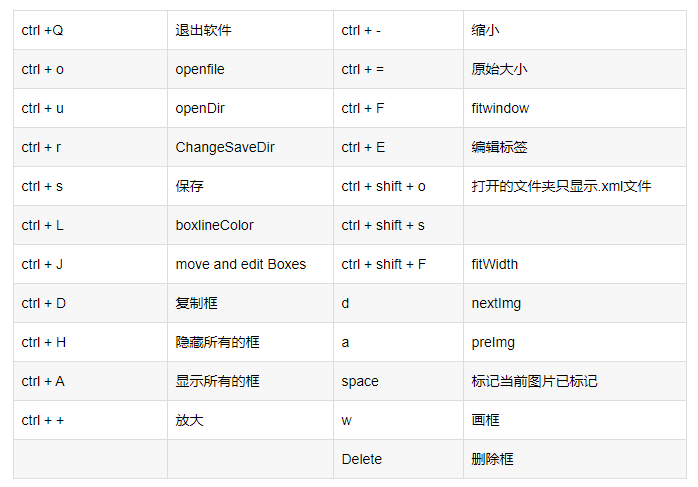
实际只用w键创建标注框,使用d、a键切换上下图片
用w框选要识别的物体,输入标注物体名字标签,我标注的是剪刀scissors
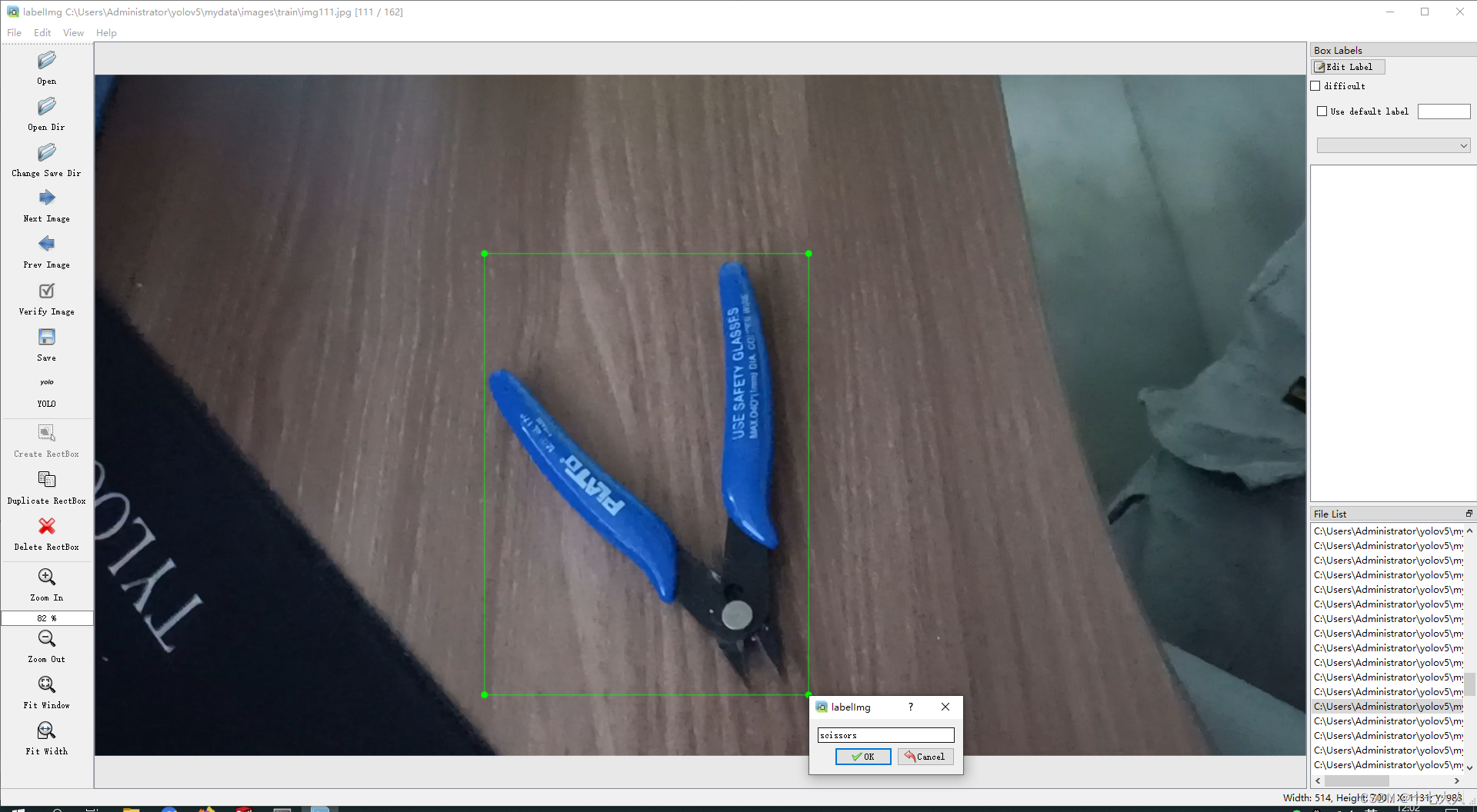
然后按d键切换下一张,直到标注完所有图片的
注意,可以一次标注多个不同物体,这里演示所以只识别一种物体
2、检查标签
打开mydata\labels\train文件
我这里是C:\Users\Administrator\yolov5\mydata\labels\train
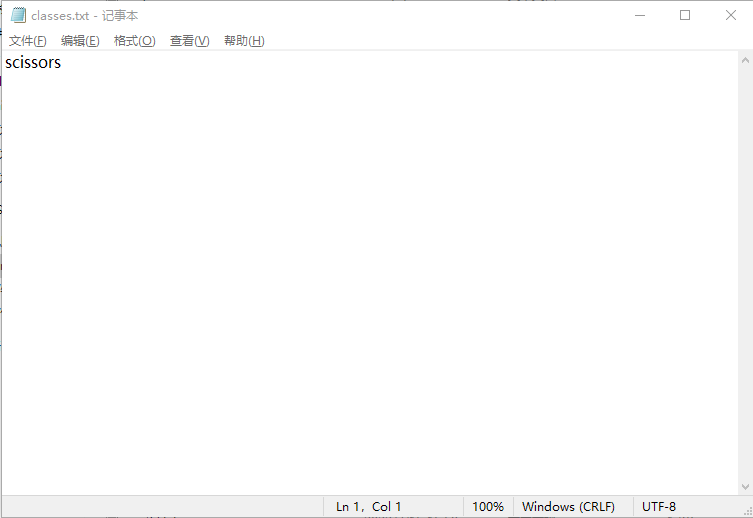
可以看到有很多txt文件,点开第一个classes.txt文件,显示只有scissors一种标签,如果你标注了几种这里就会有几种
标注完成后,打开mydata/images/train文件夹,将train里的图片挑选出大概10张(总图片的10%)特别清晰明显的图片,复制到images/val和images/test中。
val验证集用于调整训练曲线,比如当你的模型训练是遇到了模糊的图片或者其他玄学原因,导致模型出现了偏差,但是模型隔一段时间就会去跑一次验证集,这个时候验证集清晰的图片就会把这个偏差给去除,防止我们最后得到的模型精度偏差太大。
test测试集是最后模型训练完成了,测试一下模型的精度。
图片复制完后就要复制图片的标注文件
打开mydata/labels/train文件夹,复制你刚才挑选的图片的对应标注文件,复制到/labels/val与/labels/test
注意,实际这两个集可以直接为空,或者直接将训练集里复制所有文件都复制到测试集和验证集里,我这里是直接复制训练集里所有文件到另外两个集里
3、更改运行文件
将运行文件中的数据位置改成我们文件实际位置
1.修改coco128.yaml
打开yolov5\data 文件夹,找到coco128.yaml文件,复制一份,重命名为mydata.yaml
我的路径为C:\Users\Administrator\yolov5\data
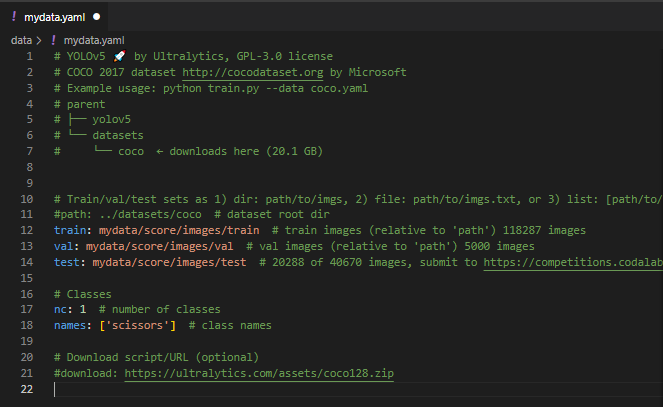
打开mydata.yaml,
修改:注释path行,
修改为train:mydata//images/train,此项为训练集相对相对位置(相对于主程序train.py的位置)
修改val: mydata/images/val,此项为验证集的相对位置
修改test: mydata/images/test,此项为测试集的相对位置
修改nc:1 此项为标签种类数,我只标记了一种,所以此处为1
修改names: ['scissors'],更改你的标签名称,有几种写几种
注释download ,此项为下载yolov5的默认脚本,对我们没用
2.修改yolov5s.yaml
打开yolov5\models,找到yolov5s.yaml,复制一份重命名为myyolov5s.yaml
我的路径为C:\Users\Administrator\yolov5\models\
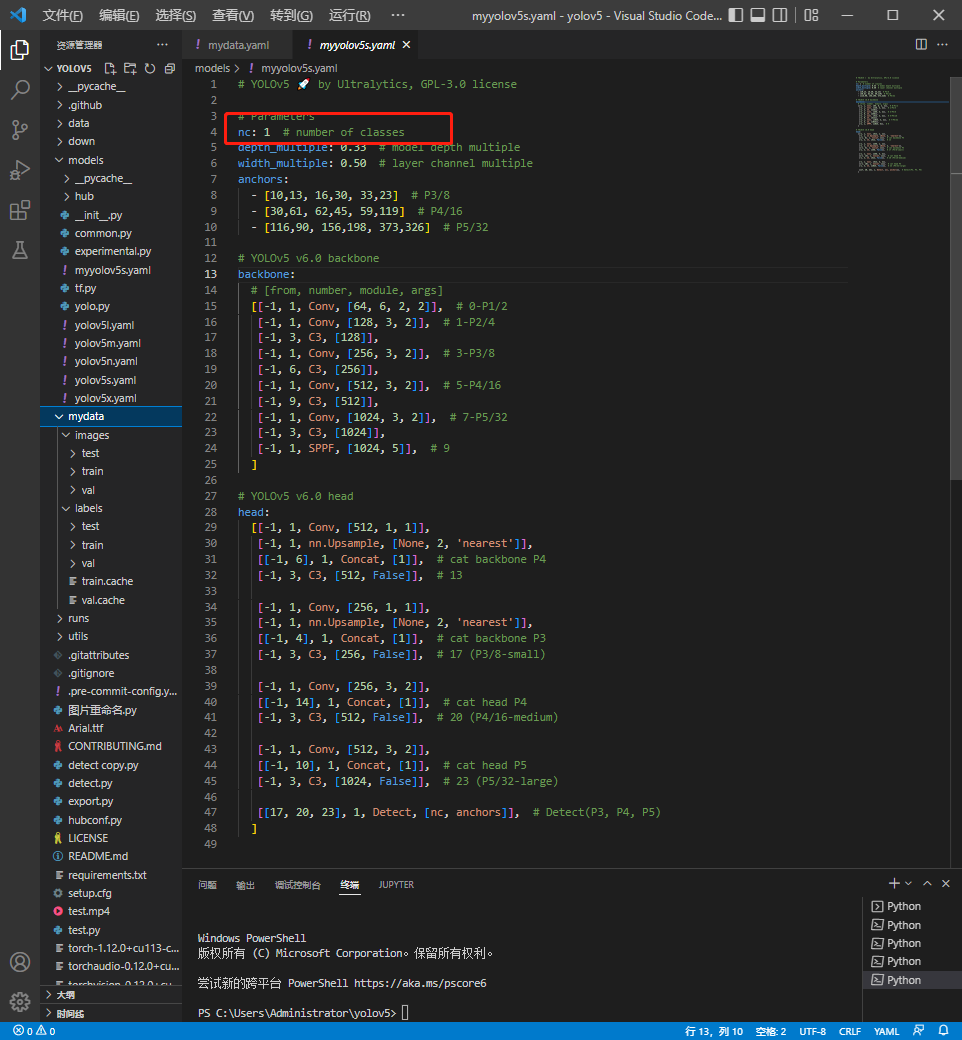
打开myyolov5s.yaml
只需要修改一项将nc改为1,此项为我们的标签种类数
注意,我们发现除了yolov5s.yaml,还有yolov5l.yaml、yolov5m.yaml、yolov5n.yaml、yolov5x.yaml
打开这些文件,仔细观察,发现只有这两项不一样

这两项是指神经网络的深度和宽度,在使用过程中这两项的数值越大,模型的精度越高,但所需要的时间也越多,模型精度从小到大依次为,yolov5n.yaml、yolov5s.yaml、yolov5m.yaml、yolov5l.yaml、yolov5x.yaml,如果你的显卡配置够好的话可以选择yolov5x.yaml,如果差一点的话可以选择yolov5n.yaml,我这里选择yolov5s.yaml
4、修改train.py
打开yolov5文件夹,找到 train.py文件,复制重命名为mytrain.py
我的文件路径为C:\Users\Administrator\yolov5\train.py
打开mytrain.py,下滑到473行
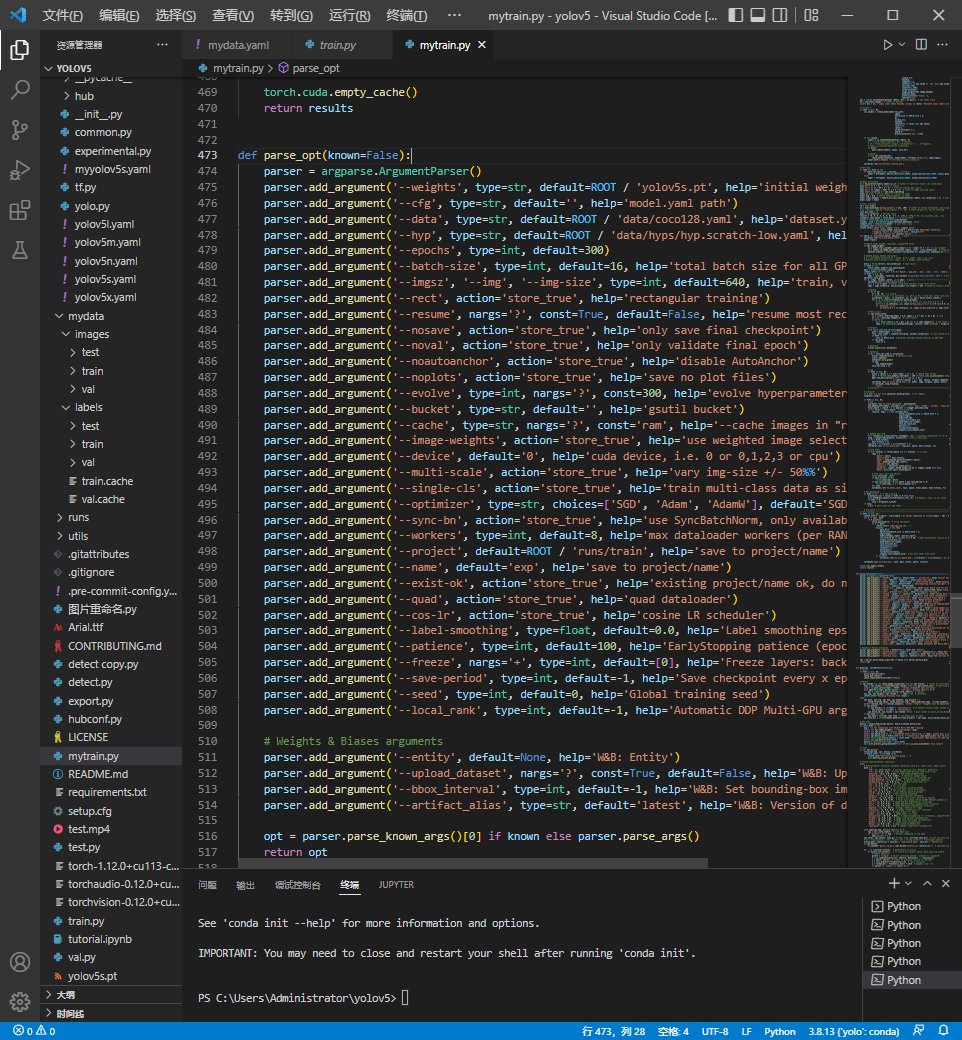
此部分代码详解请参照
yolov5的train文件代码含义解析(部分)_我有个想法~不,你不想的博客-CSDN博客_train文件
我们只需要修改这一段代码中的少数几行中"default="字样之后的文字
parser = argparse.ArgumentParser() parser.add_argument('--weights', type=str, default= 'yolov5s.pt', help='initial weights path')#预训练模型,可不填,但效果会很差,默认为yolov5s.pt parser.add_argument('--cfg', type=str, default='models/myyolov5s.yaml', help='model.yaml path')#必要修改#修改地址为models/myyolov5s.yaml,训练模型文件位置 parser.add_argument('--data', type=str, default='data/mydata.yaml', help='dataset.yaml path')#必要修改#修改地址为data/mydata.yaml,数据集文件位置 parser.add_argument('--hyp', type=str, default= 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path') parser.add_argument('--epochs', type=int, default=100)#修改训练轮数为100,轮数越高,精度越高,速度越慢,默认300 parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')#线程数默认为16,越大越快,不能过大, parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')#图片大小,越小越快,但精度越差,一般图片多大填多大,不规则填最长边尺寸 parser.add_argument('--rect', action='store_true', help='rectangular training') parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')#继续训练,如果上一次训练中止了,只要在这里填上Ture,就可以继续完成上一次训练 parser.add_argument('--nosave', action='store_true', help='only save final checkpoint') parser.add_argument('--noval', action='store_true', help='only validate final epoch') parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor') parser.add_argument('--noplots', action='store_true', help='save no plot files') parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations') parser.add_argument('--bucket', type=str, default='', help='gsutil bucket') parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"') parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training') parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')#必要修改#修改为0,0的意思是调用gpu0,如果你的电脑有几块gpu可以填1,2,3,如果没有gpu可以在上面填cpu parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%') parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class') parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer') parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode') parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)') parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name') parser.add_argument('--name', default='exp', help='save to project/name') parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment') parser.add_argument('--quad', action='store_true', help='quad dataloader') parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler') parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon') parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)') parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2') parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)') parser.add_argument('--seed', type=int, default=0, help='Global training seed') parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')注意,必须要修改 --data --cfg --batch-size 这三行代码
其他的可以稍微调整来提高精度或减少训练时间
注意!!修改好后,点击ctrl+s保存
5、开始训练,运行mytrain.py
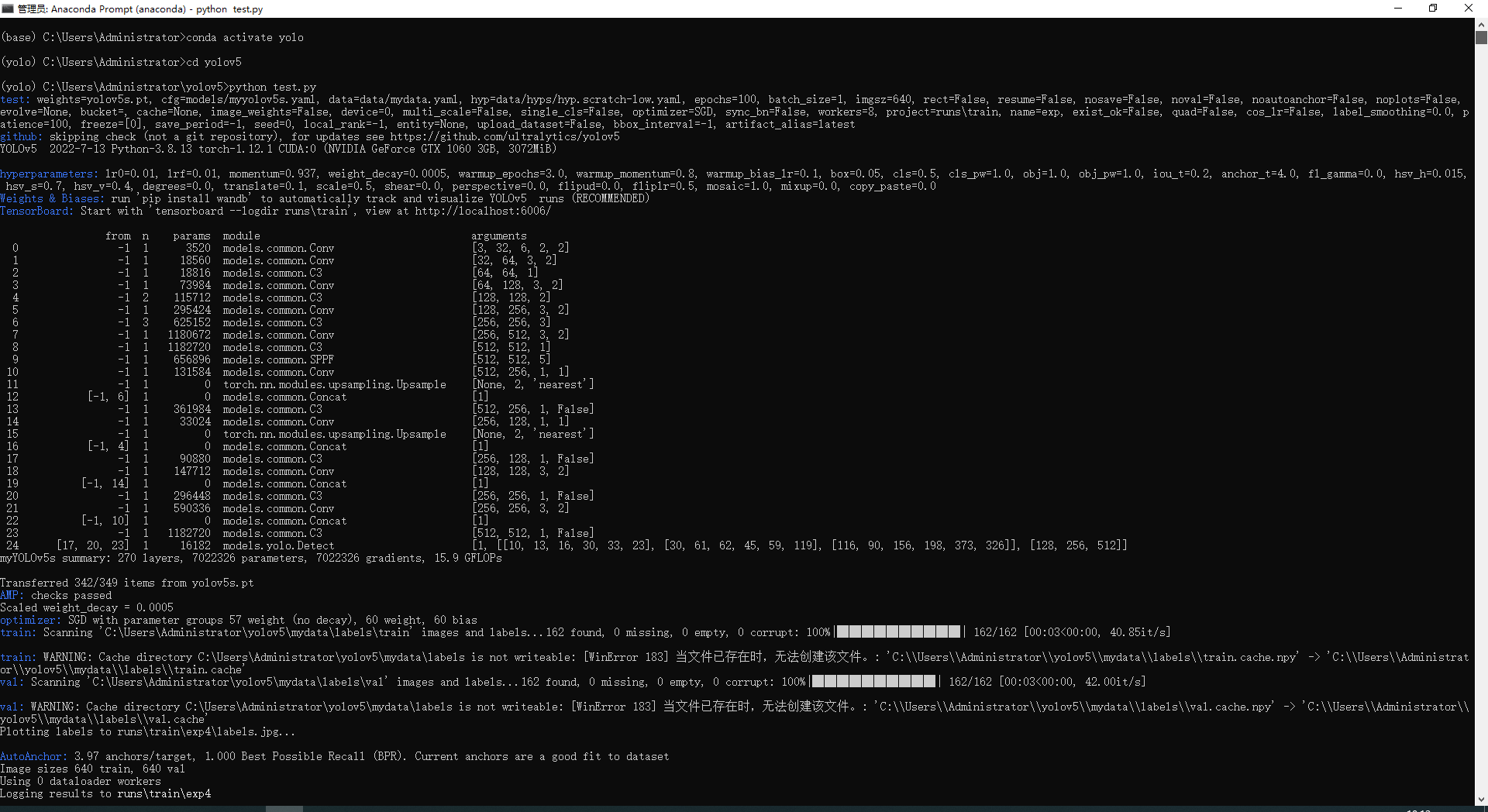
打开Anaconda prompt
输入
conda activate yolo #切换到yolo环境cd C:/Users/Administrator/yolov5 #移动到yolov5文件夹#cd 后面改成你文件夹的位置python mytrain.py #运行程序,开始训练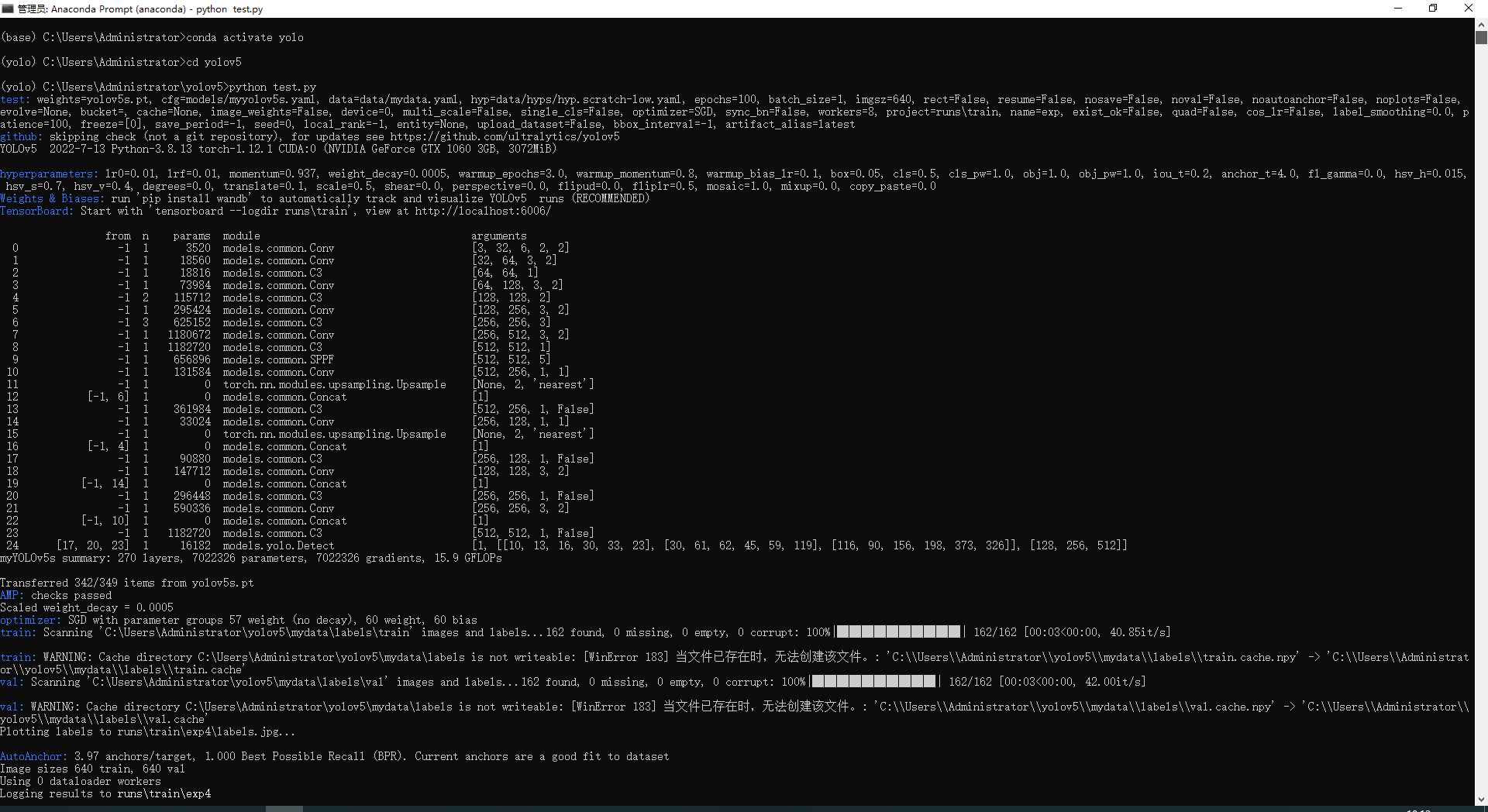
等待程序运行完成,打开yolov5\runs\train,找到最新的exp前缀的文件夹,我这里是exp8,点击进入后,打开weights文件夹
我的路径为C:\Users\Administrator\yolov5\runs\train\exp8\weights
可以看到
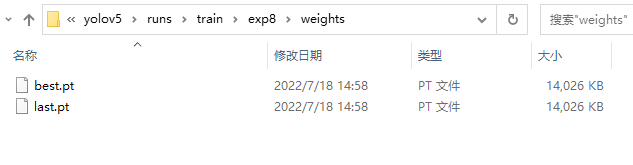
有best.pt和last.pt,这两个文件就是我们训练得到的模型。
best.pt的精度更高,但是识别率低,可能存在看到了目标,但因为阈值过高而无法识别,last.pt的精度低,但是识别率高,可能存在没看到目标,但因为阈值过低,将其他物体错误识别成目标物体
以上问题归根结底还是数据太少的原因导致,只要数据足够多,精度是可以保证的。
三、使用模型
打开yolov5文件夹,找到detect.py文件
我的路径 C:\Users\Administrator\yolov5\detect.py
detect.py程序里集成了模型所有的使用情况
打开文件,找到第215行
注意,我们主要修改 --weights --source,这两行
1、调用摄像头
打开detect.py文件
修改 --weights 为 runs/train/exp8/weights/last.pt 修改使用模型的位置,我们使用last.pt模型
修改 --source 为 0 修改调用摄像头0,如果有多个可以改1、2、3
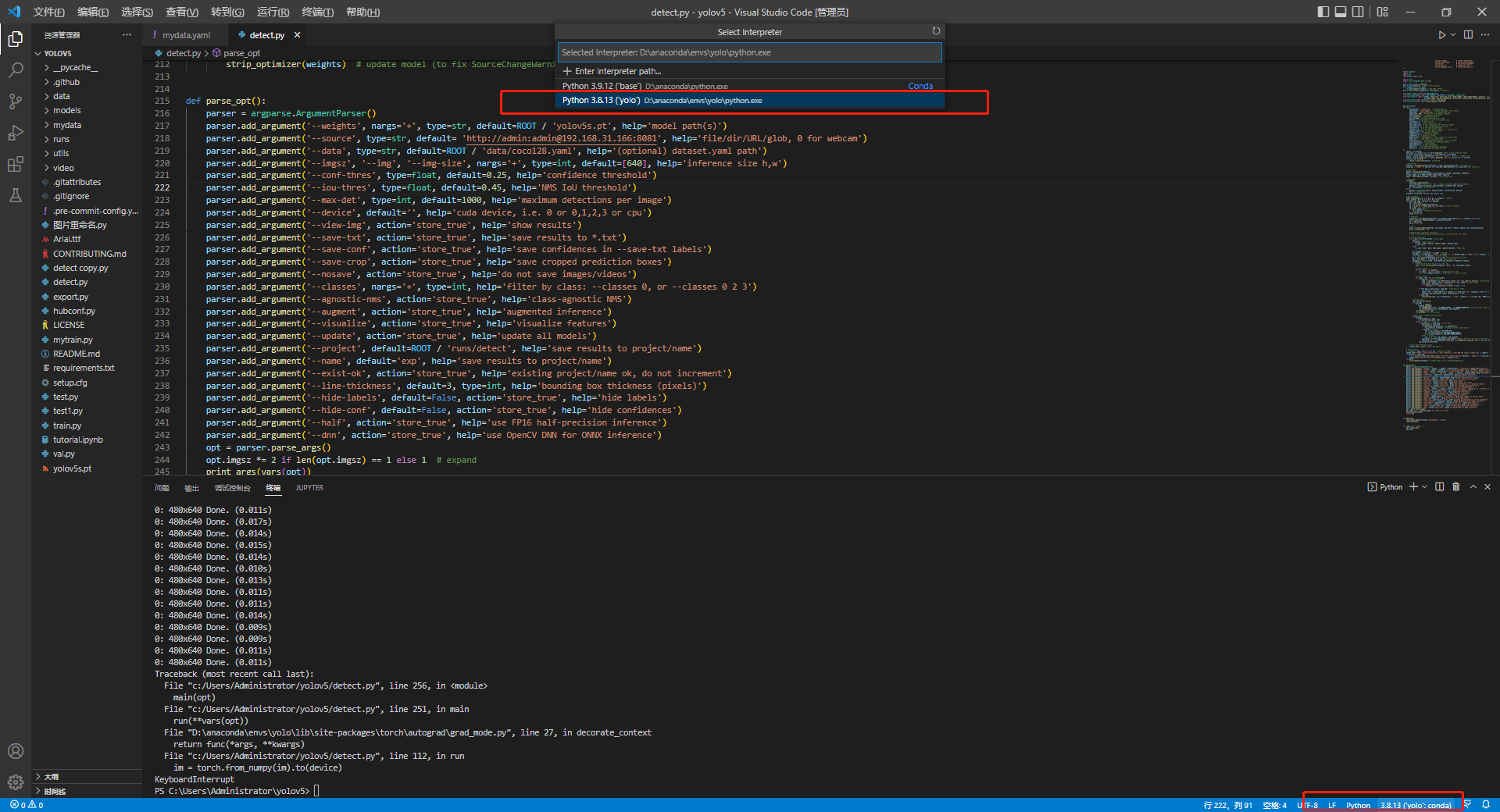
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'runs/train/exp8/weights/last.pt', help='model path(s)') parser.add_argument('--source', type=str, default= '0', help='file/dir/URL/glob, 0 for webcam') 修改好后,点击ctrl+s保存
在vscode中选中yolo环境点击运行即可
或者在Anaconda prompt在yolo环境中,在文件路径下输入
python detect.py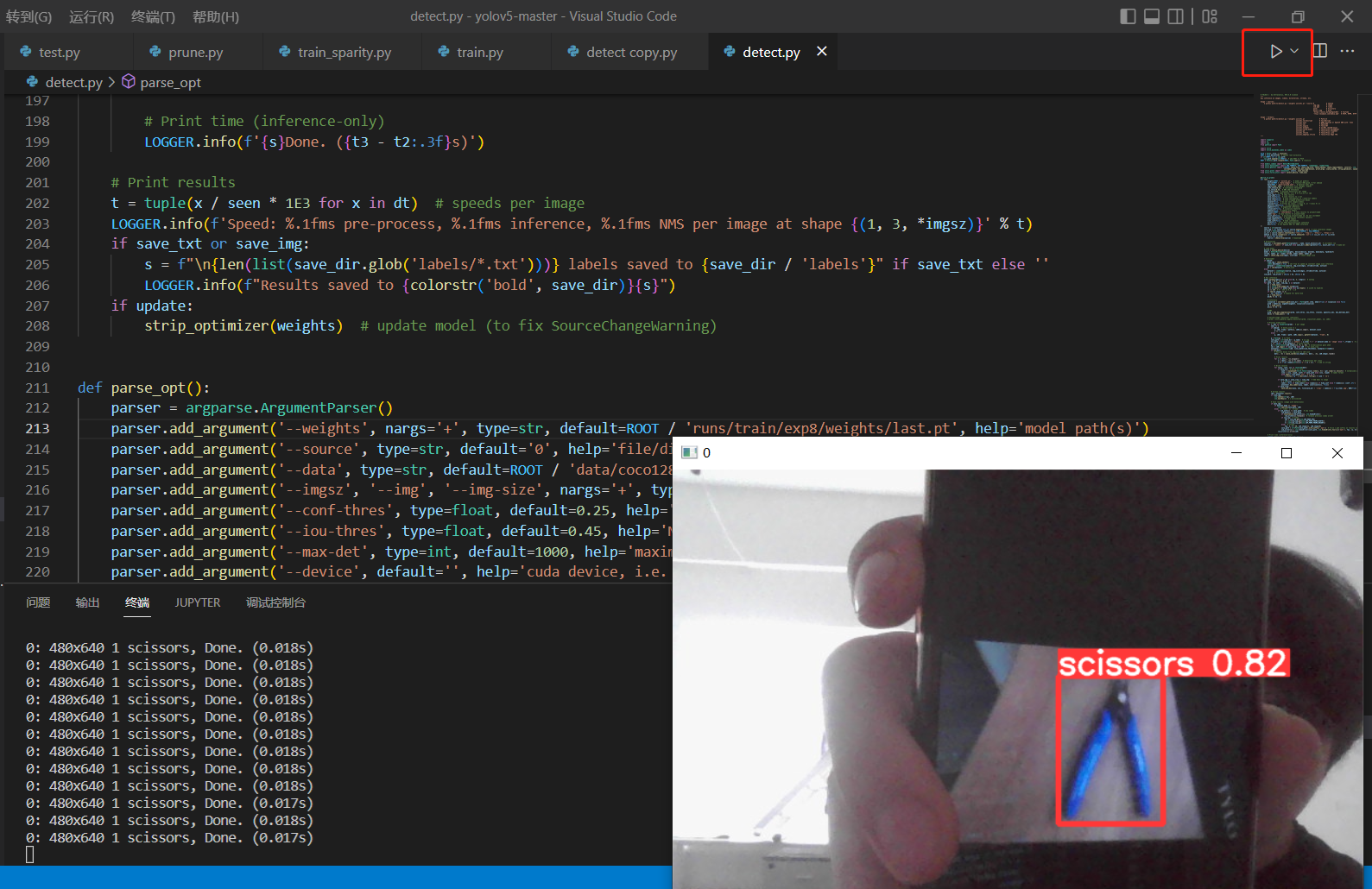
2、识别本地图片或者视频
同样,打开detect.py文件
修改 --weights 为 runs/train/exp8/weights/last.pt 修改使用模型的位置,我们使用last.pt模型
当识别文件夹里的图片,修改 --source 为 mydata/images/test 识别相对路径里mydata/images/test里我们放的测试集里所有图片
如果识别单个视频或图片,修改 --source 为 video\test.mp4 识别相对路径video/test.mp4 识别mp4视频文件
修改好后,点击ctrl+s保存
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'runs/train/exp8/weights/last.pt', help='model path(s)') parser.add_argument('--source', type=str, default= 'video/test.mp4', help='file/dir/URL/glob, 0 for webcam') 在vscode中选中yolo环境点击运行即可,或者在Anaconda prompt中,在yolo环境中,在文件路径下输入
python detect.py
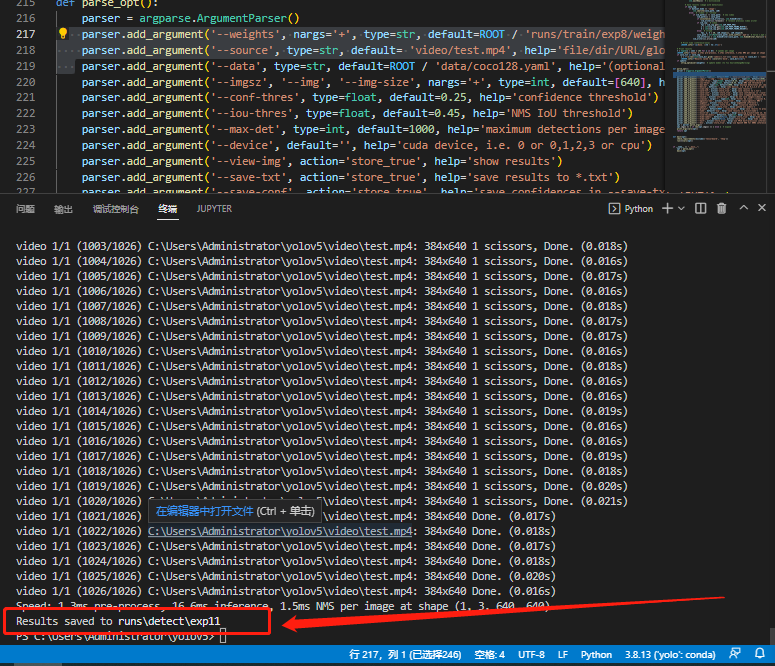
运行成功后看到输出路径为 runs\detect\exp11
移动到该路径可以看到名字为test.mp4的文件,打开文件
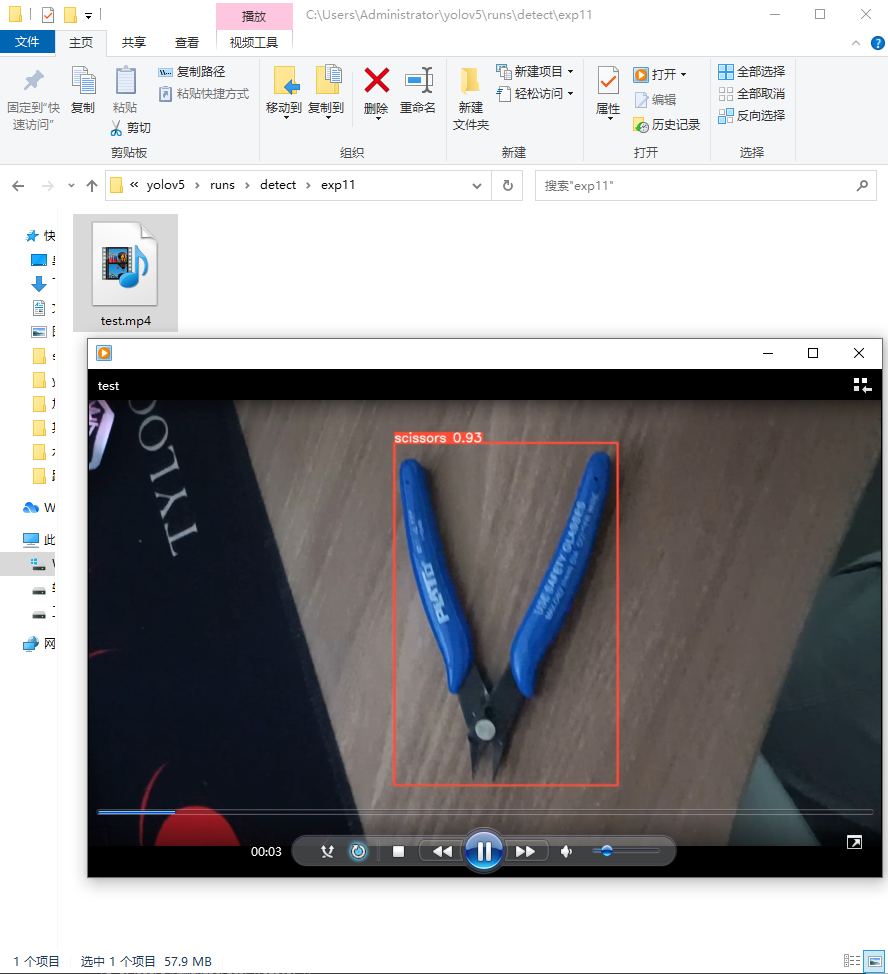
看到视频中已经标注好了目标物体
注意,这里是识别本地的文件,我们只要指定路径文件或者直接给文件夹路径就行
3、识别网络摄像头或者流媒体
先准备一台手机,和电脑连接同一个WiFi
手机下载IP摄像头app

打开软件



点击打开ip摄像头服务器,记住账号密码,以及局域网访问地址
回到电脑
打开detect.py文件
修改 --weights 为 yolov5s.pt 修改使用模型的位置,我们使用在自带 yolov5s.pt 模型(放在yolov5根目录下)
修改 --source 为 http://admin:admin@192.168.31.166:8081 此项修改为你自己手机上的ip
修改好后,点击ctrl+s保存
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path(s)') parser.add_argument('--source', type=str, default= 'http://admin:admin@192.168.31.166:8081', help='file/dir/URL/glob, 0 for webcam') 在vscode中选中yolo环境点击运行即可,或者在Anaconda prompt中,在yolo环境中,在文件路径下输入
python detect.py
可以看到界面上显示了手机拍摄到的照片,并正确识别了目标
四、总结
本文从一个新手的角度讲解了yolov5的环境安装与使用,此教程是我零零碎碎用上班摸鱼的时间写了快两个月完成的,一来记录我的学习历程,二来通过写教程的方式加强我对yolov5的使用,第三点也是最重要的一点,我是在别人教程的帮助下学会yolov5的,所以我希望我的教程也能帮助到更多人。敬此
五、找到我
CSDN 十七大人的博客
B站 十七大人的哔哩哔哩空间
知乎 十七大人 - 知乎