目录
一、为什么要内存对齐
二、基本变量类型所占大小
三、影响内存对齐的情况
四、先说结论(重要)
五、举亿点例子(以下内容均实际运行过,质量保证)
例1:研究结构体最后一个成员内存对齐问题1
例2:研究结构体最后一个成员内存对齐问题2
例3: 研究数组的内存对齐
例4:枚举 & 研究数组之间的内存对齐
例5:结构体嵌套1
例6:结构体嵌套2
例7:__attribute__((packed))
例8:#pragma pack (n)
写在前面:本次实验所用到的环境:Windows 10 Visual Studio(64 位)、Ubuntu 18.04 x86_64-linux-gnu(64 位)!!
一、为什么要内存对齐
简单来说,就是方便计算机去读写数据。
对齐的地址一般都是 n(n = 2、4、8)的倍数。
(1). 1 个字节的变量,例如 char 类型的变量,放在任意地址的位置上;
(2). 2 个字节的变量,例如 short 类型的变量,放在 2 的整数倍的地址上;
(3). 4 个字节的变量,例如 float、int 类型的变量,放在 4 的整数倍地址上;
(4). 8 个字节的变量,例如 long long、double 类型的变量,放在 8 的整数倍地址上;
二、基本变量类型所占大小
注:蓝色标记部分特别注意!!
| 数据类型 | ILP32(32位Linux系统) | LP64(大部分64位Linux系统) | LLP64(64位Windows系统) |
|---|---|---|---|
| char | 1 字节 | 1 字节 | 1 字节 |
| short | 2 字节 | 2 字节 | 2 字节 |
| int | 4 字节 | 4 字节 | 4 字节 |
| float | 4 字节 | 4 字节 | 4 字节 |
| long | 4 字节 | 8 字节 | 4 字节 |
| double | 8 字节 | 8 字节 | 8 字节 |
| long long | 8 字节 | 8 字节 | 8 字节 |
| 指针 point | 4 字节 | 8 字节 | 8 字节 |
| 枚举 enum | 4 字节 | 4 字节 | 4 字节 |
| 联合体 union | 取 union 中最大一个变量类型大小 | 取 union 中最大一个变量类型大小 | 取 union 中最大一个变量类型大小 |
ILP32 指 int,long、point 是 32 位。
LP64 指 long、point 是 64 位。
LLP64 指 long long、point 是 64 位。
三、影响内存对齐的情况
1、变量排列顺序。
2、__attribute__((packed)):取消变量对齐,按照实际占用字节数对齐(就是让变量之间排列紧密,不留缝隙)。(gcc才支持)详见例7。
3、#pragma pack (n):让变量强制按照 n 的倍数进行对齐,并会影响到结构体结尾地址的补齐(详见四的通常情况下关于结尾地址补齐的描述)。详见例8。
四、先说结论(重要)
下面的结论均为系统默认对齐规则下进行的:
通常情况:我总结的规律如下:结构体中间:各结构体的起始地址按照各个类型变量默认规则进行摆放,但除了 char 类型变量(详见一),char 类型变量一般遵循 2 的倍数地址开始存储。详见例2。结构体最后(重要):视结构体中最大类型是哪一个,如果是像 int 类型那样是 4 个字节的,并且结构体的结尾地址不满足 4 的倍数的话,向离最近的 4 的倍数地址补齐;如果是像 double 类型那样是 8 个字节的,并且结构体的结尾地址不满足 8 的倍数的话,向离最近的 8 的倍数地址补齐;以此类推。。。。
结构体嵌套:子结构体的成员变量起始地址要视子结构体中最大变量类型决定,比如 struct a 含有 struct b,b 里有 char,int,double 等元素,那 b 应该从 8 的整数倍开始存储。详见例5、例6。
含数组成员:比如 char a[5],它的对齐方式和连续写 5 个 char 类型变量是一样的,也就是说它还是按一个字节对齐。详见例1、例2、例3、例4、例5。
含联合体(union)成员:取联合体中最大类型的整数倍地址开始存储。详见例5。
个人总结能力有限,还是观看例子更容易理解:
五、举亿点例子(以下内容均实际运行过,质量保证)
没有特别标注就是 64 位!!
例1:研究结构体最后一个成员内存对齐问题1
struct stu1 { char a[18]; double b; char c; int d; short e;};Windows 10:48 字节 Ubuntu 18.04:48 字节
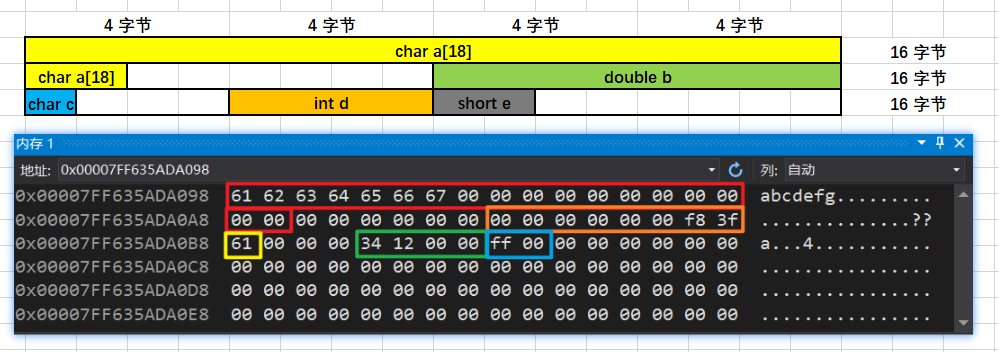
例2:研究结构体最后一个成员内存对齐问题2
struct stu1 { char a[18]; int b[3]; short c; char d; int e; short f;};Windows 10:44 字节 Ubuntu 18.04:44 字节
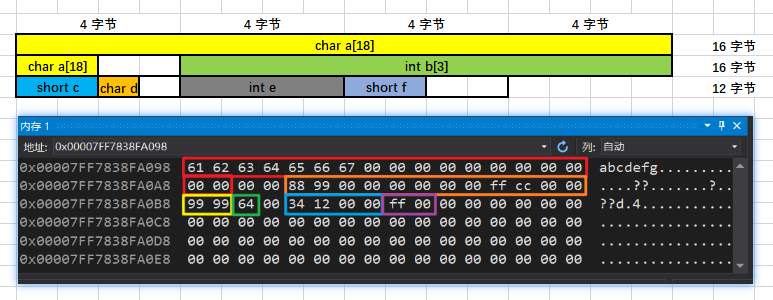
例3: 研究数组的内存对齐
struct stu1 { int a; char b[8]; float c; short d;};Windows 10:20 字节 Ubuntu 18.04:20 字节

例4:枚举 & 研究数组之间的内存对齐
enum DAY { MON = 1, TUE, WED, THU, FRI, SAT, SUN};struct stu1 { char a[5]; char b[3]; enum DAY day; int *c; short d; int e;};Windows 10:32 字节 Windows 10(32位):24 字节 Ubuntu 18.04:32 字节
64位:

32位:
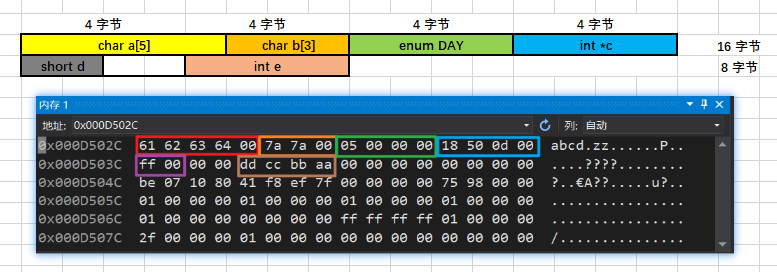
例5:结构体嵌套1
struct stu2 { char x; int y; double z; char v[6];};struct stu1 { union u1 { int a1; char a2[5]; }a; struct stu2 b; int c;};Windows 10:40 字节 Ubuntu 18.04:40 字节

例6:结构体嵌套2
struct stu2 { char x; int y; double z; char v[6];};struct stu1 { char a; struct stu2 b; int c;};Windows 10:40 字节 Ubuntu 18.04:40 字节
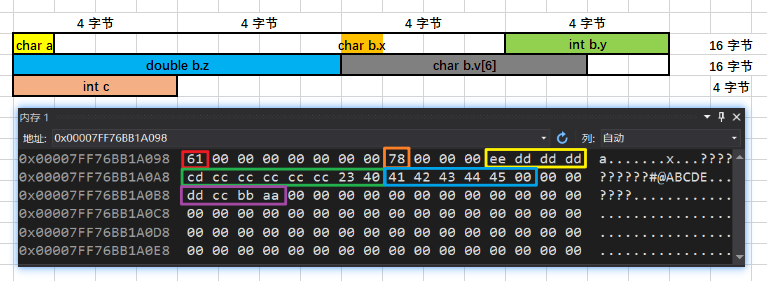
例7:__attribute__((packed))
由于 VS 和 VScode 均不支持 __attribute__((packed)) ,于是只使用 gcc 编译。
struct __attribute__((packed)) stu1 { // 取消内存对齐 char a; long b; short c; float d; int e;};Ubuntu 18.04:19 字节

例8:#pragma pack (n)
#pragma pack (2) // 强制以 2 的倍数进行对齐struct stu1 { short a; int b; long c; char d;};#pragma pack () // 取消强制对齐,恢复系统默认对齐Windows 10:12 字节 Ubuntu 18.04:16 字节
正常情况:
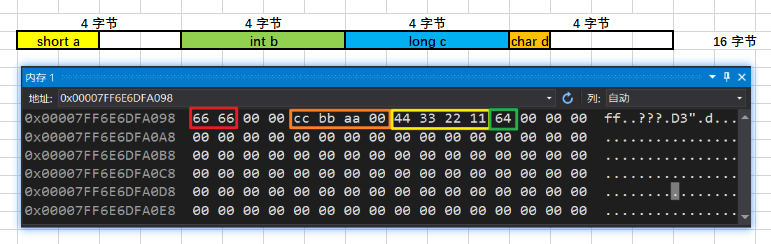
Windows 10:
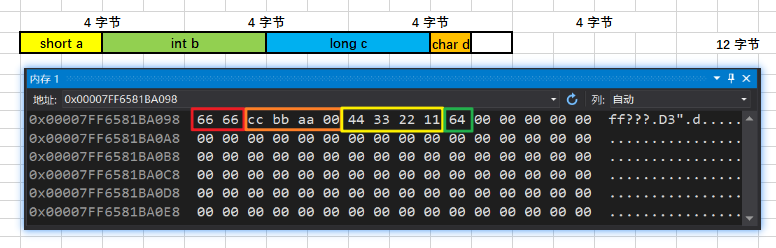
Ubuntu 18.04:
