Selenium可以驱动浏览器完成各种操作,比如模拟点击等。要想操作一个元素,首先应该识别这个元素。人有各种的特征(属性),我们可以通过其特征找到人,如通过身份证号、姓名、家庭住址。同理,一个元素会有各种的特征(属性),我们可以通过这个属性找到这对象。
目录
一、元素的概念
(一)什么是元素?
(二)查看元素信息
二、元素定位方法
(一)根据id定位
(二)根据name定位
(三)通过class name定位
(四)根据tag定位
(五)通过link text定位
(六)通过partial link text定位
(七)根据XPath定位
2.7.1绝对路径
2.7.2相对路径
(八)通过css selector定位
2.8.1 id选择器
2.8.2 class选择器
2.8.3 标签选择器
2.8.4 属性选择器
2.8.5 直接在浏览器复制
(九)定位方法的使用
2.9.1 定位方式选择
2.9.2 find_element和find_elements方法
三、元素定位的另一种写法
一、元素的概念
(一)什么是元素?
元素:由标签头 + 标签尾 + 标签头和标签尾包括的文本内容;
元素的信息就是指元素的标签名及元素的属性;
元素的层级结构就是指元素之间相互嵌套的层级结构;
元素定位最终就是通过元素的信息或者元素的层级结构来进行元素定位;
(二)查看元素信息
在谷歌浏览器中,选中元素,右键点击“检查”,即可在“Elements"中查看元素信息。
以百度首页搜索框为例,查看元素信息如下图所示:
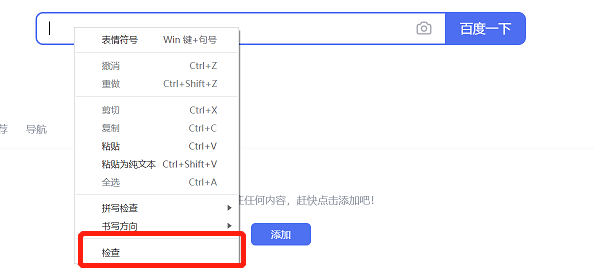
image-20220511102134911

image-20220510192728208
二、元素定位方法
webdriver 提供了一系列的对象定位方法,常用的有以下8种:
| 定位一个元素 | 定位多个元素 | 含义 |
|---|---|---|
| find_element_by_id | find_elements_by_id | 通过元素id定位 |
| find_element_by_name | find_elements_by_name | 通过元素name定位 |
| find_element_by_xpath | find_elements_by_xpath | 通过xpath表达式定位 |
| find_element_by_link_text | find_elements_by_link_text | 通过完整超链接定位 |
| find_element_by_partial_link_text | find_elements_by_partial_link_text | 通过部分链接定位 |
| find_element_by_tag_name | find_elements_by_tag_name | 通过标签定位 |
| find_element_by_class_name | find_elements_by_class_name | 通过类名进行定位 |
| find_element_by_css_selector | find_elements_by_css_selector | 通过css选择器进行定位 |
我们创建浏览器对象并访问百度首页,以百度首页为例,讲解如何定位元素。
from selenium import webdriverweb = webdriver.Chrome()web.get(r'https://www.baidu.com') (一)根据id定位
在HTML当中,id属性是唯一标识一个元素的属性,因此在selenium当中,通过id来进行元素的定位也作为首选。
百度搜索框的元素如图所示:

image-20220510192728208
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">元素定位:
element = web.find_element_by_id("kw") (二)根据name定位
在HTML当中,name属性和id属性的功能基本相同,只是name属性并不是唯一的,如果遇到没有id标签的时候,我们可以考虑通过name标签来进行定位。
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">元素定位:
element = web.find_element_by_name("wd") (三)通过class name定位
我们也可以基于class属性来定位元素。通常当我们看到有多个并列的元素如list表单,class用的都是共用同一个。
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">元素定位:
element = web.find_element_by_class_name('s_ipt')若class的值中有空格,则需要借助CSS Selector处理。
(四)根据tag定位
HTML是通过tag来定义一类功能的,比如input是输入,table是表格,tbody是表格主体等。每个元素其实就是一个tag,由于一个tag用来定义一类功能,一个网页往往有很多同类tag,所以很难通过tag去区分不同的元素。

image-20220510193305826
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">元素定位:
element = web.find_element_by_tag_name('input') 由于百度首页有很多标签名字都是”input",因此上述代码只会定位到网页的第一个“input”标签。
(五)通过link text定位
通过超链接的文本定位元素。
百度上方超链接”新闻“元素如图所示:

image-20220510195131010
百度上方超链接”新闻“元素元素html结构:
<a href="http://news.baidu.com" target="_blank" class="mnav c-font-normal c-color-t">新闻</a>元素定位:
element = web.find_element_by_link_text('新闻')(六)通过partial link text定位
有时候一个超链接的文本很长,我们如果全部输入,既麻烦,又显得代码很不美观,这时候我们就可以只截取一部分字符串,进行模糊匹配。
百度上方超链接”新闻“元素html结构:
<a href="http://news.baidu.com" target="_blank" class="mnav c-font-normal c-color-t">新闻</a>元素定位:
element = web.find_element_by_partial_link_text('闻')(七)根据XPath定位
Xpath是一种在XML和HTML文档中查找信息的语言,通过Xpath路径来定位元素的时候也是分绝对路径和相对路径。
2.7.1绝对路径
当我们想要描述某个地方时,我们常常用不同层次的节点名称串联起来,比如:你的收货地址是"江西省-南昌市-青山湖区-xx小区"。类似地,我们想要定位XML文档中某个节点时,也是这么层层递进。
绝对路径:表示页面元素在网页的HTML代码结构中,从根节点一层层地搜索到需要被定位的页面元素,绝对路径起始于正斜杠(/),每一步均被斜杠分割。
以百度搜索框元素为例,鼠标单机右键-Copy-Copy full XPath即可获取其XPath绝对路径
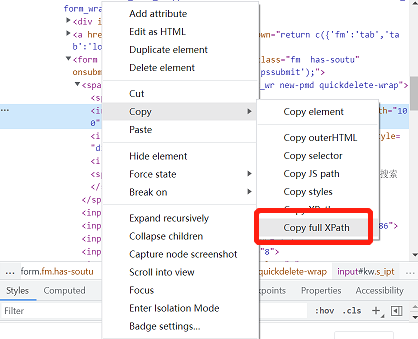
image-20220510211910536
xpath定位表达式:
/html/body/div[1]/div[2]/div[5]/div[1]/div/form/span[1]/inputPython通过xpath定位语句:
element = web.find_element_by_xpath('/html/body/div[1]/div[2]/div[5]/div[1]/div/form/span[1]/input')上述xpath定位表达式从html dom树的根节点(html节点)开始逐层查找,最后定位到“input”节点。
特点:路径唯一,但是容易受页面改动影响,即便页面代码结构只发生了微小的变化,也可能会造成原先有效的xpath定位表达式定位失败
2.7.2相对路径
相对路径:从匹配选择的当前节点开始选择文档中的节点,而不考虑它们的位置,起始于双斜杠(//)。
以百度搜索框元素为例,鼠标单机右键-Copy-Copy XPath即可获取其XPath相对路径
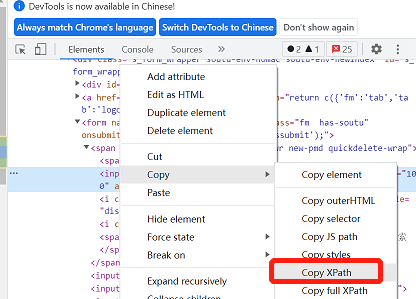
image-20220510211834245
xpath定位表达式:
//*[@id="kw"]Python通过xpath定位语句:
element = web.find_element_by_xpath('//*[@id="kw"]')相对路径的xpath定位表达式更加简洁,推荐使用相对路径的xpath表达式。
(八)通过css selector定位
在Selenium官网当中是更加推荐Css Selector()方法来进行页面元素的定位的,Css定位可以通过id选择器、class选择器、标签选择器和属性选择器。
2.8.1 id选择器
通过 # 来定义,通过元素的id属性来定位
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">元素定位:
element = web.find_element_by_css_selector("#kw") 2.8.2 class选择器
通过 .来定义,通过元素的class属性来定位
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">元素定位:
element = web.find_element_by_css_selector(".s_ipt") 2.8.3 标签选择器
通过标签的名字来定位元素
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">元素定位:
element = web.find_element_by_css_selector("input") 2.8.4 属性选择器
根据标签中的属性来定位元素, 格式: [属性名=”属性值”],或标签名[属性名=属性值]。如果属性是唯一的,那么标签名可以不用写。
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">元素定位:
element = web.find_element_by_css_selector('[id="kw"]') element = web.find_element_by_css_selector('input[id="kw"]') 2.8.4.1 定位带空格的复合class属性
定位带空格的复合class属性一般采用css selector定位方法。
以百度上方栏目元素为例,其class属性带有空格。
class="s-top-left-new s-isindex-wrap"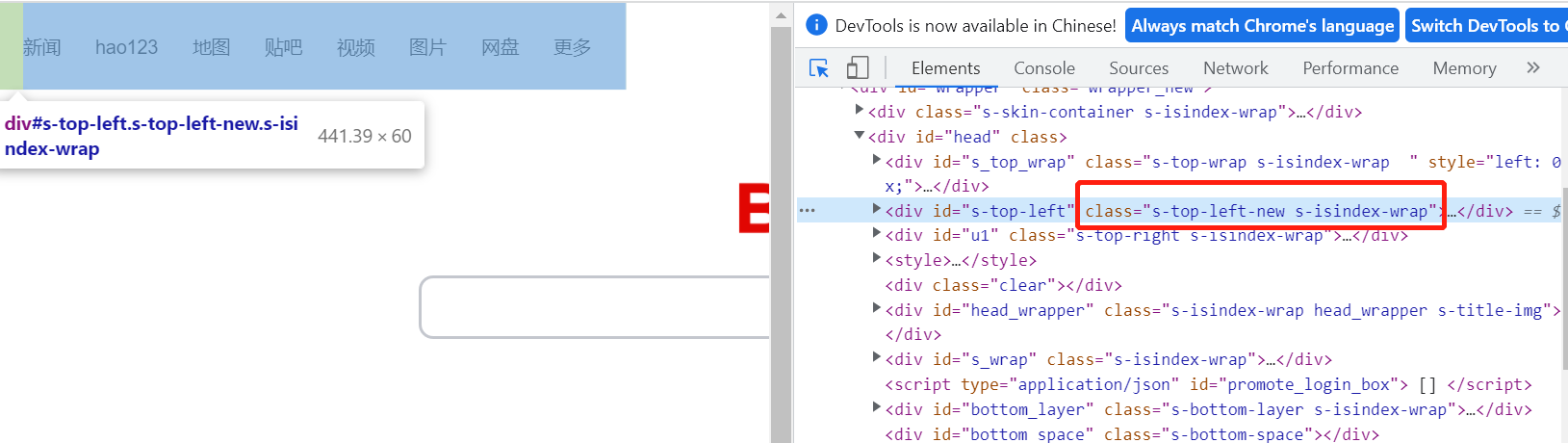
image-20220511115348420
class属性带空格,如果直接通过class属性定位是会报错的,需要通过css selector按class属性定位。
element=web.find_element_by_class_name('s-top-left-new s-isindex-wrap')直接通过class属性定位是会报错的。
no such element: Unable to locate element: {"method":"css selector","selector":".s-top-left-new s-isindex-wrap"} (Session info: chrome=99.0.4844.51)通过css selector按class属性定位,代码如下:
element=web.find_element_by_css_selector('[class="s-top-left-new s-isindex-wrap"]')2.8.5 直接在浏览器复制
css selector可以直接在浏览器中复制,鼠标单机右键-Copy-Copy selector即可获取。
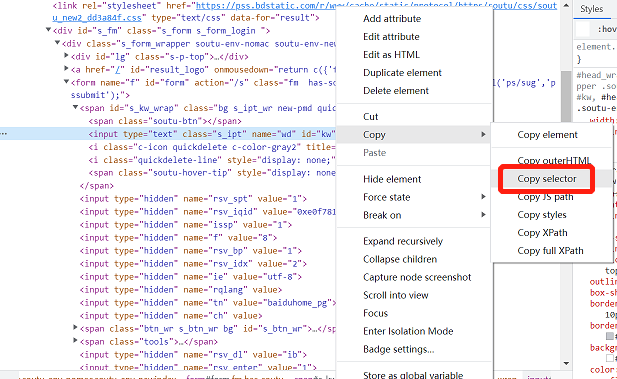
image-20220511102825357
(九)定位方法的使用
2.9.1 定位方式选择
• 当页面元素有id属性时,尽量用id来定位;
• 当有链接需要定位时,可以考虑link text或partial link text方式;
• 当要定位一组元素相同元素时,可以考虑用tag name或class name;
• css selector定位速度比较快,效率高。
• 一般id>name>css>XPath
2.9.2 find_element和find_elements方法
| find_element_by_xx | find_elements_by_xx | |
|---|---|---|
| 没有匹配到元素 | 执行报错 | 返回空列表 |
| 匹配到一个元素 | 返回元素 | 返回包含一个元素的列表 |
| 匹配到多个元素 | 返回第一个元素 | 返回包含所有匹配元素列表 |
三、元素定位的另一种写法
除了上述的8种定位方法,Selenium还提供了一个通用的方法find_element()和find_elements(),这个方法有两个参数:定位方式和定位值。
使用的时候需要导入By模块
from selenium.webdriver.common.by import By以定位一个元素为例,两种定位方法写法差异如下:
| 定位元素 | find_element_by_* | find_element() |
|---|---|---|
| 通过元素id定位 | find_element_by_id(x) | find_element(By.ID,x) |
| 通过元素name定位 | find_element_by_name(x) | find_element(By.NAME,x) |
| 通过xpath表达式定位 | find_element_by_xpath(x) | find_element(By.XPATH,x) |
| 通过完整超链接定位 | find_element_by_link_text(x) | find_element(By.LINK_TEXT,x) |
| 通过部分链接定位 | find_element_by_partial_link_text(x) | find_element(By.PARTIAL_LINK_TEXT,x) |
| 通过标签定位 | find_element_by_tag_name(x) | find_element(By.TAG_NAME,x) |
| 通过类名进行定位 | find_element_by_class_name(x) | find_element(By.CLASS_NAME,x) |
| 通过css选择器进行定位 | find_element_by_css_selector(x) | find_element(By.CSS_SELECTOR,x) |
定位多个元素,就是把上述element后面多了复数标识s,变为elements,其他操作一致。
以上的操作可以等同于以下:
from selenium.webdriver.common.by import Byelement = web.find_element(By.ID,'kw')element = web.find_element(By.NAME,'wd')element = web.find_element(By.CLASS_NAME,'s_ipt')element = web.find_element(By.TAG_NAME,'input')element = web.find_element(By.LINK_TEXT,'新闻')element = web.find_element(By.PARTIAL_LINK_TEXT,'闻')element = web.find_element(By.XPATH,'//*[@id="kw"]')element = web.find_element(By.CSS_SELECTOR,'#kw')element = web.find_element(By.CSS_SELECTOR,'[id="kw"]')element = web.find_element(By.CSS_SELECTOR,'input[id="kw"]')目前,由于selenium版本升级,使用find_element_by_*,会提示弃用警告,建议使用find_element()。
DeprecationWarning: find_element_by_* commands are deprecated. Please use find_element()警告错误提示不会影响代码的执行,可以忽略。
如果需要彻底解决,可以指定安装低版本的selenium,如安装3.3.0版本,Anaconda Prompt命令行输入:
pip install selenium==3.3.0