一、GCN的起源
曾经深度学习一直都是被几大经典模型给统治着,如CNN、RNN等等,它们无论再CV还是NLP领域都取得了优异的效果。
但是对于图结构的数据,无论是CNN还是RNN都无法解决或者效果不好。
(1)CV中的CNN:图像识别的对象是图片,是一个二维的结构,可以同CNN来提取图片的特征。CNN的核心在于kernel,它是一个小窗口,在图片上平移,通过卷积的方式来提取特征。这里的关键在于图片结构上的平移不变性:一个小窗口无论移动到图片的哪一个位置,其内部的结构都是一模一样的,因此CNN可以实现参数共享。这就是CNN的精髓所在。
(2)NLP中的RNN:自然语言处理的序列信息是一个一维的结构,RNN就是专门针对这些序列的结构而设计的,通过各种门的操作,使得序列前后的信息互相影响,从而很好地捕捉序列的特征。
这些的图片或者语言,都属于欧式空间的数据,因此才有维度的概念,欧式空间的数据的特点就是结构很规则。
但是现实生活中,其实有很多很多不规则的数据结构,典型的就是图结构,或称拓扑结构,如社交网络、化学分子结构、知识图谱等等;即使是语言,实际上其内部也是复杂的树形结构,也是一种图结构;而像图片,在做目标识别的时候,我们关注的实际上只是二维图片上的部分关键点,这些点组成的也是一个图的结构。
图结构数据特点:图结构数据十分不规则的,可以认为是无限维的一种数据,所以它没有平移不变性。每一个节点的周围结构可能都是独一无二的,这种结构的数据,就让传统的CNN、RNN瞬间失效。所以很多学者从上个世纪就开始研究怎么处理这类数据了。这里涌现出了很多方法,例如GNN、DeepWalk、node2vec等等,GCN只是其中一种。
GCN,图卷积神经网络,实际上跟CNN的作用一样,就是一个特征提取器,只不过它的对象是图数据。GCN的目的就是一个学习图结构 G = ( V , E ) \mathcal{G}=(\mathcal{V},\mathcal{E}) G=(V,E)特征的映射函数,他的输入是:
(1)A feature description x i x_i xi for every node i i i; summarized in a N×D feature matrix X (N: number of nodes, D: number of input features)
(2)A representative description of the graph structure in matrix form; typically in the form of an adjacency matrix A (or some function thereof)
输出是一个node-level的output Z(它是一个N×F的特征矩阵,F是每个节点的输出特征数量)。
每个神经网络结构就可以被写为一个non-linear function
H ( l + 1 ) = f ( H ( l ) , A ) H^{(l+1)}=f(H^{(l)},A) H(l+1)=f(H(l),A)
其中, H ( 0 ) = X H^{(0)}=X H(0)=X和 H ( L ) = Z H^{(L)}=Z H(L)=Z,(L是层的个数)。然后,具体的模型只在如何选择和参数化映射函数 f ( . , . ) f(.,.) f(.,.)方面有所不同。
GCN精妙地设计了一种从图数据中提取特征的方法,从而让我们可以使用这些特征去对图数据进行节点分类(node classification)、图分类(graph classification)、边预测(link prediction),还可以顺便得到图的嵌入表示(graph embedding),可见用途广泛。
GCN原理:对于给定的一批图数据,其中有N个节点(node),每个节点都有D维度特征,组成特征矩阵X=N×D,然后各个节点之间的关系也会形成一个N×N维的矩阵A,也称为邻接矩阵(adjacency matrix)。X和A便是GCN模型的输入。
GCN也是一个神经网络层,用以下这个公式就可以很好地提取图的特征,即,GCN的层与层之间的传播方式是:
H ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) W ( l ) ) H^{(l+1)}=\sigma(\tilde D^{-\frac{1}{2}}\tilde A\tilde D^{-\frac{1}{2}}H^{(l)}W^{(l)}) H(l+1)=σ(D~−21A~D~−21H(l)W(l))
其中:
(1) A ~ = A + I \tilde A=A+I A~=A+I, I I I是单位矩阵
(2) D ~ \tilde D D~是 A ~ \tilde A A~的度矩阵(degree matrix)
(3)H是每一层的特征,对于输入层的话,H就是X
(4)σ是非线性激活函数
作者Thomas Kipf在GRAPH CONVOLUTIONAL NETWORKS给出一个由简入繁的过程来解释上面公式:
每一层GCN的输入都是邻接矩阵A和node的特征H,直接做一个内积,再乘一个参数矩阵W,然后激活一下,就相当于一个简单的神经网络层:
f ( H ( l ) , A ) = σ ( A H ( l ) W ( l ) ) f(H^{(l)},A)=\sigma( AH^{(l)}W^{(l)}) f(H(l),A)=σ(AH(l)W(l))
实验证明,即使就这么简单的神经网络层,就已经很强大了。这个简单模型就是正常的神经网络操作。
但是这个简单模型有几个局限性:
(1)只使用A的话,由于A的对角线上都是0,所以在和特征矩阵H相乘的时候,只会计算一个node的所有邻居的特征的加权和,该node自己的特征却被忽略了。因此,可以做一个小小的改动,给A加上一个单位矩阵 I I I ,这样就让对角线元素变成 I I I了。
(2)A是没有经过归一化的矩阵,这样与特征矩阵相乘会改变特征原本的分布,产生一些不可预测的问题。所以对A做一个标准化处理。首先让A的每一行加起来为1,我们可以乘以一个D的逆,D就是度矩阵。可以进一步把D的拆开与A相乘,得到一个对称且归一化的矩阵 D ~ − 1 2 A ~ D ~ − 1 2 \tilde D^{-\frac{1}{2}}\tilde A\tilde D^{-\frac{1}{2}} D~−21A~D~−21 。
通过对上面两个局限的改进,便得到了最终的层特征传播公式:
f ( H ( l ) , A ) = σ ( D ^ − 1 2 A ^ D ^ − 1 2 H ( l ) W ( l ) ) f(H^{(l)},A)=\sigma(\hat D^{-\frac{1}{2}}\hat A\hat D^{-\frac{1}{2}}H^{(l)}W^{(l)}) f(H(l),A)=σ(D^−21A^D^−21H(l)W(l))
其中, A ^ = A + I \hat A=A+I A^=A+I,其中, I I I是单位矩阵(identity matrix), D ^ \hat D D^是 A ^ \hat A A^的对角节点度矩阵
公式中与对称归一化拉普拉斯矩阵十分类似,而在谱图卷积的核心就是使用对称归一化拉普拉斯矩阵,这也是GCN的卷积叫法的来历。
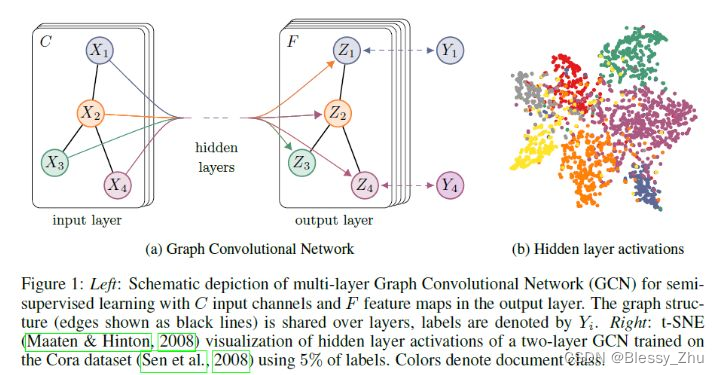
上图中的GCN输入一个图,通过若干层GCN每个node的特征从X变成了Z,但是,无论中间有多少层,node之间的连接关系,即A,都是共享的。
假设构造一个两层的GCN,激活函数分别采用ReLU和Softmax,则整体的正向传播的公式为:
Z = f ( X , A ) = s o f t m a x ( A ^ R e L U ( A ^ X W ( 0 ) ) W ( 1 ) ) Z=f(X,A)=softmax(\hat A ReLU(\hat AXW^{(0)})W^{(1)}) Z=f(X,A)=softmax(A^ReLU(A^XW(0))W(1))
最后,针对所有带标签的节点计算cross entropy损失函数:
L = − ∑ l ∈ Y L ∑ f = 1 F Y l f l n Z l f \mathcal{L}=-\sum_{l\in\mathcal{Y}_L}\sum_{f=1}^F Y_{lf}lnZ_{lf} L=−l∈YL∑f=1∑FYlflnZlf
就可以训练一个node classification的模型了。由于即使只有很少的node有标签也能训练,作者称他们的方法为半监督分类。当然,也可以用这个方法去做graph classification、link prediction,只是把损失函数给变化一下即可。
注:本文参考博客最通俗易懂的图神经网络(GCN)原理详解