用户中心是一个典型的读多写少系统,可以说我们大部分的系统都属于这种类型,而这类系统通过缓存就能获得很好的性能提升。并且在流量增大后,用户中心通常是系统改造中第一个要优化的模块,因为它常常和多个系统重度耦合,所以梳理这个模块对整个系统后续的高并发改造非常重要。
如果我们从数据结构出发,先对一些场景进行改造,然后再去做缓存,会让之后的改造变得简单很多。所以先梳理数据库结构,再对系统进行高并发改造是很有帮助的。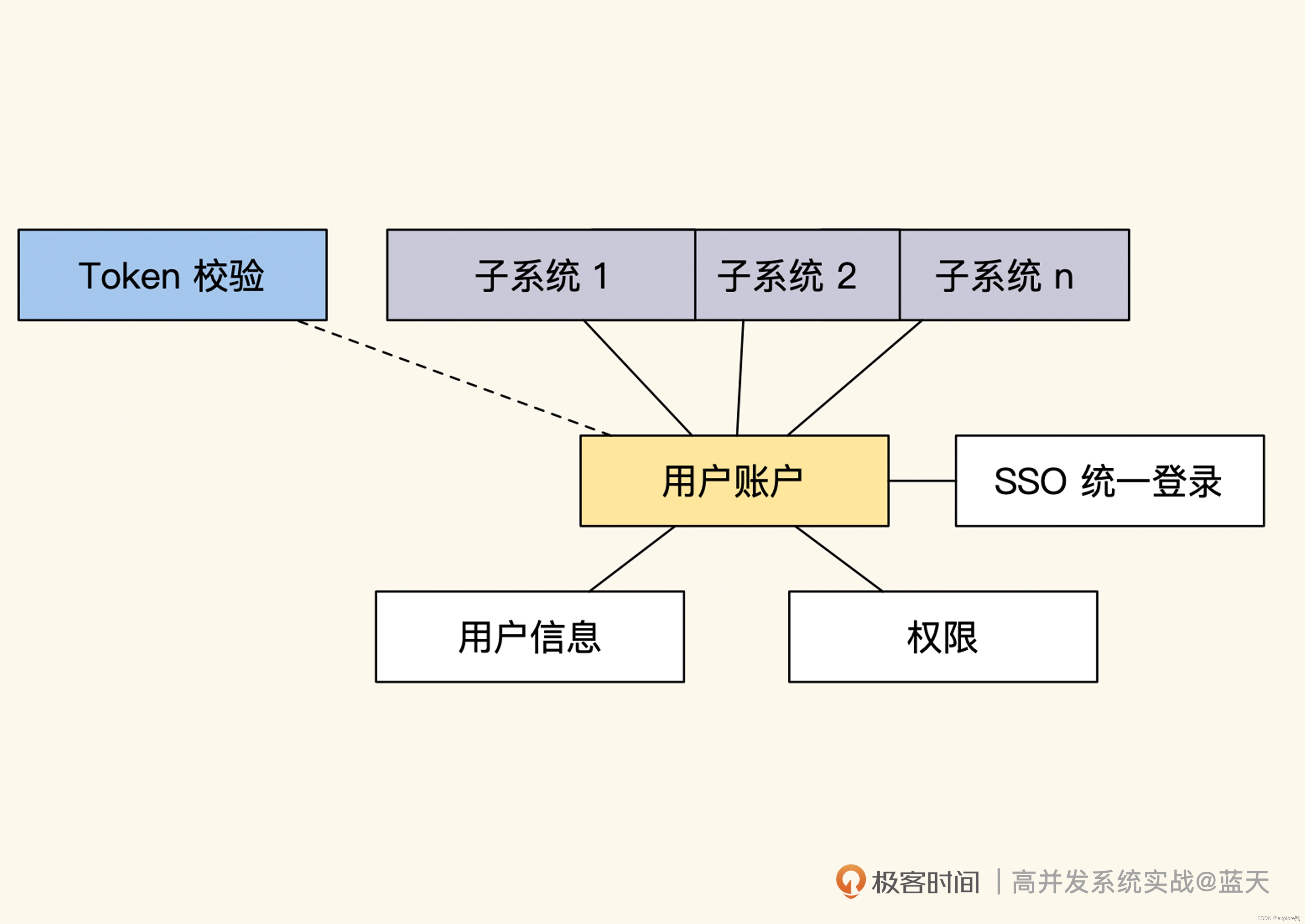
用户中心的主要功能是维护用户信息、用户权限和登录状态,它保存的数据大部分都属于读多写少的数据。用户中心常见的优化方式主要是将用户中心和业务彻底拆开,不再与业务耦合,并适当增加缓存来提高系统性能。
一些表优化的思路
精简数据表。比如账户表只保存用户名和密码,这样即使数据量很大,查询性能也不错。不过你要注意,精简数据量虽然能换来更好的响应速度,但不提倡过度设计。因为表字段如果缺少冗余会导致业务实现更为繁琐,比如账户表如果把昵称和头像删减掉,我们每次登录就需要多读取一次数据库,并且需要一直关注账户表的缓存同步更新。
数据归类整理
数据主要有四种:实体对象主表、辅助查询表、实体关系和历史数据,不同类型的数据所对应的缓存策略是不同的。
实体对象表是适合放在缓存中的。实体数据是我们业务的主要承载体,当我们找到实体主体的时候,就可以根据这个主体在缓存中查到所有和它有关联的数据,来服务用户。
实体辅助表
为了精简数据且方便管理,我们经常会根据不同用途对主表拆分,常见的方式是做纵向表拆分。
纵向表拆分的目的一般有两个,一个是把使用频率不高的数据摘出来。
辅助表的另一个用途是辅助查询,当原有业务数据结构不能满足其他维度的实体查询时,可以通过辅助表来实现。比如用户账号表为主体用于做用户登陆使用,而辅助信息表保存家庭住址、省份、微信、邮编等平时不会展示的信息。
对于实体关系表可以将M:n拆分一下避免依赖维护困难。
动作历史数据表记录的是数据实体的动作或状态变化过程,比如用户登陆日志、用户积分消费获取记录等。这类数据会随着时间不断增长,它们一般用于记录、展示最近信息,不建议用在业务的实时统计计算上。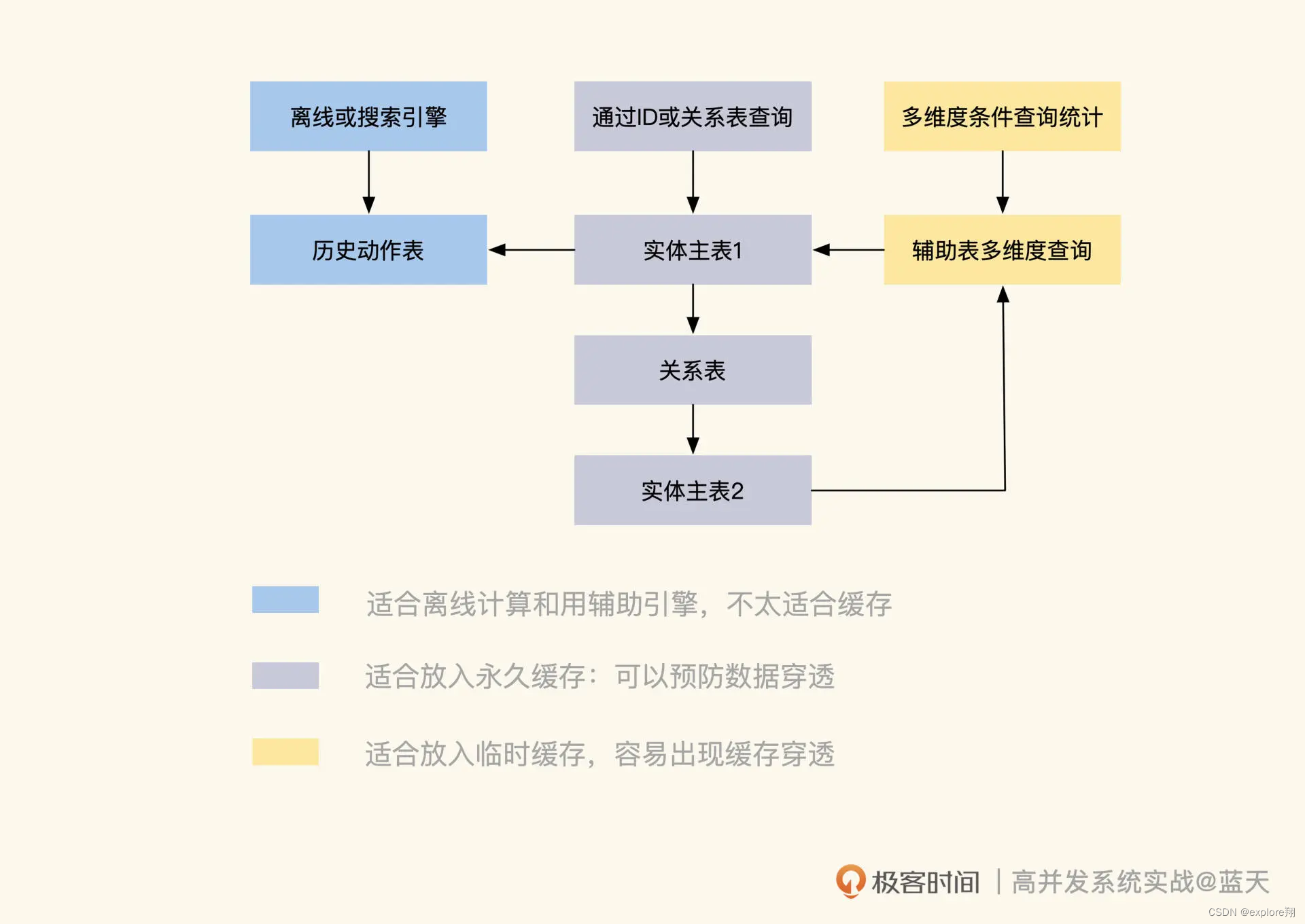
总结:
能够通过 ID 快速匹配的实体,以及通过关系快速查询的数据,适合放在长期缓存当中;
通过组合条件筛选统计的数据,也可以放到临时缓存,但是更新有延迟;
数据增长量大或者跟设计初衷不一样的表数据,这种不适合、也不建议去做做缓存。
二、缓存性价比和缓存一致性问题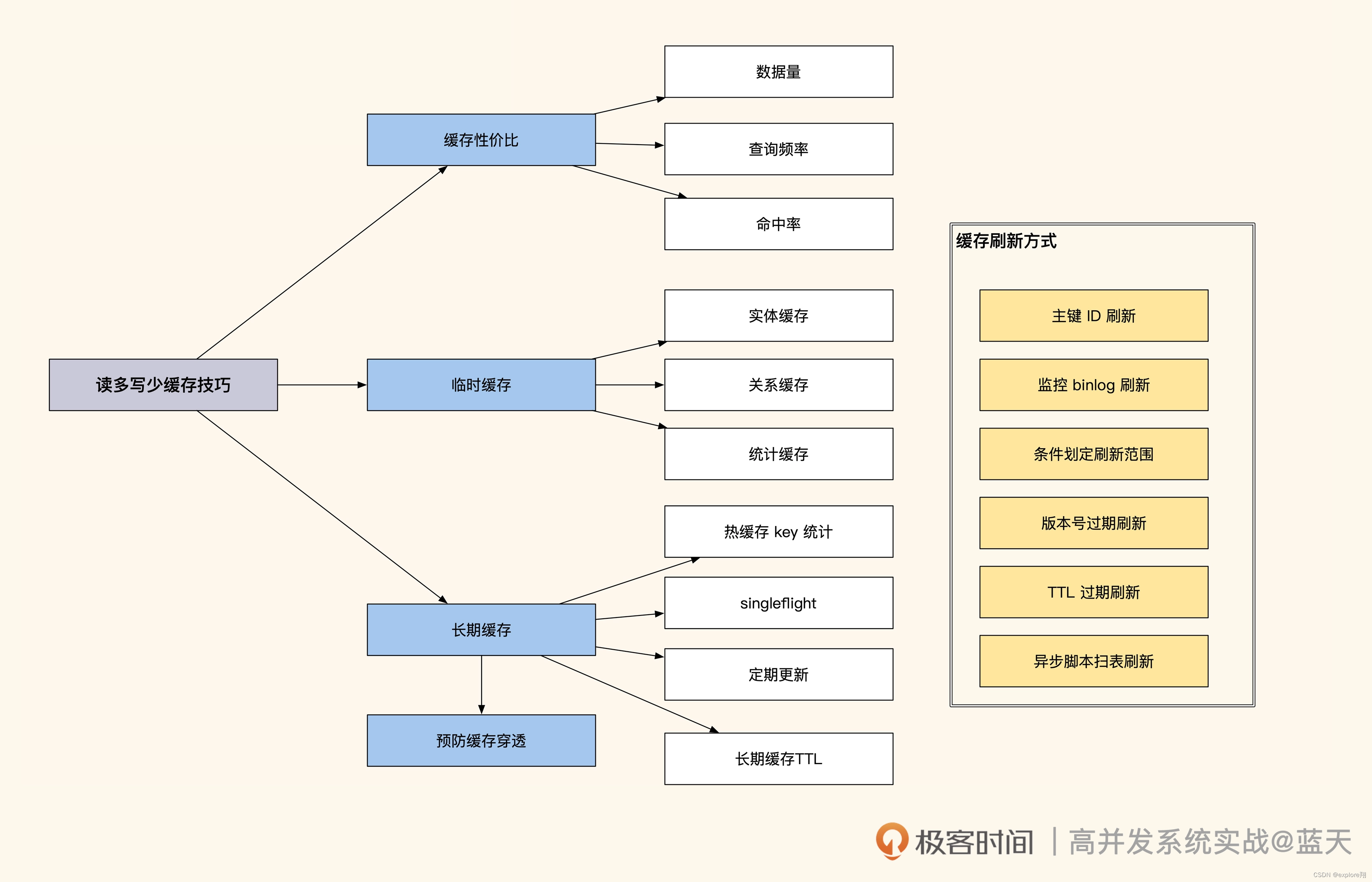
缓存可以滥用吗?
我们一开始肯定想把实体表(账号密码)放到缓存中。但是这些信息只会在登录时用到。用户即使频繁登录,也不会造成太大的流量冲击。我们需要评估缓存是否有效,一般来说,只有热点数据放到缓存才更有价值。
临时热缓存
我们把目标放到会被高频查询的信息上,也就是用户信息。用户信息的使用频率很高,在很多场景下会被频繁查询展示,比如我们在论坛上看到的发帖人头像、昵称、性别等,这些都是需要频繁展示的数据,不过这些数据的总量很大,全部放入缓存很浪费空间。对于这种数据,我建议使用临时缓存方式,就是在用户信息第一次被使用的时候,同时将数据放到缓存当中,短期内如果再次有类似的查询就可以快速从缓存中获取
// 尝试从缓存中直接获取用户信息userinfo, err := Redis.Get("user_info_9527")if err != nil { return nil, err}//缓存命中找到,直接返回用户信息if userinfo != nil { return userinfo, nil}//没有命中缓存,从数据库中获取userinfo, err := userInfoModel.GetUserInfoById(9527)if err != nil { return nil, err}//查找到用户信息if userinfo != nil { //将用户信息缓存,并设置TTL超时时间让其60秒后失效 Redis.Set("user_info_9527", userinfo, 60) return userinfo, nil}// 没有找到,放一个空数据进去,短期内不再问数据库// 可选,这个是用来预防缓存穿透查询攻击的Redis.Set("user_info_9527", "", 30)return nil, nil这种临时缓存适合表中数据量大,但热数据少的情况,可以降低热点数据的压力。
长期热数据缓存
当 TTL 到期时,如果大量缓存请求没有命中,透传的流量会不会打沉我们的数据库?这其实就是行业里常提到的缓存击穿问题,如果缓存出现大规模并发穿透,那么很有可能导致我们服务宕机。不过,要想实现长期缓存,就需要我们人工做更多的事情来保持缓存和数据表数据的一致性。
这里介绍一下缓存穿透,缓存击穿,缓存雪崩以及解决方案
缓存穿透就是查询一个缓存和数据库都不存在的数据,这样的话就直接透过缓存,直接查库,返回空。数据库压力很大。解决办法:缓存空对象。当数据库查不到时就在缓存中缓存一个空对象,设置过期时间。下次再请求就直接在缓存拿到。缺点是缓存空间占用问题,以及数据不一致问题,即使设置了过期时间也会导致这段时间的不一致。第二种就是布隆过滤器。m位的数组初始化0和n个哈希函数,一个Key经过哈希函数映射让n个位变为1。下次有新元素看看key映射后是不是都是1,不是说明不存在直接返回空,是说明存在走缓存。缺陷是判断存在时可能误判,因为哈希冲突,不存在一定是不存在的。第二是删除元素比较困难,因为会把其他key的元素变成0。另外我感觉key越多,产生哈希冲突的可能性越大。
缓存击穿:某个热点数据过期后,大量的请求穿过缓存到达数据库,压力很大。解决方案:设置Key永不过期,或者启动一个任务定期将该数据送入缓存。第二种是加锁,当大量请求查询同一个key,只有一个请求获取锁,查询数据库放入缓存,解锁,其他请求再从缓存拿数据。但是感觉这样很影响并发性,请求延迟。
缓存雪崩:缓存中大量的key同时过期,或者redis直接宕机,压力很大。
解决方案就是每个Key过期时间打散,均匀分布。redis故障可以采用主从架构、哨兵机制、集群等高可用架构。
我们可以结合长期热缓存和临时缓存。
如果是热key,缓存查不到,直接返回空。如果不是热key,就查询临时缓存,找不到的话,查数据库,更新临时缓存。更新时优化是锁,只有一个线程更新,其他线程等待1秒,再查缓存。这样可以保证后端不会有多个线程读取同一条数据,从而冲垮缓存和数据库服务(缓存的写并发没有读性能那么好)
另外,热key是会更新的。来自于统计一段时间内数据访问流量,计算得出的热点数据。那长期缓存的更新会异步脚本去定期扫描热缓存列表,通过这个方式来主动推送缓存,同时把 TTL 设置成更长的时间,来保证新的热数据缓存不会过期。当这个 key 的热度过去后,热缓存 key 就会从当前 set 中移除,腾出空间给其他地方使用。
缓存一致性问题
临时缓存是有 TTL 的,如果 60 秒内修改了用户的昵称,缓存是不会马上更新的。最糟糕的情况是在 60 秒后才会刷新这个用户的昵称缓存,显然这会给系统带来一些不必要的麻烦。
单条实体数据缓存刷新
单条实体数据缓存更新是最简单的一个方式,比如我们缓存了 9527 这个用户的 info 信息,当我们对这条数据做了修改,我们就可以在数据更新时同步更新对应的数据缓存:整体来讲就是先更新数据库,再识别出被修改数据的 ID,然后根据 ID 删除被修改的数据缓存,等下次请求到来时,再把最新的数据更新到缓存中,这样就会有效减少并发操作把脏数据带入缓存的可能性。
关系型和统计型数据缓存刷新
这种刷新较比较复杂。因为这些统计是由多条数据计算而成的。当我们对这类数据更新缓存时,很难识别出需要刷新哪些关联缓存。
我们可以采用人工编码维护。比较麻烦,还要考虑新增数据关联的ID等。除了人工维护缓存外,还有一种方式就是通过订阅数据库来找到 ID 数据变化。如下图,我们可以使用 Maxwell 或 Canal,对 MySQL 的更新进行监控。(这样变更信息会推送到 Kafka 内,我们可以根据对应的表和具体的 SQL 确认更新涉及的数据 ID,然后根据脚本内设定好的逻辑对相 关 key 进行更新。例如用户更新了昵称,那么缓存更新服务就能知道需要更新 user_info_9527 这个缓存,同时根据配置找到并且删除其他所有相关的缓存。)
如果我们表内的数据更新很少,那么可以采用版本号缓存设计。这个方式比较狂放:一旦有任何更新,整个表内所有数据缓存一起过期
思考?布隆过滤器误判和无法删除元素的机制怎么改进?
可以考虑用一个表记录误判的那些元素,把它空对象计入缓存。因为误判的概率小,所以数量不会很多。当布隆判断完,再让这个表判断。代价是建表查表的代价。
也可以增加哈希函数,这样误判概率变小。不过计算代价变大。
删除元素机制可以加一个过期时间一起缓存,到期就删除。
好像有一种布谷鸟过滤器,可以解决这些问题。
如何降低用户中心鉴权时的流量压力?
答案是token技术。
传统的 Session 方式是把用户的登录信息通过 SessionID 统一缓存到服务端中,然后客户端以cookie的方式缓存在客户端,客户端和子系统每次请求都需要到用户中心服务器去“提取”用户信息(比如密码等),这就会导致用户中心的流量很大,所有业务都很依赖用户中心。
为了降低用户中心的流量压力,同时让各个子系统与用户中心脱耦,我们采用信任“签名”的 token,**把用户信息加密发放到客户端,让客户端本地拥有这些信息。而子系统只需通过签名算法对 token 进行验证,就能获取到用户信息。**这种方式的核心是把用户信息放在服务端外做传递和维护,以此解决用户中心的流量性能瓶颈。此外,通过定期更换 token,用户中心还拥有一定的用户控制能力,也加大了破解难度,可谓一举多得。
其实用布隆过滤器也是类似的思想,把一些东西放在外面,简化系统的压力。
缓存一致性问题
缓存和数据库,无论先处理谁,只要后者有延迟/失败,都会导致不一致的情况,这也正是缓存不一致的根本原因所在。所有解决方案和讨论都是围绕这一点来进行的。
最差的就是先写缓存再写数据库。如果写完缓存,数据库写失败,那么缓存的数据就是脏数据,不行。
先写数据库,再写缓存。问题又来了,写数据库成功,但写缓存失败了,依然会造成缓存脏数据的问题。但写缓存失败比写数据库失败的概率要小很多了(因为数据库可能有加锁、外键约束、超时等机制限制),所以此方案要比第一种方案好一点。在高并发场景中,如果多个线程同时执行先写数据库,再写缓存的操作,可能会出现数据库是新值,而缓存中是旧值,两边数据不一致的情况。
既然更新缓存会有浪费系统资源等问题,那就直接删除缓存来代替更新缓存呢?
先删缓存,再写数据库。也会造成不一致的问题。
延迟双删:写完数据库后,再删除一次。
该方案有个非常关键的地方是:第二次删除缓存,并非立马就删,而是要在一定的时间间隔之后。sleep的时间要对业务读写缓存的时间做出评估,sleep时间大于读写缓存的时间即可。(为什么要延迟,如果旧的请求还没来得及把旧值写到缓存,新的请求就删除旧值,没有意义的操作)
再结合上文的,对于关系统计查询的不一致,可以用canal来辅助。
下面还有机房双活,机房之间的数据同步常常会因为网络延迟或数据冲突而停止,最终导致两个机房的数据不一致。(必须实现数据同步,阿里有OTTER)
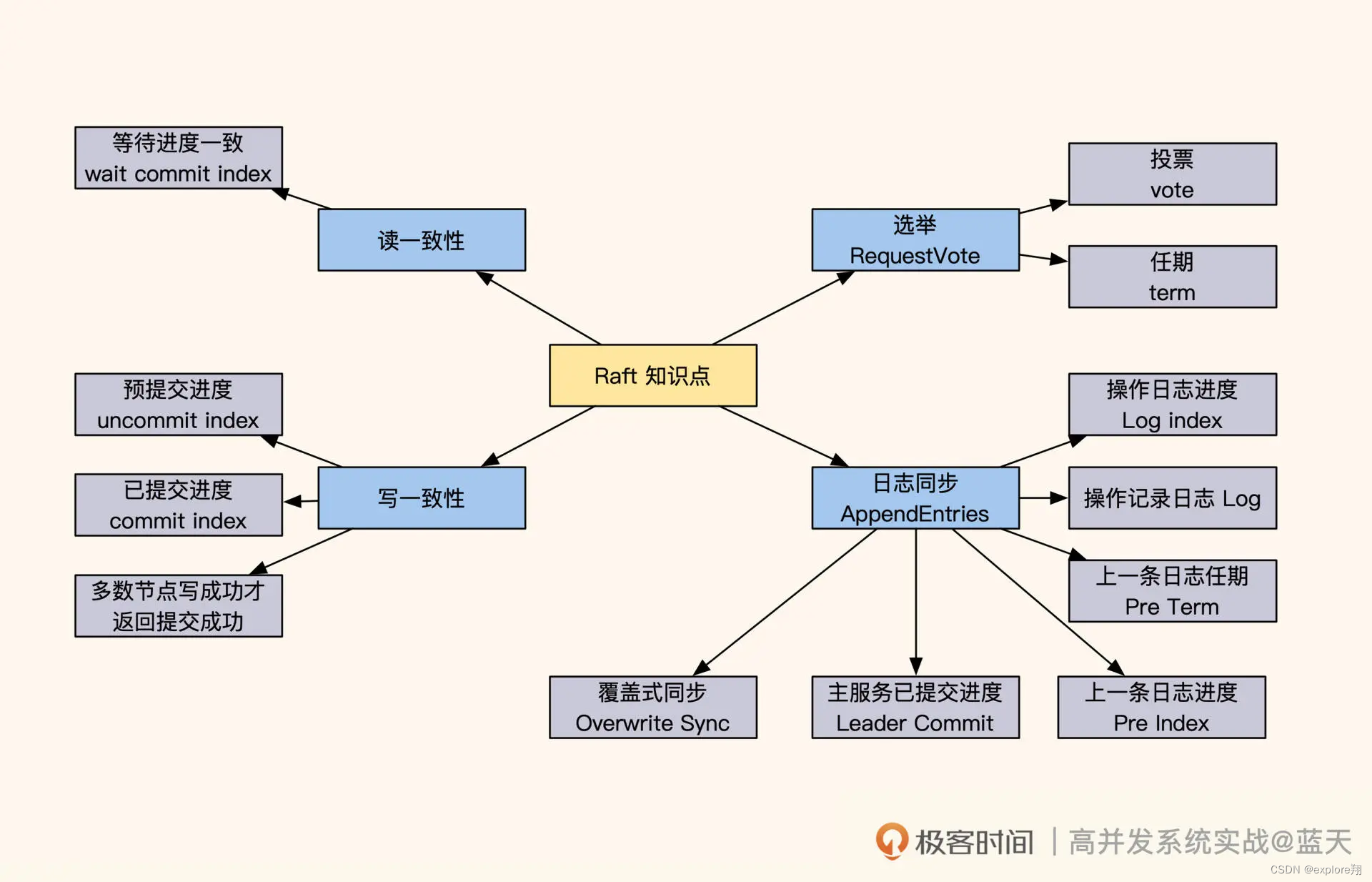
共识Raft:如何保证多机房数据的一致性?
但如果业务对“事务 + 强一致”的要求极高,比如库存不允许超卖,那我们通常只有两种选择:一种是将服务做成本地服务,但这个方式并不适合所有业务;另一种是采用多机房,但需要用分布式强一致算法保证多个副本的一致性。相比 Paxos,Raft 不仅更容易理解,还能保证数据操作的顺序,因此在分布式数据服务中被广泛使用,像 etcd、Kafka 这些知名的基础组件都是用 Raft 算法实现的。可以说了解了 Raft,就相当于了解了分布式强一致性数据服务的半壁江山。
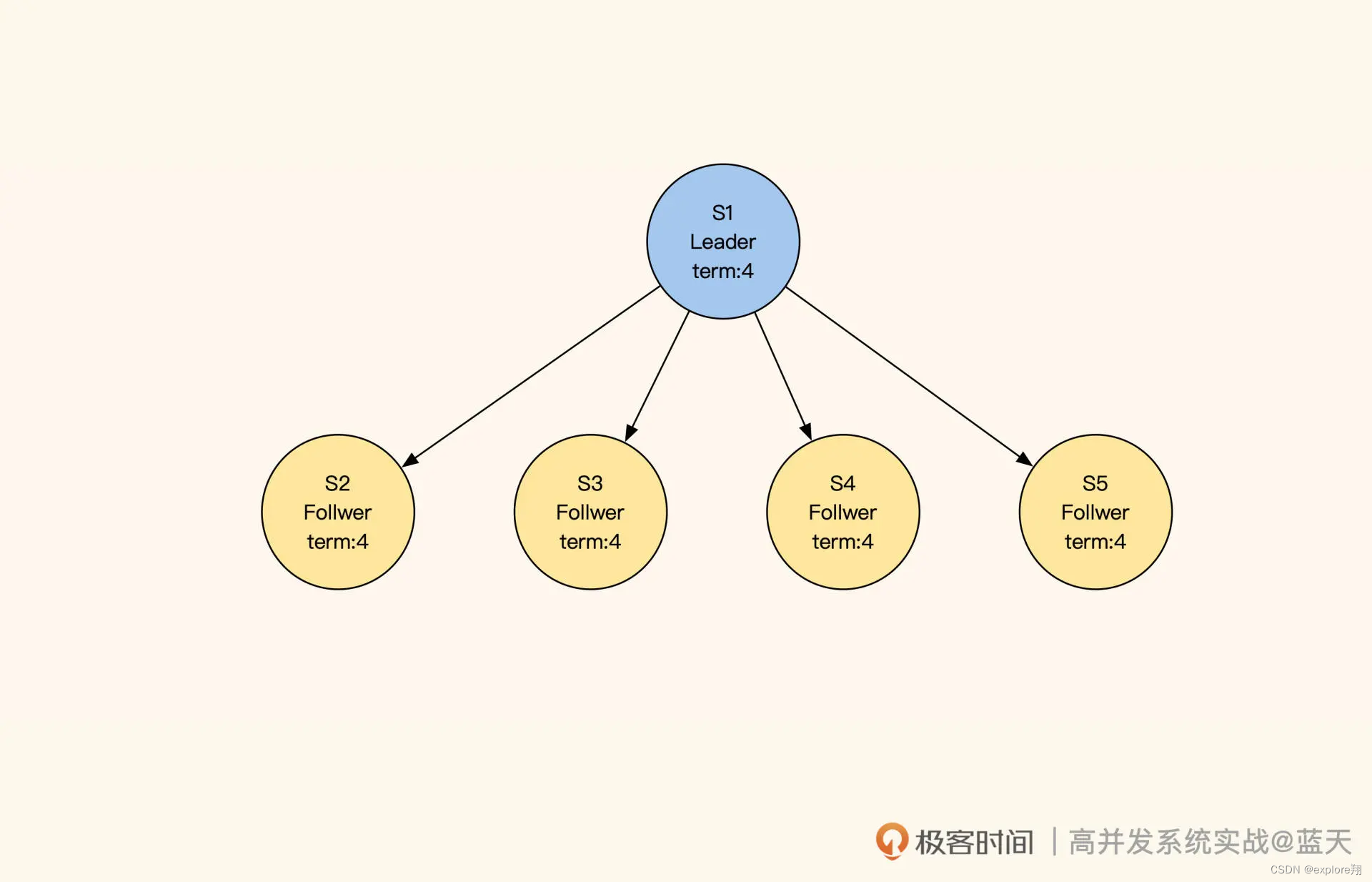
我们启动五个 Raft 分布式数据服务:S1、S2、S3、S4、S5,
每个节点都有以下三种状态:
Leader:负责数据修改,主动同步修改变更给 Follower;
Follower:接收 Leader 推送的变更数据;
Candidate:集群中如果没有 Leader,那么进入选举模式。
如果集群中的 Follower 节点在指定时间内没有收到 Leader 的心跳,那就代表 Leader 损坏,集群无法更新数据。这时候 Follower 会进入选举模式,在多个 Follower 中选出一个 Leader,保证一组服务中一直存在一个 Leader,同时确保数据修改拥有唯一的决策进程。
那 Leader 服务是如何选举出来的呢?进入选举模式后,这 5 个服务会随机等待一段时间。等待时间一到,当前服务先投自己一票,并对当前的任期“term”加 1 (上图中 term:4 就代表第四任 Leader),然后对其他服务发送 RequestVote RPC(即请求投票)进行拉票。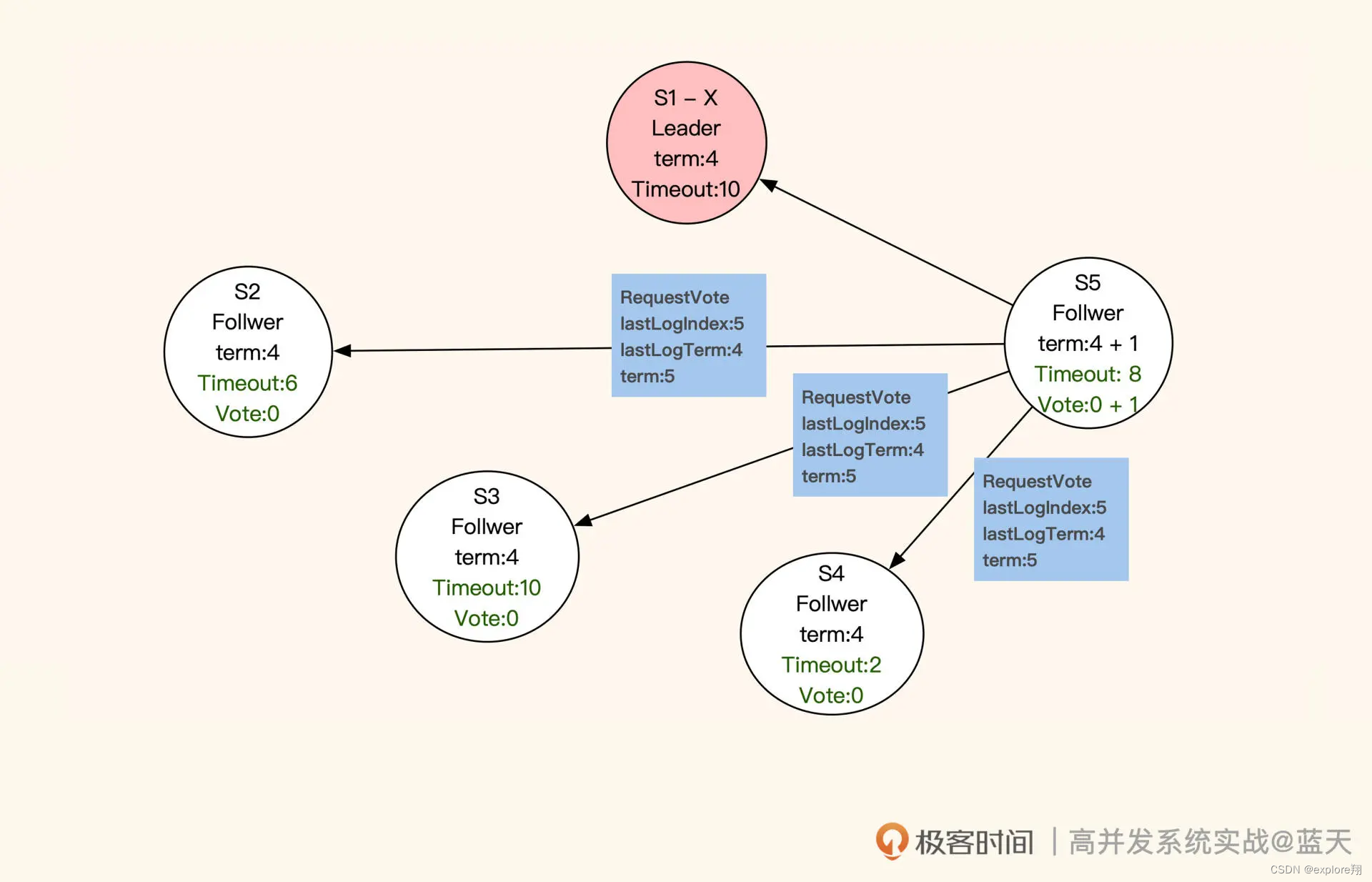
收到投票申请的服务,并且申请服务(即“发送投票申请的服务”)的任期和同步进度都比它超前或相同,那么它就会投申请服务一票,并把当前的任期更新成最新的任期。同时,这个收到投票申请的服务不再发起投票,会等待其他服务邀请。
注意,每个服务在同一任期内只投票一次。如果所有服务都没有获取到多数票(三分之二以上服务节点的投票),就会等当前选举超时后,对任期加 1,再次进行选举。最终,获取多数票且最先结束选举倒计时的服务会被选为 Leader。
被选为 Leader 的服务会发布广播通知其他服务,并向其他服务同步新的任期和其进度情况。同时,新任 Leader 会在任职期间周期性发送心跳,保证各个子服务(Follwer)不会因为超时而切换到选举模式。在选举期间,若有服务收到上一任 Leader 的心跳,则会拒绝(如下图 S1)。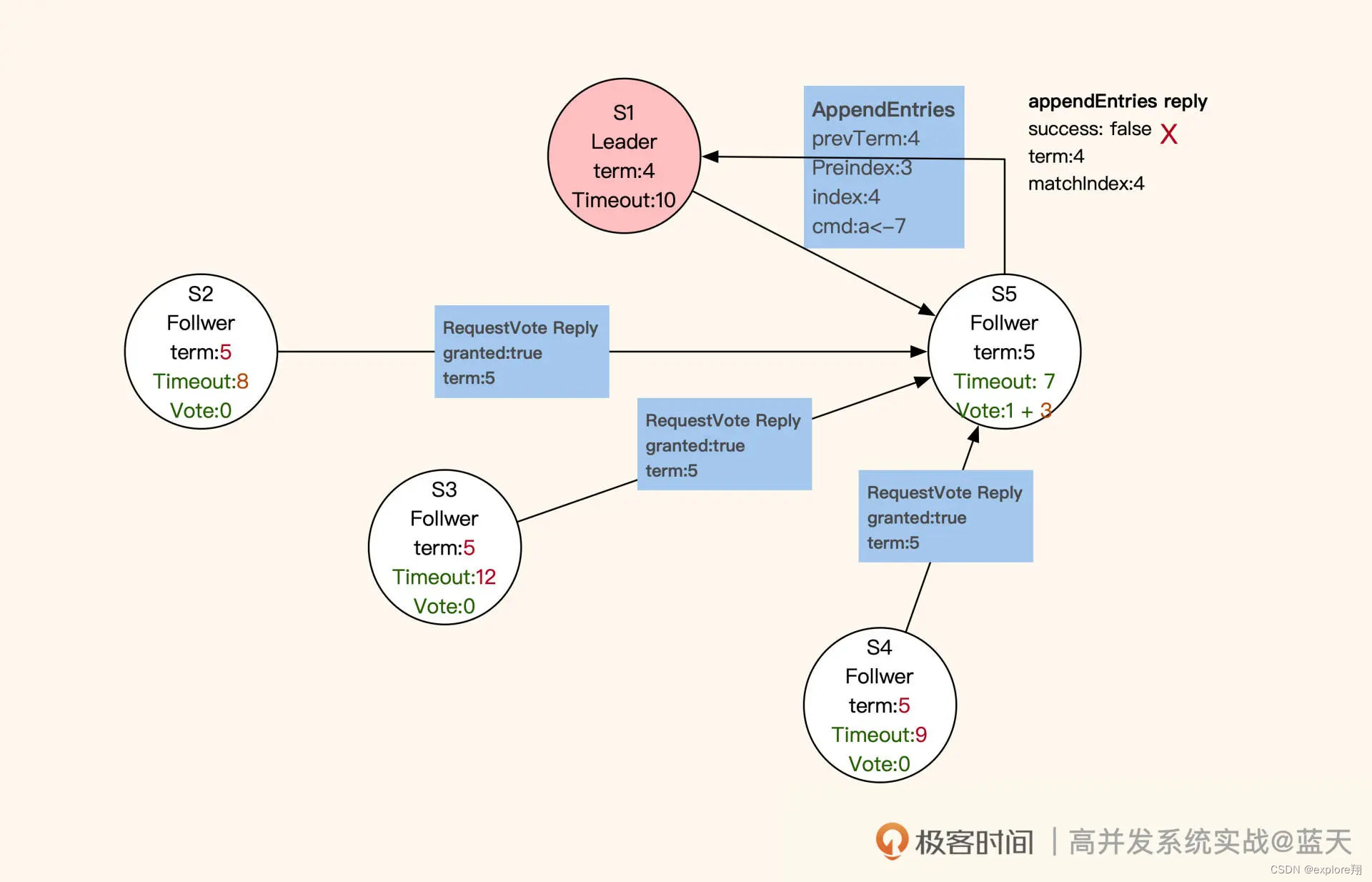
如何保证多副本写一致?
在数据同步期间,Follower 会与 Leader 的日志完全保持一致。不难看出,Raft 算法采用的也是主从方式同步,只不过 Leader 不是固定的服务,而是被选举出来的。这样当个别节点出现故障时,是不会影响整体服务的。不过,这种机制也有缺点:如果 Leader 失联,那么整体服务会有一段时间忙于选举,而无法提供数据服务。通常来说,客户端的数据修改请求都会发送到 Leader 节点(如下图 S1)进行统一决策,如果客户端请求发送到了 Follower,Follower 就会将请求重定向到 Leader。那么,Raft 是怎么实现同分区数据备份副本的强一致性呢?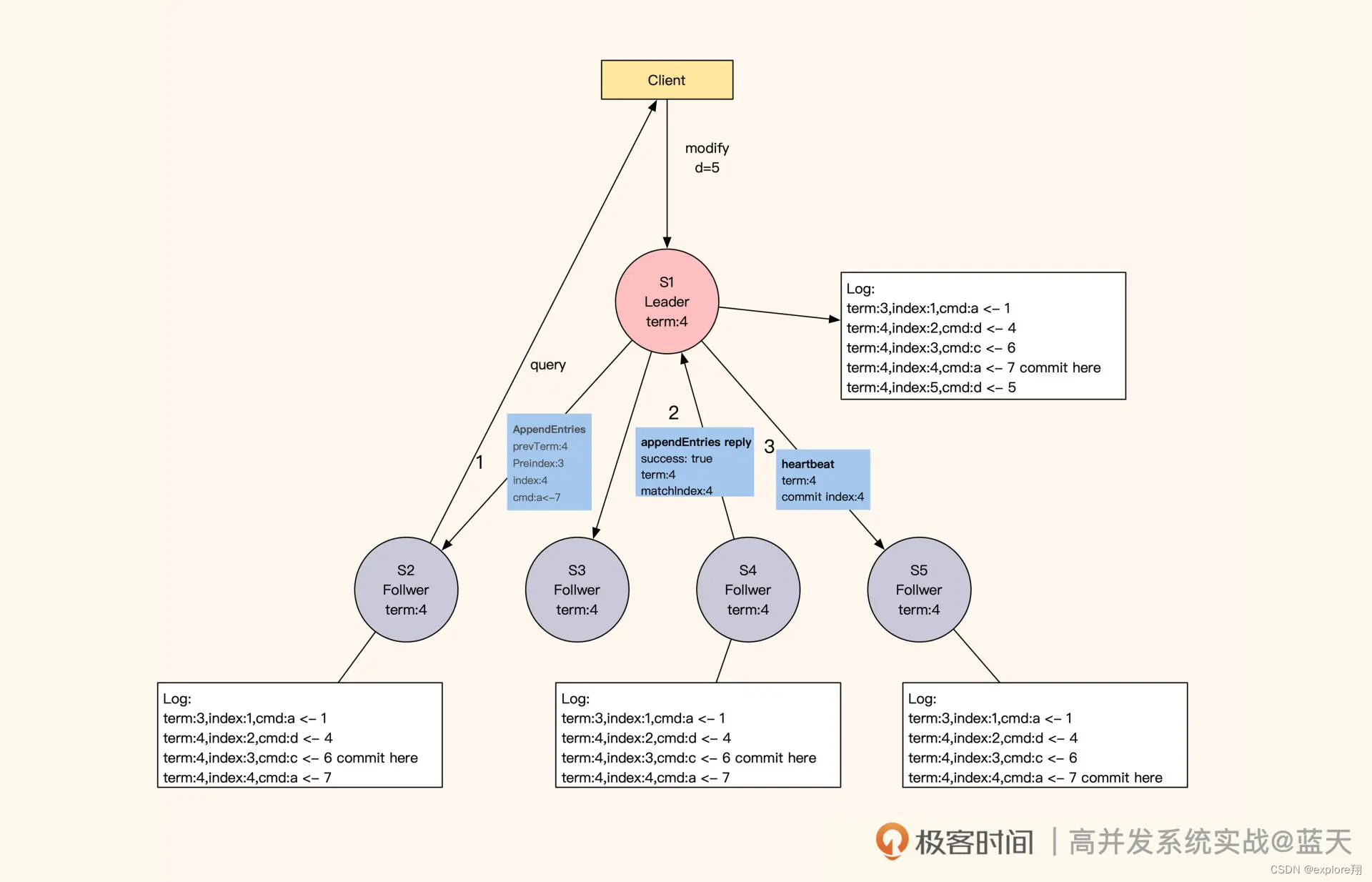
具体来讲,Leader 成功修改数据后,会产生对应的日志,然后 Leader 会给所有 Follower 发送单条日志同步信息。只要大多数 Follower 返回同步成功,Leader 就会对预提交的日志进行 commit,并向客户端返回修改成功。接着,Leader 在下一次心跳时(消息中 leader commit 字段),会把当前最新 commit 的 Log index(日志进度)告知给各 Follower 节点,然后各 Follower 按照这个 index 进度对外提供数据,未被 Leader 最终 commit 的数据则不会落地对外展示。如果在数据同步期间,客户端还有其他的数据修改请求发到 Leader,那么这些请求会排队,因为这时候的 Leader 在阻塞等待其他节点回应。
不过,这种阻塞等待的设计也让 Raft 算法对网络性能的依赖很大,因为每次修改都要并发请求多个节点,等待大部分节点成功同步的结果。最惨的情况是,返回的 RTT 会按照最慢的网络服务响应耗时(“两地三中心”的一次同步时间为 100ms 左右),再加上主节点只有一个,一组 Raft 的服务性能是有上限的。对此,我们可以减少数据量并对数据做切片,提高整体集群的数据修改性能。请你注意,当大多数 Follower 与 Leader 同步的日志进度差异过大时,数据变更请求会处于等待状态,直到一半以上的 Follower 与 Leader 的进度一致,才会返回变更成功。当然,这种情况比较少见。
服务之间如何同步日志进度?
讲到这我们不难看出,在 Raft 的数据同步机制中,日志发挥着重要的作用。在同步数据时,Raft 采用的日志是一个有顺序的指令日志 WAL(Write Ahead Log),类似 MySQL 的 binlog。该日志中记录着每次修改数据的指令和修改任期,并通过 Log Index 标注了当前是第几条日志,以此作为同步进度的依据。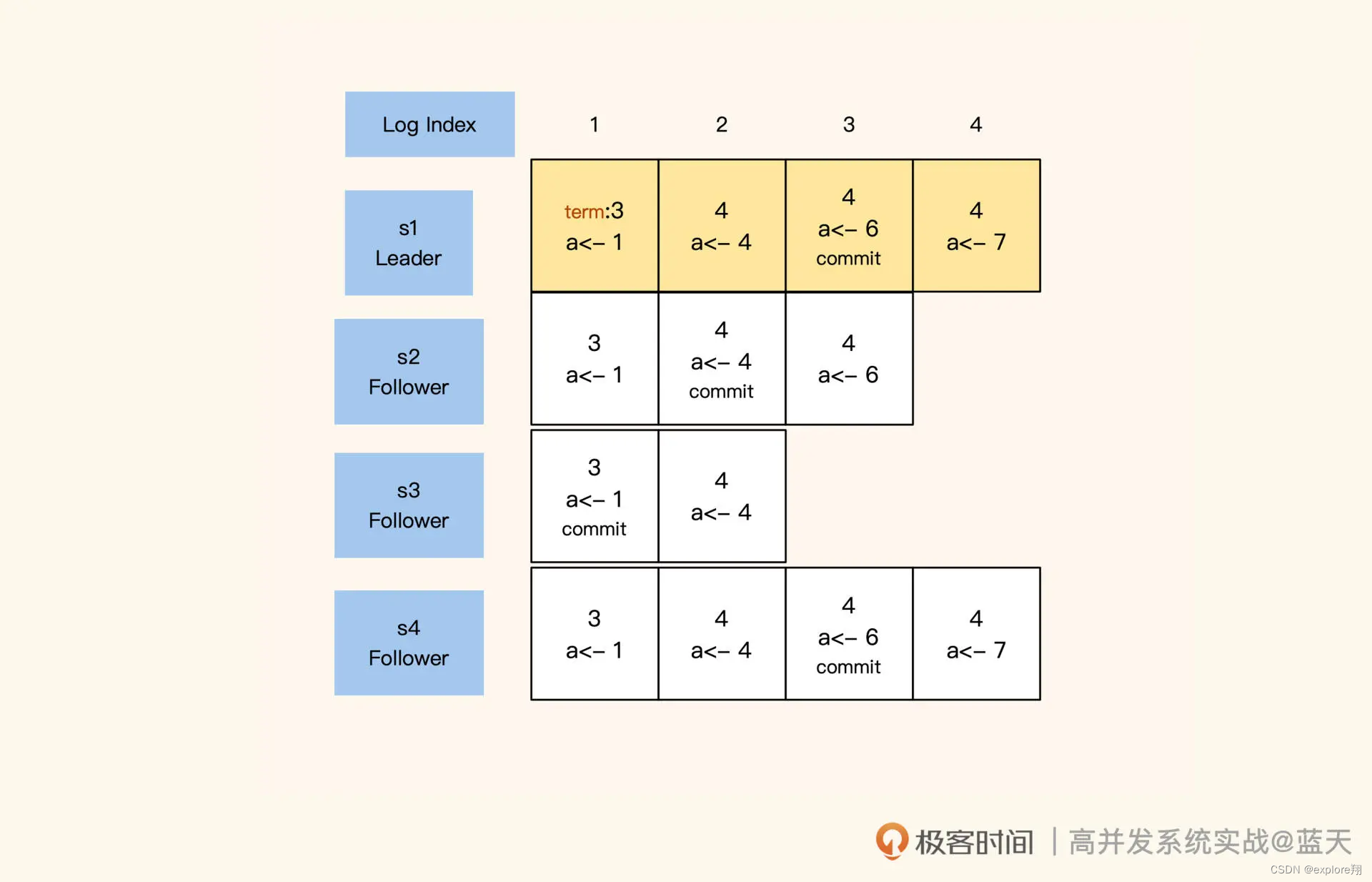
其中,Leader 的日志永远不会删除,所有的 Follower 都会保持和 Leader 完全一致,如果存在差异也会被强制覆盖。同时,每个日志都有“写入”和“commit”两个阶段,在选举时,每个服务会根据还未 commit 的 Log Index 进度,优先选择同步进度最大的节点,以此保证选举出的 Leader 拥有最新最全的数据。
Leader 在任期内向各节点发送同步请求,其实就是按顺序向各节点推送一条条日志。如果 Leader 同步的进度比 Follower 超前,Follower 就会拒绝本次同步。Leader 收到拒绝后,会从后往前一条条找出日志中还未同步的部分或者有差异的部分,然后开始一个个往后覆盖实现同步。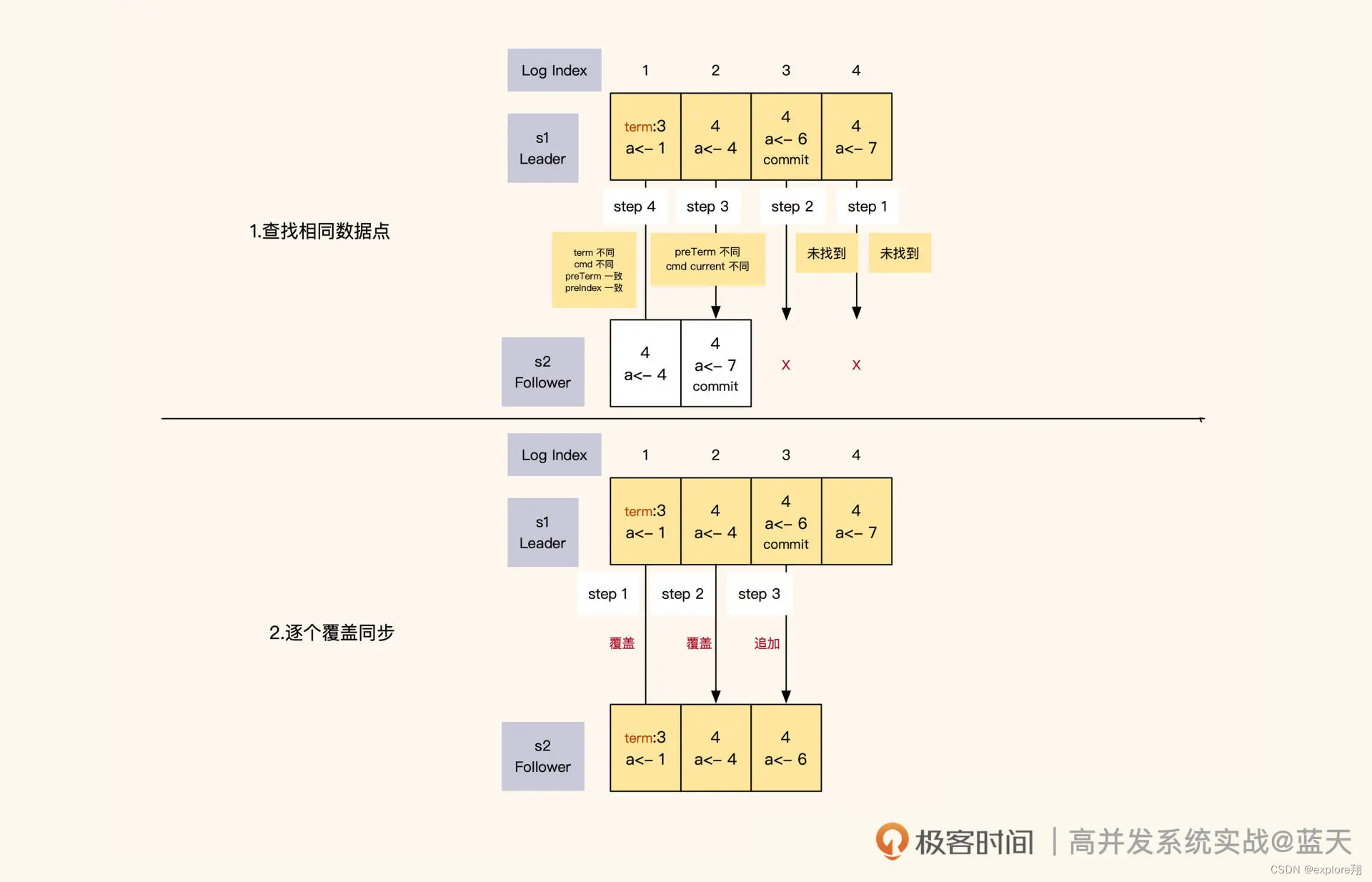
Leader 和 Follower 的日志同步进度是通过日志 index 来确认的。Leader 对日志内容和顺序有绝对的决策权,当它发现自己的日志和 Follower 的日志有差异时,为了确保多个副本的数据是完全一致的,它会强制覆盖 Follower 的日志。
那么 Leader 是怎么识别出 Follower 的日志与自己的日志有没有差异呢?实际上,Leader 给 Follower 同步日志的时候,会同时带上 Leader 上一条日志的任期和索引号,与 Follower 当前的同步进度进行对比。对比分为两个方面:**一方面是对比 Leader 和 Follower 当前日志中的 index、多条操作日志和任期;另一方面是对比 Leader 和 Follower 上一条日志的 index 和任期。**如果有任意一个不同,那么 Leader 就认为 Follower 的日志与自己的日志不一致,这时候 Leader 会一条条倒序往回对比,直到找到日志内容和任期完全一致的 index,然后从这个 index 开始正序向下覆盖。同时,在日志数据同步期间,Leader 只会 commit 其所在任期内的数据,过往任期的数据完全靠日志同步倒序追回。
你应该已经发现了,这样一条条推送同步有些缓慢,效率不高,这导致 Raft 对新启动的服务不是很友好。所以 Leader 会定期打快照,通过快照合并之前修改日志的记录,来降低修改日志的大小。而同步进度差距过大的 Follower 会从 Leader 最新的快照中恢复数据,按快照最后的 index 追赶进度。
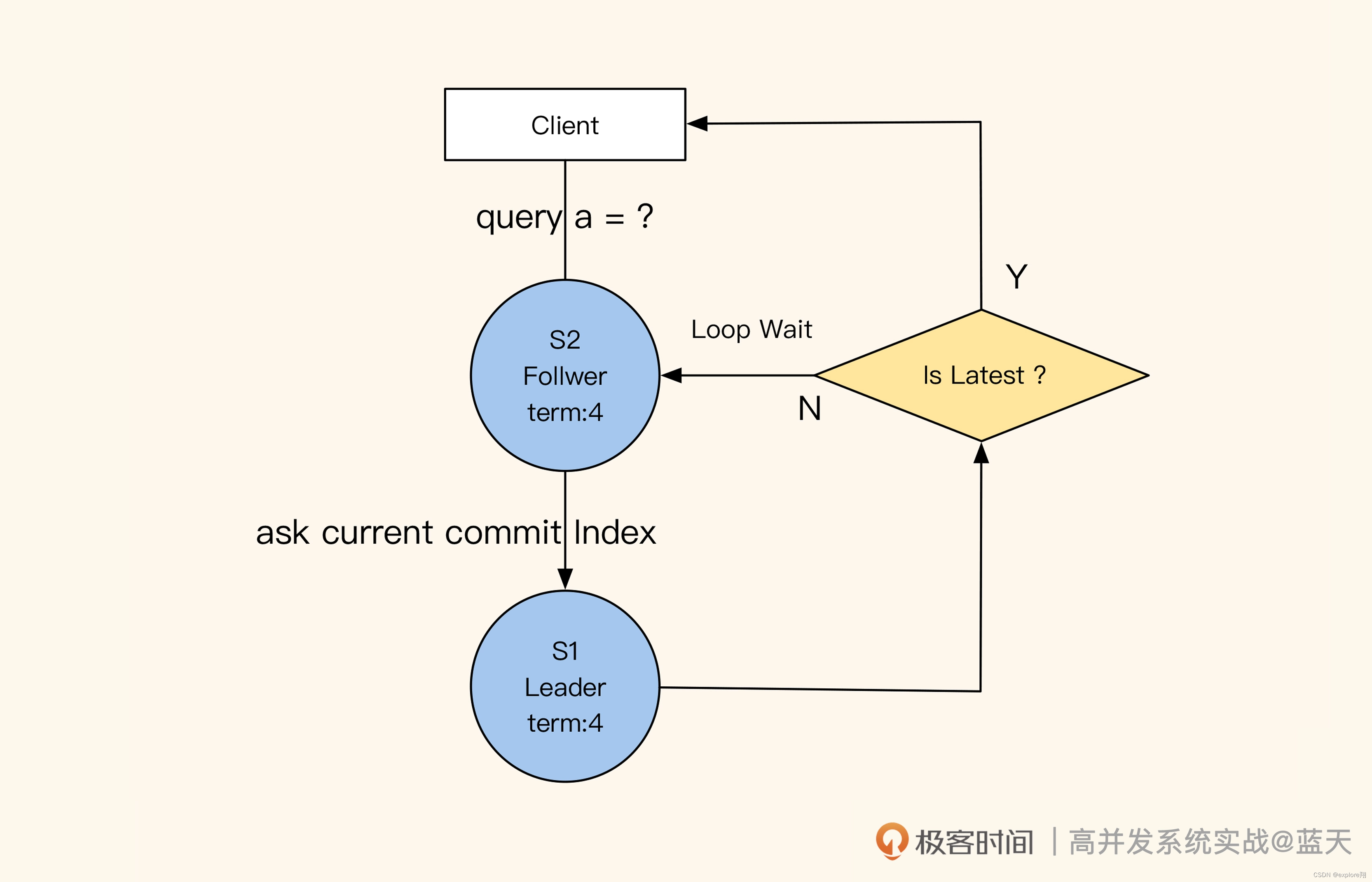
如何保证读取数据的强一致性?
通过前面的讲解,我们知道了 Leader 和 Follower 之间是如何做到数据同步的,那从 Follower 的角度来看,它又是怎么保证自己对外提供的数据是最新的呢?这里有个小技巧,就是 Follower 在收到查询请求时,会顺便问一下 Leader 当前最新 commit 的 log index 是什么。如果这个 log index 大于当前 Follower 同步的进度,就说明 Follower 的本地数据不是最新的,这时候 Follower 就会从 Leader 获取最新的数据返回给客户端。可见,保证数据强一致性的代价很大。