2022年是生成模型奇幻发展的一年,Stable Diffusion?创造了超现实主义的艺术, ChatGPT ?回答了生命意义的问题,Make a Video?从文本生成了栩栩如生的马儿,DreamFusion✨生成了不可思议的三维模型,多个AI领域得以迅速发展,绘画、音乐、新闻创作、主播等诸多行业正在被重新定义。
下面让我们一起回顾2022年里一些引人注目的生成模型顶级论文:
| 模型 | 文章链接 | 项目链接 | 方向 |
|---|---|---|---|
| DALL-E 2 | https://arxiv.org/abs/2204.06125 | DALLE2-pytorch | 文本生成图像 |
| Stable Diffusion | https://arxiv.org/abs/2112.10752 | Stable Diffusion | 文本生成图像 |
| An Image is Worth One Word | https://arxiv.org/abs/2208.01618 | An Image is Worth One Word | 文本生成图像 |
| Make-A-Video | https://arxiv.org/abs/2209.14792 | Make-A-Video | 文本生成视频 |
| Dreambooth | https://arxiv.org/abs/2208.12242 | Dreambooth | 文本生成图像 |
| YOLOv7 | https://arxiv.org/abs/2208.12242 | YOLOv7 | 目标检测、图像生成 |
| ChatGPT | https://openai.com/blog/chatgpt/ | ChatGPT | 人机对话 |
| Block-NeRF | https://openai.com/blog/chatgpt/ | Block-NeRF | 人机对话 |
| DreamFusion | https://dreamfusion3d.github.io/ | DreamFusion | 文本转3D |
| Whisper | https://cdn.openai.com/papers/whisper.pdf | Whisper | 音频转文字 |
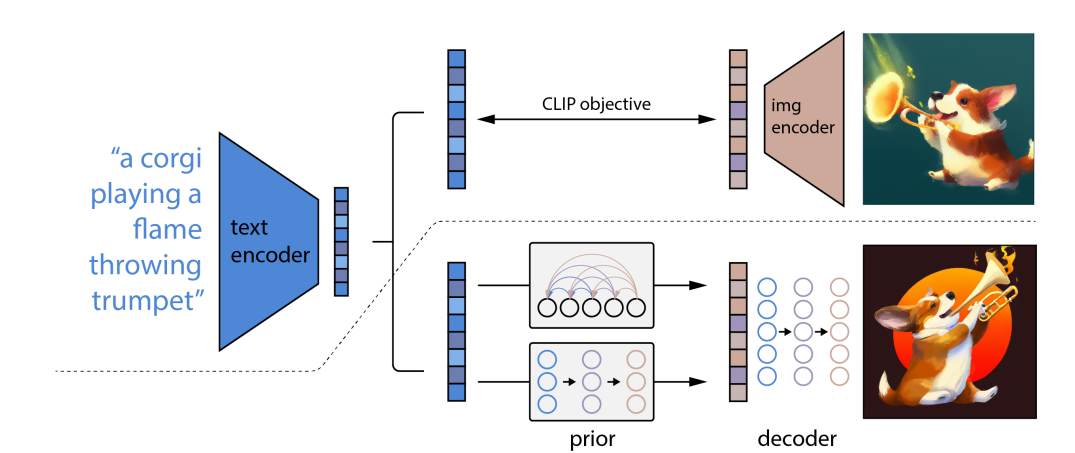
1、DALL-E 2:使用 CLIP 生成分层文本条件图像
DALL-E 2 通过使用两阶段模型提高了 DALL-E 文本到图像生成功能的真实性、多样性和计算效率,首先在给定文本标题的情况下生成 CLIP 图像嵌入,然后使用基于扩散的解码器生成以图像嵌入为条件的图像。
? :模型主要架构为:
先训练好一个CLIP模型,找到图像和文本对之间的相连关系。给定一个文本,CLIP的文本编码器就可以将这个文本变成一个文本特征。DALL·E2训练一个prior模型,将文本特征作为该模型的输入,输出为图像特征,将这个图像特征给解码器,从而生成一个完成的图像。
2、Stable Diffusion:基于潜在扩散模型的高分辨率图像合成
Stable diffusion是一个基于Latent Diffusion Models(潜在扩散模型)的文本生成图像模型。
?:Diffusion model相比GAN可以取得更好的图片生成效果,然而该模型需要反复迭代计算,因此训练和推理代价都很高。论文提出一种在潜在表示空间(latent
space)上进行diffusion过程的方法,从而能够大大减少计算复杂度,同时也能达到十分不错的图片生成效果。
?:Stable diffusion相比于其它空间压缩方法,论文提出的方法可以生成更细致的图像,并且在高分辨率图片生成任务(如风景图生成,百万像素图像)上表现得也很好。
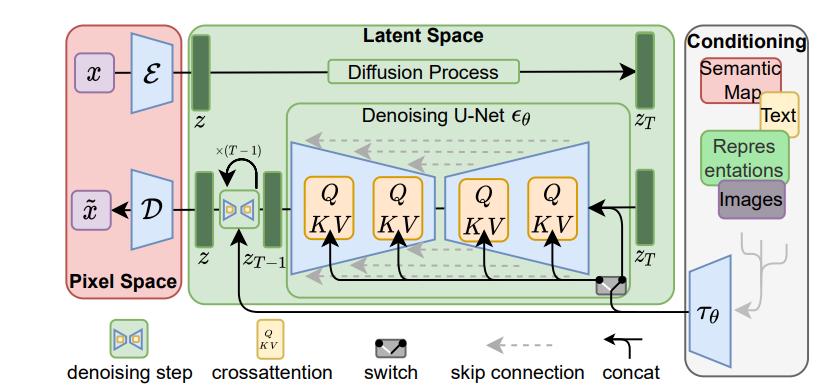 论文将该模型在无条件图片生成(unconditional image synthesis),** 图片修复(inpainting),图片超分(super-resolution)任务上进行了实验,都取得了不错的效果。
论文将该模型在无条件图片生成(unconditional image synthesis),** 图片修复(inpainting),图片超分(super-resolution)任务上进行了实验,都取得了不错的效果。
论文中提到的条件图片生成任务包括 类别条件图片生成(class-condition), 文图生成(text-to-image), 布局条件图片生成(layout-to-image)。
3、An Image is Worth One Word:使用文本反转个性化文本到图像生成
本文提出了 personalized text-to-image generation,也即个性化的文转图生成。可以基于文本+用户给的几张图(“new concepts”)来生成新的图像,“textual inversions”用于把图片概念转换成pseudo-words(text encoder的embedding),用这个embedding表示新的concept从而生成一些具备这样概念的图片。相比GAN在embedding space上的很多技巧,本文的方法在distortion和editability上取得了很好的平衡。
创新思路
通过使用三五张新的‘words’在冻结权重的text-to-image model(也就是作为特征抽取器)的embedding空间的表示来学习,用户提供的概念,然后这些‘words’可以组成自然语言句子,通过启发式方法来创造个性化的创作。对比之前的工作将给定图像转化到模型的latent space,我们转化用户提供的概念。此外,我们将这个概念表示为模型词汇表中的一个新的伪词, for more general and intuitive editing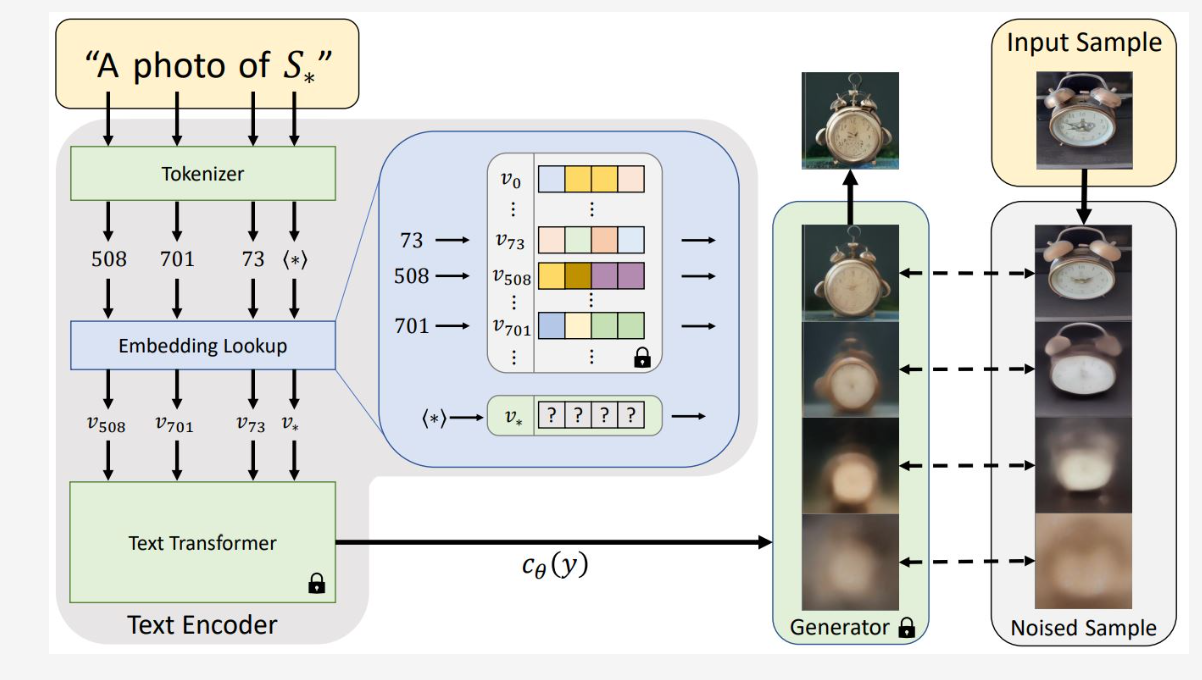
4、Make-A-Video:根据一句话就能一键生成视频
Make-A-Video——一种直接将文本到图像(T2I)生成的最新巨大进展转换为文本到视频(T2V)的方法。
Make-A-Video有三个优点:
它加快了T2V模型的训练(它不需要从头开始学习视觉和多模态表示),它不需要成对的文本视频数据,生成的视频继承了当今图像生成模型的广度(审美、幻想描述等方面的多样性)。模型设计了一种简单而有效的方法,用新颖有效的时空模块建立T2I模型。首先,模型分解全时间U-Net和注意张量,并在空间和时间上近似它们。其次,模型设计了一个时空流水线来生成高分辨率和帧速率视频,其中包括视频解码器、插值模型和两个超分辨率模型,可以实现除T2V以外的各种应用。Make-a-video在时空分辨率、对文本的忠实度和质量等各个方面都开创了文本到视频生成的最新技术
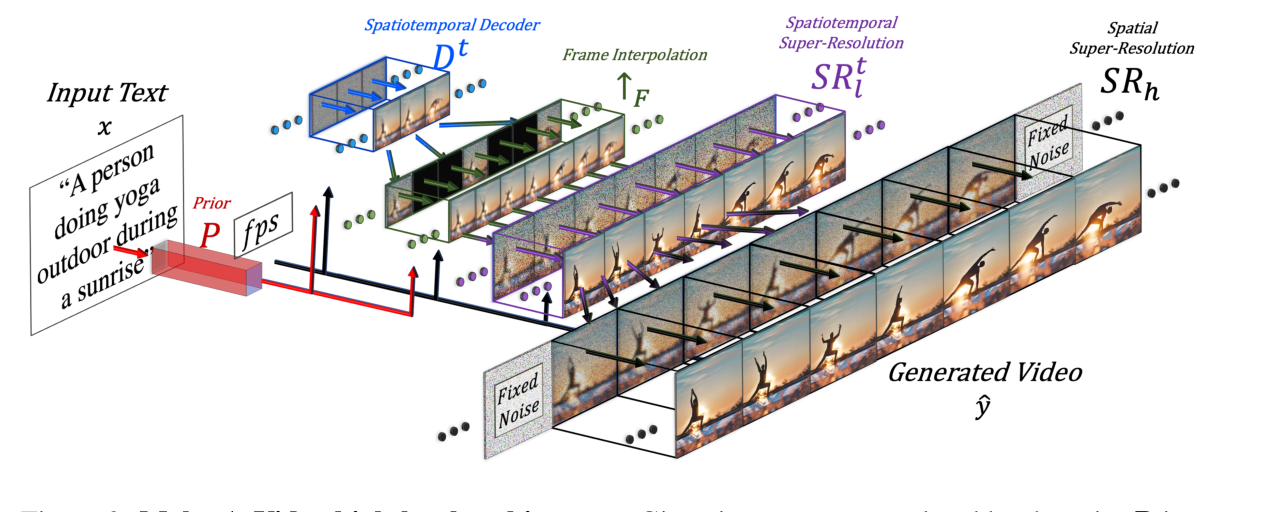
主要框架如上图所示,Make-A-Video由三个主要组件组成:(i)基于文本图像对训练的基本T2I模型(ii)时空卷积层和注意力层以及(iii)用于提高帧率的帧插值网络和两个用来提升画质的超分网络。
5、DreamBooth:微调文本到图像扩散模型以实现主题驱动生成
一些大型文本到图像模型基于用自然语言编写的文本提示(prompt)实现了高质量和多样化的图像合成。这些模型的主要优点是从大量的图像 - 文本描述对中学到强大的语义先验,例如将「dog」?这个词与可以在图像中以不同姿势出现的各种狗的实例关联在一起。
虽然这些模型的合成能力是前所未有的,但它们缺乏模仿给定参考主题的能力,以及在不同场景中合成主题相同、实例不同的新图像的能力。可见,已有模型的输出域的表达能力有限。
为了解决这个问题,来自谷歌和波士顿大学的研究者提出了一种「个性化」的文本到图像扩散模型 DreamBooth,能够适应用户特定的图像生成需求。该研究的目标是扩展模型的语言 - 视觉字典,使其将新词汇与用户想要生成的特定主题绑定。一旦新字典嵌入到模型中,它就可以使用这些词来合成特定主题的新颖逼真的图像,同时在不同的场景中进行情境化,保留关键识别特征
6、YOLOv7:先进的实时目标检测网络
YOLOv7 在 5 FPS 到 160 FPS 范围内的速度和准确度都超过了所有已知的目标检测器,并且在 GPU V100 上 30 FPS 或更高的所有已知实时目标检测器中具有最高的准确度 56.8% AP。
YOLOv7整体上和YOLOV5是相似的,主要是网络结构的内部组件的更换(涉及一些新的sota的设计思想)、辅助训练头、标签分配思想等。整体预处理、loss等可参考yolov5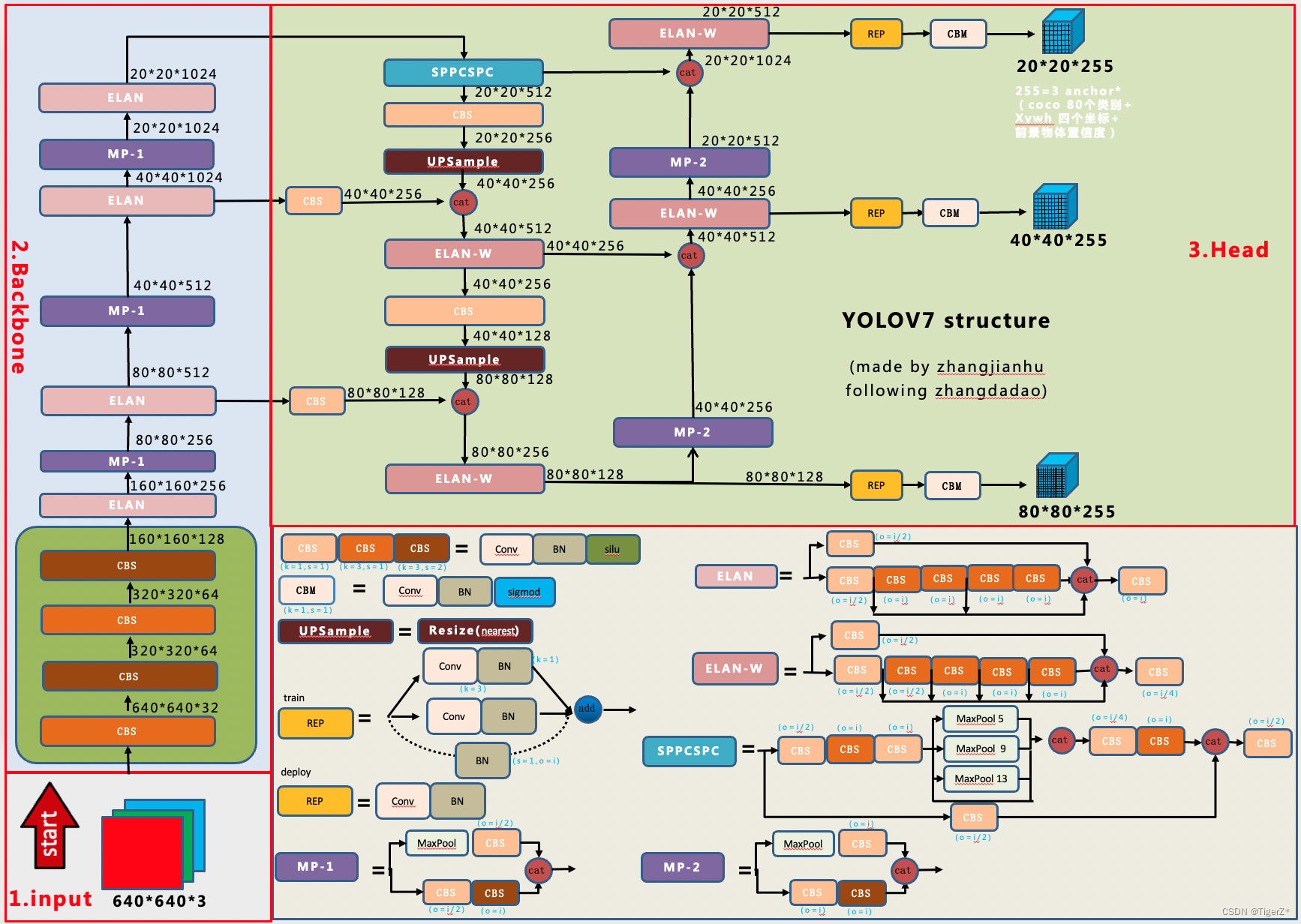
主要贡献是现有的一些trick的集合以及模块重参化和动态标签分配策略,最终在 5 FPS 到 160 FPS 范围内的速度和准确度都超过了所有已知的目标检测器。
7、ChatGPT:遵循人类指令的预训练聊天机器人模型
语言模型在过去几年中通过从人工输入提示生成多样化且引人注目的文本,显示出令人印象深刻的功能。
?:ChatGPT 是一种专注于对话生成的语言模型,能够根据用户的文本输入,产生相应的智能回答,这个回答可以是简短的词语,也可以是长篇大论。ChatGPT使用带有人类反馈的强化学习(RLHF)微调语言模型,这一训练范式增强了人类对模型输出结果的调节,并且对结果进行了更具理解性的排序,使它们能够更好地与人类意图保持一致。其中GPT是Generative
Pre-trained Transformer(生成型预训练变换模型)的缩写。
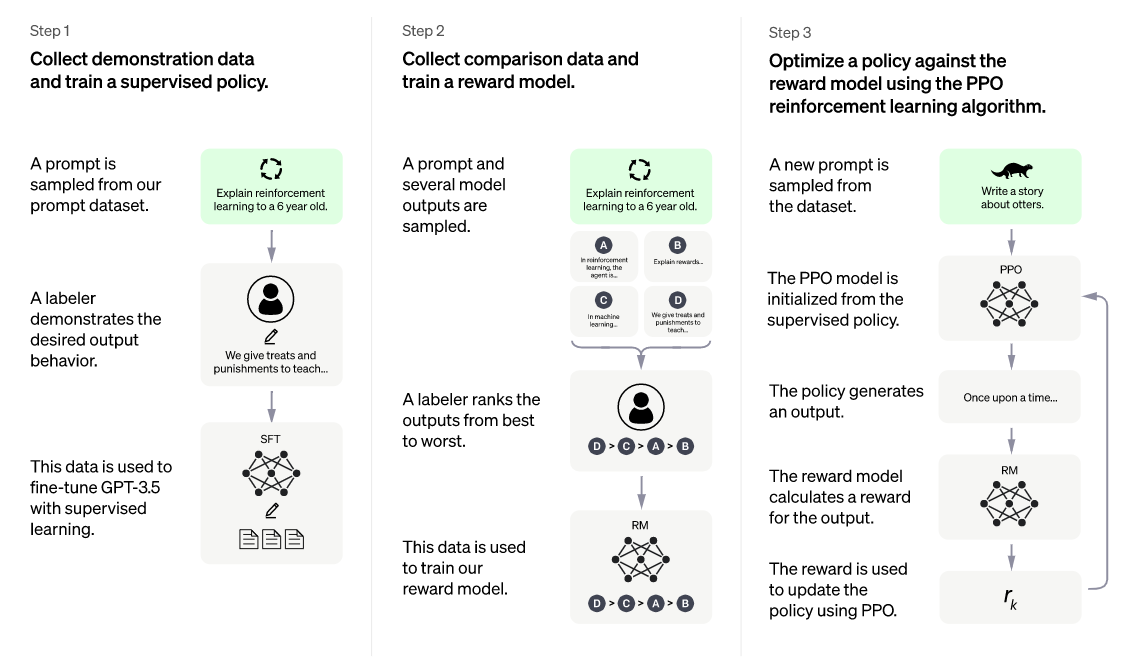
ChatGPT的训练过程分为以下三个阶段:训练监督策略模型 —— 训练奖励模型(Reward Mode,RM) —— 采用PPO(Proximal Policy Optimization,近端策略优化)强化学习来优化策略
8、Block-NeRF:可扩展的大场景神经视图合成

Block-NeRF是一种NeRF新的延伸,用来表示大规模环境。在渲染城市规模的场景时,将城市场景分为多个模块(Blocks),并且将NeRF也单独分配给每个block进行渲染,在预测时动态地呈现和组合这些NeRFs。这种分解(decomposition)的过程将渲染时间与场景大小解耦(decouples),即分隔开两者之间的必然联系,使渲染能够扩展到任意大的环境,并允许对环境进行逐块更新(per-block updates ofthe environment)。
作者最终从 280 万张图像中构建了一个 Block-NeRF 网格,以创建迄今为止最大的神经场景表示,能够渲染旧金山的整个社区。
9、DreamFusion:用二维扩散模型实现Text-to-3D

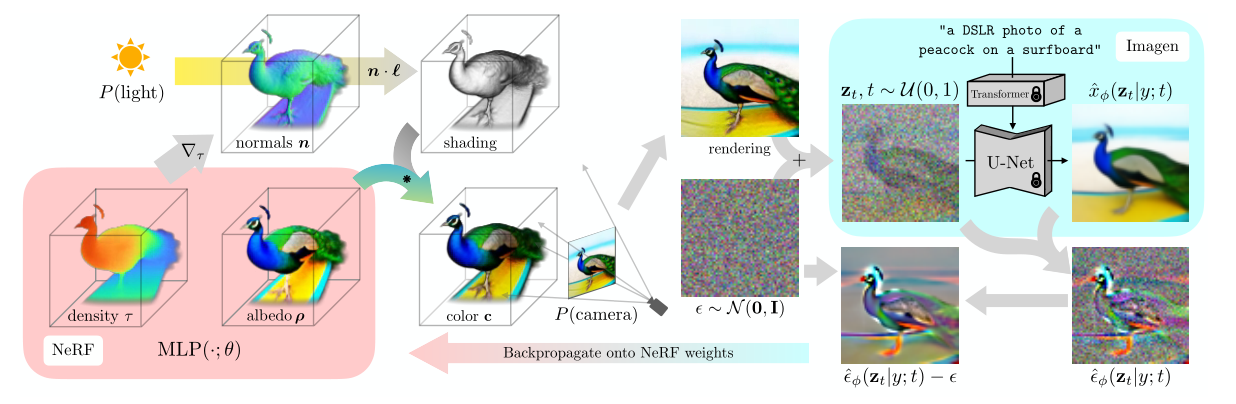
要直接训练一个text-to-3D的模型非常困难,因为DALL-E 2等模型的训练需要吞噬数十亿个图像-文本对,但并不存在如此大规模的3D标注数据,目前也没有一个高效的模型架构对3D数据进行降噪。DreamFusion先使用一个预训练2D扩散模型基于文本提示生成一张二维图像,然后引入一个基于概率密度蒸馏的损失函数,通过梯度下降法优化一个随机初始化的神经辐射场NeRF模型。
在DreamFusion中,使用了一个预先训练的二维文本到图像扩散模型,扩散模型是潜在变量生成模型,它学习将样本从可控制的噪声分布逐渐转换为数据分布。
? :Dreamfusion从随机的相机位置和角度反复渲染NeRF的视图,用这些渲染结果作为环绕Imagen的分数蒸馏损失函数的输入。每次迭代都包含四步:①随机采样一个相机和灯光;②从该相机和灯光下渲染NeRF的图像;③计算SDS损失相对于NeRF参数的梯度;④使用优化器更新NeRF参数。
10、Whisper:基于大规模弱监督的鲁棒语音识别
语音识别是人工智能中的一个领域,它允许计算机理解人类语音并将其转换为文本。 该技术用于 Alexa 和各种聊天机器人应用程序等设备。 而我们最常见的就是语音转录,语音转录可以语音转换为文字记录或字幕。从任务本身来看,音频转文字可没有你想象得那么简单。如果说GPT-3的训练数据是海量的文字,那么Whisper要学习的是各种各样的口音甚至方言,每个人说话的节奏、语调也不一样,由于很多转录场景是电话、通讯APP等非正式场合,背景会有噪音,也会偶尔有中断。
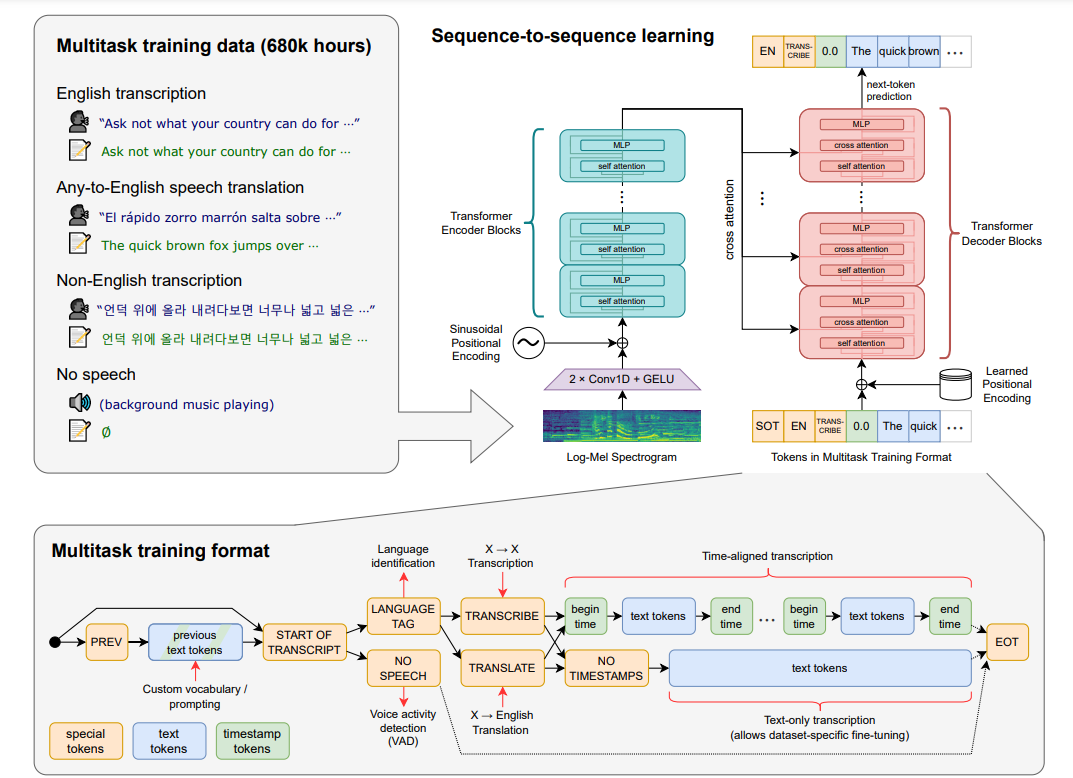
?:Whisper模型是在68万小时标记音频数据的数据集上训练的,其中包括11.7万小时96种不同语言的演讲和12.5万小时从”任意语言“到英语的翻译数据。
Whisper 架构是一种简单的端到端方法,实现为利用Transformer模型的编码器-解码器。输入音频被分成 30 秒一段的模块,然后转换成 log-Mel 频谱图,然后传递到编码器。编码器来计算注意力,最后把数据传递给解码器,解码器被训练来预测相应的文本,并添加特殊标记,这些标记用来单个模型执行诸如语言识别、多语言语音转录和英语语音翻译等任务。
当然,这篇文章绝不是详尽无遗的,我仅仅列举了最引我注目的这十个模型项目,还有更多更多同样优秀出色的成果在2022年焕发光彩。
参考:
https://chuanenlin.medium.com/2022-top-ai-papers-a-year-of-generative-models-a7dcd9109e39
https://blog.csdn.net/weixin_44292547/article/details/126426322
? 最后
我们已经建立了?T2I研学社群,如果你还有其他疑问或者对?文本生成图像很感兴趣,可以私信我加入社群。
? 加入社群 抱团学习:中杯可乐多加冰-采苓AI研习社
? 限时免费订阅:文本生成图像T2I专栏
? 支持我:点赞?+收藏⭐️+留言?