前言
因为项目需要,需要批处理很多Matlab的.m文件,从每个文件中提取结果合并到一个文件中。 很明显,如果手工统计,几百个文件会累死的。 因此立即想到了Python在批处理方面的优势,因此就在网上找了相关资料,实现了想要的功能,这里简单记录一下。
一、环境准备
首先电脑上要有Matlab,而且不能太老,比如Matlab 7.0可能就不行。 在电脑Matlab的安装目录下,依次找到MATLAB\R2015b\extern\engines\python,例如我电脑上的路径是D:\Program Files\MATLAB\R2015b\extern\engines\python。 在这个目录下有个setup.py。在命令行中安装这个脚本,正常就可以成功了。
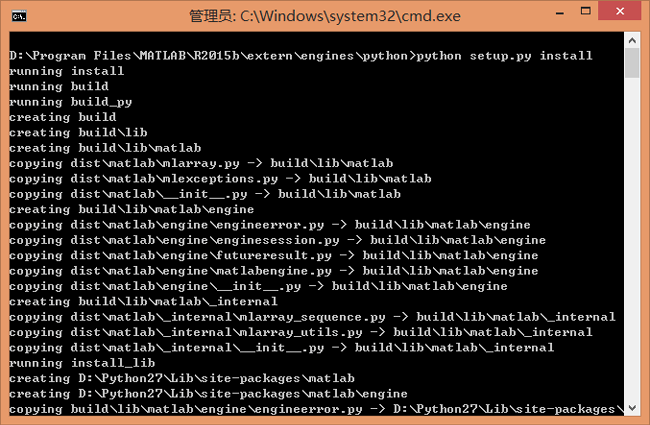
然后就可以在Python中import了,这个包的名字就叫”matlab”。
二、简单示例
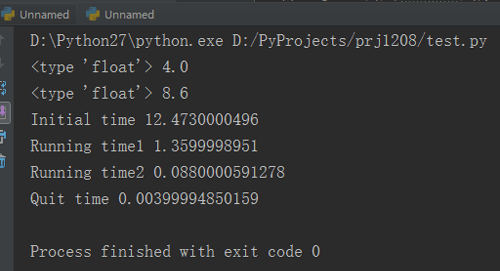
下面的代码简单演示了在Python中调用了Matlab的sqrt()函数并返回结果。说明了调用的主要步骤,同时加入了计时的代码,记录每个过程的耗时。
# coding=utf-8import matlab.engineimport time# 第一步,初始化Matlab的Runtimet1 = time.time()eng = matlab.engine.start_matlab()t2 = time.time()# 第二步,调用Matlab函数res1 = eng.sqrt(16.0)t3 = time.time()res2 = eng.abs(-8.6)t4 = time.time()# 第三步,退出Runtimeeng.quit()t5 = time.time()print type(res1), res1print type(res2), res2print "Initial time", t2 - t1print "Running time1", t3 - t2print "Running time2", t4 - t3print "Quit time", t5 - t4可以看到,程序输出了和在Matlab中调用函数一样的格式ans=…。同时可以发现,与C# & Matlab混合编程类似,程序运行最耗时的就是Runtime的初始化。 不同的运算耗时的差别与初始化耗时相比可以忽略不计。同时Runtime只要初始化一次,第二次调用函数时就不需要再初始化了。这些都和C#的接口是一样的。
三、更复杂的示例
很明显,我们好不容易用Python调Matlab肯定不是想简单做个开方、取绝对值的运算的,要不然直接Python就可以实现,何必杀鸡焉用牛刀。 比如调用我们自己编写的.m文件中的函数等等。下
1.调用.m文件
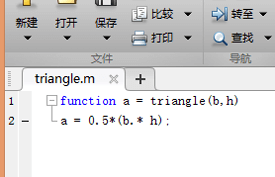
首先新建一个m文件,并起名为triangle.m,用于计算三角形面积。如下。
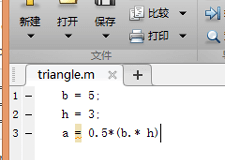
并且将这个m文件放在py文件同一路径下,然后在Python中可以这样调用。
# coding=utf-8import matlab.engineeng = matlab.engine.start_matlab()eng.triangle(nargout=0)eng.quit()结果如下。
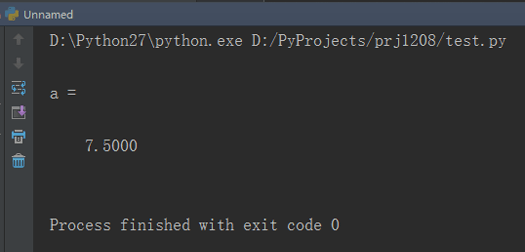
控制台中像Matlab一样输出了结果。 但有几点需要注意。首先nargout=0的含义是表示返回值为空。尽管控制台打印出了结果,但并不会返回给Python。 如果没有这个参数,程序会报错。同时m文件必须和脚本文件在同一目录下才能运行。而eng后面的内容就是m文件的名字。
2.调用自定义函数
把之前的m文件少做修改,编程Matlab函数,如下。
Python调用代码如下:
# coding=utf-8import matlab.engineeng = matlab.engine.start_matlab()ans = eng.triangle(2.3, 9.1)print anseng.quit()这里用变量ans接收了返回值,下一步就可以继续用于其它操作了。 这里也有需要注意的地方。需要记住的是eng后面的依然是m文件的名字而不是函数的名字。 这里就涉及到Matlab中函数的命名规范问题了。一般情况下函数名与m文件名保持一致。 但如果不一致,在Python中经过测试也可以,但最好保持一致。
对于多返回值函数,可以在Matlab中组成一个矩阵,直接返回这个矩阵,然后在Python中再解析。 或者指定返回值个数。
不过需要注意的是,例如Matlab返回了一个a = [[1 2 3]]的矩阵,但直接获取a[0]是错的。因为Matlab返回的是一个二维矩阵,所以矩阵其实是1×3。 所以应该按照行列的方式读取,写成a[0][0]。
在Python中创建Matlab矩阵也很简单。代码如下:
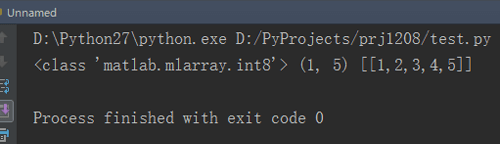
# coding=utf-8import matlab.engineA = matlab.int8([1, 2, 3, 4, 5])print type(A), A.size, A输出结果如下:
3.绘图测试
代码如下。
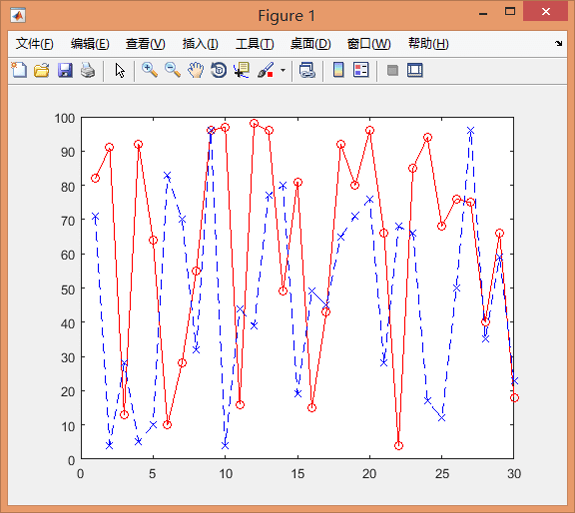
#coding=utf-8import matlab.enginedef plot_test(eng): eng.workspace['data'] = \ eng.randi(matlab.double([1, 100]), matlab.double([30, 2])) eng.eval("plot(data(:,1),'ro-')") eng.hold('on', nargout=0) eng.eval("plot(data(:,2),'bx--')")eng = matlab.engine.start_matlab()plot_test(eng)# 需要让程序在这暂停,类似于C++里的system('pause'),不然Figure一闪而过# 按任意键退出raw_input()eng.quit()运行结果如下。
首先,对于一些简单的命令,如max、min、power、sqrt等,我们直接可以eng.xxx()来完成。 但对于如绘图等稍微复杂的命令,我们就可以使用eng.eval()函数来完成。 其中参数是我们拼接的需要执行的字符串,如“plot(data(:,1),’ro-‘)”等。这样程序在运行时就会调用Matlab执行这一行语句。 所以其实同理,我们完全可以把之前的例子写成eng.eval("sqrt(16.0)",nargout=0),控制台会输出结果4。 或者全部用eval()函数来写Matlab命令,不与Python进行数据交互,只是调用Matlab。 在使用eval()时需要注意返回值的问题。如果没有返回值,别忘了加上一句nargout=0。
以上只是很少一部分混合编程的相关知识,只是项目中用到的部分。其实还有很多东西可以学习,更多有关Python Matlab混合编程的说明可以参考官方文档。 看到网上还有一种Matlab的调用方式,直接pip install mlab,然后直接import mlab就可以了,但是没有尝试,因此这里不多介绍了。
三、项目相关
最后简单说一下项目相关的东西。项目中的需求是,有很多.m文件分布在许多文件夹中,需要获取到某一路径下的全部m文件。 然后获取m文件中矩阵的相关统计值。最后再将各个m文件的统计结果汇总在一个m文件中。 因此使用了Python的os模块遍历文件夹,获取所有m文件的路径,然后根据指定的规则对m文件进行重写,并输出成新的m文件放在脚本目录下。 最后通过Python调用Matlab运行m脚本,输出结果到Python中,Python集中汇总输出。
这里的关键点之一是由于各个m文件的文件名是不同的,因此eng.xxx()是没有办法在运行前写死的。 必须根据读取的文件名动态生成Python语句然后运行。这对于传统编译型语言可能很难实现,但对Python解释型语言很容易实现。 在Python中有exec()函数可以实现这个需求,其中参数是需要执行的代码字符串。 项目部分代码如下:
def joinCode(new_names): codes = [] for item in new_names: codes.append("res = eng." + item + "()") return codesdef execMatlab(codes, exs, ex2s, eys, ey2s): eng = matlab.engine.start_matlab() for code in codes: exec code exs.append(res[0][0]) ex2s.append(res[0][1]) eys.append(res[0][2]) ey2s.append(res[0][3]) eng.quit()项目中首先调用joinCode()函数根据new_names列表动态生成代码字符串存放在codes中。 然后调用execMatlab()函数依次执行每条语句。这里的res看似并没有在代码中定义,而且在IDE中确实也会报错,说未定义。 但是其实它是在动态执行的代码中定义的,因此执行时是不会报错的。
顺带提一下,在Python中,执行系统命令调用的是os.system()函数。参数就是需要执行的代码。 而且这个函数对于Windows和Linux都适用,是跨平台的。类似于os.walk()等内置函数,都是抽象后的与系统无关的函数。 下面的代码是用于执行动态系统代码的例子:
def exeCMD(cmds): for i in range(cmds.__len__()): print "\n---------------------------------------------------------------------" print "Executing:", cmds[i] os.system(cmds[i]) print "---------------------------------------------------------------------\n" print "**********", ((i + 1) * 1.0 / len(cmds)) * 100, "% finished.**********" print "**********100 % finished.**********"最后,可以import platform包,可以获取系统类型。如下函数是判断当前是什么系统,从而自动决定是使用哪种路径分隔符。
def getOSType(): sysstr = platform.system() if (sysstr == "Windows"): separator = "\\" elif (sysstr == "Linux"): separator = "/" return separator